This paper proposes a novel lightweight channel attention mechanism coordinate attention, Be able to consider the relationship between channels and long-distance location information at the same time . It is found through experiments that ,coordinate attention It can effectively improve the accuracy of the model , And it only brings a small amount of computing consumption , Very good
source : Xiaofei's algorithm Engineering Notes official account
The paper : Coordinate Attention for Efficient Mobile Network Design

- Address of thesis :https://arxiv.org/abs/2103.02907
- Paper code :https://github.com/Andrew-Qibin/CoordAttention
Introduction
at present , The attention mechanism of lightweight networks mostly adopts SE modular , Only the information between channels is considered , Location information is ignored . Although later BAM and CBAM Try to extract positional attention information by convolution after reducing the number of channels , But convolution can only extract local relations , Lack the ability to extract long-distance relationships . So , This paper proposes a new efficient attention mechanism coordinate attention, It can encode the horizontal and vertical position information into channel attention in , So that mobile networks can focus on a wide range of location information without too much computation .
coordinate attention The main advantages are as follows :
- Not only the information between channels is obtained , Direction related location information is also considered , It is helpful for the model to better locate and identify targets .
- Flexible and light enough , It can be simply inserted into the core structure of the mobile network .
- It can be used as a pre training model in a variety of tasks , Such as detection and segmentation , Both have good performance improvements .
Coordinate Attention
Coordinate Attention It can be regarded as a computing unit to enhance the ability of mobile network feature expression , Accept intermediate features \(X=[x_1,x_2,\cdots,x_C]\in\mathbb{R}^{C\times H\times W}\) As input , Output and \(X\) Enhanced features of the same size \(Y=[y_1,y_2,\cdots,y_C]\).
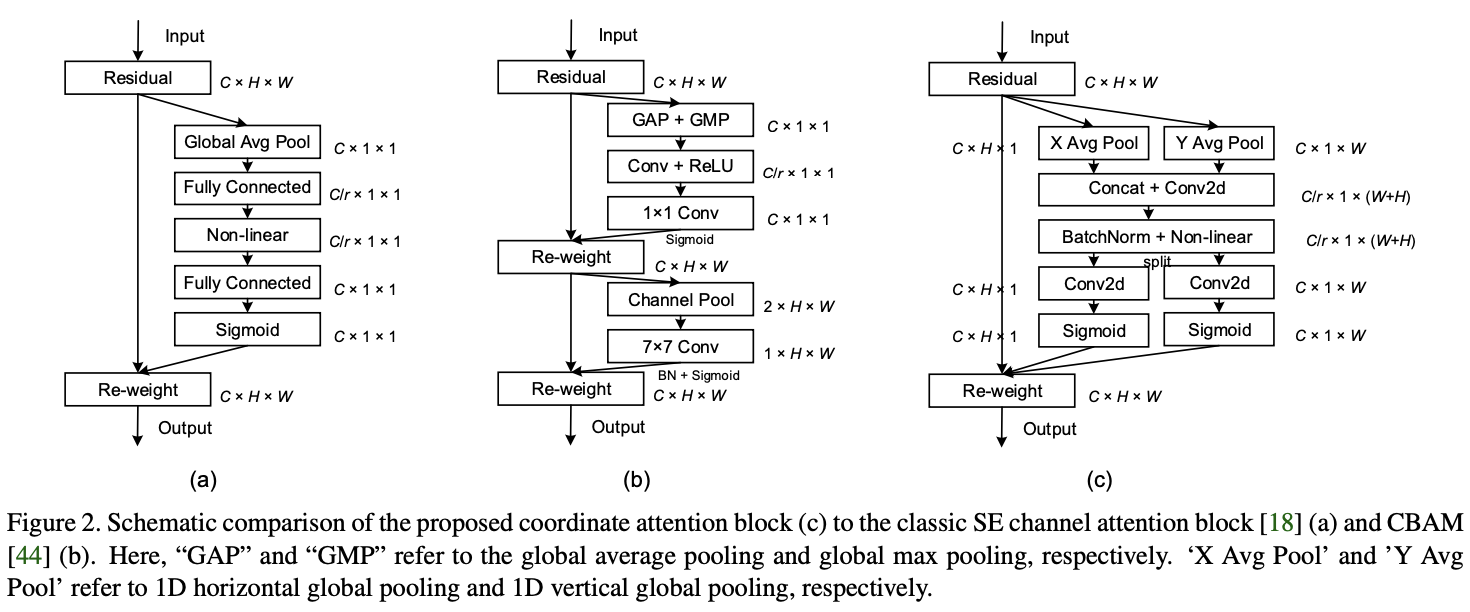
Coordinate Attention Blocks
Coordinate Attention be based on coordinate information embedding and coordinate attention generation There are two steps to encode the channel relationship and the long-distance relationship .
Coordinate Information Embedding
channel attention Common global pooling codes global spatial information , Compress the global information into a scalar , It is difficult to retain important spatial information . So , This paper transforms the global pooling into two 1 Coding operation of dimensional vector . For input \(X\), Use pooled cores \((H,1)\) and \((1,W)\) To encode horizontal and vertical features , That is to say \(c\) The output of dimension feature is :
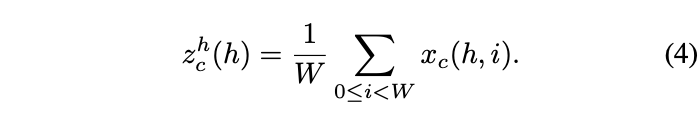
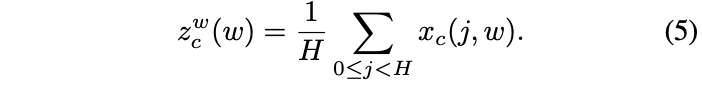
The above formula integrates features from different directions , Output a pair of feature maps with known directions . Compare the compression method of global pooling , This allows attention block Capture the long-distance relationship in one direction while preserving the spatial information in the other direction , Help the network locate the target more accurately .
Coordinate Attention Generation
In order to make better use of the above coordinate infomation, The paper puts forward the supporting coordinate attention generation operation , The design is mainly based on the following three criteria :
- Simple and light enough .
- Can make full use of the extracted location information .
- It can handle the relationship between channels equally efficiently .
First, put the formula 4 And the formula 5 Output concatenate get up , Use \(1\times 1\) Convolution 、BN And nonlinear activation :
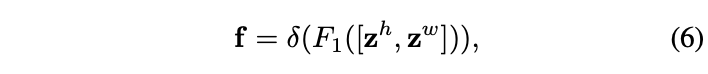
\(f\in\mathbb{R}^{C/r\times(H+W)}\) It is an intermediate feature containing horizontal and vertical spatial information ,\(r\) Is the reduction factor . The features of the two directions here are not fiercely integrated ,concatenate I think the main purpose of is to unify BN operation . And then \(f\) It is divided into two independent features \(f^h\in\mathbb{R}^{C/r\times H}\) and \(f^w\in\mathbb{R}^{C/r\times W}\), Use the other two \(1\times 1\) Convolution sum sigmoid Function for feature transformation , Make its dimension and input \(X\) Agreement :
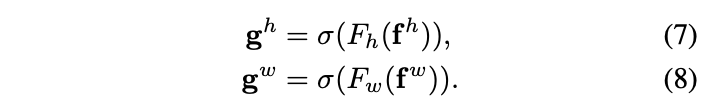
Will output \(g^h\) and \(g^w\) Merge into weight matrix , Used to calculate coordinate attention block Output :
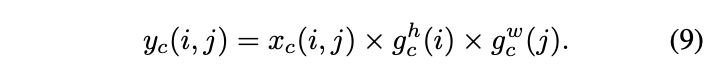
coordinate attention block And se block The biggest difference is ,coordinate attention block Each weight of contains information between channels 、 Horizontal spatial information and vertical spatial information , It can help the network locate the target information more accurately , Enhance recognition .
Implementation
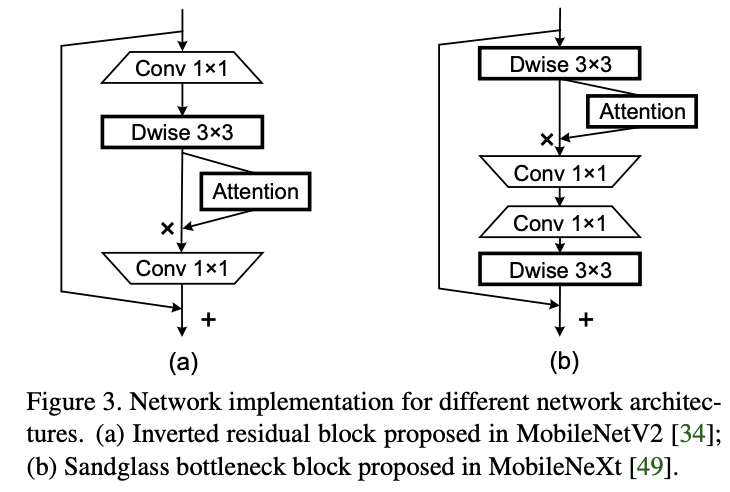
take coordinate attention block be applied to MobileNetV2 and MobileNeXt On ,block Structure is shown in figure 3 Shown .
Experiment
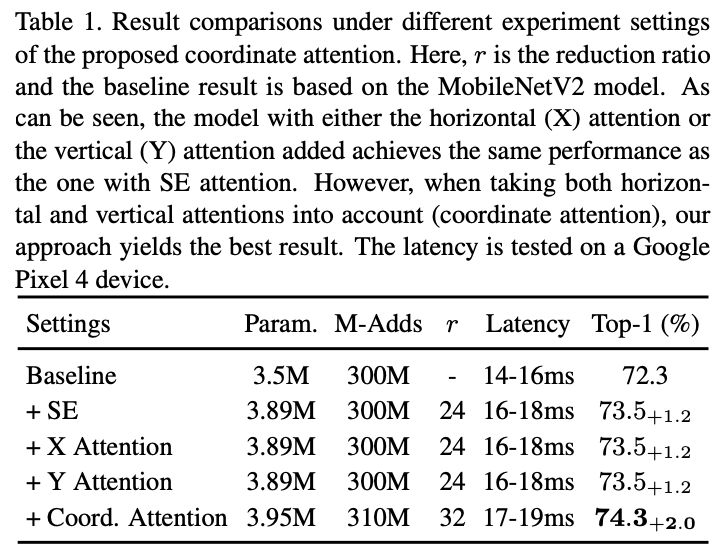
be based on MobileNetV2 Carry out the comparative experiment of module setting .
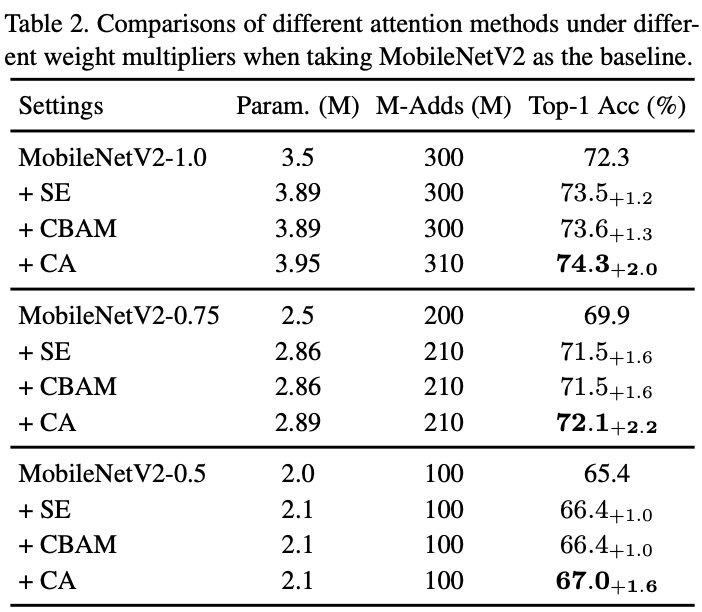
Performance comparison of different attention structures on different backbone networks .
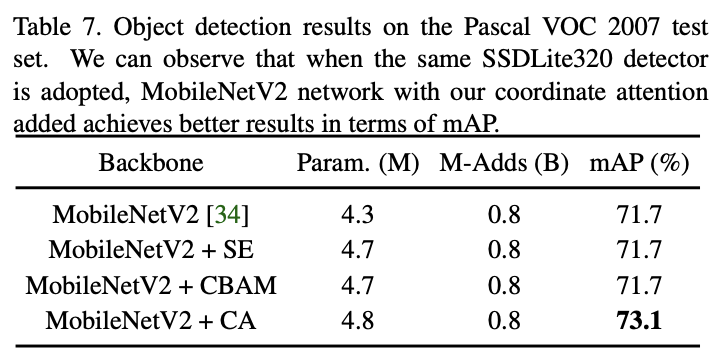
Performance comparison of target detection network .
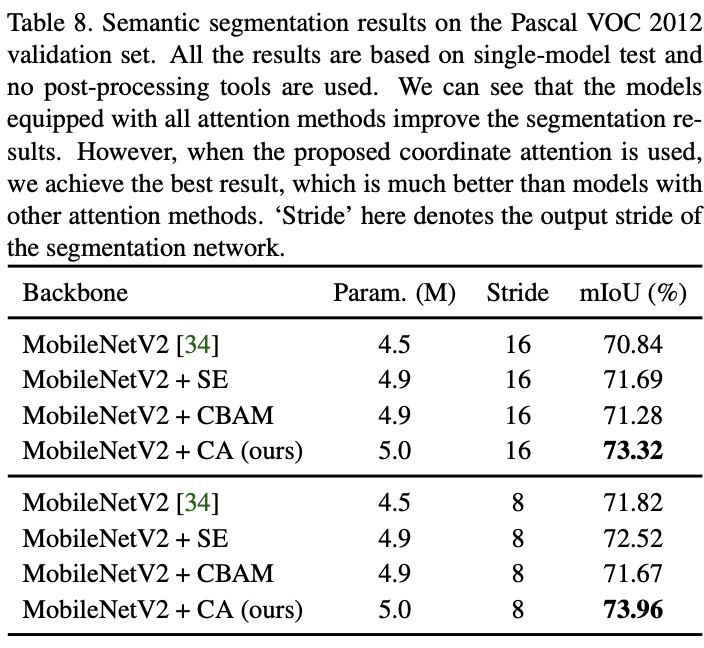
Performance comparison of semantic segmentation tasks .
Conclusion
This paper proposes a novel lightweight channel attention mechanism coordinate attention, Be able to consider the relationship between channels and long-distance location information at the same time . It is found through experiments that ,coordinate attention It can effectively improve the accuracy of the model , And it only brings a small amount of computing consumption , Very good .
If this article helps you , Please give me a compliment or watch it ~
More on this WeChat official account 【 Xiaofei's algorithm Engineering Notes 】