当前位置:网站首页>CV learning notes alexnet
CV learning notes alexnet
2022-07-03 10:09:00 【Moresweet cat】
Alexnet
1. background
AlexNet yes 2012 year ImageNet The winner of the competition Hinton And his students Alex Krizhevsky The design of the . Also after that year , More and deeper neural networks are proposed .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-2b8DWrWq-1644766402742)(./imgs/image-20220124173246167.png)]](/img/db/4e2ca3d794500bbedb58369aec791d.jpg)
2. Network structure
Original network structure :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-UqWJ2aWj-1644766402743)(./imgs/format,png)]](/img/45/58fdba00d37ef4ac13b545cbaa8c11.jpg)
The original explanation is that the top half and the bottom half run in different GPU On , So simplify the native network into the following structure , Let's see how the intermediate process is calculated .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-Ceok64pF-1644766402744)(./imgs/image-20220124173335247.png)]](/img/99/87fba24faff1ec86fe65c6986f1e67.jpg)
Detailed explanation :
Input receive a three channel two-dimensional 224$\times$224 matrix , Therefore, the original input image input network should be processed first ,resize To (224,224,3).
Use steps of 4$\times 4 , Big Small by 11 4, The size is 11 4, Big Small by 11\times$11 The convolution check image is convoluted , Characteristics of output (feature map) by 96 layer ( That is, the output has 96 Channels )
The detailed calculation method has been introduced in the author's previous article , Here is a deduction .
The number of output channels and the number of convolution kernels (3 passageway , The number of channels of convolution kernel should be consistent with the number of original input channels ) Agreement , Therefore, the number of output channels can be artificially defined after convolution . It's used here 96 individual 11$\times 11 volume product nucleus Into the That's ok 了 volume product , transport Out by 55 11 Convolution kernel performs convolution , Output is 55 11 volume product nucleus Into the That's ok 了 volume product , transport Out by 55\times 55 55 55\times$96,55 How to calculate it , Using the formula N=(W-F+2P)/S + 1,W Enter a size for ,F Is the convolution kernel size ,P To fill the value size ,S Is the step size , Substituting into the formula, we can get ,N=(224-55+2 × \times × 0)/4 +1=54, Many layers have been LRN operation , May refer to 《 The controversial local response normalization of deep learning (LRN) Detailed explanation 》, The author will not make an introduction here
Then enter the pool operation , Pooling does not change the number of output channels , Pooled pool_size by 3 $ \times$ 3, Therefore, the output size is (55-3)/2+1=27, So the final output is 27 × 27 × 96 27\times 27\times 96 27×27×96
And then pass by same The way padding after , use 5 × \times × 5 Convolution operation is carried out by convolution kernel of , The output channel is 256,same After calculation, the output is ⌈ 27 1 ⌉ = 27 \lceil \frac{27}{1} \rceil = 27 ⌈127⌉=27, The output size does not change , So the final output is 27 × 27 × 256 27 \times 27 \times 256 27×27×256
In the framework of general deep learning padding There are two filling methods ,same and vaild,same Under way , Try to keep the output consistent with the input size ( Excluding the number of channels ), It is based on the above calculation formula P value , To decide how many turns to add around 0, Then the output size is N = ⌈ W S ⌉ N =\lceil \frac{W}{S} \rceil N=⌈SW⌉
valid Specify P=0, Then the output size is N = ⌈ W − F + 1 S ⌉ N = \lceil \frac{W-F+1}{S}\rceil N=⌈SW−F+1⌉
contrast :valid Mode means only effective convolution , Do not process boundary data ;same Represents the convolution result at the reserved boundary , It usually leads to output shape With the input shape identical
And then use 3 × \times × 3 The window of , In steps 2 × \times × 2 The window of the maximum pool operation , Pooling does not change the number of channels , Output is (27-3+0)/2 + 1 = 13, Therefore, the output size is 13 × 13 × 256 13 \times 13 \times 256 13×13×256
Then go through same Way plus padding, Output is ⌈ 13 1 ⌉ = 13 \lceil \frac{13}{1} \rceil = 13 ⌈113⌉=13 The output channel is specified as 384, That's it 384 individual 3 × 3 3 \times 3 3×3 Convolution kernel ( The number of convolution cores is equal to the number of output channels ), The final output is 13 × 13 × 384 13 \times 13 \times 384 13×13×384
And then keep 384 The output channel of does not change , Add one circle padding( namely P=1), use 3 × \times × 3 The convolution kernel of convolution , Output is (13-3+2)/1 + 1 = 13, So the final output is 13 × 13 × 384 13 \times 13 \times 384 13×13×384
Then set the output channel to 256, Add one circle padding( namely P=1), use 3 × \times × 3 The convolution kernel of convolution , Output is (13-3+2)/1 + 1 = 13, So the final output is 13 × 13 × 256 13 \times 13 \times 256 13×13×256
And then use 3 × \times × 3 The window size of 、2 × \times × 2 Step size of to maximize pool operation , Pooling does not change the number of channels , The number of channels is still 256, Output is (13-3+0)/2 + 1 = 6, So the final output is 6 × 6 × 256 6 \times 6 \times 256 6×6×256
because FC( Fully connected layer ) Receive only one-dimensional vectors , Therefore, it is necessary to 6 × 6 × 256 6 \times 6 \times 256 6×6×256 convert to 1 × 1 × 9216 1 \times 1 \times 9216 1×1×9216 Vector , Input is 9216 Parameters , This process becomes the process of flattening , The principle is to use and original featuremap Convolution with convolution kernels of the same size , The number is the number of output channels , Then go through three layers FC, Re pass softmax Classifiers to classify ,softmax The number of output is the number of categories you want to divide ,FC The process in the layer is equivalent to using 1 × \times × 1 The process of convolution with the convolution kernel of .
Personal study notes , Only exchange learning , Reprint please indicate the source !
边栏推荐
- Window maximum and minimum settings
- Working mode of 80C51 Serial Port
- 2020-08-23
- Timer and counter of 51 single chip microcomputer
- (1) 什么是Lambda表达式
- Drive and control program of Dianchuan charging board for charging pile design
- Leetcode 300 longest ascending subsequence
- (2)接口中新增的方法
- el-table X轴方向(横向)滚动条默认滑到右边
- Windows下MySQL的安装和删除
猜你喜欢

2. Elment UI date selector formatting problem

YOLO_ V1 summary

Leetcode - 895 maximum frequency stack (Design - hash table + priority queue hash table + stack)*
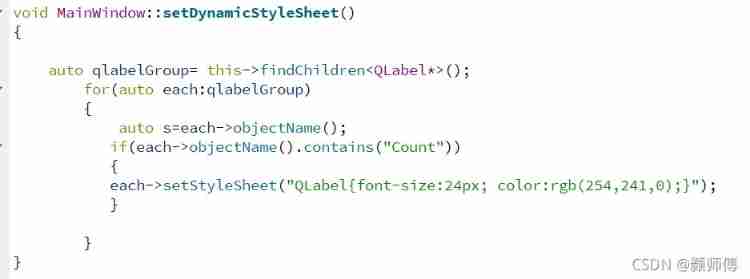
QT is a method of batch modifying the style of a certain type of control after naming the control

LeetCode - 703 数据流中的第 K 大元素(设计 - 优先队列)
LeetCode - 1670 设计前中后队列(设计 - 两个双端队列)

RESNET code details

There is no shortcut to learning and development, and there is almost no situation that you can learn faster by leading the way

Opencv feature extraction - hog

Opencv notes 20 PCA
随机推荐
Vscode markdown export PDF error
Vgg16 migration learning source code
Assignment to '*' form incompatible pointer type 'linkstack' {aka '*'} problem solving
QT self drawing button with bubbles
Connect Alibaba cloud servers in the form of key pairs
STM32 running lantern experiment - library function version
2020-08-23
(2) New methods in the interface
Notes on C language learning of migrant workers majoring in electronic information engineering
CV learning notes - Stereo Vision (point cloud model, spin image, 3D reconstruction)
The new series of MCU also continues the two advantages of STM32 product family: low voltage and energy saving
LeetCode - 703 数据流中的第 K 大元素(设计 - 优先队列)
LeetCode - 1172 餐盘栈 (设计 - List + 小顶堆 + 栈))
Opencv feature extraction - hog
Design of charging pile mqtt transplantation based on 4G EC20 module
Application of external interrupts
My openwrt learning notes (V): choice of openwrt development hardware platform - mt7688
LeetCode - 1670 設計前中後隊列(設計 - 兩個雙端隊列)
getopt_ Typical use of long function
yocto 技术分享第四期:自定义增加软件包支持