视频目标检测是图像目标检测在视频领域的自然延伸,因为视频的本质还是连续的图像,视频目标检测的基本原理与图像目标检测是一样的。视频数据由大量连续图像组成,数量多,相邻图像之间的像素变化较小,存在大量的冗余信息。若将视频数据逐帧分解,直接输入图像目标检测的模型进行训练,庞大的计算量会严重影响检测速度,导致检测结果毫无实际应用的价值,且无法解决视频数据运动模糊、视频离焦、不寻常的姿态或物体遮挡等问题。
当人们不确定一个对象的身份时,他们会从其他相关信息中寻找一个与当前对象具有高度语义相似性的不同对象,并将其分配到一起。视频包含了关于相同对象实例的更丰富的信息,例如,它在不同姿势和不同视角下的外观,因此视频目标检测器应该比静态图像检测器更强大,关键的挑战是设计一个模型,充分利用当前图像帧的时间上下文信息来提高检测精度和速度。
2016 年,微软亚洲研究院的代季峰团队提出深度特征流算法 DFF(Deep Feature Flow),核心思想是采用简单的固定间隔算法选取一系列稀疏的关键帧,以耗时费力的深度神经网络提取特征;对于占比更大的非关键帧,利用光流网络(FlowNet)计算上一个关键帧和当前非关键帧之间的光流场(flow field),然后通过光流场将关键帧的深度卷积特征图传播到当前帧,最后将所有的特征图送入任务网络(Task Network)获取检测结果。利用光流网络比常用的提取特征的卷积神经网络计算量更小的优点,DFF 算法引入 FlowNet 来计算非关键帧的特征图,以此减少模型的计算量。当关键帧间隔帧数为 10 时,DFF 算法的检测精度 mAP 比基准方法下降了 0.8,但运行速度提升了约 5 倍,达到了 20.25FPS。
由于视频中的物体检测会受到各种环境因素的影响,难以成功检测单帧图像的目标,代季峰团队在 DFF 的基础上提出新算法 FGFA[26](Flow-Guided Feature Aggregation),并在 2017 年的 ILSVRC 比赛中斩获冠军,首先将图像送入特征提取网络得到相应的特征图,在将相邻帧在运动路径上前后K 帧的特征图传播到当前帧中,并引入一个自适应权重网络将传播过来的特征聚合到当前帧的特征中,以增强当前帧的特征表示,提高当前帧的特征质量。FGFA是一个典型的以速度换取检测精度的算法,当关键帧间隔帧数为 10 时,检测指标mAP 提升至 76.3%,相对于基准算法的 mAP 值增加了 2.9%,但是单帧的平均检测时间从 288ms 上升到了 733ms。
高性能的目标检测依赖于昂贵的卷积网络来计算特征,这常常会给那些需要实时从视频流中检测出目标的应用带来重大挑战,解决这一问题的关键是如何保持竞争性能的同时降低计算成本。2018 年香港中文大学商汤科技联合实验室公布了 ST-Lattice(尺度-时间网格)算法,先在稀疏的关键帧上得到检测结果,然后利用传播和细化单元(Propagation and Refinement Units)对检测结果进行跨时间、跨尺度的传播,直到到达输出节点,以此辅助非关键帧的检测,最后使用 tube-level分类器对结果进行位置修正。在 ImageNet VID 数据集上,ST-Lattice 算法作为精度/速度的折衷,可以达到 79.6mAP(20fps)和 79.0mAP(62fps)的性能。
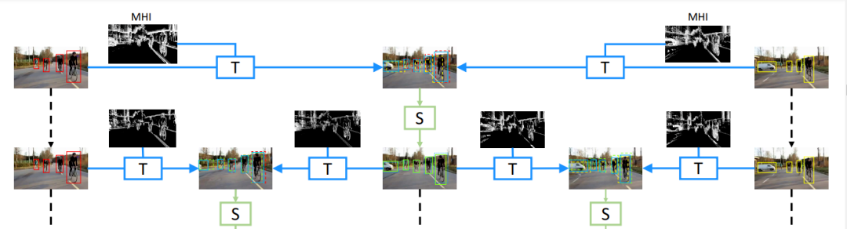
上图呈现了尺度-时间网格算法的详细过程,途中的每个节点表示一定尺度和时间点的检测结果,每条边则表示从一个节点到另一个节点的一次性操作。水平方向的操作 T(蓝色)表示时间传播,采用 MHI 的方式有效的计算和保留足够的运动信息,用以处理帧间较大的运动位移,粗略的定位到中间时间处的目标,此操作只关注物体的运动,不考虑预测结果和 Ground True 之间的偏移量。垂直方向(绿色)代表从低分辨率到高分辨率的空间细化,用于弥补操作 T 的影响,通过从粗到细的方法回归边界盒的偏移量,以此实现更精准的定位。对于一个视频,只在稀疏的关键帧上进行卷积操作提取特征并给出最后的检测结果,将结果沿着预定义的路径传播到最底层,底部的最终结果覆盖了所有时间点。
2018 年,Fanyi Xiao 和 Yong Jae Lee 在文献中时空记忆网络(spatial-temporal memory network, STMN),提出一种新的 RNN 结构,为视频对象检测建模对象随时间变化的外观和运动信息。跨帧的记忆网络传递信息会带来定位误差,可利用 Match Trans 机制建模目标运动,使用匹配变换去对齐帧到帧的特征,使精度达到了当时的领先水准。
Gedas Bertasius 等人提出的时空采样网络(Spatiotemporal Sampling Networks, STSN),采用 Deformable Conv 结构提取相邻帧空间特征来执行视频目标检测。2020年,出现了可学习的时空采样模块[30](Learnable Spatio-Temporal Sampling, LSTS),利用 ResNet-101 作为 backbone 对关键帧进行处理,而非关键帧采用轻量级的网络,可实现精度和速度的极致,实现在帧间传播高级特征的目的。此文有稀疏递归特征更新(SRFU)和密集特征聚合(DFA)两个网络模块,SRFU 用于维持记忆特征来捕获时间关系,记忆特征会在关键帧处进行迭代更新,DFA 传播关键帧的记忆特征以此增强和丰富非关键帧的低级特征。LSTS 模块嵌入到 SRFU 和 DFA 结构中,以便在帧间准确的传播和对齐特征。LSTS 模块思想:在特征Ft 上进行随机采样,利用采样位置计算嵌入的特征 f(Ft) 和 g(Ft+k)相对应的相似度权重,计算出权重,并对𝐹进行特征融合获得传播特征F'(t+k),在训练过程中根据最终的检测损失迭代更新采样的位置。
上述算法均采用深层网络 ResNet-101 作为特征提取的网络,然后使用 Faster R-CNN 或 R-FCN 作为检测网络,这种两阶段的检测方案可以有效的提高视频目标检测的精确度,但对于速度方面有欠缺。本文所提出的方案利用一阶段的检测网络对稀疏的关键帧进行检测,会牺牲些许的精度以寻求速度的提升,实验结果表明所提算法在确保一定精确的情况下可以达到实时的效果。
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://xie.infoq.cn/article/5b93298d77d88ea03f6456ca7