当前位置:网站首页>Dom4J解析XML、Xpath检索XML
Dom4J解析XML、Xpath检索XML
2022-07-01 18:43:00 【斯文~】
概述
两种解析方式
1.SAX解析
2.DOM解析
Dom常见的解析工具
DOM解析解析文档对象模型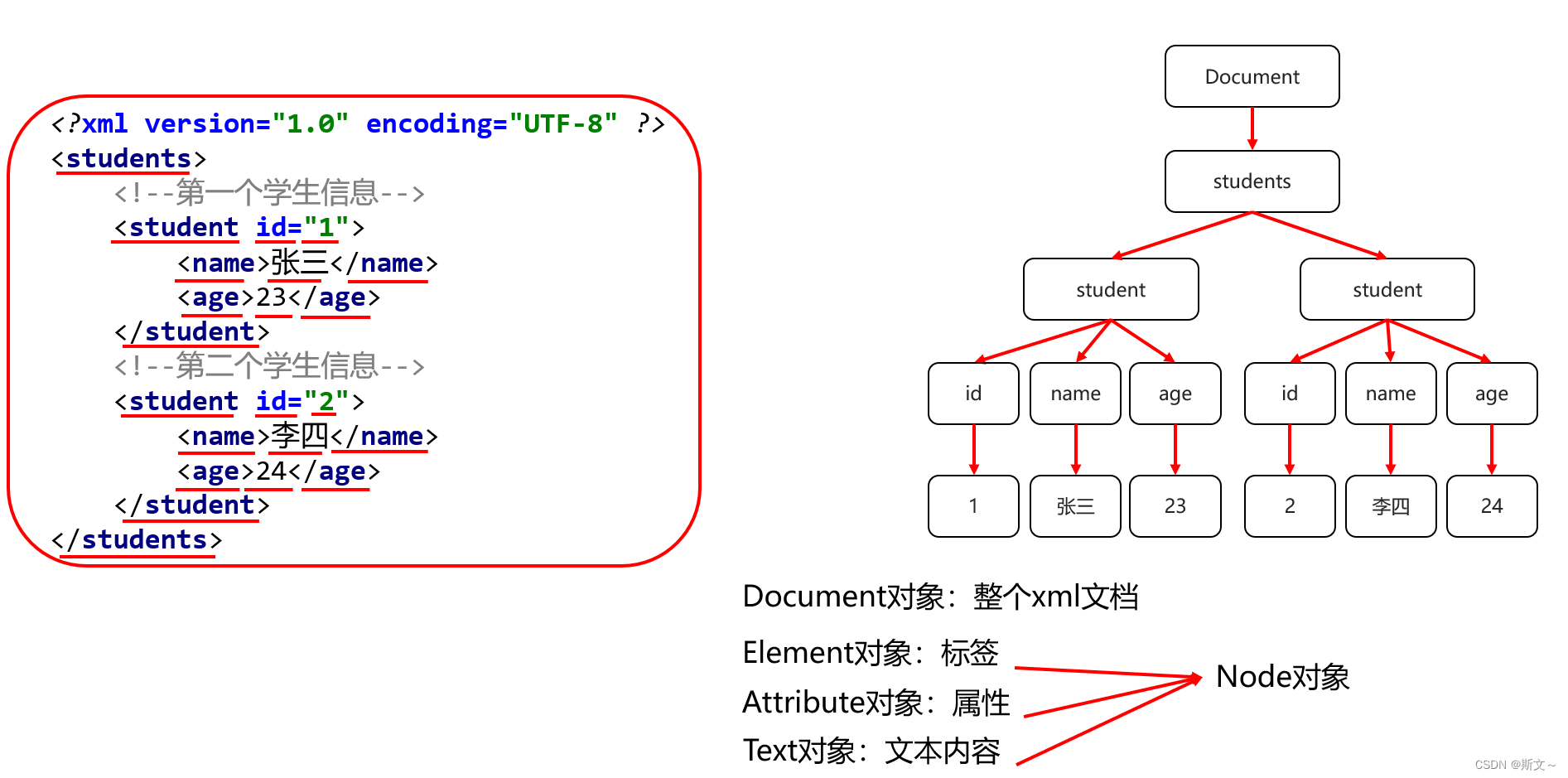
Dom4J解析XML文件
Dom4J官网: https://dom4j.github.io/
实现步骤
1.下载Dom4j框架;
2.在项目中创建一个文件夹:lib;
3.将dom4j-2.1.1.jar文件复制到 lib 文件夹;
4.在jar文件上点右键,选择 Add as Library -> 点击OK;
5.在类中导包使用;
构造器、方法
Dom4J的解析思想
得到文档对象Document,从中获取元素对象和内容。
SAXReader类
| 构造器 | 说明 |
|---|---|
| public SAXReader() | 创建Dom4J的解析器对象 |
| Document read(String url) | 加载XML文件成为Document对象 |
Document类
| 方法 | 说明 |
|---|---|
Element getRootElement() | 获得根元素对象 |
List<Element> elements() | 得到当前元素下所有子元素 |
List<Element> elements(String name) | 得到当前元素下指定名字的子元素返回集合 |
Element element(String name) | 得到当前元素下指定名字的子元素,如果有很多名字相同的返回第一个 |
String getName() | 得到元素名字 |
String attributeValue(String name) | 通过属性名直接得到属性值 |
String elementText(子元素名) | 得到指定名称的子元素的文本 |
String getText() | 得到文本 |
代码示例
Dom4JDemo1.java
public class Dom4JDemo1 {
@Test
public void parseXMLData() throws Exception {
// 1、创建一个Dom4j的解析器对象,代表了整个dom4j框架
SAXReader saxReader = new SAXReader();
// 2、把XML文件加载到内存中成为一个Document文档对象
// Document document = saxReader.read(new File("xml-app\\src\\Contacts.xml")); // 需要通过模块名去定位
// Document document = saxReader.read(new FileInputStream("xml-app\\src\\Contacts.xml"));
// 注意: getResourceAsStream中的/是直接去src下寻找的文件
InputStream is = Dom4JDemo1.class.getResourceAsStream("/Contacts.xml");
Document document = saxReader.read(is);
// 3、获取根元素对象
Element root = document.getRootElement();
System.out.println(root.getName());
// 4、拿根元素下的全部子元素对象(一级)
// List<Element> sonEles = root.elements();
List<Element> sonEles = root.elements("contact");
for (Element sonEle : sonEles) {
System.out.println(sonEle.getName());
}
// 拿某个子元素
Element userEle = root.element("user");
System.out.println(userEle.getName());
// 默认提取第一个子元素对象 (Java语言。)
Element contact = root.element("contact");
// 获取子元素文本
System.out.println(contact.elementText("name"));
// 去掉前后空格
System.out.println(contact.elementTextTrim("name"));
// 获取当前元素下的子元素对象
Element email = contact.element("email");
System.out.println(email.getText());
// 去掉前后空格
System.out.println(email.getTextTrim());
// 根据元素获取属性值
Attribute idAttr = contact.attribute("id");
System.out.println(idAttr.getName() + "-->" + idAttr.getValue());
// 直接提取属性值
System.out.println(contact.attributeValue("id"));
System.out.println(contact.attributeValue("vip"));
}
}
Contacts.xml
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="1" vip="true">
<name> 潘金莲 </name>
<gender>女</gender>
<email>[email protected]</email>
</contact>
<contact id="2" vip="false">
<name>武松</name>
<gender>男</gender>
<email>[email protected]</email>
</contact>
<contact id="3" vip="false">
<name>武大狼</name>
<gender>男</gender>
<email>[email protected]</email>
</contact>
<user>
</user>
</contactList>
XML检索技术:Xpath
XPath介绍
XPath使用路径表达式来定位XML文档中的元素节点或属性节点,Xpath技术更加适合做信息检索。
使用流程
1.导入jar包(dom4j和jaxen-1.1.2.jar),Xpath技术依赖Dom4j技术;
2.通过dom4j的SAXReader获取Document对象;
3.利用XPath提供的API,结合XPath的语法完成选取XML文档元素节点进行解析操作;
| 方法 | 说明 |
|---|---|
Node selectSingleNode("表达式") | 获取符合表达式的唯一元素 |
List<Node> selectNodes("表达式") | 获取符合表达式的元素集合 |
Xpath的检索方法
1.绝对路径
/根元素/子元素/孙元素
采用绝对路径获取从根节点开始逐层的查找节点列表并返回信息。
从根元素开始,一级一级向下查找,不能跨级。
2.相对路径
./子元素/孙元素
先得到根节点,再采用相对路径获取下一级节点的子节点并返回信息。
从当前元素开始,一级一级向下查找,不能跨级。
3.全文检索
直接全文搜索所有的指定元素并返回。
4.属性查找
在全文中搜索属性,或者带属性的元素。
代码示例
XPathDemo.java
public class XPathDemo {
/** 1.绝对路径: /根元素/子元素/子元素。 */
@Test
public void parse01() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索全部的名称
List<Node> nameNodes = document.selectNodes("/contactList/contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
/** 2.相对路径: ./子元素/子元素。 (.代表了当前元素) */
@Test
public void parse02() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
Element root = document.getRootElement();
// c、检索全部的名称
List<Node> nameNodes = root.selectNodes("./contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
/** 3.全文搜索: //元素 在全文找这个元素 //元素1/元素2 在全文找元素1下面的一级元素2 //元素1//元素2 在全文找元素1下面的全部元素2 */
@Test
public void parse03() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索数据
//List<Node> nameNodes = document.selectNodes("//name");
// List<Node> nameNodes = document.selectNodes("//contact/name");
List<Node> nameNodes = document.selectNodes("//contact//name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
/** 4.属性查找。 //@属性名称 在全文检索属性对象。 //元素[@属性名称] 在全文检索包含该属性的元素对象。 //元素[@属性名称=值] 在全文检索包含该属性的元素且属性值为该值的元素对象。 */
@Test
public void parse04() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索数据
List<Node> nodes = document.selectNodes("//@id");
for (Node node : nodes) {
Attribute attr = (Attribute) node;
System.out.println(attr.getName() + "===>" + attr.getValue());
}
// 查询name元素(包含id属性的)
// Node node = document.selectSingleNode("//name[@id]");
Node node = document.selectSingleNode("//name[@id=888]");
Element ele = (Element) node;
System.out.println(ele.getTextTrim());
}
}
Contacts2.xml
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="1" vip="true">
<name> 潘金莲 </name>
<gender>女</gender>
<email>[email protected]</email>
</contact>
<contact id="2" vip="false">
<name>武松</name>
<gender>男</gender>
<email>[email protected]</email>
</contact>
<contact id="3" vip="false">
<name>武大狼</name>
<gender>男</gender>
<email>[email protected]</email>
</contact>
<user>
<contact>
<info>
<name id="888">我是西门庆</name>
</info>
</contact>
</user>
</contactList>
边栏推荐
- [live broadcast appointment] database obcp certification comprehensive upgrade open class
- C端梦难做,科大讯飞靠什么撑起10亿用户目标?
- 中英说明书丨人可溶性晚期糖基化终末产物受体(sRAGE)Elisa试剂盒
- 寶,運維100+服務器很頭疼怎麼辦?用行雲管家!
- 2020, the regular expression for mobile phone verification of the latest mobile phone number is continuously updated
- The former 4A executives engaged in agent operation and won an IPO
- 如何运营好技术相关的自媒体?
- Technical secrets of ByteDance data platform: implementation and optimization of complex query based on Clickhouse
- 【pytorch记录】模型的分布式训练DataParallel、DistributedDataParallel
- Database foundation: select basic query statement
猜你喜欢
微服务大行其道的今天,Service Mesh是怎样一种存在?
Today, with the popularity of micro services, how does service mesh exist?
Specification of lumiprobe reactive dye indocyanine green

如何使用物联网低代码平台进行个人设置?

Lake shore optimag superconducting magnet system om series

Superoptimag superconducting magnet system - SOM, Som2 series

Leetcode-160 intersecting linked list
【快应用】text组件里的文字很多,旁边的div样式会被拉伸如何解决
Prices of Apple products rose across the board in Japan, with iphone13 up 19%

MySQL常用图形管理工具 | 黑马程序员
随机推荐
Graduation season | Huawei experts teach the interview secret: how to get a high paying offer from a large factory?
Technical secrets of ByteDance data platform: implementation and optimization of complex query based on Clickhouse
Taiaisu M source code construction, peak store app premium consignment source code sharing
机械设备行业数字化供应链集采平台解决方案:优化资源配置,实现降本增效
Create your own NFT collections and publish a Web3 application to show them (Introduction)
The best landing practice of cave state in an Internet ⽹⾦ financial technology enterprise
Getting started with kubernetes command (namespaces, pods)
Golang error handling
Lumiprobe 细胞成像研究丨PKH26细胞膜标记试剂盒
混沌工程平台 ChaosBlade-Box 新版重磅发布
洞态在某互联⽹⾦融科技企业的最佳落地实践
组队学习! 14天鸿蒙设备开发“学练考”实战营限时免费加入!
Example explanation: move graph explorer to jupyterlab
摄像头的MIPI接口、DVP接口和CSI接口[通俗易懂]
Leetcode-141 circular linked list
宝,运维100+服务器很头疼怎么办?用行云管家!
Altair HyperWorks 2022 software installation package and installation tutorial
Lake Shore低温恒温器的氦气传输线
MySQL common graphics management tools | dark horse programmers
Improve yolov5 with gsconv+slim neck to maximize performance!