当前位置:网站首页>(2021-08-20) web crawler learning 2
(2021-08-20) web crawler learning 2
2022-07-04 11:19:00 【Kosisi】
Here's the catalog title
1 Regular expressions
1.1 regular expression syntax
regular expression 、 regex or RE
Regular expressions are expressions used to express a set of strings concisely , It is mainly used in string matching
Composed of characters and operators
Common operators
| The operator | explain | example |
|---|---|---|
| . | Represents any single character | |
| [ ] | Character set , Give a value range for a single character | [abc] Express a、b、c,[a-z] Express a To z Single character |
| [^] | Non character set , Give the exclusion range for a single character | [^abc] Express non a or b or c A single character of |
| * | Previous character 0 Times or infinitely | abc* Express ab、abc、abcc、abccc etc. |
| + | Previous character 1 Times or infinitely | abc+ Express abc、abcc、abccc etc. |
| ? | Previous character 0 Time or 1 Second expansion | abc? Express ab、abc |
| | | Any one of the left and right expressions | abc |
| {m} | Extend the previous character m Time | ab{2}c Express abbc |
| {m,n} | Extend the previous character m to n Time ( contain n) | ab{1,2}c Express abc、abbc |
| ^ | Match the beginning of a string | ^abc Express abc And at the beginning of a string |
| $ | Match to the end of the string | abc$ Express abc And at the end of a string |
| ( ) | Group markers , The interior can only be used | The operator | (abc) Express abc,(abc|def) Express abc、def |
| \d | Numbers , Equivalent to [0-9] | |
| \w | Word characters , Equivalent to [A-Za-z0-9_] |
matching IP Regular expression of address :
IP The address is divided into 4 paragraph , Each paragraph 0-255
0-99 Representation of the range :[1-9]?\d
100-199 Representation of the range :1\d{2}
200-249 Representation of the range :2[0-4]\d
250-255 Representation of the range :25[0-5]
therefore 0-255 Expressed as ([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
IP Expression of address :(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
1.2 Classic regular expressions
from 26 A string of letters :^[A-Za-z]+$
from 26 A string of letters and numbers :^[A-Za-z0-9]+$
String in integer form :^-?\d+$
A string in the form of a positive integer :^[0-9]*[1-9][0-9]*$
Postal code in China 6 position :[1-9]\d{5}
Match Chinese characters :[\u4e00-\u9fa5]
Domestic phone number :\d{3}-\d{8}|d{4}-\d{7}
2 RE library
2.1 Basic use
import re
re The library uses raw string Type represents regular expression , Expressed as r’text’
raw string Is a string that does not contain a re escape of the escape character
re Library can also be used string Type said , But tedious , And need escape escape character
2.2 Main function function
| function | explain |
|---|---|
| re.search() | Search a string for the first place to match a regular expression , return match object |
| re.match() | Match regular expressions from the beginning of a string , return match object |
| re.findall() | Search string , Return all matching substrings with list type |
| re.split() | Split a string according to the regular expression matching result , Return list type |
| re.finditer() | Search string , Returns the iteration type of a matching result , Each iteration element is mtach object |
| re.sub() | Replace all substrings matching regular expressions in a string , Return the replaced string |
1)re.search(pattern, string, flags=0)
Search a string for the first place to match a regular expression , return match object
pattern: The string or native string representation of a regular expression
string: String to match
flags: Control flags when regular expressions are used
| Common marks | explain |
|---|---|
| re.I re.IGNORECASE | Ignore the case of regular expressions ,[A-Z] Can match lowercase characters |
| re.M re.MULTILINE | In regular expressions ^ The operator can start each line of a given string as a match |
| re.S re.DOTALL | In regular expressions . Operators can match all characters , The default matches all characters except line breaks |
import re
match = re.compile(r'[1-9]\d{5}')
srt = match.search('BIT 100081')
if srt:
print(srt.group(0))
2)re.match(pattern, string, flags=0)
The matching regular expression returns... From the beginning of a string match object
import re
match = re.compile(r'[1-9]\d{5}')
srt = match.match('100081 BIT ')
if srt:
print(srt.group(0))
3)re.findall(pattern, string, flags=0)
Search string , Return all matching substrings with list type
import re
match = re.compile(r'[1-9]\d{5}')
srt = match.findall('BIT100081 TSU100084')
if srt:
print(srt)
4)re.split(pattern, string, maxsplit=0, flags=0)
Split a string according to the regular expression matching result , Return list type
maxsplit: Maximum number of divisions , The rest is output as the last element
Here's an example , He can only cut the first
import re
match = re.compile(r'[1-9]\d{5}')
srt = match.split('BIT100081 TSU100084', maxsplit=1)
if srt:
print(srt)
5)re.finditer(pattern, string, flags=0)
Search string , Returns the iteration type of a matching result , Each iteration element is mtach object
import re
match = re.compile(r'[1-9]\d{5}')
for m in match.finditer('BIT100081 TSU100084'):
if m:
print(m.group(0))
6)re.sub(pattern, repl, string, count=0, flags=0)
Replace all substrings matching regular expressions in a string , Return the replaced string
repl: Replace string matching string
count: The maximum number of replacements to match
sub = match.sub(':zipcode', 'BIT100081 TSU100084')
print(sub)
7)regex=re.compile(pattern, flags=0)
Compile the string form of regular expression into regular expression object
This is a re Another equivalent use of Library - Object oriented usage : Multiple operations after compilation
Such as :
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
2.3 re Library Match object
Match Object is the result of a match , Contains a lot of matching information
Match Object properties
| attribute | explain |
|---|---|
| .string | The text to be matched |
| .re | Used when matching patter object ( Regular expressions ) |
| .pos | The beginning of regular expression search text |
| .endpos | The end of regular expression search text |
Match Object method
| Method | explain |
|---|---|
| .group(0) | Get the matching string |
| .start() | Match string at the beginning of the original string |
| .end() | Match string at the end of the original string |
| .span() | return (.start(), .end()) |
For empty variables , Transfer group It's wrong. , So add if Sentence to judge whether it is empty .
Re Greedy matching and minimal matching of Libraries
Re The library defaults to greedy matching , That is, the output matches the longest substring
Minimum match operator
| The operator | explain |
|---|---|
| *? | Previous character 0 Times or infinitely , Minimum match |
| +? | Previous character 1 Times or infinitely , Minimum match |
| ?? | Previous character 0 Time or 1 Second expansion , Minimum match |
| {m,n}? | Extend the previous character m to n Time ( contain n), Minimum match |
As long as the length output may be different , You can add... After the operator ? Become the smallest match
3 example : Taobao product information directional crawler
3.1 Get ready
3.1.1 Function description
Save it for the next time , Tutorial information is out of date , The first step is to solve the login problem .
4 Stock data directed crawler
4.1 Get ready
Function description :
The goal is : Get all the stock names and trading information of Shanghai Stock Exchange and Shenzhen Stock Exchange
Output : Save to file
technology roadmap :requests-bs4-re
Sina stock :https://finance.sina.com.cn/stock/
Good guy still JavaScript
Save these two questions first , Wait until I learn , Finish these two questions again .
But there is one thing to remember , Print without wrapping ,’\r’, Indicates that the cursor is raised to the front of this line , Then the output , And cover this line . meanwhile print Every time the function outputs, there will be a newline , So this can be banned ,end=' '
5 Scrapy library
5.1 Basic knowledge
5.1.1 Crawler framework analysis
The crawler frame , It is a collection of software structure and functional components to realize the function of crawler , Can help users to achieve professional web crawler .
5+2 structure , Five of them are the main part of the framework , It also contains two intermediate keys
ENGINE modular 、SCHEDULER modular 、ITEM PIPELINES modular 、SPIDERS Module and DOWNLOADER modular
stay ENGINE Module and SPIDERS modular 、ENGINE Module and DOWNLOADER modular The middle contains the middle key .downloader MIDDLEWARE Middle key —— Realization engine scheduler and downloader User configurable control of the data flow between . Through the modification of the middle key 、 discarded 、 Add request or response
sipder middleware Middle key —— Reprocessing of requests and crawling items . Functions include modification 、 discarded 、 Add request or crawl item
You can write configuration code
Including the main 3 Data flow paths :
1) from spiders Module passing engine arrive schedur modular ,engine from spiders Get the request of crawling user -request, Understood as a url, Request by spiders arrive engine after ,engine Put this crawl request , Forward to schedur modular —— Be responsible for scheduling crawling requests .
2) from schedur Module through engine arrive downloader modular , The final data is returned to spiders, First engine from schedur The module obtains the next network request to crawl , At this time, the network request is the real request to crawl on the network , that engine After receiving such a request , Send to... Through the middle key downloader modular , then downloader After the module gets the request , Truly connect to the Internet , And crawl relevant web pages , After crawling to the web ,downloader The module will crawl the content to form an object , This object is called response ——response, Encapsulate all the content into one response after , Pass this response through the middle key engine Finally sent to spiders, A real crawl in this path url Request process of schedur downloader Finally, the relevant content is returned to spiders.
3) from spiders What happened engine arrive item pipelines modular , First spiders Deal with from downloader Response obtained , After processing, two data types are generated , A data type is called crawl item ,scrapty item, Also called item, Another data type is the new crawl request , That is to say, after we get a web page from the Internet , If there are other links in this page , It is also what we need , Can be in spiders Add relevant functions in , Start crawling again for new links ;spiders After generating these two data types , Send it to engine modular ,engine After the module receives two types of data , Will be one of the items Send to item pipelines, Will be one of the request Send to schedur To schedule , So as to provide a new data source for later data processing and restart the web crawler request .
The entrance is spiders, The exit is item pipelines;engine、scheduler and downloader All functions have been implemented , Users do not need to edit , What users need to write is spiders and item pipelines modular , Just write according to the framework , Call it configuration
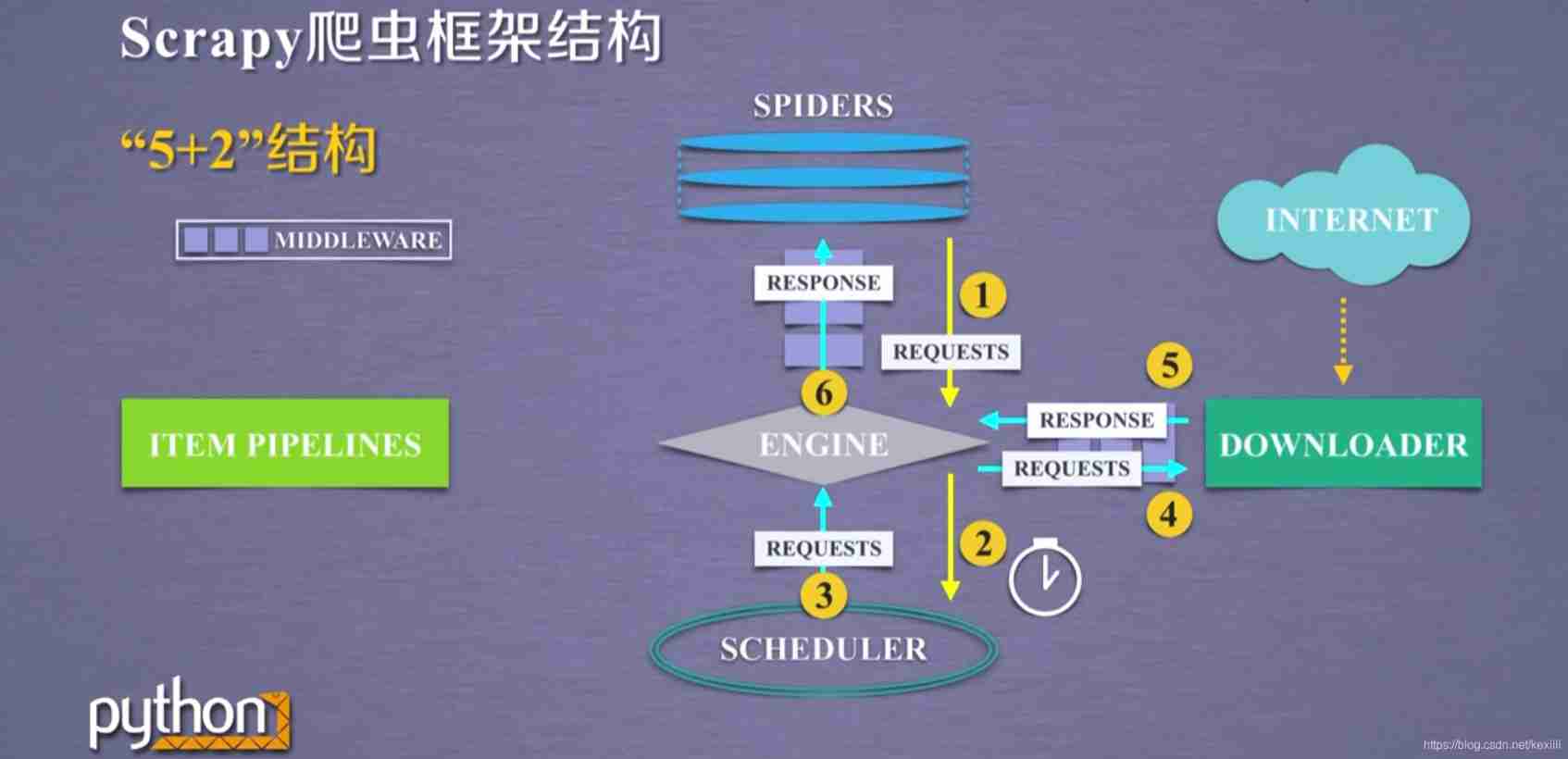
Module analysis
1)engin modular
No user modification is required
Control the data flow between all modules
Trigger events based on conditions
2)downloader modular
Download the web page upon request
3)scheduler Module is a module that schedules and manages all crawling requests
4)spiders modular
analysis downloader Response returned -response
Generate crawling items -scraped item
Generate additional crawling requests -request
5)item pipelines
To process in a pipeline spiders The resulting crawling term
Consists of a sequence of operations , Similar to assembly line , Each operation is a item pipeline type
5.1.2 requests Kuhe scrapy Reptile comparison
Neither of these has been dealt with js、 Submit Form 、 Response to verification code and other functions .
The difference
| requests | scrapy |
|---|---|
| Page crawler | Website crawler |
| Function library | frame |
| Insufficient consideration of concurrency , Poor performance | Good concurrency , Higher performance |
| Focus on page downloads | Focus on reptile structure |
| Flexible customization | General customization flexibility , Difficulty in deep customization |
How to choose :
For smaller requests requests library
Continuous or uninterrupted , Or cyclical , I hope data accumulation can form my own crawler Library , It is recommended to use scrapy
High degree of customization , Self built frame ,requests>scrapy
5.1.3 Common commands
Run from the command prompt scrapy -h You can see that scrapy Command line
Command line format :>scrapy<command>[options][args]
The specific command is command in ,
Common commands
| command | explain | Format |
|---|---|---|
| start project | Create a new project | scrapy startproject <name>[dir] |
| genspider | Create a reptile | scrapy genspider [options] <name> <domain> |
| settings | Get crawler configuration information | scrapy settings [options] |
| crawl | Run a reptile | scrapy crawl <spider> |
| list | List all the crawlers in the project | scrapy list |
| shell | start-up URL Debug command line | scrapy shell [url] |
The command line is easier to automate , Suitable for script control
5.2 Instance of a : Crawl a simple web page
html Address :http://python123.io/ws/demo.html
File name :hemo.html
It looks a little strong ,
1) First, we need to create a crawler project
Select directory , I chose D:\exfile\pyfile\pycode>, stay cmd In the operation , from c Disk to d disc , Direct input d: that will do , To go to the subdirectory, enter cd exfile You can enter the subdirectory , Display the current directory with dir Command is enough . After success, a directory will be generated in this path , The files in the directory are __init__.py、items.py、middlewares.py、pipelines.py、settings.py These documents .
Generated project directory
Generate outer directory : python123demo/
This directory contains configuration files : scrapy.cfg, For deployment scrapy Reptiles use , The concept of deployment is to put the crawler on a specific server , And configure the relevant operation interface in the server
subdirectories :python123demo/, Refer to scrapy User defined framework python Code
__init__.py: Is the initialization script , Users do not need to write
items.py: Corresponding items Class code template , Need to inherit scrapy Library provides the item Class ( Inheritance class )
middlewares.py: refer to middlewares The code template ,( Inheritance class )
pipelines.py:pipelines.py The code template ( Inheritance class )
settings.py: Corresponding scrapy Crawler profile , Optimize crawler function
Next level subdirectory : spiders/, yes spiders Code template directory ( Inheritance class )
The interior includes __init__.py and __pycache__/ Cache directory , There is no need to modify
2) Create a... In the project scrapy Reptiles
Just one command : The user gives the name of the crawler and the website it crawled scrapy genspider demo python123.io
Generate a file named demo Of spider, Will be in spider Create one in the directory demo Of py file , This file can also be generated manually .
Will prompt :Created spider 'demo' using template 'basic' in module: python123demo.spiders.demo
demo.py file
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
start_urls = ['http://python123.io/']
def parse(self, response):
pass
parse() Used to process responses , Parse the content to form a dictionary , Discover new URL Crawl request .
3) Configuration produces spider Reptiles
To modify demo.py file
response It is equivalent to returning the stored or corresponding object of the content from the network , We need to response The content of html In file . modify url:start_urls = ['http://python123.io/ws/demo.html']
The name of the definition file :
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % fname)
4) Run crawler , Access to web pages
stay cmd Run in scrapy crawl demo
5.3 yield Use of keywords
Related to the concept of generator
A generator is a function that constantly generates values
contain yield The function of a statement is a generator
The generator generates one value at a time (yield sentence ), The function is frozen , A value is generated after being awakened .
Usually with for Use it in a circular way
Compared with common writing , Usually, when the number of iterations and cycles is large, resources and storage space can be saved .
5.4 scrapy Data types of reptiles
1)request class class scrapy.http.Request()
Representing one request object —— It means a HTTP request
from spider Generate , from downloader perform
Contains six commonly used properties and methods :
| Properties or methods | explain |
|---|---|
| .url | Request The corresponding request URL Address |
| .method | Corresponding request method ,'GET ''POST’ etc. |
| .headers | Dictionary type style request header |
| .body | Request content subject , String type |
| .meta | Extended information added by users , stay scrapy Information transfer between internal modules |
| .copy() | Copy the request |
2)response class class scrapy.http.Response()
It means a HTTP Respond to
from downloader Generate , from spider Handle
Seven common attributes and methods
| Properties or methods | explain |
|---|---|
| .url | Response Corresponding URL Address |
| .status | HTTP Status code , The default is 200 |
| .headers | Response Corresponding header information |
| .body | Response Corresponding content information , String type |
| .flag | A set of marks |
| .reques | produce Response The type corresponds to Request object |
| .copy() | Copy the request |
3)item class class scrapy.item.Item()
Item Object represents a slave HTML Information content extracted from the page
from spider Generate , from Item Pipline Handle
Defined by dictionary type ,, It is actually a dictionary like type , But you can operate according to the dictionary type
5.5 Information extraction method
scrapy Reptiles support a variety of HTML Information extraction method :
Beautiful Soup
Ixml
re
XPath Selector
CSS Selector
Basic use :
\<HTML>.css('a::attr(href)').extract()
a It's the label name ,attr(href) Is the tag attribute
Learn the cursory ending first !
I need to practice
Project practice , One by one !
Continue to learn later
边栏推荐
- Canoe: the difference between environment variables and system variables
- 三立期货安全么?期货开户怎么开?目前期货手续费怎么降低?
- Replace() function
- Automatic translation between Chinese and English
- Four sorts: bubble, select, insert, count
- Send a request using paste raw text
- Iptables cause heartbeat brain fissure
- LxC shared directory permission configuration
- For and while loops
- Application of slice
猜你喜欢
Using Lua to realize 99 multiplication table
QQ group collection

Failed to configure a DataSource: ‘url‘ attribute is not specified... Bug solution
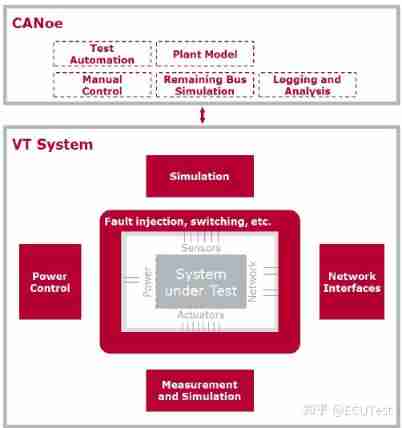
Canoe: what is vtsystem
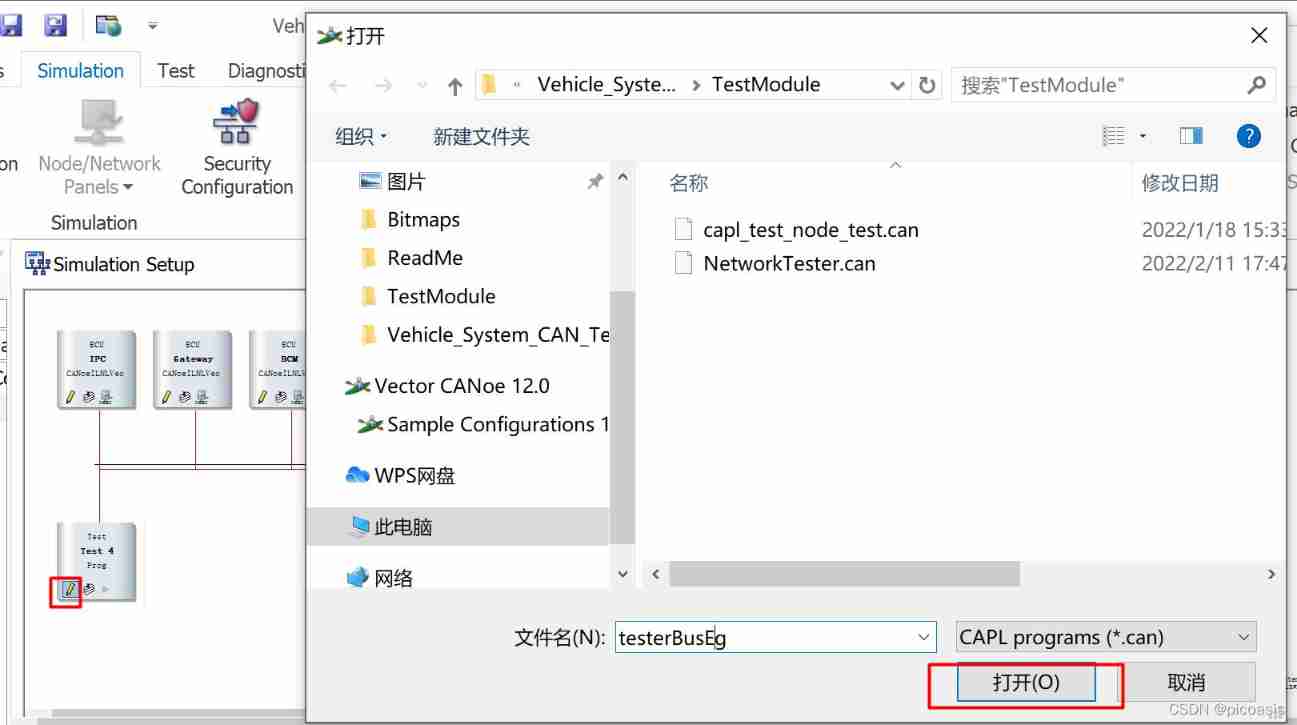
Canoe test: two ways to create CAPL test module
Replace() function
Take advantage of the world's sleeping gap to improve and surpass yourself -- get up early

SQL greatest() function instance detailed example
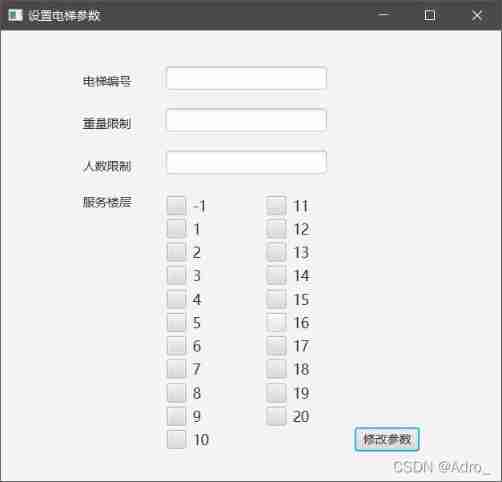
Elevator dispatching (pairing project) ②

What if the book written is too popular? Author of "deep reinforcement learning" at Peking University: then open the download
随机推荐
Summary of automated testing framework
Basic function exercises
Elevator dispatching (pairing project) ②
Locust learning record I
IO stream ----- open
Canoe the second simulation engineering xvehicle 3 CAPL programming (operation)
20 kinds of hardware engineers must be aware of basic components | the latest update to 8.13
Day01 preliminary packet capture
thread
F12 clear the cookies of the corresponding web address
MBG combat zero basis
2、 Operators and branches
Replace() function
First article
Global function Encyclopedia
Summary of Shanghai Jiaotong University postgraduate entrance examination module firewall technology
VPS安装Virtualmin面板
Object. Assign () & JS (= >) arrow function & foreach () function
Canoe - the third simulation project - bus simulation - 2 function introduction, network topology
Installation of ES plug-in in Google browser