当前位置:网站首页>Calculate weight and comprehensive score by R entropy weight method
Calculate weight and comprehensive score by R entropy weight method
2022-07-05 15:04:00 【See the sea for the first time】
In recent work, we need to calculate intelligently according to big data , Predict or recommend supply chain payment priority / Power comes back , In the past, it was a priority to make payment manually according to factors such as supplier relationship , It cannot objectively distribute payment strategies to other suppliers , Now it is calculated objectively according to big data , Make a note of
1, get data
Get data from starRocks,
library(RMySQL)
library(tibble)
library(dplyr)
criterions_cite <- function(){
# Establishing a connection ,project_name Represents the name of the project database
conn <- dbConnect(MySQL(), dbname = 'ods', username = 'pxxx', password = 'xxx', host = 'xx.xx.xx.xx', port = 9030)
# If there is Chinese garbled in the table , You can add the following code
#dbSendQuery(conn, 'SET NAMES GBK')
#sheet_name Indicates the name of the table to be read
filter_statements <- paste0('SELECT * FROM ods_fkyc_local')
# Filtering data
res <- dbSendQuery(conn, filter_statements)
# Extract the data ,-1 It means extract all ,3 It means taking three rows of data
dat <- dbFetch(res, -1)
# close RMySQL Data set in
dbClearResult(dbListResults(conn)[[1]])
# Close the connection
dbDisconnect(conn)
return(dat)
}
# Get the data set from the database
mydt <- criterions_cite()
tb.mydt <- as_tibble(mydt)2, Specify the positive , Negative indicators
Like sales , The larger the negative selling amount, the better it can be specified as a positive indicator
Like defective inventory , Unsalable inventory , Amount in arrears This kind of index is about as few as possible, and it is designated as a negative index
# 1, normalization , Positive indicators
min_max_norm <- function(x) {
(x - min(x)) / (max(x) - min(x))
}
# Negative indicators
max_min_norm <- function(x) {
(max(x) - x) / (max(x) - min(x))
}
# normalization , First deal with positive indicators
min_max_norm_mydt <- tb.mydt %>% mutate(across(c(9,13,14), min_max_norm))
# Then deal with the negative indicators first
max_min_norm_mydt <- min_max_norm_mydt %>% mutate(across(c(10,11,12), max_min_norm))
3, Calculate the index after normalization
p_value <- function(x){
x / sum(x)
}
p_mydt <- max_min_norm_mydt %>% mutate(across(c(9:14), p_value))
## Calculate the entropy
entropy <- function(x){
n <- length(x)
(-1 / log2(n)) * (sum( x * ifelse(log2(x)==-Inf, 0, log2(x)) ))
}
e_mydt <- p_mydt %>% summarise(across(c(9:14), entropy))
e_mydt
d_mydt = 1-e_mydt
d_mydt
w = d_mydt/sum(d_mydt)
w
w And is the weight
4, Then calculate the comprehensive score and rank , Then export
fscore <- function(x, y){
sum(x*y)
}
old_data <- rename(tb.mydt[,9:14],c(old_ZPO_K001_sum="ZPO_K001_sum",old_zpo_k006_sum="zpo_k006_sum",old_zx0030_sum="zx0030_sum",old_fyjj201to03_sum="fyjj201to03_sum",old_wpfm_sum="wpfm_sum",old_total_amount="total_amount"))
result_data=cbind(max_min_norm_mydt,old_data)
mydt3 <- result_data %>% group_by(1:n()) %>% mutate(score = fscore(c_across(9:14), w)) %>% arrange(-score) %>% ungroup() %>% select("com_code","organization_name","lifnr","name1","dept_no","dept_name","brand_code","brand_name","ZPO_K001_sum","zpo_k006_sum","zx0030_sum","fyjj201to03_sum","wpfm_sum","total_amount","old_ZPO_K001_sum","old_zpo_k006_sum","old_zx0030_sum","old_fyjj201to03_sum","old_wpfm_sum","old_total_amount","score")
write.table(mydt3, file = "/app/bigdata_app/data/fkyc/MyData.csv",quote = FALSE,row.names=FALSE, col.names=FALSE)
Export the calculated data csv file , and streamload Into the starRocks in
边栏推荐
猜你喜欢
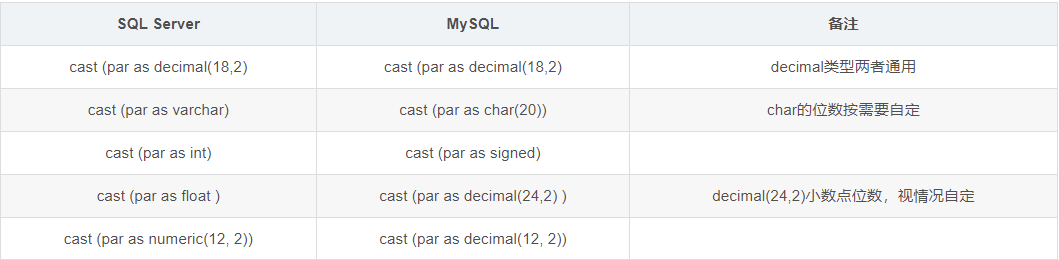
sql server学习笔记

30岁汇源,要换新主人了

可视化任务编排&拖拉拽 | Scaleph 基于 Apache SeaTunnel的数据集成
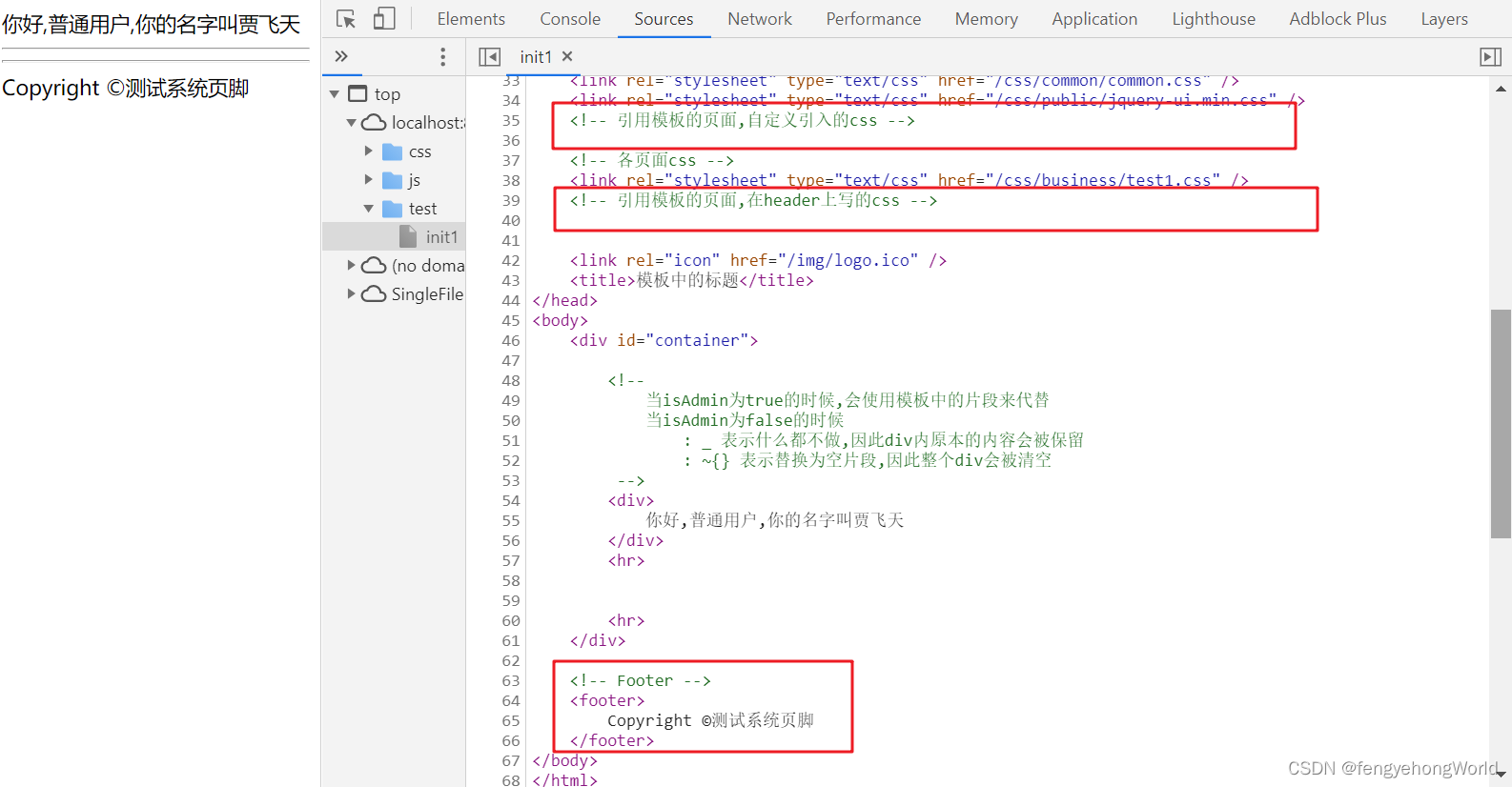
Creation and use of thymeleaf template

Crud of MySQL

超越PaLM!北大硕士提出DiVeRSe,全面刷新NLP推理排行榜
MySQL之CRUD
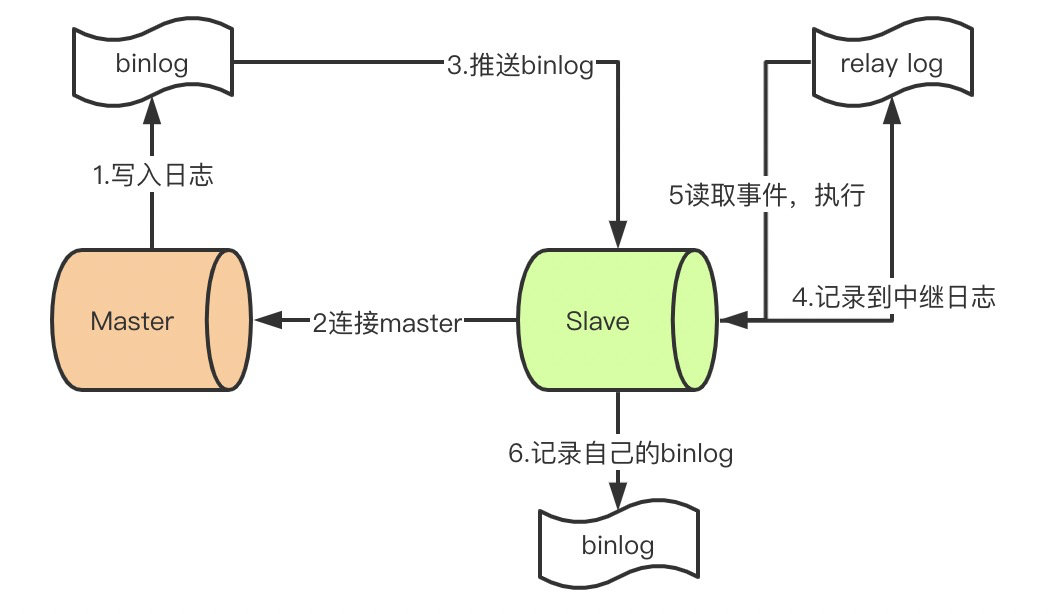
想进阿里必须啃透的12道MySQL面试题
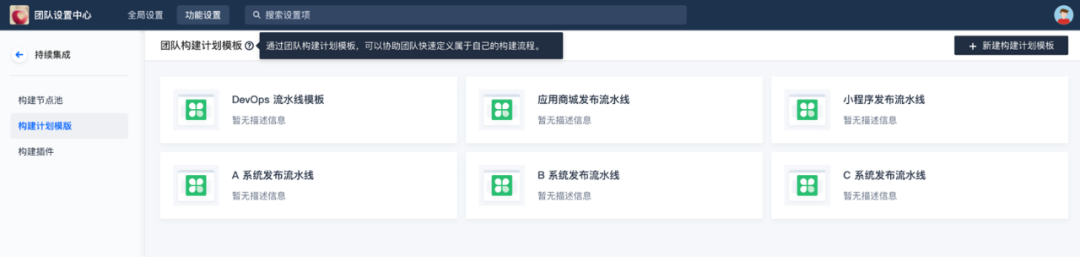
Coding devsecops helps financial enterprises run out of digital acceleration

Drive brushless DC motor based on Ti drv10970
随机推荐
做研究无人咨询、与学生不交心,UNC助理教授两年教职挣扎史
Long list optimized virtual scrolling
FR练习题目---简单题
【数组和进阶指针经典笔试题12道】这些题,满足你对数组和指针的所有幻想,come on !
Install and configure Jenkins
超越PaLM!北大硕士提出DiVeRSe,全面刷新NLP推理排行榜
Photoshop plug-in - action related concepts - actions in non loaded execution action files - PS plug-in development
Magic methods and usage in PHP (PHP interview theory questions)
外盘入金都不是对公转吗,那怎么保障安全?
【华为机试真题详解】字符统计及重排
【华为机试真题详解】欢乐的周末
Crud of MySQL
[JVM] operation instruction
美团优选管理层变动:老将刘薇调岗,前阿里高管加盟
Two Bi development, more than 3000 reports? How to do it?
[detailed explanation of Huawei machine test] happy weekend
sql server学习笔记
TS所有dom元素的类型声明
[summary of leetcode weekly competition] the 81st fortnight competition of leetcode (6.25)
Ecotone technology has passed ISO27001 and iso21434 safety management system certification