当前位置:网站首页>Data Lake (XII): integration of spark3.1.2 and iceberg0.12.1
Data Lake (XII): integration of spark3.1.2 and iceberg0.12.1
2022-07-02 19:38:00 【Lansonli】
 List of articles
List of articles
Spark3.1.2 And Iceberg0.12.1 Integrate
One 、 towards pom File import depends on
Two 、SparkSQL Set up catalog To configure
3、 ... and 、 Use Hive Catalog management Iceberg surface
Four 、 use Hadoop Catalog management Iceberg surface
4、 Create the corresponding Hive Table mapping data
Spark3.1.2 And Iceberg0.12.1 Integrate
Spark Can operate Iceberg Data Lake , the Iceberg The version is 0.12.1, This version is similar to Spark2.4 Version is compatible . Because in Spark2.4 Operation in version Iceberg Don't support DDL、 Add partition and partition conversion 、Iceberg Metadata query 、insert into/overwrite Wait for the operation , It is recommended to use Spark3.x Version to integrate Iceberg0.12.1 edition , Here we use Spark The version is 3.1.2 edition .
One 、 towards pom File import depends on
stay Idea Created in Maven project , stay pom Import the following key dependencies into the file :
<!-- Configure the following to solve stay jdk1.8 When packing in an environment, there is an error “-source 1.5 China does not support it. lambda expression ” -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- Spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!-- Spark And Iceberg Integrated dependency packages -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-spark3</artifactId>
<version>0.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-spark3-runtime</artifactId>
<version>0.12.1</version>
</dependency>
<!-- avro Format Dependency package -->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.10.2</version>
</dependency>
<!-- parquet Format Dependency package -->
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.12.0</version>
</dependency>
<!-- SparkSQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!-- SparkSQL ON Hive-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!--<!–mysql Rely on the jar package –>-->
<!--<dependency>-->
<!--<groupId>mysql</groupId>-->
<!--<artifactId>mysql-connector-java</artifactId>-->
<!--<version>5.1.47</version>-->
<!--</dependency>-->
<!--SparkStreaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!-- SparkStreaming + Kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!--<!– towards kafka Production data requires packages –>-->
<!--<dependency>-->
<!--<groupId>org.apache.kafka</groupId>-->
<!--<artifactId>kafka-clients</artifactId>-->
<!--<version>0.10.0.0</version>-->
<!--<!– Compile and test using jar package , No transitivity –>-->
<!--<!–<scope>provided</scope>–>-->
<!--</dependency>-->
<!-- StructStreaming + Kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!-- Scala package -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.14</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.12.14</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.12.14</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
<version>1.0</version>
</dependency>
</dependencies>Two 、SparkSQL Set up catalog To configure
The following operations are mainly SparkSQL operation Iceberg, Again Spark Two are supported in Catalog Set up :hive and hadoop,Hive Catalog Namely iceberg Table storage use Hive Default data path ,Hadoop Catalog You need to specify the Iceberg Format table storage path .
stay SparkSQL The code specifies the Catalog:
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
// Appoint hive catalog, catalog The name is hive_prod
.config("spark.sql.catalog.hive_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hive_prod.type", "hive")
.config("spark.sql.catalog.hive_prod.uri", "thrift://node1:9083")
.config("iceberg.engine.hive.enabled", "true")
// Appoint hadoop catalog,catalog The name is hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.getOrCreate()3、 ... and 、 Use Hive Catalog management Iceberg surface
Use Hive Catalog management Iceberg The default data of the table is stored in Hive Corresponding Warehouse Under the table of contents , stay Hive The corresponding Iceberg surface ,SparkSQL Equivalent to Hive client , Additional Settings required “iceberg.engine.hive.enabled” The attribute is true, Otherwise, in the Hive Corresponding Iceberg Data cannot be queried in the format table .
1、 Create table
// Create table ,hive_pord: Appoint catalog name .default: Appoint Hive Libraries that exist in .test: Created iceberg Table name .
spark.sql(
"""
| create table if not exists hive_prod.default.test(id int,name string,age int) using iceberg
""".stripMargin)Be careful :
1) Create table time , The name of the table is :${catalog name }.${Hive Middle Library name }.${ Created Iceberg Format table name }
2) After the table is created , Can be in Hive The corresponding test surface , Created is Hive appearance , In the corresponding Hive warehouse The corresponding data directory can be seen under the directory .

2、 insert data
// insert data
spark.sql(
"""
|insert into hive_prod.default.test values (1,"zs",18),(2,"ls",19),(3,"ww",20)
""".stripMargin)3、 Query data
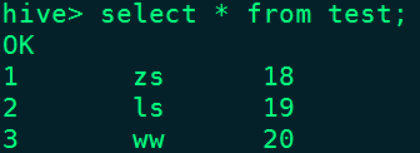
// Query data
spark.sql(
"""
|select * from hive_prod.default.test
""".stripMargin).show()give the result as follows :

stay Hive Corresponding test Data can also be queried in the table :
4、 Delete table
// Delete table , The data corresponding to the deleted table will not be deleted
spark.sql(
"""
|drop table hive_prod.default.test
""".stripMargin)Be careful : After deleting the table , The data will be deleted , But the table directory still exists , If the data is completely deleted , You need to delete the corresponding table directory .
Four 、 use Hadoop Catalog management Iceberg surface
Use Hadoop Catalog Management table , You need to specify the corresponding Iceberg Directory where data is stored .
1、 Create table
// Create table ,hadoop_prod: Appoint Hadoop catalog name .default: Specify the library name .test: Created iceberg Table name .
spark.sql(
"""
| create table if not exists hadoop_prod.default.test(id int,name string,age int) using iceberg
""".stripMargin)Be careful :
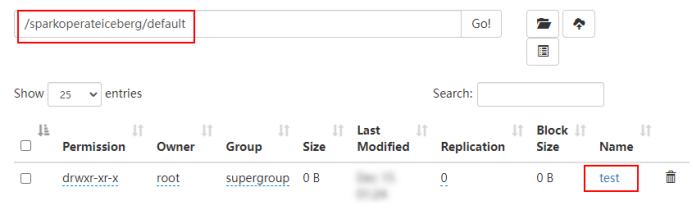
1) Create a table named :${Hadoop Catalog name }.${ Randomly defined library name }.${Iceberg Format table name }
2) Create table , Will be in hadoop_prod Create the table under the directory corresponding to the name
2、 insert data
// insert data
spark.sql(
"""
|insert into hadoop_prod.default.test values (1,"zs",18),(2,"ls",19),(3,"ww",20)
""".stripMargin)3、 Query data
spark.sql(
"""
|select * from hadoop_prod.default.test
""".stripMargin).show() 
4、 Create the corresponding Hive Table mapping data
stay Hive Execute the following table creation statement in the table :
CREATE TABLE hdfs_iceberg (
id int,
name string,
age int
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/sparkoperateiceberg/default/test'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');stay Hive Query in “hdfs_iceberg” The table data is as follows :

5、 Delete table
spark.sql(
"""
|drop table hadoop_prod.default.test
""".stripMargin)Be careful : Delete iceberg After the table , Data is deleted , The corresponding library directory exists .
- Blog home page :https://lansonli.blog.csdn.net
- Welcome to thumb up Collection Leaving a message. Please correct any mistakes !
- This paper is written by Lansonli original , First appeared in CSDN Blog
- When you stop to rest, don't forget that others are still running , I hope you will seize the time to learn , Go all out for a better life
边栏推荐
- Registration opportunity of autowiredannotationbeanpostprocessor in XML development mode
- End to end object detection with transformers (Detr) paper reading and understanding
- 从20s优化到500ms,我用了这三招
- 嵌入式(PLD) 系列,EPF10K50RC240-3N 可编程逻辑器件
- Cuckoo filter
- NMF-matlab
- 《MongoDB入门教程》第03篇 MongoDB基本概念
- [pytorch learning notes] tensor
- NPOI导出Excel2007
- [error record] problems related to the installation of the shuttle environment (follow-up error handling after executing the shuttle doctor command)
猜你喜欢

450-深信服面经1

xml开发方式下AutowiredAnnotationBeanPostProcessor的注册时机

Educational Codeforces Round 129 (Rated for Div. 2) 补题题解
Idea editor removes SQL statement background color SQL statement warning no data sources are configured to run this SQL And SQL dialect is not config
KS004 基于SSH通讯录系统设计与实现

Juypter notebook modify the default open folder and default browser

Istio部署:快速上手微服务,
Advanced performance test series "24. Execute SQL script through JDBC"

Py之interpret:interpret的简介、安装、案例应用之详细攻略

定了,就是它!
随机推荐
Build a master-slave mode cluster redis
【ERP软件】ERP体系二次开发有哪些危险?
AcWing 1131. Saving Private Ryan (the shortest way)
横向越权与纵向越权[通俗易懂]
《重构:改善既有代码的设计》读书笔记(下)
Chic Lang: completely solve the problem of markdown pictures - no need to upload pictures - no need to network - there is no lack of pictures forwarded to others
简书自动阅读
Digital scroll strip animation
Gamefi链游系统开发(NFT链游开发功能)丨NFT链游系统开发(Gamefi链游开发源码)
Web2.0 giants have deployed VC, and tiger Dao VC may become a shortcut to Web3
守望先锋世界观架构 ——(一款好的游戏是怎么来的)
451 implementation of memcpy, memmove and memset
Why should we build an enterprise fixed asset management system and how can enterprises strengthen fixed asset management
Gamefi chain game system development (NFT chain game development function) NFT chain game system development (gamefi chain game development source code)
Windows2008R2 安装 PHP7.4.30 必须 LocalSystem 启动应用程序池 不然500错误 FastCGI 进程意外退出
golang:[]byte转string
使用 Cheat Engine 修改 Kingdom Rush 中的金钱、生命、星
AcWing 343. Sorting problem solution (Floyd property realizes transitive closure)
Binary operation
Introduction of Ethernet PHY layer chip lan8720a