当前位置:网站首页>【信息检索导论】第三章 容错式检索
【信息检索导论】第三章 容错式检索
2022-07-02 06:25:00 【lwgkzl】
总览
本章主要解决以下几个问题:
- 根据用户的询问,如何找到用户询问中的词语对应的倒排表?
- 如果用户不记得某个单词怎么拼写,如何实现模糊查询(通配符查询)?
- 如果用户写错了某个字, 怎么样帮助他纠正,以便返回用户真正想查询的单词?
以上问题分别对应下面的三小节。
3.1 检索词项字典
前言:在前两章中,我们进行布尔查询都是直接默认根据用户查询的词项,就直接获取到了他的倒排表。但实际上,我们需要首先在词项词典中找到对应的词项,才能返回该词项对应的倒排表。对用户的query进行分词后,获取到待查询词项,我们首先要在词项词典中查找,最简单的方法当然是线性查找,不过这种方法时间复杂度 O ( n ) O(n) O(n)太高。当然我们可以将词项词典根据字典序排序,这样我们就可以愉快的使用二分查找 O ( l o g n ) O(logn) O(logn)了,然而事情并没有这么简单,如果是web检索的话,词表是需要不断更新的, 而如果需要保证词项词表有序的话, 每次更新词表也会造成巨大的性能浪费。所以接下来我们就介绍两种解决方案,帮助我们在词项词典中快速定位!
字符串哈希: 孟德曾言:“何以解忧,唯有哈希”,字符串哈希的作用是定义一个函数,将一个字符串映射到与其唯一对应的某个数字,在这里我们可以直接映射到内存地址,这样每来一个查询词项,我们经过哈希函数“唰”的一下就能找到词项对应的内存地址了,时间复杂度为 O ( 1 ) O(1) O(1),与词项词典的大小无关,不过太快也不是什么好事,尤其对于某些朋友而言,哈希函数有着以下的局限。
字符串哈希的局限:
- 随着词项字典的动态增加,发生冲突(多个字符串被该函数映射到同一个数字)的可能性会加大
- 字符串哈希无法处理下文所说的*“前缀查询”*,也就无法适配到下文所说的“通配符检索”
那么人们就期待出现一种完美的算法来解决这个问题,他既要能快速的查询,也要支持快速的动态插入。 他就是-------二叉搜索树:
二叉搜索树每个叶子节点都是一个字符串, 非叶子结点则作为划分节点,将小于该节点的字符串划分到左子树,将大于该节点的字符串划分到右子树(具体见算法导论)。二叉搜索树也可以看做是字符串的前缀树,可用于字符串的前缀检索。总而言之,二叉搜索树可以实现动态增加,并且检索效率是 O ( l o g n ) O(logn) O(logn),之后在简单二叉搜索树的基础上有了一些改进,其中平衡二叉树动态维持二叉搜索树的平衡,保证每次检索的时间复杂度都在 O ( l o g n ) O(logn) O(logn)左右,B-树将二叉树扩展为了多叉,每一个分支代表某一个区间的字符串,以便减轻平衡二叉树每次维护平衡时的开销。具体的算法介绍都请查询圣级魔导书 —《算法导论》。
3.2 通配符查询
当小明沉重的在输入框中缓缓打出 “马*梅” 的时候,他想了解的是一个伟大的英雄的英勇事迹,可惜小明忘记他的全名了,就记得他叫马什么梅。这个时候就需要模糊检索了,小明输入的中间这个*代表的是代替任何字符。这种查询叫做通配符查询。
a. 单个通配符查询
如果用户的查询中只包含一个通配符,在现有的词项检索技术中还是能够轻松解决的,如“马*梅”,那么我可以构造两颗二叉搜索树,一颗存储正向的词项(A),另一颗存储反转之后的词项(B)。那么我只需要在树A中检索以“马”为前缀的词项集合 以及 在树B中检索以“梅”为前缀的词项集合,然后对这两者取并集,就是马什么梅所对应的所有词项了。
b. 多个通配符查询
如果用户查询的包含多个通配符,如“马*梅*斯基”,这个时候我们就需要借助一些别的手段了。
轮排索引: 将单个词项的最后加上特殊字符$,并且将其轮转的所有形态都加入词项词典, 然后构造基于轮排词项词典的二叉搜索树。样例如下图所示:
这样做有什么好处呢,这个时候我们就可以查询“马*梅*斯基”了,首先将其转化为斯基$\马*梅*,然后在二叉搜索树中检索包含"斯基$\马"的词项(前缀检索),最后在检索得到的词项中,通过衡量检索到的词项中是否包含“梅”这个关键字来进行筛选,筛选后得到了最终的词项列表。
轮排索引的缺陷: 将原有大量词项成倍的扩增,因为他保存了原有的每个词项旋转的所有结果,让本就不富裕的计算机存储雪上加霜。
k-gram索引:
这种方法比较native, 是把单个词项的k-gram给抽出来词项,构成了k-gram词典,比如考虑词项 “马冬梅汽车斯基” 的2-gram, 则是【‘$马’,‘马东’,‘冬梅’…‘斯基’,‘基$’】为了标识开始结束位置,在开始和结束的位置都给他标上特殊字符$,那么词典中就包含了这么多项。然后根据通配符中的2-gram去检索对应的词项即可: 如“马*梅”,则变成了布尔检索的 “ 马 ” A N D “ 梅 马” AND “梅 马”AND“梅”,然后找到对应词项。
3.3 拼写纠正
终于来到拼写纠正了,显然用户在查询的时候由于输入法或者记忆偏差等种种原因,他有可能输错。比如小明查询了一个名字“马西梅”,显然在提瓦特大陆上并没有“马西梅”这个英雄的名字。这就引出了拼写纠正技术。
原则与步骤:
- 当用户检索关键词的信息过少时,我们可以认为他输错了信息,因此对他进行拼写纠正,并且提供纠正之后的词汇的搜索结果作为“拼写建议”。
- 对于一个拼写错误的词汇,我们需要找到正确拼写中与其距离其最近的词项。
- 如果有多个正确拼写的词项与该错误拼写距离最近,选择出现频率最大的词项作为最终的拼写结果
根据以上的原则和步骤,我们需要定义一个概念为错误词汇与正确词汇之间的*“距离”*由什么确定。
a. 词项独立的校正方法
这种方法针对的是用户输入错了单词,如上文所示,我们需要定义衡量错误词汇与正确词汇之间差距的标准,在此枚举两种方式。
编辑距离:第一种衡量方式为编辑距离,这个直接leetcode了解下吧, 链接
题目中这个最少操作次数,即为两个词汇的距离。
k-gram重合度:
同上,将词项拆解为k-gram之后,比较正确词汇和错误词汇的公共k-gram的数量,公共数量越多,则说明两个词汇距离越近。 比如考虑词项 “马冬梅” 的2-gram, 则是【‘$马’,‘马东’,‘冬梅’,‘梅$’】, 而错误词项“马西梅”的2-gram为【‘$马’,‘马东’,‘西梅’,‘梅$’】,显然,两者的距离是比较接近的。但是又有一个问题就是,如果词项的长度很长,可能会有一定偏差如有个词项为“马冬梅-罗伯斯别格-奥斯特洛夫斯基”,那么他和错误词汇“马西梅”的2-gram公共数量和“马冬梅”是一样的,显然从用户的角度“马冬梅”与“马西梅”的距离更近。为了考虑到这一点,我们使用一个指标为杰卡德系数。
雅可比系数: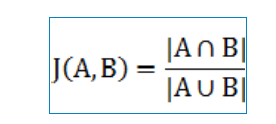
其中A,B分别是错误词汇与正确词汇的k-gram的集合。
b. 上下文敏感的校正方法
这种方法适用的情况是,用户输入的单词都是对的,但是组合起来的短语不是用户想表达的意思。如用户输入的是“飞翔科技的挖掘机”,当然检索出来就没有太多结果,但是其中“飞翔”,“科技”等词语都是正确的词汇。 这个时候我们就需要结合上下文把它规约成 “蓝翔科技”。目前传统的方法里面没有特别合适的方法, 比较暴力的做法是,将短语中的每一个词都尝试替换成与其距离相近的词,然后组合成新的短语,然后选择频率最高的短语即可。
c. 基于语音的校正方法
有一种语音哈希的方法为** soundex 算法**,可以将发音相似的词归为同一类。
总结
问题1. 根据用户的询问,如何找到用户询问中的词语对应的倒排表?
答案1: 二叉搜索树 或者 字符串哈希都可
问题2. 如果用户不记得某个单词怎么拼写,如何实现模糊查询(通配符查询)?
答案2: 使用轮排索引或者k-gram索引
问题3. 如果用户写错了某个字, 怎么样帮助他纠正,以便返回用户真正想查询的单词?
答案3: 使用编辑距离等算法纠正词项级别的错误, 基于词项级别的错误修改短语级别的错误。
本章知识图谱

边栏推荐
- Build FRP for intranet penetration
- Sqli-labs customs clearance (less1)
- CRP implementation methodology
- Anti shake and throttling of JS
- view的绘制机制(二)
- sparksql数据倾斜那些事儿
- The boss said: whoever wants to use double to define the amount of goods, just pack up and go
- 2021-07-17C#/CAD二次开发创建圆(5)
- ORACLE EBS ADI 开发步骤
- ORACLE 11G利用 ORDS+pljson来实现json_table 效果
猜你喜欢








随机推荐
sqli-labs通關匯總-page2
2021-07-05c /cad secondary development create arc (4)
pySpark构建临时表报错
php中判断版本号是否连续
view的绘制机制(三)
Alpha Beta Pruning in Adversarial Search
IDEA2020中PySpark的两表关联(字段名相同)
Network security -- intrusion detection of emergency response
ssm人事管理系统
Oracle EBs and apex integrated login and principle analysis
2021-07-05C#/CAD二次开发创建圆弧(4)
如何高效开发一款微信小程序
MySQL中的正则表达式
MySQL无order by的排序规则因素
Pyspark build temporary report error
spark sql任务性能优化(基础)
Yaml file of ingress controller 0.47.0
DNS攻击详解
Oracle段顾问、怎么处理行链接行迁移、降低高水位
How to call WebService in PHP development environment?