当前位置:网站首页>诸神黄昏时代的对比学习
诸神黄昏时代的对比学习
2022-07-04 12:37:00 【InfoQ】

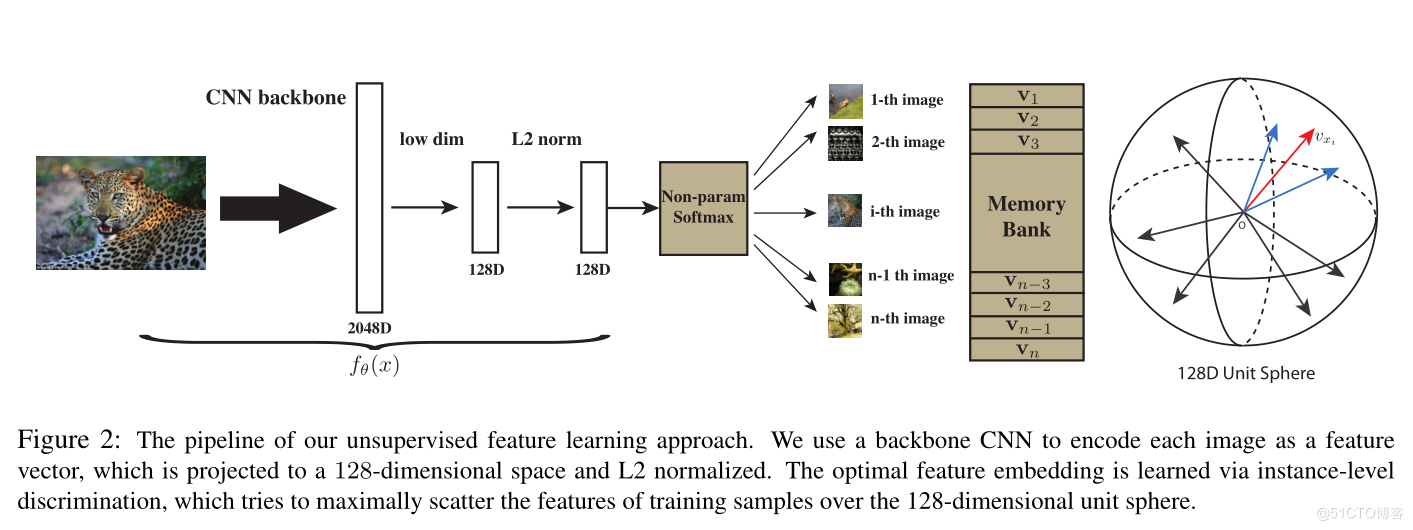
InstDisc


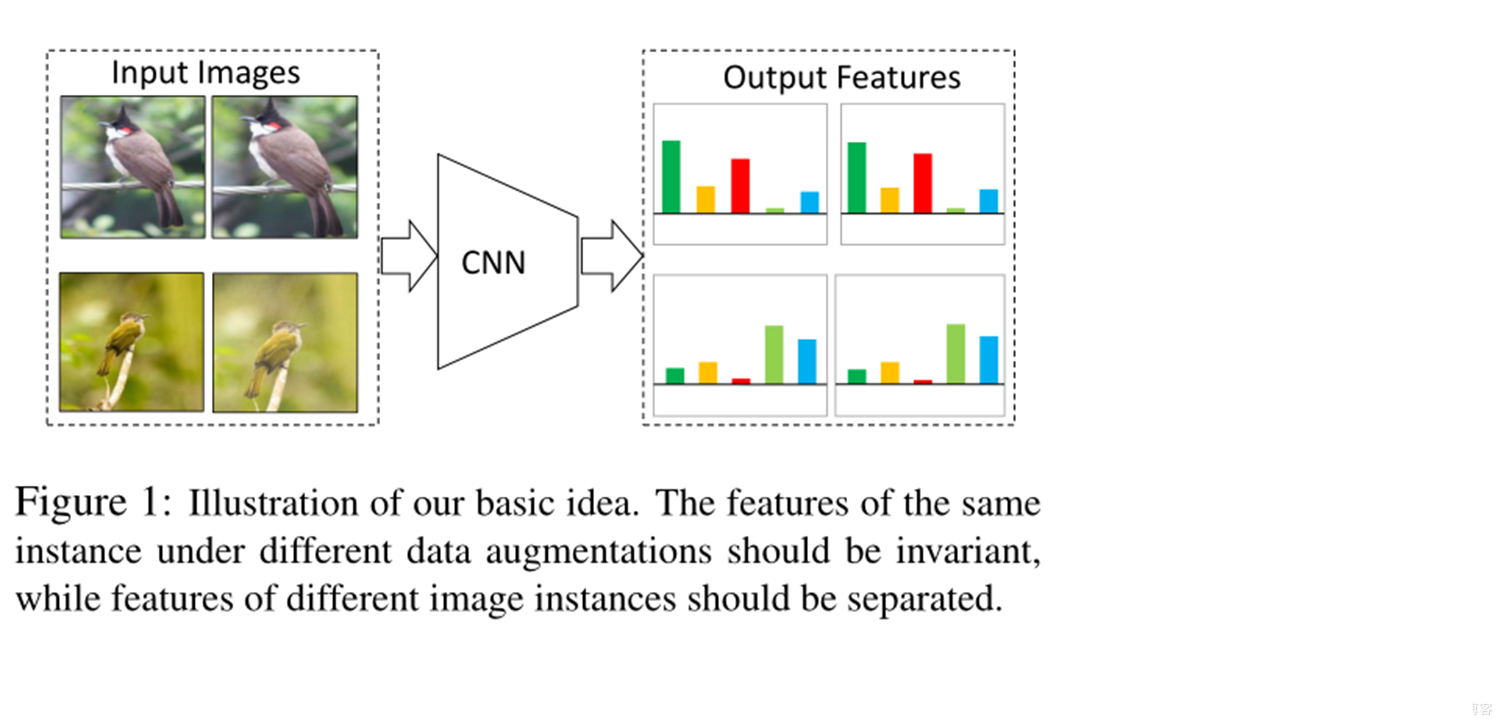
InvaSpread


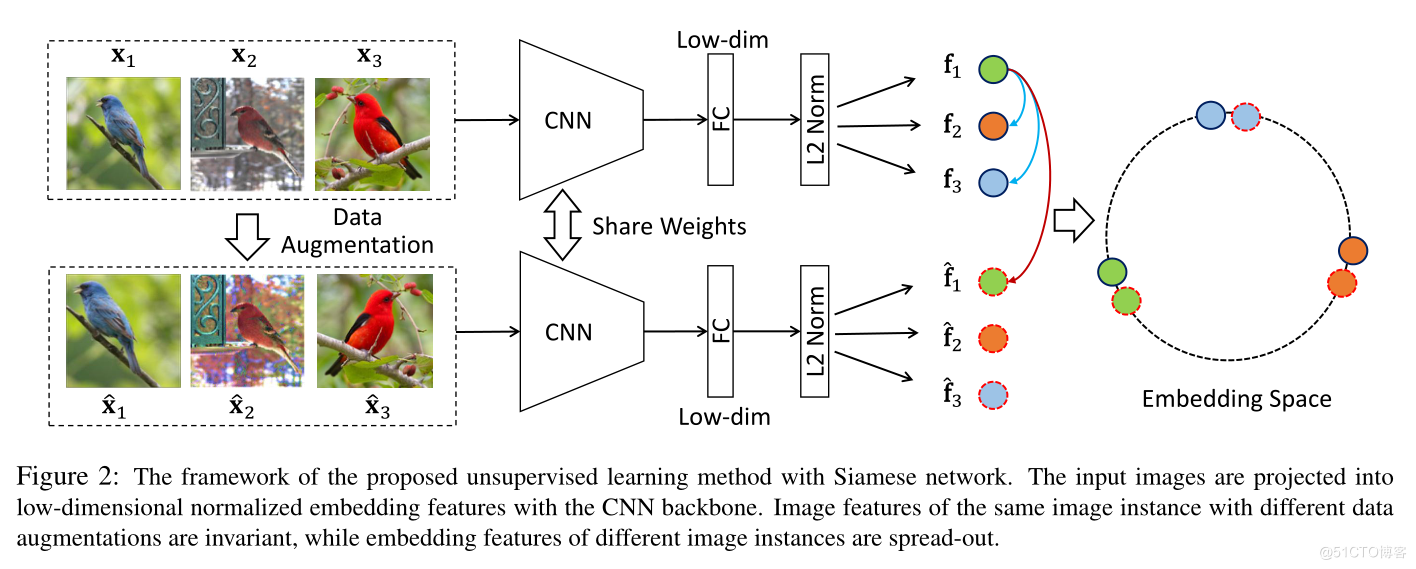

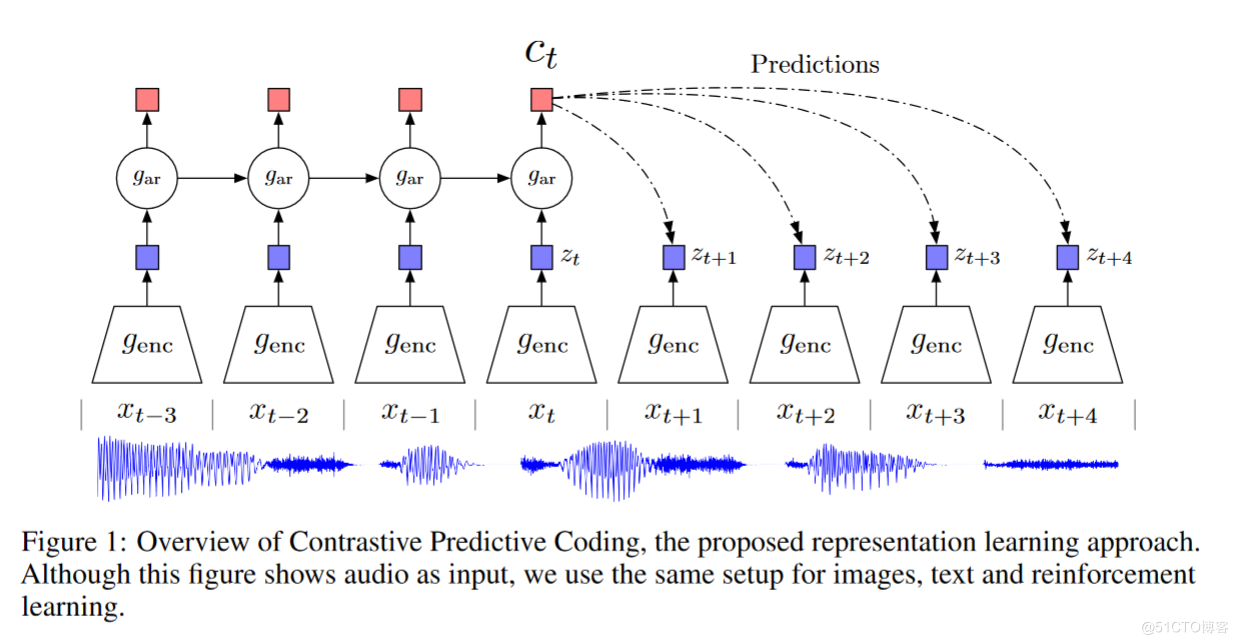
CPC

CMC

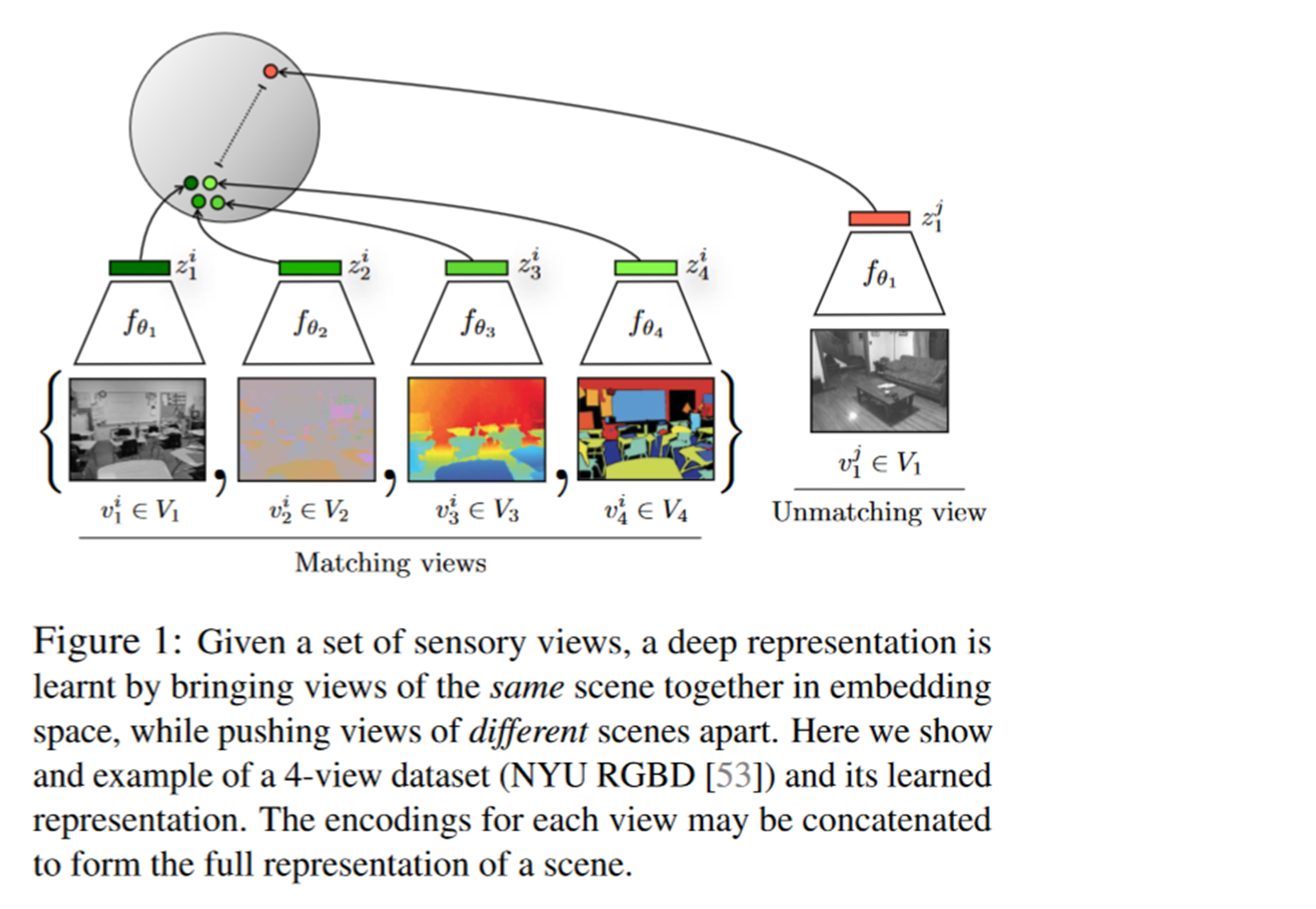
- 第一张图是图像的原图。
- 第二张图是一个深度信息图。他表示的是这个物体离你的远近。你可以想象成一个热图,就是离你越远的颜色越怎么样,离你越近的颜色越怎么样。
- 第三张图是一个表面法线图。
- 第四张图是一个图像分割图。
边栏推荐
- 轻松玩转三子棋
- Wechat video Number launches "creator traffic package"
- CVPR 2022 | TransFusion:用Transformer进行3D目标检测的激光雷达-相机融合
- A taste of node JS (V), detailed explanation of express module
- mm_ Cognition of struct structure
- Langue C: trouver le nombre de palindromes dont 100 - 999 est un multiple de 7
- Global and Chinese market of dental elevators 2022-2028: Research Report on technology, participants, trends, market size and share
- Entity framework calls Max on null on records - Entity Framework calling Max on null on records
- When synchronized encounters this thing, there is a big hole, pay attention!
- 数据库锁表?别慌,本文教你如何解决
猜你喜欢

How to realize the function of Sub Ledger of applet?
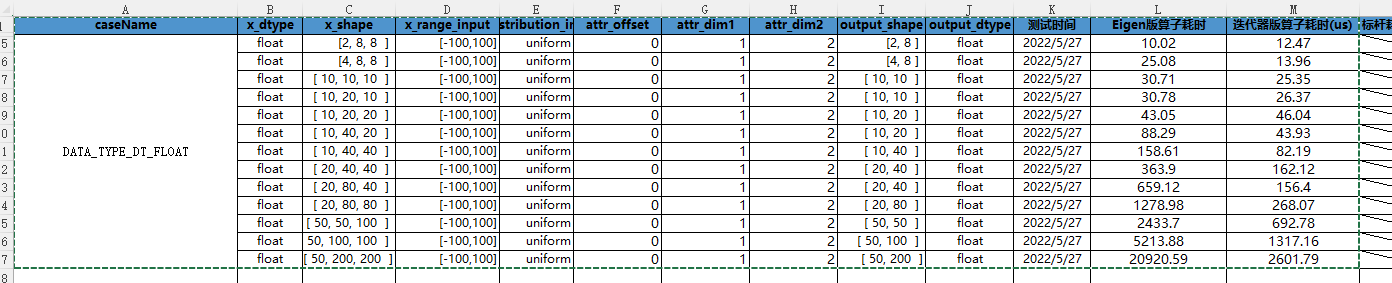
Cann operator: using iterators to efficiently realize tensor data cutting and blocking processing
Introduction to random and threadlocalrandom analysis
CVPR 2022 | TransFusion:用Transformer进行3D目标检测的激光雷达-相机融合
Flet教程之 按钮控件 ElevatedButton入门(教程含源码)
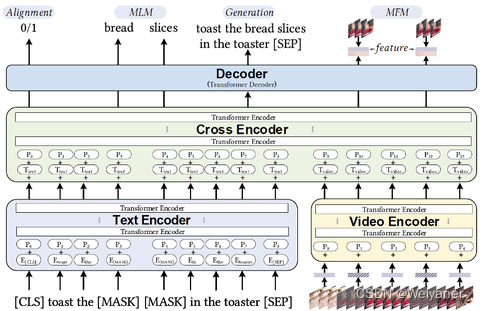
美团·阿里关于多模态召回的应用实践

vim 出现 Another program may be editing the same file. If this is the case 的解决方法
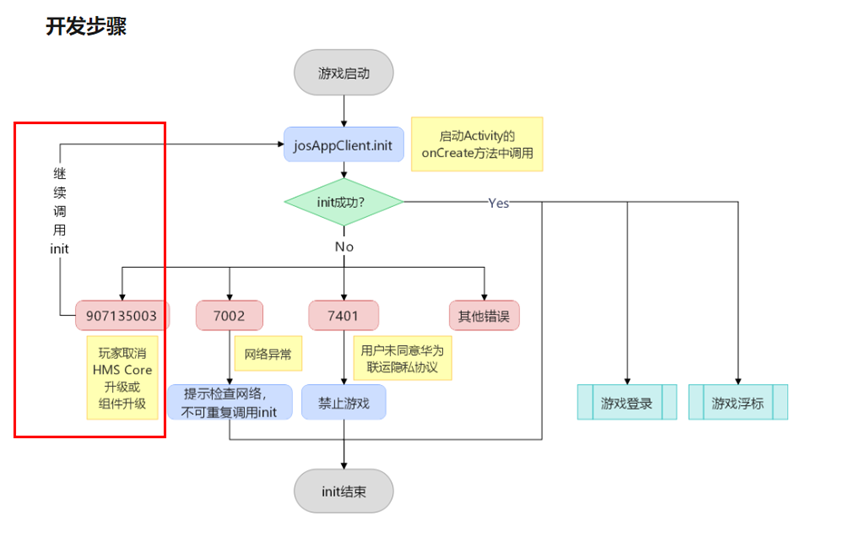
游戏启动后提示安装HMS Core,点击取消,未再次提示安装HMS Core(初始化失败返回907135003)

I want to talk about yesterday
VIM, another program may be editing the same file If this is the solution of the case
随机推荐
After installing vscode, the program runs (an include error is detected, please update the includepath, which has been solved for this translation unit (waveform curve is disabled) and (the source fil
ArcGis利用栅格处理工具进行影像裁剪
Daily Mathematics Series 57: February 26
阿里云有奖体验:用PolarDB-X搭建一个高可用系统
Practice of retro SOAP Protocol
PostgreSQL 9.1 soaring Road
jsonp
美团·阿里关于多模态召回的应用实践
面试官:Redis 过期删除策略和内存淘汰策略有什么区别?
7、 Software package management
Full arrangement (medium difficulty)
众昂矿业:为保障萤石足量供应,开源节流势在必行
Flet教程之 02 ElevatedButton高级功能(教程含源码)(教程含源码)
阿里云有奖体验:用PolarDB-X搭建一个高可用系统
17.内存分区与分页
It's hard to hear C language? Why don't you take a look at this (V) pointer
PostgreSQL 9.1 飞升之路
【Android Kotlin】lambda的返回语句和匿名函数
Fastlane one click package / release app - usage record and stepping on pit
CTF竞赛题解之stm32逆向入门