当前位置:网站首页>flink reads mongodb data source
flink reads mongodb data source
2022-08-05 03:59:00 【//Inheritance _ Documentary】
文章目录
一、普通java模式获取
1. mongodb-driver驱动
mongodb-driver是mongo官方推出的java连接mongoDB的驱动包,相当于JDBC驱动.
(1)通过maven仓库导入:https://mvnrepository.com/artifact/org.mongodb/mongodb-driver
(2)Download the corresponding one from the official websitejava的驱动:http://docs.mongodb.org/ecosystem/drivers/java/
(3)used by different driversjarAlso not the same reference:http://mongodb.github.io/mongo-java-driver/
例如:
<dependencies>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver-sync</artifactId>
<version>3.11.2</version>
</dependency>
</dependencies>
2. 创建方法类
2.1 查询全部,遍历打印
package mongodb.test;
import org.bson.Document;
import com.mongodb.BasicDBObject;
import com.mongodb.MongoClient;
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
public class Mongodb {
/** * Query to print all collections */
public static void mongoQueryAll() {
//1.创建链接
MongoClient client = new MongoClient("localhost");
//2.打开数据库test
MongoDatabase db = client.getDatabase("test");
//3.获取集合
MongoCollection<Document> collection = db.getCollection("stu");
//4.The query gets a collection of documents
FindIterable<Document> documents = collection.find();
//5.循环遍历
for (Document document : documents) {
System.out.println(document);
}
//6.关闭连接
client.close();
}
public static void main(String[] args) {
mongoQueryAll();
}
}
//打印输出stu全部数据
Document{
{
_id=5d7374e836a89c5a3d18b87a, name=xiaohua}}
Document{
{
_id=2.0, sn=002, name=xiaogang}}
Document{
{
_id=3.0, sn=003, name=zhangfei, job=Forward fighter}}
Document{
{
_id=5d73782736a89c5a3d18b87b, sn=004, name=xiaobingbing}}
Document{
{
_id=5d7396b44ec120618b2dd0cb, name=Document{
{
surname=李, name=world name}}, job=[皇帝, 大人物, 大丈夫, 功成名就]}}
2.2 条件查询
/** * 条件查询:如查询id为xxxx的学生所有信息 */
public static void mongoConditionQuery() {
//1.创建链接
MongoClient client = new MongoClient("localhost");
//2.打开数据库test
MongoDatabase db = client.getDatabase("test");
//3.获取集合
MongoCollection<Document> collection = db.getCollection("stu");
//4.构建查询条件,按照name来查询
BasicDBObject stu = new BasicDBObject("name","zhangfei");
//5.通过id查询记录,获取文档集合
FindIterable<Document> documents = collection.find(stu);
//5.打印信息
for (Document document : documents) {
System.out.println("name:"+document.getString("name"));
System.out.println("sn:"+document.getString("sn"));
System.out.println("job:"+document.getString("job"));
}
//6.关闭连接
client.close();
}
public static void main(String[] args) {
mongoConditionQuery();
}
//执行输出
name:zhangfei
sn:003
job:Forward fighter
注意:When query conditions are required+Write this when judging,For example, query the student numbersn>003的学员
//查询sum大于3的学员
BasicDBObject stu = new BasicDBObject("sum",new BasicDBObject("$gt",003));
2.3 插入语句
/** * 插入语句 */
public static void mongoInsert() {
//1.创建链接
MongoClient client = new MongoClient("localhost");
//2.打开数据库test
MongoDatabase db = client.getDatabase("test");
//3.获取集合
MongoCollection<Document> collection = db.getCollection("stu");
//4.准备插入数据
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("sn","005");
map.put("name","xiaoA");
map.put("job","A工作");
map.put("sum",6);
//5.将map转换成document
Document document = new Document(map);
collection.insertOne(document);
//6.关闭连接
client.close();
}
//测试执行
public static void main(String[] args) {
mongoInsert();
}
批量插入,仅供参考:
//When you need to insert multiple documents,It is of course possible to loop through a single insert,但是效率不高,MongoDBProvides a method for batch insertion
List<DBObject> objs = new ArrayList<DBObject>();
objs.add(new BasicDBObject("name","user29").append("age", 30).append("sex", 1));
objs.add(new BasicDBObject("name","user30").append("age", 30).append("sex", 1));
collection.insert(objs);
//This inserts in batches.Bulk inserts pass data to the database in one request,Then inserted by the database,It saves resources for each request than circular single insert.
二、Flink 以Hadoop文件格式读取
1. pom.xml添加相关依赖
<!--hadoop compatibility-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.mongodb.mongo-hadoop</groupId>
<artifactId>mongo-hadoop-core</artifactId>
<version>2.0.0</version>
</dependency>
2. 以Hadoop文件格式读取MongoDB中的数据
import com.mongodb.hadoop.MongoInputFormat;
import com.mongodb.hadoop.MongoOutputFormat;
import com.mongodb.hadoop.io.BSONWritable;
import example.flink.KeySelector.RecordSeclectId;
import example.flink.mapFunction.BSONMapToRecord;
import example.flink.reduceFunction.KeyedGroupReduce;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.hadoop.mapreduce.HadoopInputFormat;
import org.apache.flink.api.java.hadoop.mapreduce.HadoopOutputFormat;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.hadoop.mapreduce.Job;
import org.bson.BSONObject;
public class MongoSet {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
Job inputJob = Job.getInstance();
//inputJob.getConfiguration().set("mongo.input.uri", "mongodb://readuser:[email protected]:port,mongos02:port,mongos03:port/db.collection");
//inputJob.getConfiguration().set("mongo.auth.uri", "mongodb://root:[email protected]:port,mongos02:port,mongos03:port/admin");
inputJob.getConfiguration().set("mongo.input.uri", "mongodb://readuser:[email protected]:port,mongos02:port,mongos03:port/db.collection?&authMechanism=SCRAM-SHA-1&authSource=admin&readPreference=secondary");
inputJob.getConfiguration().set("mongo.input.split.read_shard_chunks", "true");
inputJob.getConfiguration().set("mongo.input.split.create_input_splits", "false");
inputJob.getConfiguration().set("mongo.input.split_size","16");
inputJob.getConfiguration().set("mongo.input.query", "{'createDateTime': {\"$lte\":{\"$date\":\"2019-05-27T00:00:00.000Z\"}, \"$gte\":{\"$date\":\"2010-03-17T00:00:00.000Z\"}}}");
inputJob.getConfiguration().set("mongo.input.fields", "{\"Id\":\"1\",\"saleType\":\"1\",\"saleNum\":\"1\",\"createDateTime\":\"1\"}");
HadoopInputFormat<Object, BSONObject> hdIf =
new HadoopInputFormat<>(new MongoInputFormat(), Object.class, BSONObject.class, inputJob);
DataSet<Tuple2<Object, BSONObject>> inputNew = env.createInput(hdIf);
DataSet<Tuple2<String, BSONWritable>> personInfoDataSet = inputNew
.map(new BSONMapToRecord())
.groupBy(new RecordSeclectId())
.reduceGroup(new KeyedGroupReduce());
Job outputJob = Job.getInstance();
outputJob.getConfiguration().set("mongo.output.uri", "mongodb://mongo:27017/db.collection");
outputJob.getConfiguration().set("mongo.output.batch.size", "8");
outputJob.getConfiguration().set("mapreduce.output.fileoutputformat.outputdir", "/tmp");
personInfoDataSet.output(new HadoopOutputFormat<>(new MongoOutputFormat<>(), outputJob));
env.execute(MongoSet.class.getCanonicalName());
}
三、Flink CDC监控MongoDB oplog的变化(Only real-time data can be synchronized)
1、简介
MongoDB CDC连接器通过伪装一个MongoDB集群里副本,利用MongoDB集群的高可用机制,该副本可以从master节点获取完整oplog(operation log)事件流.
Flink CDC官网:https://github.com/ververica/flink-cdc-connectors
MongoDB CDC:https://github.com/ververica/flink-cdc-connectors/blob/master/docs/content/connectors/mongodb-cdc.md
mongodb知识点整理:https://blog.csdn.net/penngo/article/details/124232016
2、依赖条件
MongoDB版本
MongoDB version >= 3.6集群部署
副本集 或 分片集群 .Storage Engine
WiredTiger存储引擎.副本集协议版本
副本集协议版本1 (pv1) .
从4.0版本开始,MongoDB只支持pv1. pv1是MongoDB 3.2或更高版本创建的所有新副本集的默认值.需要的权限
MongoDB Kafka Connector需要changeStream 和 read 权限.
您可以使用下面的示例进行简单授权:
更多详细授权请参考MongoDB数据库用户角色.
use admin;
db.createUser({
user: "flinkuser",
pwd: "flinkpw",
roles: [
{
role: "read", db: "admin" }, //read role includes changeStream privilege
{
role: "readAnyDatabase", db: "admin" } //for snapshot reading
]
});
3、配置MongoDB副本集
创建mongo1.conf、mongo2.conf、mongo3.conf
# mongo1.conf
dbpath=/data/mongodb-4.4.13/data1
logpath=/data/mongodb-4.4.13/mongo1.log
logappend=true
port=27017
replSet=replicaSet_penngo # 副本集名称
oplogSize=200
# mongo2.conf
dbpath=/data/mongodb-4.4.13/data2
logpath=/data/mongodb-4.4.13/mongo2.log
logappend=true
port=27018
replSet=replicaSet_penngo # 副本集名称
oplogSize=200
# mongo3.conf
dbpath=/data/mongodb-4.4.13/data3
logpath=/data/mongodb-4.4.13/mongo3.log
logappend=true
port=27019
replSet=replicaSet_penngo # 副本集名称
oplogSize=200
启动mongodb服务端
在单独的终端上分别运行以下命令:
> mongod --config ../mongo1.conf
> mongod --config ../mongo2.conf
> mongod --config ../mongo3.conf
连接mongodb,使用mongo shell配置副本集
> mongo --port 27017
# 在mongo shell中执行下边命令初始化副本集
> rsconf = {
_id: "replicaSet_penngo",
members: [
{
_id: 0, host: "localhost:27017"},
{
_id: 1, host: "localhost:27018"},
{
_id: 2, host: "localhost:27019"}
]
}
> rs.initiate(rsconf)
mongo shell中创建数据库penngo_db和集合coll,插入1000条数据
> use penngo_db
> for (i=0; i<1000; i++) {
db.coll.insert({
user: "penngo" + i})}
> db.coll.count()

在mongo shell创建新用户,给Flink MongoDB CDC使用
> use admin;
> db.createUser({
user: "flinkuser",
pwd: "flinkpw",
roles: [
{
role: "read", db: "admin" }, //read role includes changeStream privilege
{
role: "readAnyDatabase", db: "admin" } //for snapshot reading
]
});
4、创建maven工程
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.penngo.flinkcdc</groupId>
<artifactId>FlickCDC</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>FlickCDC_TEST</name>
<url>https://21doc.net/</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<flink-version>1.13.3</flink-version>
<flink-cdc-version>2.1.1</flink-cdc-version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink-cdc-version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mongodb-cdc</artifactId>
<version>${flink-cdc-version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>alimaven</id>
<name>Maven Aliyun Mirror</name>
<url>https://maven.aliyun.com/repository/central</url>
</repository>
</repositories>
</project>
MongoDBExample.java
package com.penngo.flinkcdc;
import com.ververica.cdc.connectors.mongodb.MongoDBSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.commons.lang3.StringEscapeUtils;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
public class MongoDBExample {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.通过FlinkCDC构建SourceFunction
SourceFunction<String> mongoDBSourceFunction = MongoDBSource.<String>builder()
.hosts("127.0.0.1:27017")
.username("flinkuser")
.password("flinkpw")
.database("penngo_db")
.collection("coll")
// .databaseList("penngo_db")
// .collectionList("coll")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(mongoDBSourceFunction);
SingleOutputStreamOperator<Object> singleOutputStreamOperator = dataStreamSource.process(new ProcessFunction<String, Object>() {
@Override
public void processElement(String value, ProcessFunction<String, Object>.Context ctx, Collector<Object> out) {
try {
System.out.println("processElement=====" + value);
}catch (Exception e) {
e.printStackTrace();
}
}
});
dataStreamSource.print("原始流--");
env.execute("Mongo");
}
}
运行效果
四、Flink SQL CDC 监控MongoDB
边栏推荐
- Redis1: Introduction to Redis, basic features of Redis, relational database, non-relational database, database development stage
- 2022 Hangzhou Electric Multi-School 1st Game
- Confessing the era of digital transformation, Speed Cloud engraves a new starting point for value
- bytebuffer internal structure
- Use Unity to publish APP to Hololens2 without pit tutorial
- 队列题目:最近的请求次数
- shell脚本:for循环与while循环
- cross domain solution
- 重载运算符
- UE4 第一人称角色模板 添加冲刺(加速)功能
猜你喜欢
从企业的视角来看,数据中台到底意味着什么?

今年七夕,「情蔬」比礼物更有爱
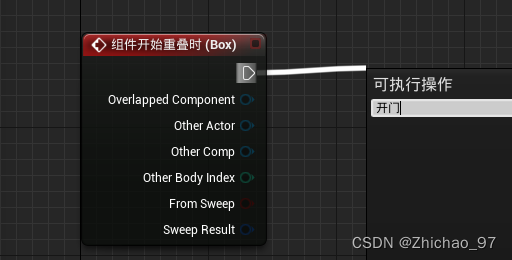
UE4 通过与其它Actor互动开门
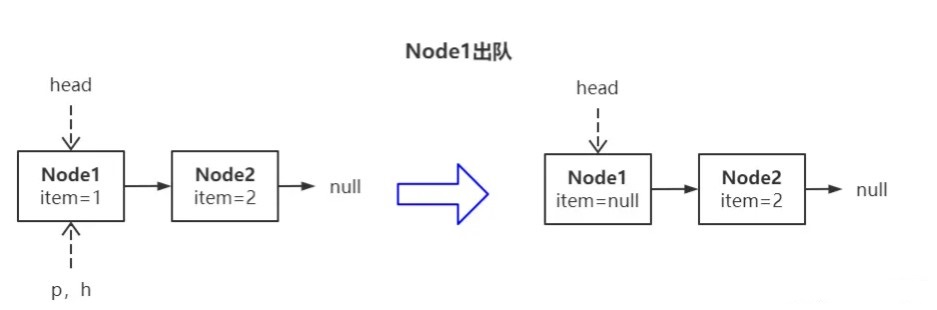
Android interview question - how to write with his hands a non-blocking thread safe queue ConcurrentLinkedQueue?
Some conventional routines of program development (1)
Use Unity to publish APP to Hololens2 without pit tutorial

Detailed and comprehensive postman interface testing practical tutorial
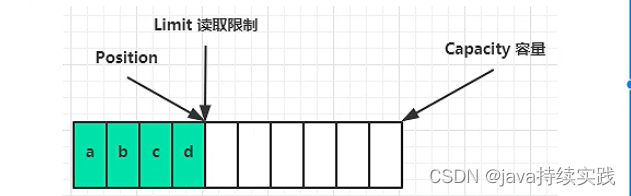
bytebuffer internal structure
Haproxy搭建Web群集

【8.4】代码源 - 【数学】【历法】【删库】【不朴素的数列(Bonus)】
随机推荐
YYGH-13-客服中心
【8.1】代码源 - 【第二大数字和】【石子游戏 III】【平衡二叉树】
Static method to get configuration file data
Spark基础【介绍、入门WordCount案例】
[SWPU2019]Web1
36-Jenkins-Job Migration
UE4 opens doors with overlapping events
Qixi Festival code confession
token、jwt、oauth2、session解析
Redis key基本命令
新人如何入门和学习软件测试?
[BSidesCF 2019]Kookie
【背包九讲——01背包问题】
多御安全浏览器新版下载 | 功能优秀性能出众
iMedicalLIS listener (2)
2022软件测试工程师最全面试题
测试薪资这么高?刚毕业就20K
七夕节赚徽章拉
Ice Scorpion V4.0 attack, security dog products can be fully detected
XMjs cross-domain problem solving