当前位置:网站首页>Spark概述
Spark概述
2022-07-02 05:49:00 【懒猫gg】
前言
MR计算模型已经可以满足所有的计算需求了。但其对于一些复杂的计算要经过多个Map或者reduce, 中间步骤读写HDFS。而这些中间数据是不被用户关心的,spark提出RDD计算模型, 不同于MR的是中间输出结果可以保存在内存中。
安装
spark的安装方式有几种,这边选用docker的方式
docker pull apache/spark-py:v3.2.1
docker run -it -d --name pyspark \
-p 4000:4000 \
--volume /Users/xxx/Public/spark:/opt/spark/work-dir \
apache/spark-py:v3.1.3 /bin/bash
架构
Spark应用程序由一个driver进程(驱动程序)和一组Executor进程组成。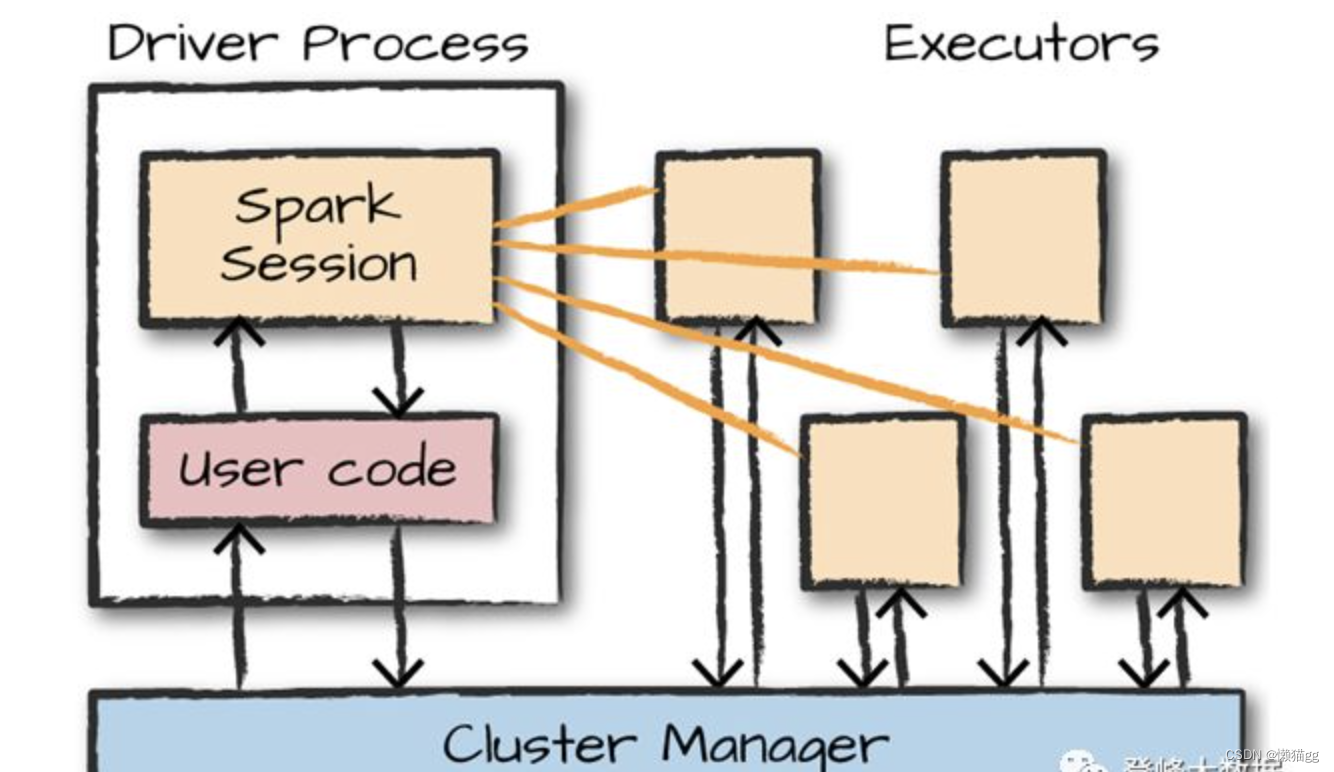
driver是管理进程,位于集群中的一个节点上。负责三件事:
- 维护有关Spark应用程序的信息;
- 响应用户的程序或输入,通过SparkSession的与用户输入的代码进行交互。
- 分析、分配和调度executor的工作。当碰到“行为”代码时触发, 即解析用户代码,形成任务计算,分配资源情况进行调度
executors进程实际执行driver分配给他们的工作。只负责两件事:
- 执行由驱动程序分配给它的代码,
- 并将执行器executor的计算状态报告给驱动(driver)节点。
Spark除了集群cluster模式之外,还具有本地local模式。
- 集群cluster模式: driver驱动程序和executor执行器是简单的进程,这意味着它们可以在同一台机器或不同的机器上运行。
- 在本地local模式中:驱动程序和执行程序(作为线程)在您的个人计算机上运行,而不是集群。
数据模型
从Spark版本的来看主要产生三个版本:
RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6)
RDD
RDD是分布式的Java对象的集合, 存储本身不关心数据本身结构,只要在执行时,通过代码解析数据行进行识别,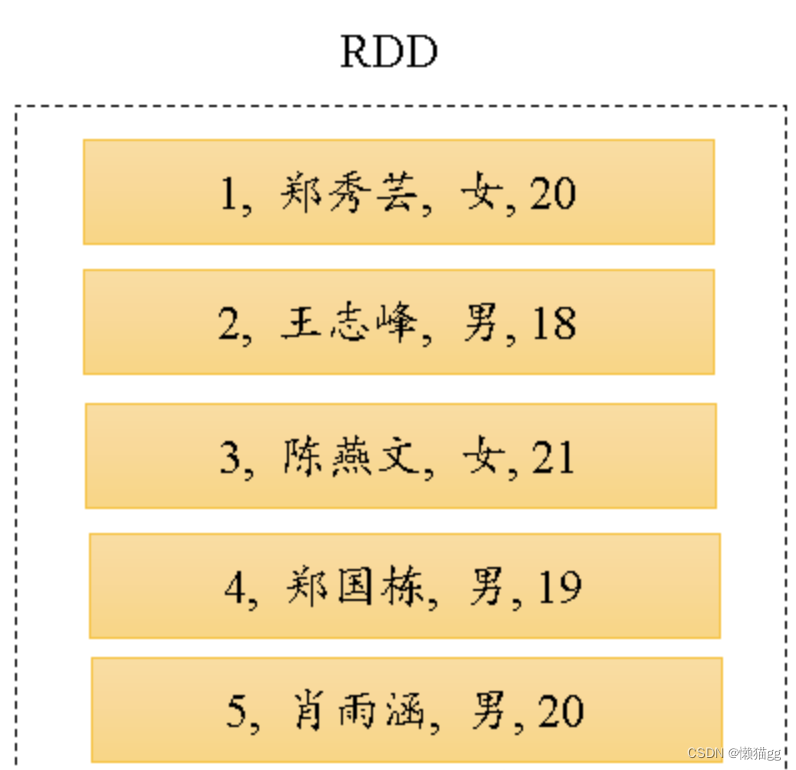
Dataframe
DataFrame在RDD的基础上添加了数据描述信息(Schema,即元信息),因此看起来更像是一张数据库表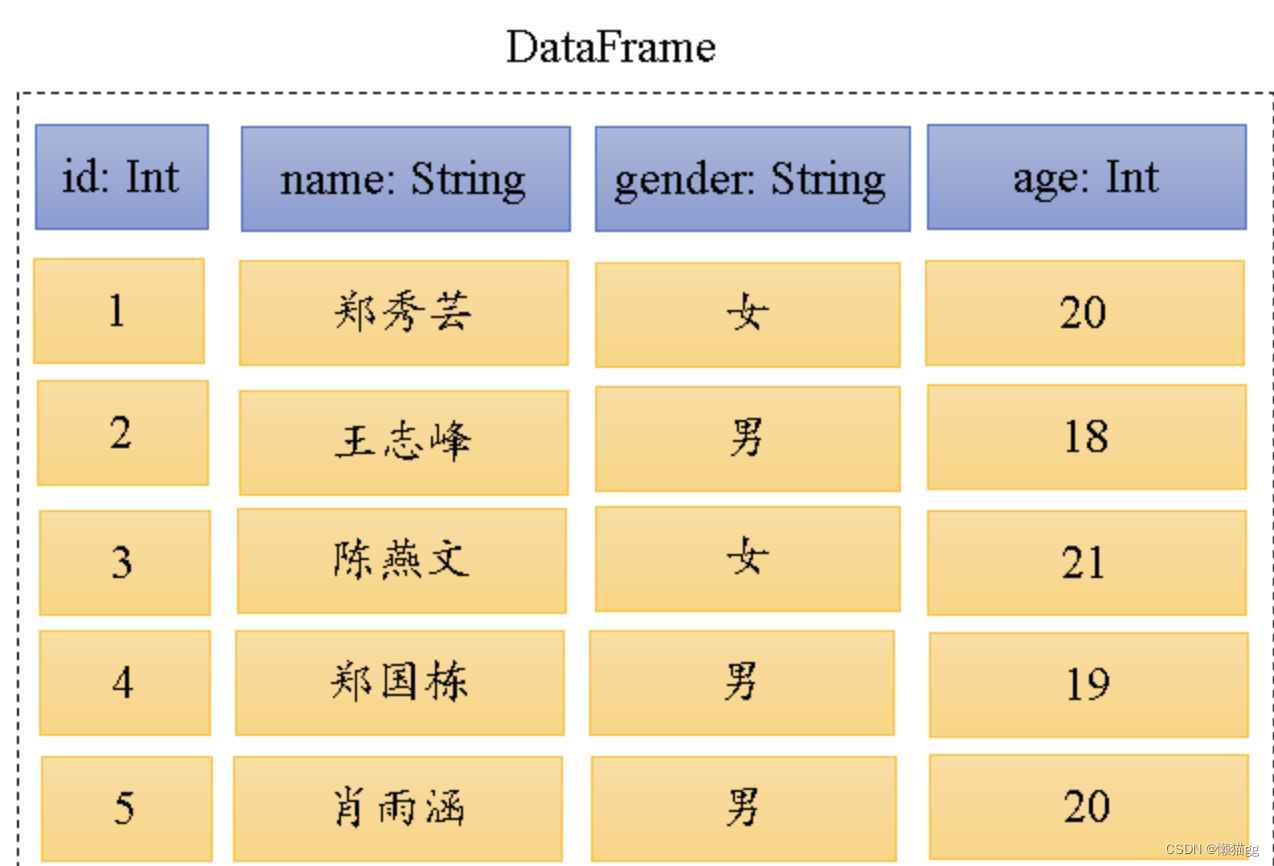
Dataset
在RDD的每行数据加了类型约束。它是强类型的,它包含的每一个元素已由case class定义,每一个属性的类型都是确定的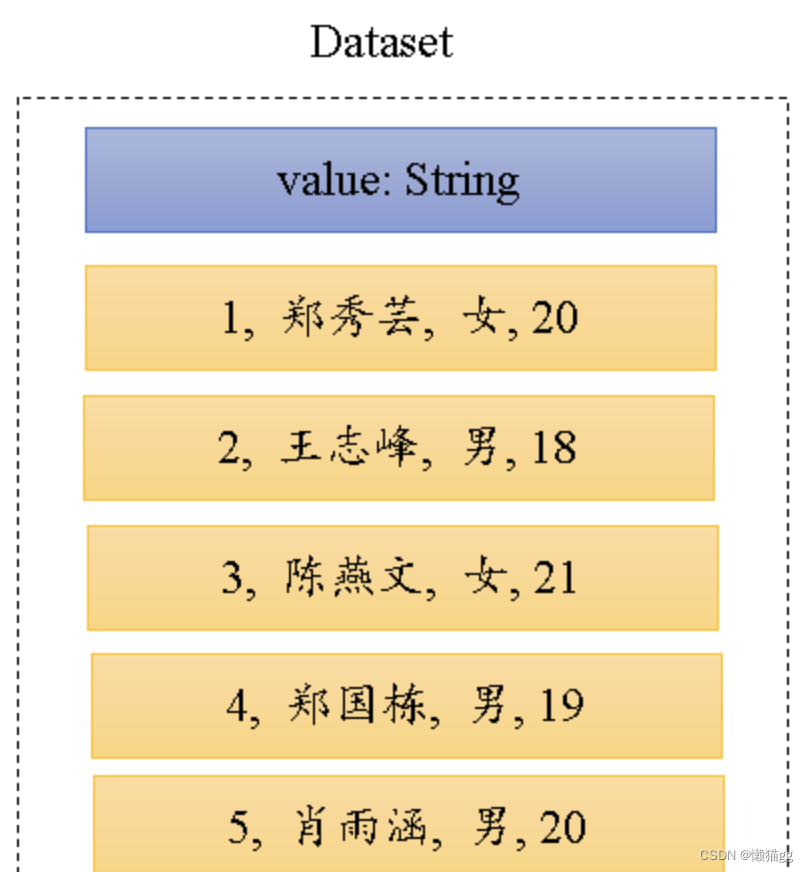
一个DataFrame所代表的是一个元素类型为Row的Dataset,即DataFrame只是Dataset[Row]的一个类型别名
三者对比

那么什么时候需要使用DataSet或者DataFrame,而不是RDD呢?
- 如果你需要丰富的语义、高级抽象和特定领域专用的 API,那就使用 DataFrame 或 Dataset;
- 如果你的处理需要对半结构化数据进行高级处理,如 filter、map、aggregation、average、sum、SQL 查询、列式访问或使用 lambda 函数,那就使用 DataFrame 或 Dataset;
- 如果你想在编译时就有高度的类型安全,想要有类型的 JVM 对象,用上 Catalyst 优化,那就使用 Dataset;
- 如果你想在不同的 Spark 库之间使用一致和简化的 API,那就使用 DataFrame 或 Dataset;
三者转换
# rdd
val input = List("zhangshan 18","lisi 22","wangwu 19","zhaoliu 21")
val rdd = sc.parallelize(input)
# rdd to df
val df = rdd.map(line => {
val strings = line.split(" ")
(strings(0), strings(1).toInt)
}).toDF("name", "age")
# rdd to ds
val ds = rdd.map(line => {
val strings = line.split(" ")
Person(strings(0), strings(1).toInt)
}
).toDS()
# df to ds
val toDS = df.as[Person]
# ds to df
val toDF = ds.toDF()
# to rdd
val dftordd = df.rdd
val dstordd = ds.rdd
RDD分区
为了使每个executor执行器并行执行任务,Spark将数据分解成块,这些数据块称为partition(分区).
- 可以创建的时候指定分区数
- 可以定义分区规则, Partitioner
Spark会对文件进行分片操作(类似于MapReduce的分片,实际上调用的是MapReduce的分片接口),分片操作完成后,每个分区将存储一个分片的数据,因此分区的数量等于分片的数量。
计算模型
在Spark中,核心数据结构是不可变的,这意味着它们在创建之后无法更改。乍一看,这似乎是个奇怪的概念: 如果你不能改变它,你应该如何使用它? 要“更改”一个DataFrame,您需要指导Spark如何修改它以实现您想要的功能。这些指导指令称为Transformations转换。每一次Transformations转换就是RDD的每一次转化操作。对RDD的每一次操作都会生成一个新的RDD,由于RDD的懒加载特性,新的RDD会依赖原有RDD,因此RDD之间存在类似流水线的前后依赖关系。这种依赖关系分为两种:窄依赖和宽依赖。
窄依赖是指父RDD的一个分区最多被子RDD的一个分区所用。也就是说,父RDD的分区与子RDD的分区的对应关系为一对一或多对一。例如,map()、filter()、union()、join()等操作都会产生窄依赖。
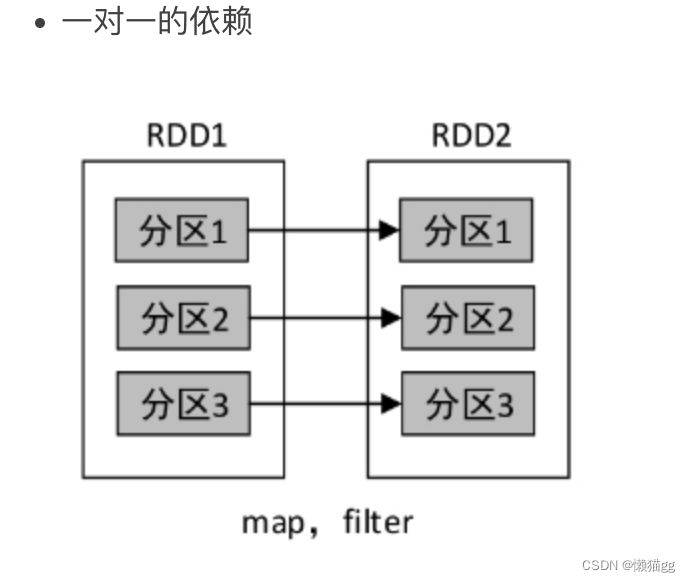
宽依赖是指父RDD的一个分区被子RDD的多个分区所用。也就是说,父RDD的分区与子RDD的分区的对应关系为多对多。例如,groupByKey()、reduceByKey()、sortByKey()等操作都会产生宽依赖。

在数据容错方面,窄依赖要优于宽依赖。当子RDD的某一个分区的数据丢失时,若是窄依赖,则只需重算和该分区对应的父RDD分区即可,而宽依赖需要重算父RDD的所有分区。在groupByKey()操作中,若RDD2的分区1丢失,则需要重新计算RDD1的所有分区(分区1、分区2、分区3)才能对其进行恢复。此外,宽依赖在进行Shuffle之前,需要计算好所有父分区的数据,若某个父分区的数据未计算完毕,则需要等待。
transformation转换允许我们构建逻辑转换计划。为了触发计算,我们运行一个action操作。action操作指示Spark通过执行一系列transformation转换计算结果。这一系列的换会会生成有向无环图任务
- Spark会根据DAG将整个计算划分为多个阶段,每个阶段称为一个Stage。每个Stage由多个Task任务并行进行计算,每个Task任务作用在一个分区上,一个Stage的总Task任务数量是由Stage中最后一个RDD的分区个数决定的。
- Stage的划分依据为是否有宽依赖,即是否有Shuffle。Spark调度器会从DAG图的末端向前进行递归划分,遇到Shuffle则进行划分,Shuffle之前的所有RDD组成一个Stage,整个DAG图为一个Stage。
经典的单词计数执行流程的Stage划分如下图所示
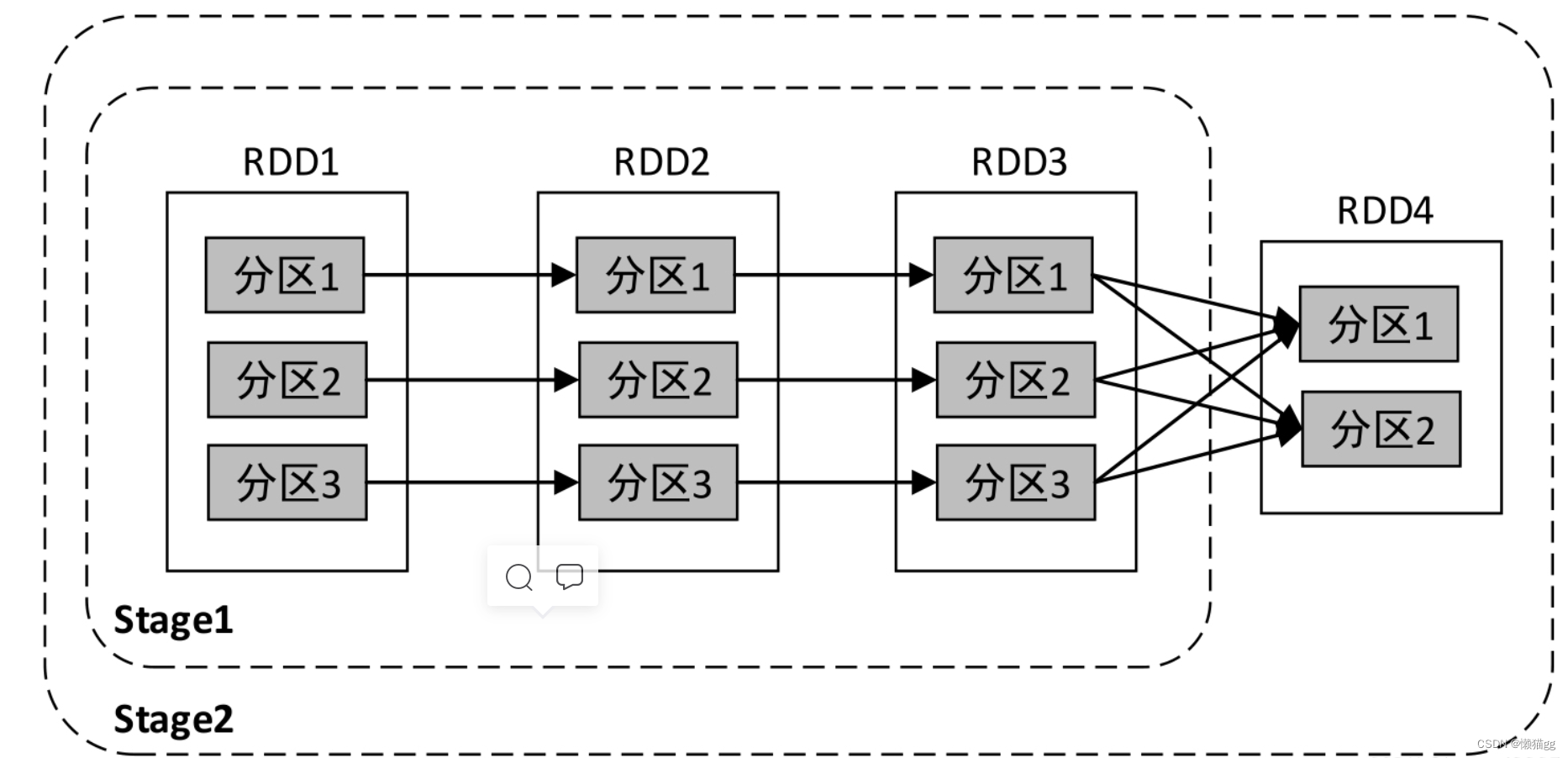
上图中的依赖关系一共可以划分为两个Stage:从后向前进行递归划分,RDD3到RDD4的转换是Shuffle操作,因此在RDD3与RDD4之间划开,继续向前查找,RDD1、RDD2、RDD3之间的关系为窄依赖,因此为一个Stage;整个转换过程为一个Stage。
Join算法
Join 的常见算法:
- Nested Loop Join
- Sort Merge Join
- Hash Join(8.0 mysql加入)
分布式系统实现 Join 数据分布的常见策略有:
- Broadcast Join
- Shuffle Join
- Colocate/Local Join
Broadcast Join
把A表广播到所有B表分区所在节点,然后根据A的join key构建Hash Table,把每一行记录都存进HashTable. 适用A表是小表的情况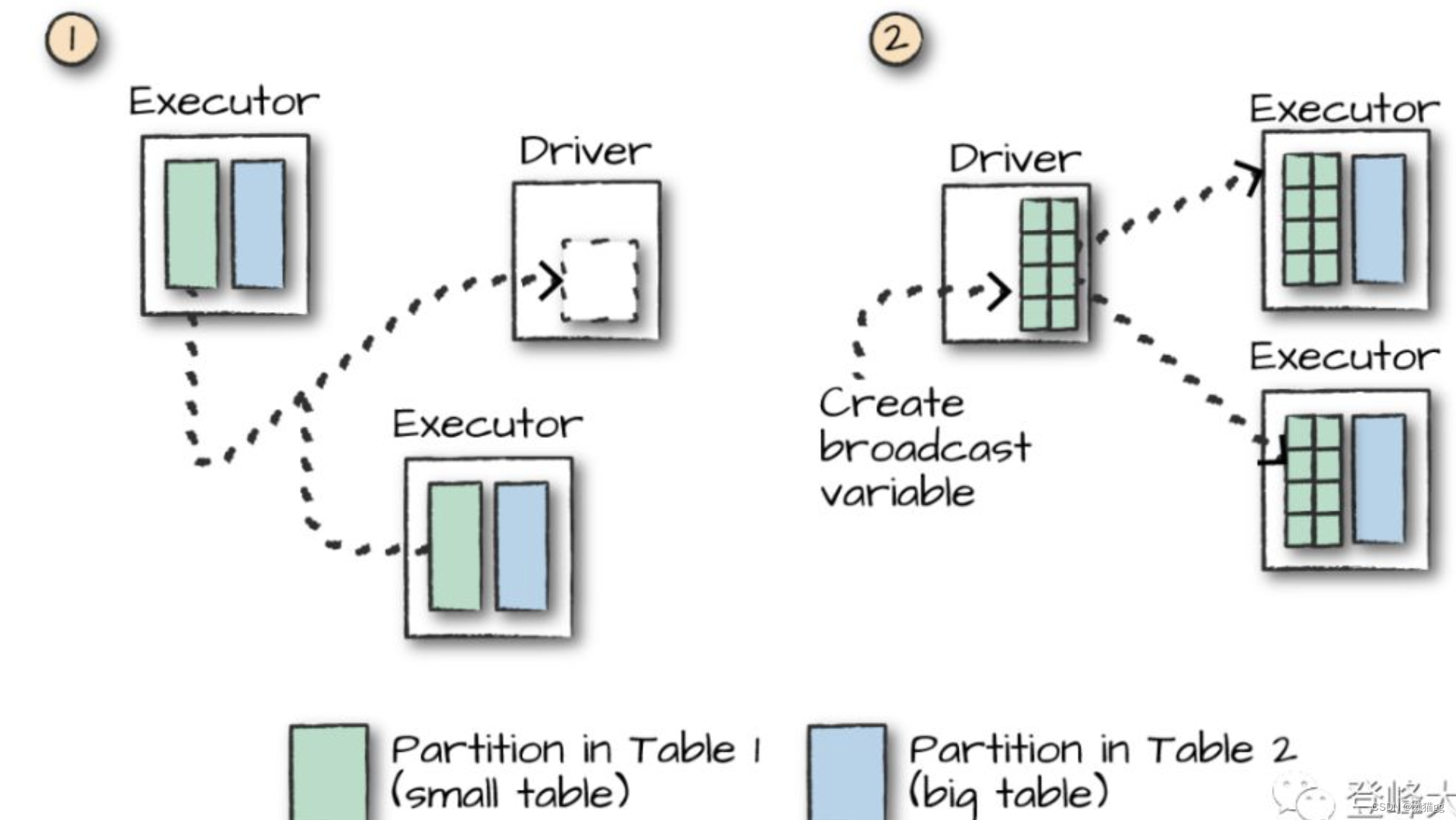
我们在开始时只执行一次,然后让每个单独的工作节点执行工作,而不必等待或与任何其他工作节点通信,
Shuffle Join
将A,B表 具有相同性质的(如Hash值相同)join key 进行Shuffle到同一个分区。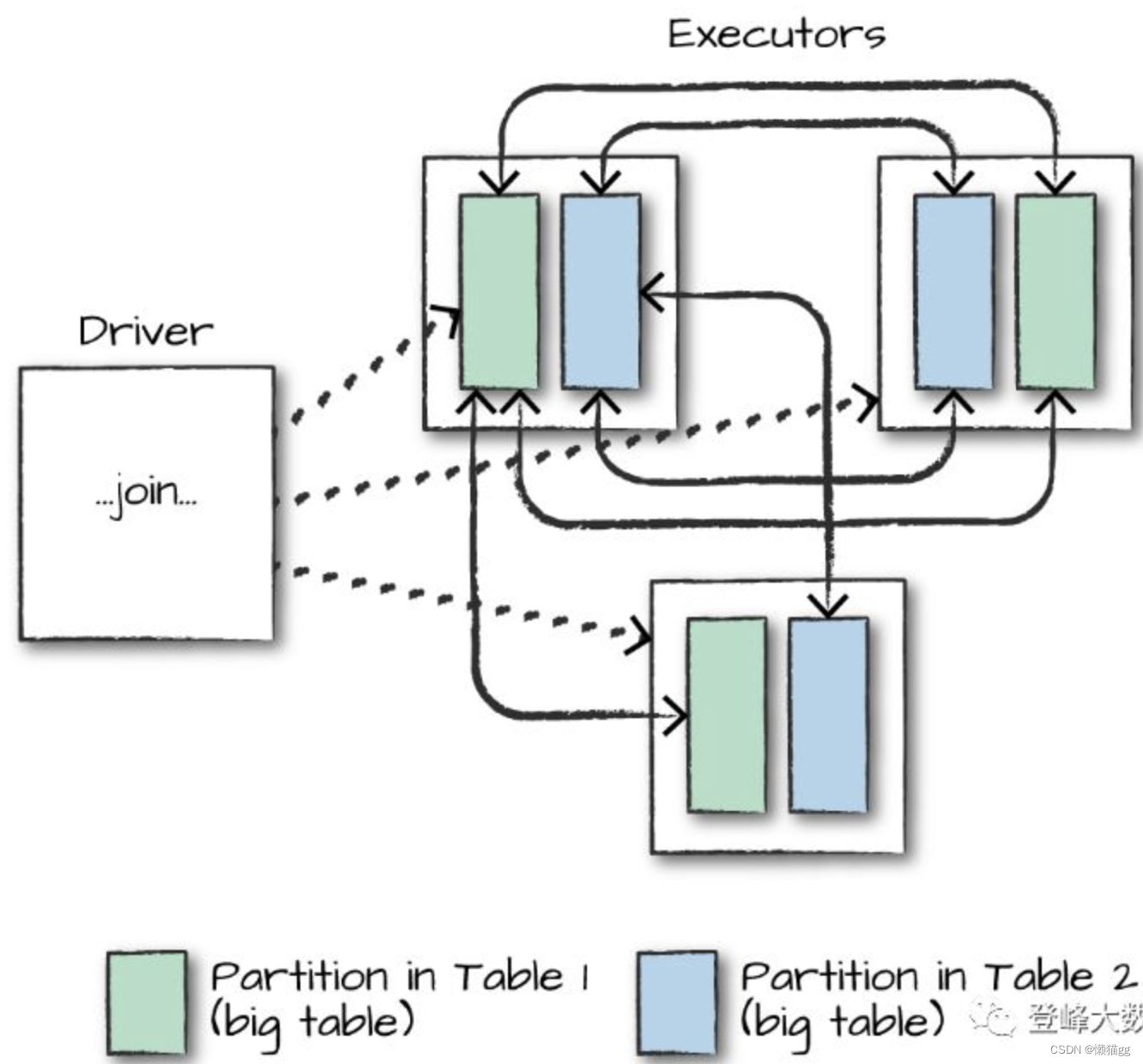
Colocate/Local Join
通人数据合理的分区, 让多个节点 Join 时没有数据移动和网络传输,每个节点只在本地进行 Join,能够本地进行 Join 的前提是相同 Join Key 的数据分布在相同的节点。
Spark SQL
在spark引挚基础之上,还可以构建其它的应用。
Spark SQL 是在 spark RDD弹性计算之前 构建的SQL方案。他的语法完全兼容 Hive SQL 。 因此可以直接在HIVE中使用。
即写个解析程序,把SQL解析成Spark语言
Spark Streaming
Spark流是对于Spark核心API的拓展,从而支持对于实时数据流的可拓展,高吞吐量和容错性流处理。数据可以由多个源取得,例如:Kafka,Flume,Twitter,ZeroMQ,Kinesis或者TCP接口,同时可以使用由如map,reduce,join和window这样的高层接口描述的复杂算法进行处理。最终,处理过的数据可以被推送到文件系统,数据库和HDFS。
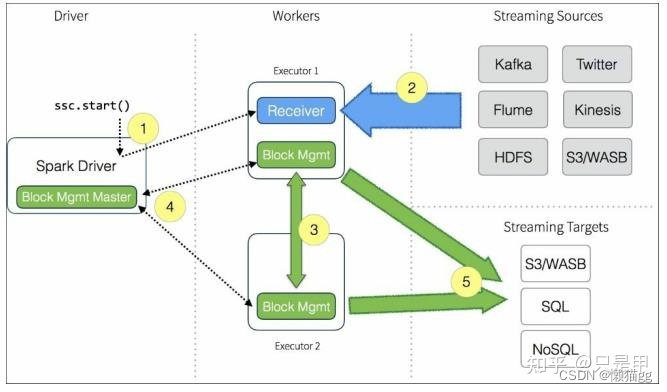
Spark Streaming架构

- Client:负责向Spark Streaming中输入数据(flume kafka)
- Worker:从Client接收数据, 根据规则(如每1秒)生成RDD,并将RDD对应的blocId报告给master
- Master:记录.Dstream之间的依赖关系或者血缘关系(blocId序列 ),然后生成任务DAG计算得出新的RDD
public class WorldCount {
public static void main(String[] args) throws InterruptedException {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
wordCounts.print();
jssc.start(); // Start the computation
jssc.awaitTermination(); // Wait for the computation to terminate
}
}
## 使用命令向spark stream提交任务
spark-submit \
--class WorldCount \
--master local[2] \
/home/javaspark/SparkStudy-1.0-SNAPSHOT.jar
## 使用 nc命令向 stream发数据
$ nc -lk 9999
hello world
Spark Streaming的组件介绍
Spark Streaming的核心组件有2个:
- Streaming Context
- Dstream(离散流)
Streaming Context
Streaming Context是Spark Streaming程序的起点,生成Streaming Context之前需要生成SparkContext,SparkContext可以理解为申请Spark集群的计算资源,Streaming Context可以理解为申请Spark Streaming的计算资源
Dstream(离散流)
Dstream是Spark Streaming的数据抽象,同DataFrame,其实底层依旧是RDD。
Discretized Stream或DStream是Spark Streaming提供的基本抽象。它表示一个连续的数据流,要么是从源接收的输入数据流,要么是通过转换输入流生成的处理数据流。在内部,DStream由一系列连续的rdd表示,这是Spark对不可变的分布式数据集的抽象。DStream中的每个RDD都包含一定时间间隔的数据,如下图所示:
在DStream上应用的任何操作都转换为在底层rdd上的操作。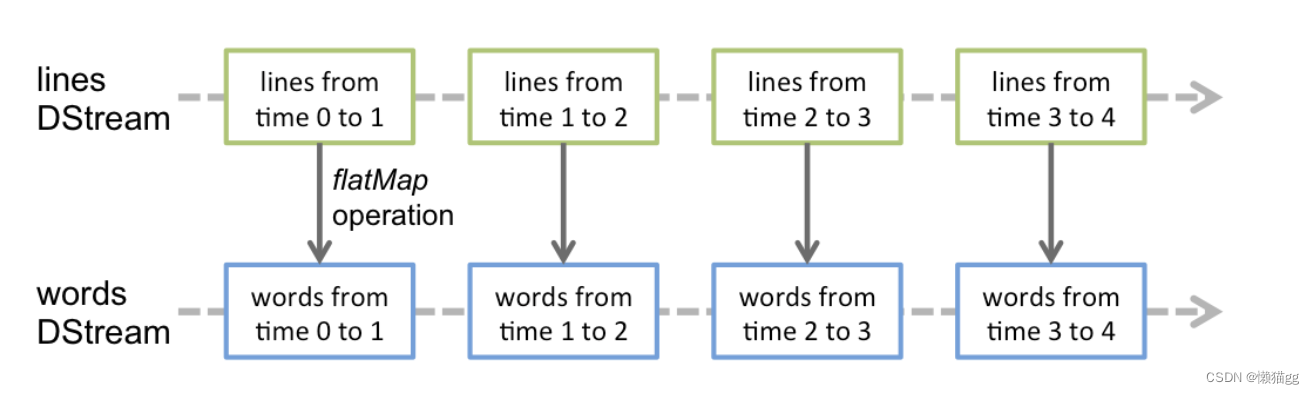
这些底层RDD转换是由Spark引擎计算的。DStream操作隐藏了大部分细节,并为开发人员提供了更高级的API。
Receiver
每个输入DStream(文件流除外)都与一个Receiver (Scala doc, Java doc)对象相关联,接收来自源的数据并将其存储在Spark的内存中进行处理。
Spark Streaming提供了两类内置流源: 1) 基本源:在StreamingContext API中直接可用的源。例如文件系统和套接字连接。 2) 高级资源:像Kafka, Kinesis等资源可以通过额外的实用程序类获得。这些需要根据链接部分中讨论的额外依赖项进行链接。
注意,如果希望在流应用程序中并行接收多个数据流,可以创建多个输入Dstream。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark worker/executor是一个长期运行的任务,因此它占用分配给Spark Streaming应用程序的一个核心。因此,Spark Streaming应用程序需要分配足够的内核(或者线程,如果在本地运行的话)来处理接收到的数据,以及运行接收端,记住这一点很重要。
可靠性

接收器把数据流打包成块,存储在executor的内存中,如果开启了WAL,将会把数据写入到存在容错文件系统的日志文件中。
接收到的数据块的元信息发送给driver中的StreamingContext,这些元数据包括:executor内存中数据块的引用ID和日志文件中数据块的偏移信息。
每一个批处理间隔,StreamingContext使用块信息用来生成RDD和jobs,SparkContext执行这些job用于处理executor内存中的数据块。
以便于恢复,流式处理会周期的被checkpoint到文件中。
主要参考
《Spark权威指南(中文版)》
《spark官网文档》
《Spark基础学习笔记》
《Java-Spark系列7-Spark streaming介绍》
《Spark Streaming Programming Guide》
《Spark Streaming(一)简介与架构》
边栏推荐
- idea開發工具常用的插件合集匯總
- How to write good code - Defensive Programming Guide
- With an amount of $50billion, amd completed the acquisition of Xilinx
- [PHP是否安装了 SOAP 扩]对于php实现soap代理的一个常见问题:Class ‘SoapClient‘ not found in PHP的处理方法
- 文件包含漏洞(二)
- Zzuli:1064 encrypted characters
- Win10 copy files, save files... All need administrator permission, solution
- php按照指定字符,获取字符串中的部分值,并重组剩余字符串为新的数组
- Innovation never stops -- the innovation process of nvisual network visualization platform for Excel import
- Matplotlib double Y axis + adjust legend position
猜你喜欢

Brew install * failed, solution
Oled12864 LCD screen

正则表达式总结
Record sentry's path of stepping on the pit

With an amount of $50billion, amd completed the acquisition of Xilinx
我所理解的DRM显示框架
File contains vulnerabilities (II)

Cambrian was reduced by Paleozoic venture capital and Zhike shengxun: a total of more than 700million cash

“简单”的无限魔方

Pytorch Basics
随机推荐
Principle and implementation of parallax effect
vite如何兼容低版本浏览器
数理统计与机器学习
Brew install * failed, solution
PHP 开发与测试 Webservice(SOAP)-Win
XSS basic content learning (continuous update)
php读文件(读取文件内含有某字符串的指定行)
中小型项目手撸过滤器实现认证与授权
Visual Studio导入
Reflection of the soul of the frame (important knowledge)
数据挖掘方向研究生常用网站
Zzuli:1067 faulty odometer
Software testing - concept
Test case
Fabric. JS compact JSON
Typora installation (no need to enter serial number)
Fabric. JS free draw rectangle
centos8安装mysql8.0.22教程
php内的addChild()、addAttribute()函数
How to write good code - Defensive Programming Guide