当前位置:网站首页>爬虫练习题(一)
爬虫练习题(一)
2022-07-04 12:37:00 【InfoQ】
import requests
word = input("请输入搜索内容")
start = int(input("请输入起始页"))
end = int(input("请输入结束页"))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word}的第{n}页。html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))

https://www.sogou.com/web?query=python&page=2&ie=utf8url = f'https://www.sogou.com/web?query={word}&page={n}'
https://www.sogou.com/web?query=Python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=12736&sst0=1650428312860&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428312860
https://www.sogou.com/web?query=java&_ast=1650428313&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=10734&sst0=1650428363389&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428363389
https://www.sogou.com/web?query=C%E8%AF%AD%E8%A8%80&_ast=1650428364&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=11662&sst0=1650428406805&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428406805
https://www.sogou.com/web?
https://www.sogou.com/web?query=Python&
https://www.sogou.com/web?query=Python&page=2&ie=utf8
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
'cookie' = "IPLOC=CN3600; SUID=191166B6364A910A00000000625F8708; SUV=1650427656976942; browerV=3; osV=1; ABTEST=0|1650428297|v17; SNUID=636A1DCD7B7EA775332A80CB7B347D43; sst0=663; [email protected]@@@@@@@@@; LSTMV=229,37; LCLKINT=1424"
'URl' = "https://www.sogou.com/web?query=Python&_ast=1650429998&_asf=www.sogou.com&w=01029901&cid=&s_from=result_up&sut=5547&sst0=1650430005573&lkt=0,0,0&sugsuv=1650427656976942&sugtime=1650430005573"
url="https://www.sogou.com/web?query={}&page={}:
" ":" ",
# 构建字典的格式,','千万千万别忘了
# headers是关键字不能写错了,写错的话就会有如下报错
import requests
url = "https://www.bxwxorg.com/"
hearders = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, hearders=hearders)
print(response.content.decode("UTF-8"))
Traceback (most recent call last):
File "D:/pythonproject/第二次作业.py", line 141, in <module>
response = requests.get(url, hearders=hearders)
File "D:\python37\lib\site-packages\requests\api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "D:\python37\lib\site-packages\requests\api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
TypeError: request() got an unexpected keyword argument 'hearders'
# 原因:三个hearders写的一致,但是headers是关键字,所以报类型错误
# 但是写成heades会有另一种报错形式
import requests
word = input("请输入搜索内容")
start = int(input("请输入起始页"))
end = int(input("请输入结束页"))
heades = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word}的第{n}页。html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))
Traceback (most recent call last):
File "D:/pythonproject/第二次作业.py", line 117, in <module>
response = requests.get(url, headers=headers)
NameError: name 'headers' is not defined
# 原因:三个hearders写的不一致,所以报名称错误
# 正确写法是,最好不要写错!
import requests
url = "https://www.bxwxorg.com/"
headers = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, headers=headers)
print(response.content.decode("UTF-8"))
for n in range(start, end + 1):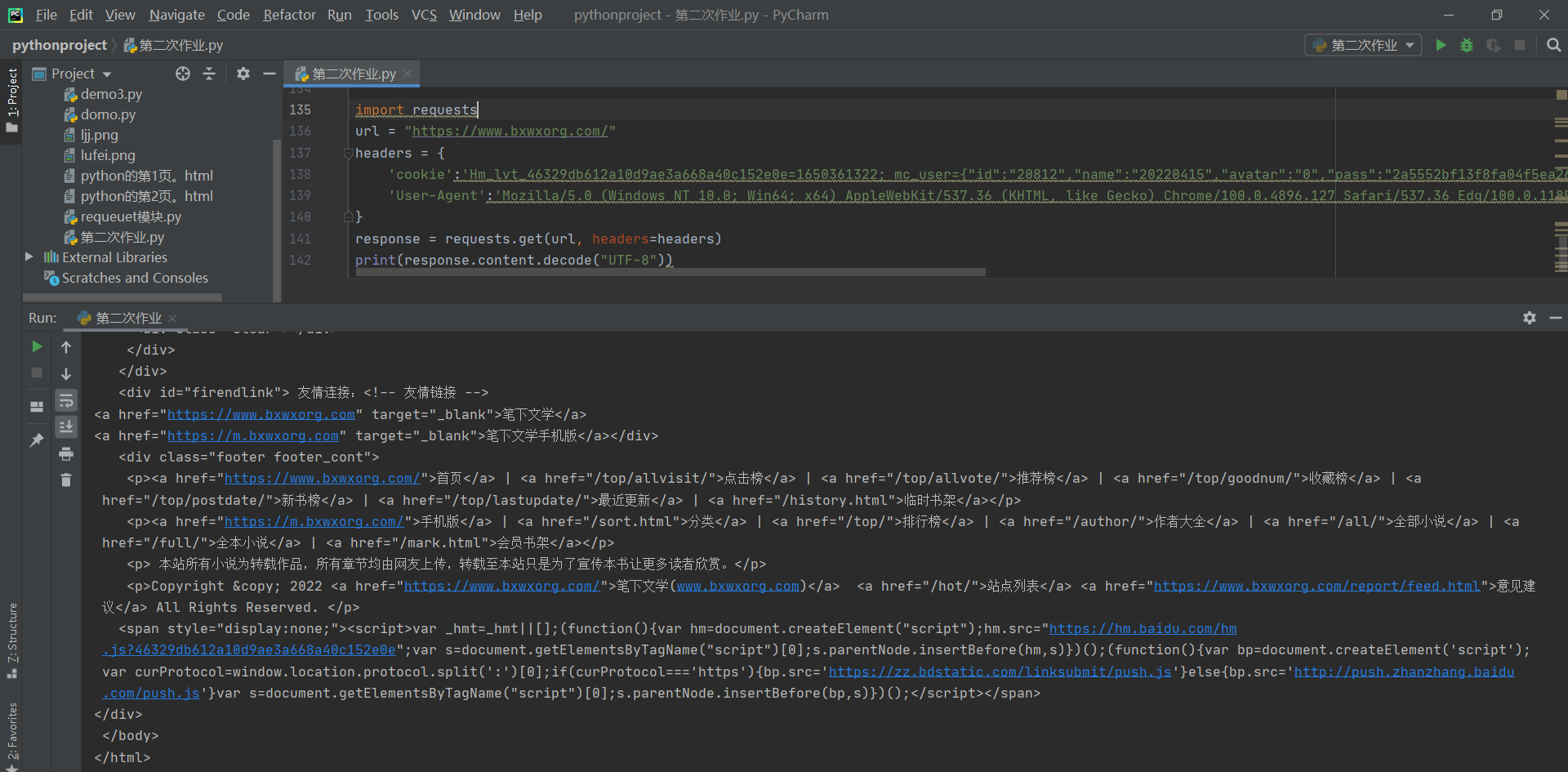
边栏推荐
- Error: Failed to download metadata for repo ‘AppStream‘: Cannot download repomd. XML solution
- 美团·阿里关于多模态召回的应用实践
- PostgreSQL 9.1 飞升之路
- 洞见科技解决方案总监薛婧:联邦学习助力数据要素安全流通
- Etcd 存储,Watch 以及过期机制
- Two dimensional code coding theory
- 读《认知觉醒》
- Abnormal mode of ARM processor
- Transformer principle and code elaboration (tensorflow)
- ArgMiner:一个用于对论点挖掘数据集进行处理、增强、训练和推理的 PyTorch 的包
猜你喜欢
Introduction to the button control elevatedbutton of the fleet tutorial (the tutorial includes the source code)

昨天的事情想说一下

ISO 27001 Information Security Management System Certification
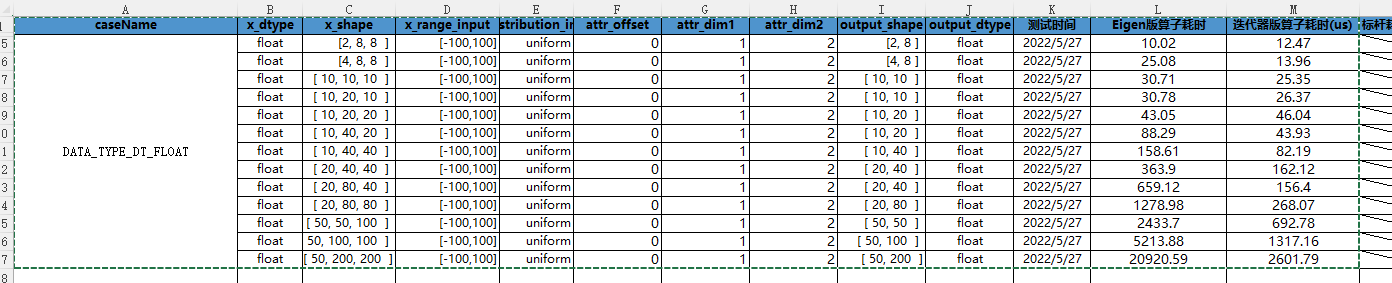
Cann operator: using iterators to efficiently realize tensor data cutting and blocking processing
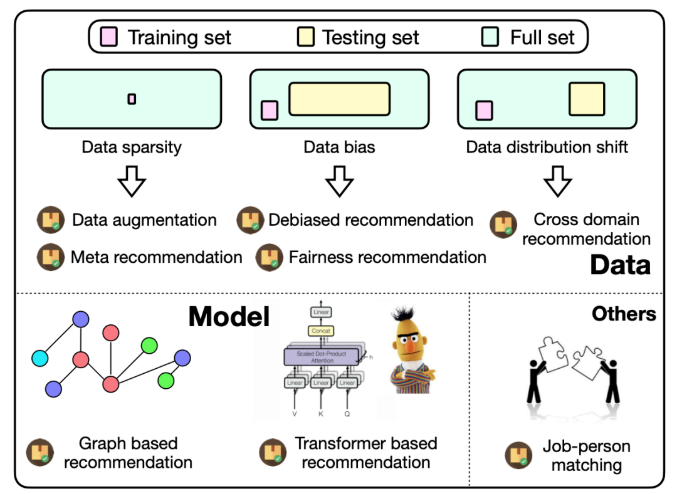
8个扩展子包!RecBole推出2.0!
AI painting minimalist tutorial

洞见科技解决方案总监薛婧:联邦学习助力数据要素安全流通
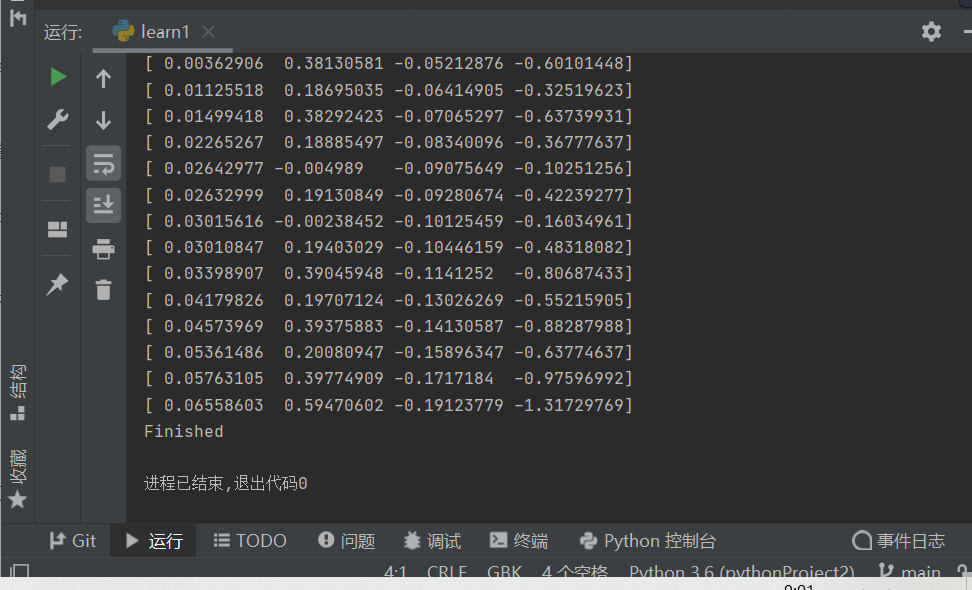
强化学习-学习笔记1 | 基础概念
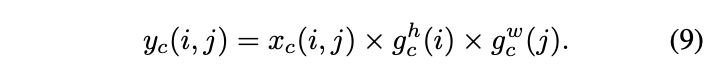
CA:用于移动端的高效坐标注意力机制 | CVPR 2021

How to realize the function of Sub Ledger of applet?
随机推荐
Interviewer: what is the difference between redis expiration deletion strategy and memory obsolescence strategy?
Peak detection of measured signal
Cann operator: using iterators to efficiently realize tensor data cutting and blocking processing
Building intelligent gray-scale data system from 0 to 1: Taking vivo game center as an example
I want to talk about yesterday
Kivy教程之 08 倒计时App实现timer调用(教程含源码)
Langue C: trouver le nombre de palindromes dont 100 - 999 est un multiple de 7
runc hang 导致 Kubernetes 节点 NotReady
面向个性化需求的在线云数据库混合调优系统 | SIGMOD 2022入选论文解读
Argminer: a pytorch package for processing, enhancing, training, and reasoning argument mining datasets
How to realize the function of Sub Ledger of applet?
C语言:求字符串的长度
Practice of retro SOAP Protocol
MDK在头文件中使用预编译器时,#ifdef 无效的问题
WPF双滑块控件以及强制捕获鼠标事件焦点
【数据聚类】第四章第一节3:DBSCAN性能分析、优缺点和参数选择方法
强化学习-学习笔记1 | 基础概念
求解:在oracle中如何用一条语句用delete删除两个表中jack的信息
[leetcode] 96 and 95 (how to calculate all legal BST)
CA:用于移动端的高效坐标注意力机制 | CVPR 2021