当前位置:网站首页>Faster-ILOD、maskrcnn_ Benchmark training coco data set and problem summary
Faster-ILOD、maskrcnn_ Benchmark training coco data set and problem summary
2022-07-02 07:34:00 【chenf0】
loading annotations into memory...
Done (t=18.25s)
creating index...
index created!
number of images used for training: 31235
2022-06-05 03:17:10,191 maskrcnn_benchmark.trainer INFO: Start training
/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/structures/segmentation_mask.py:422: UserWarning: This overload of nonzero is deprecated:
nonzero()
Consider using one of the following signatures instead:
nonzero(*, bool as_tuple) (Triggered internally at /pytorch/torch/csrc/utils/python_arg_parser.cpp:766.)
item = item.nonzero()
/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
"https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [15,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [17,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [23,0,0] Assertion `t >= 0 && t < n_classes` failed.
Traceback (most recent call last):
File "tools/train_first_step.py", line 232, in <module>
main()
File "tools/train_first_step.py", line 224, in main
model = train(cfg, args.local_rank, args.distributed)
File "tools/train_first_step.py", line 103, in train
arguments,
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/engine/trainer.py", line 70, in do_train
loss_dict,_,_,_,_ = model(images, targets)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/apex-0.1-py3.7-linux-x86_64.egg/apex/amp/_initialize.py", line 197, in new_fwd
**applier(kwargs, input_caster))
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/detector/generalized_rcnn.py", line 67, in forward
x, result, detector_losses = self.roi_heads(features, proposals, targets)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/roi_heads/roi_heads.py", line 27, in forward
x, detections, loss_box = self.box(features, proposals, targets)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/roi_heads/box_head/box_head.py", line 55, in forward
loss_classifier, loss_box_reg = self.loss_evaluator([class_logits], [box_regression])
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/roi_heads/box_head/loss.py", line 151, in __call__
sampled_pos_inds_subset = torch.nonzero(labels > 0).squeeze(1)
RuntimeError: copy_if failed to synchronize: cudaErrorAssert: device-side assert triggered

The reason is that my training data set is 70,coco altogether 80 class
coco.py It's very clear in , I haven't seen it before haha , When the basic training category is 70 when ,first 70 categories Corresponding 1 ~ 79. take num_classes Change to 81 To run successfully
# first 40 categories: 1 ~ 44; first 70 categories: 1 ~ 79; first 75 categories: 1 ~ 85
# second 40 categories: 45 ~ 91; second 10 categories: 80 ~ 91; second 5 categories: 86 ~ 91
# totally 80 categories
边栏推荐
- Alpha Beta Pruning in Adversarial Search
- Cognitive science popularization of middle-aged people
- 離線數倉和bi開發的實踐和思考
- Oracle 11.2.0.3 handles the problem of continuous growth of sysaux table space without downtime
- 【模型蒸馏】TinyBERT: Distilling BERT for Natural Language Understanding
- 矩阵的Jordan分解实例
- PointNet理解(PointNet实现第4步)
- 机器学习理论学习:感知机
- parser.parse_args 布尔值类型将False解析为True
- 【信息检索导论】第七章搜索系统中的评分计算
猜你喜欢

【信息检索导论】第七章搜索系统中的评分计算
SSM二手交易网站
![[introduction to information retrieval] Chapter 1 Boolean retrieval](/img/78/df4bcefd3307d7cdd25a9ee345f244.png)
[introduction to information retrieval] Chapter 1 Boolean retrieval
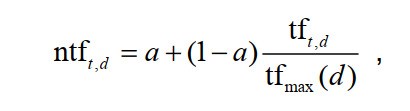
【信息检索导论】第六章 词项权重及向量空间模型
Using MATLAB to realize: Jacobi, Gauss Seidel iteration
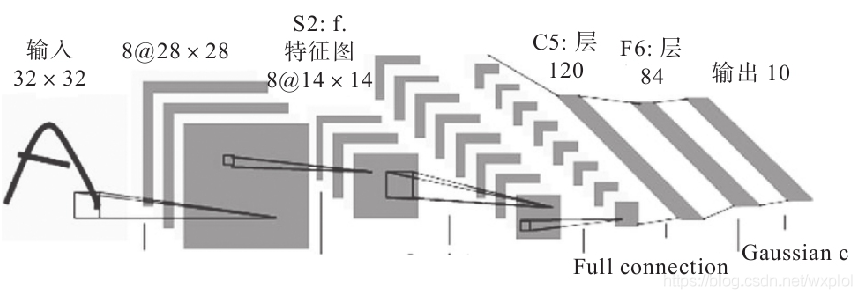
常见CNN网络创新点

类加载器及双亲委派机制

ERNIE1.0 与 ERNIE2.0 论文解读
Illustration of etcd access in kubernetes
Interpretation of ernie1.0 and ernie2.0 papers
随机推荐
聊天中文语料库对比(附上各资源链接)
软件开发模式之敏捷开发(scrum)
Convert timestamp into milliseconds and format time in PHP
Feeling after reading "agile and tidy way: return to origin"
Pyspark build temporary report error
矩阵的Jordan分解实例
使用 Compose 实现可见 ScrollBar
Oracle EBS database monitoring -zabbix+zabbix-agent2+orabbix
常见CNN网络创新点
[introduction to information retrieval] Chapter 1 Boolean retrieval
图片数据爬取工具Image-Downloader的安装和使用
Get the uppercase initials of Chinese Pinyin in PHP
Sparksql data skew
Faster-ILOD、maskrcnn_benchmark训练自己的voc数据集及问题汇总
離線數倉和bi開發的實踐和思考
Using compose to realize visible scrollbar
传统目标检测笔记1__ Viola Jones
使用Matlab实现:幂法、反幂法(原点位移)
Open failed: enoent (no such file or directory) / (operation not permitted)
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization