当前位置:网站首页>Go zero micro Service Practice Series (VII. How to optimize such a high demand)
Go zero micro Service Practice Series (VII. How to optimize such a high demand)
2022-06-28 15:17:00 【kevwan】
In the first two articles, we introduced various best practices for cache usage , First, we introduce the basic postures used by cache , How to use go-zero How to write the cache code in the automatically generated cache and logic code , Then I explained the penetration in the face of cache 、 breakdown 、 Solutions to common problems such as avalanches , Finally, it focuses on how to ensure cache consistency . Because caching is very important for high concurrency services , So we will continue to learn about caching in this article .
Local cache
When we encounter extreme hot data queries , At this time, local cache should be considered . The hotspot local cache is mainly deployed in the code of the application server , Used to block hotspot queries for Redis Equally distributed cache or database pressure .
In our mall , home page Banner There will be some advertising products or recommended products in the , The information of these commodities is entered and changed by the operation in the management background . The demand for these goods is very large , Even if it's Redis It's hard to carry , So here we can use local cache to optimize .

stay product Create a commodity operation table in the warehouse product_operation, For simplicity, keep only the necessary fields ,product_id To promote the goods of the operation id,status Is the status of the operating commodity ,status by 1 It will be on the home page Banner Show the product in .
CREATE TABLE `product_operation` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`product_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT ' goods id',
`status` int NOT NULL DEFAULT '1' COMMENT ' Operation commodity status 0- Offline 1- go online ',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ' Creation time ',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ' Update time ',
PRIMARY KEY (`id`),
KEY `ix_update_time` (`update_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=' Commodity operation table ';
The implementation of local caching is relatively simple , We can use map To do it on your own , stay go-zero Of collection Provided in Cache To realize the function of local cache , Let's just use it , It is never a wise choice to build the wheel repeatedly ,localCacheExpire Expiration time for local cache ,Cache Provides Get and Set Method , Very simple to use
localCache, err := collection.NewCache(localCacheExpire)
First look up from the local cache , If it hits the cache, it returns . If the cache is not hit, you need to query the operating bit commodity from the database first id, Then aggregate the product information , Finally, it is pushed back into the local cache . The detailed code logic is as follows :
func (l *OperationProductsLogic) OperationProducts(in *product.OperationProductsRequest) (*product.OperationProductsResponse, error) {
opProducts, ok := l.svcCtx.LocalCache.Get(operationProductsKey)
if ok {
return &product.OperationProductsResponse{Products: opProducts.([]*product.ProductItem)}, nil
}
pos, err := l.svcCtx.OperationModel.OperationProducts(l.ctx, validStatus)
if err != nil {
return nil, err
}
var pids []int64
for _, p := range pos {
pids = append(pids, p.ProductId)
}
products, err := l.productListLogic.productsByIds(l.ctx, pids)
if err != nil {
return nil, err
}
var pItems []*product.ProductItem
for _, p := range products {
pItems = append(pItems, &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
})
}
l.svcCtx.LocalCache.Set(operationProductsKey, pItems)
return &product.OperationProductsResponse{Products: pItems}, nil
}
Use grpurl Debug tool request interface , First request cache miss after , Subsequent requests will hit the local cache , When the local cache expires, it will go back to the source again db Load data into local cache
~ grpcurl -plaintext -d '{}' 127.0.0.1:8081 product.Product.OperationProducts
{
"products": [
{
"productId": "32",
"name": " Electric fan 6"
},
{
"productId": "31",
"name": " Electric fan 5"
},
{
"productId": "33",
"name": " Electric fan 7"
}
]
}
Be careful , Not all information is suitable for local caching , The characteristic of local cache is that the request volume is very high , At the same time, certain inconsistencies can be allowed in business , Because the local cache generally does not take the initiative to update , You need to wait until it expires and go back to the source db Update later . Therefore, in the business, it depends on the situation to see whether the local cache is required .
Automatically identify hotspot data
home page Banner Scenarios are configured by operators , That is, we can know the hot data that may be generated in advance , But in some cases, we can not predict in advance that data will become a hot spot . So we need to be able to identify these hot data adaptively and automatically , Then promote the data to the local cache .
We maintain a sliding window , For example, the sliding window is set to 10s, It's about statistics 10s What's inside key Accessed by high frequency , One sliding window corresponds to multiple Bucket, Every Bucket Corresponding to one in map,map Of key For commodities id,value The number of requests corresponding to the product . Then we can do it regularly ( such as 10s) To count all the current Buckets Medium key The data of , Then import the data into the big top heap , It's easy to get from the big top pile topK Of key, We can set a threshold , For example, a certain time in a sliding window key Visit frequency exceeds 500 Time , Just think the key As a hot spot key, So that the key Upgrade to local cache .
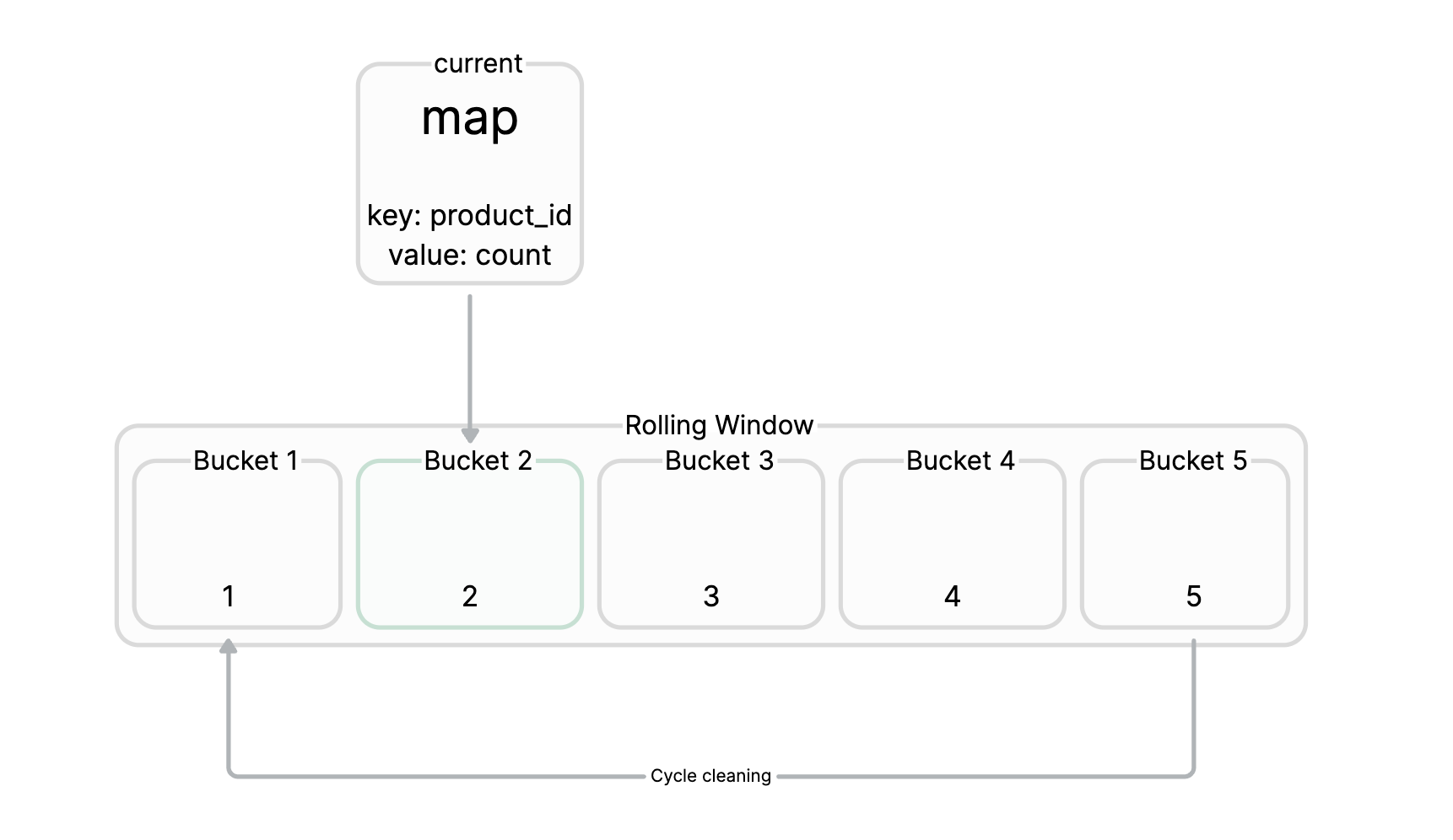
Cache usage tips
Here are some tips for caching
- key Try to make the naming easy to read , That is to say, you can see the name and know the meaning , The length should be as small as possible on the premise that it is easy to read , To reduce the occupation of resources , about value You can use int Try not to use string, For less than N Of value,redis Internal shared_object cache .
- stay redis Use hash In the case of key The split , The same hash key Will fall into the same redis node ,hash Too large will lead to uneven distribution of memory and requests , Consider right hash Split into small hash, Make the node memory uniform to avoid single node request hotspots .
- To avoid nonexistent data requests , Cause each request to be cached miss Directly into the database , Set the empty cache .
- When objects need to be stored in the cache , Serialization try to use protobuf, Minimize data size .
- When adding new data, ensure that the cache must exist before adding , Use Expire To determine whether the cache exists .
- The need to store daily login scenarios , have access to BITSET, To avoid a single BITSET Too big or hot , Can be done sharding.
- In the use of sorted set When , Avoid using zrange perhaps zrevrange Returns a collection that is too large , High complexity .
- Try to use when caching PIPELINE, But also pay attention to avoid too large a collection .
- Avoid oversized value.
- Try to set the expiration time for the cache .
- Use the full operation command with caution , such as Hash Type of HGETALL、Set Type of SMEMBERS etc. , These operations will affect Hash and Set Full scan of the underlying data structure , If there is a large amount of data , It will block Redis The main thread .
- To get the full data of a collection type, you can use SSCAN、HSCAN Wait for the command to return the data in the set in batches , Reduce blocking of main threads .
- Use with caution MONITOR command ,MONITOR The command will continuously write the monitored content to the output buffer , If there are many online commands , The output buffer will overflow soon , Would be right Redis Performance impact .
- The production environment is disabled KEYS、FLUSHALL、FLUSHDB Wait for the order .
Conclusion
This article introduces how to use local hotspot cache to deal with ultra-high requests , Hotspot cache is divided into known hotspot cache and unknown hotspot cache . Known hotspot caches are simple , Load from the database into memory in advance , Unknown hotspot cache we need to adaptively identify the hotspot data , Then upgrade the data of these hotspots to local cache . Finally, some tips for caching in actual production are introduced , Be flexible in the production environment and try to avoid problems .
I hope this article can help you , thank you .
Every Monday 、 Thursday update
Code warehouse : https://github.com/zhoushuguang/lebron
Project address
https://github.com/zeromicro/go-zero
https://gitee.com/kevwain/go-zero
Welcome to use go-zero and star Support us !
WeChat ac group
Focus on 『 Microservice practice 』 Official account and click Communication group Get community group QR code .
边栏推荐
- Steve Jobs of the United States, died; China jobs, sold
- 一个bug肝一周...忍不住提了issue
- SQL statement exercises
- 动力电池,是这样被“瓜分”的
- 扩充C盘(将D盘的内存分给C盘)
- Li Kou today's question -522 Longest special sequence
- 3. caller service call - dapr
- S2b2c system website solution for kitchen and bathroom electrical appliance industry: create s2b2c platform Omni channel commercial system
- 智慧园区数智化供应链管理平台如何优化流程管理,驱动园区发展提速增质?
- Oracle11g database uses expdp to back up data every week and upload it to the backup server
猜你喜欢

Steve Jobs of the United States, died; China jobs, sold

3. caller service call - dapr

Jackie Chan and fast brand, who is the Savior of Kwai?
完整的模型训练套路(一)
Leetcode 48. Rotate image (yes, resolved)

GBASE南大通用亮相第六届世界智能大会
![[C language] implementation of binary tree and three Traversals](/img/9f/384a73fb82265a76fc5eef884ce279.png)
[C language] implementation of binary tree and three Traversals

环保产品“绿色溢价”高?低碳生活方式离人们还有多远

How can the digital intelligent supply chain management platform of the smart Park optimize process management and drive the development of the park to increase speed and quality?

MIPS assembly language learning-01-sum of two numbers, environment configuration and how to run
随机推荐
DBMS in Oracle_ output. put_ Line output problem solving process
使用Karmada实现Helm应用的跨集群部署
ROS knowledge points - ROS create workspace
Li Kou today's question -522 Longest special sequence
How to build a 100000 level QPS large flow and high concurrency coupon system from zero
ROS知识点——使用VScode搭建ROS开发环境
With 120billion yuan, she will ring the bell for IPO again
论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
Calculator (force buckle)
SQL statement exercises
买卖股票的最佳时机
Complete model training routine (I)
The hidden crisis of Weilai: past, present and future
WSUS客户端访问服务端异常报错-0x8024401f「建议收藏」
Flutter dart语言特点总结
R语言ggplot2可视化:使用patchwork包(直接使用加号+)将一个ggplot2可视化结果和一段文本内容横向组合起来形成最终结果图
[C language] implementation of binary tree and three Traversals
New offline retail stores take off against the trend, and consumption enthusiasm under the dark cloud of inflation
隐私计算 FATE - 离线预测
Power battery is divided up like this