当前位置:网站首页>3.3 Monte Carlo Methods: case study: Blackjack of Policy Improvement of on- & off-policy Evaluation
3.3 Monte Carlo Methods: case study: Blackjack of Policy Improvement of on- & off-policy Evaluation
2022-07-03 10:09:00 【Most appropriate commitment】
Catalog
Background
In 3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation, we finished the evaluation of the on-policy Monte Carlo Method. And in 3.2 Off-Policy Monte Carlo Methods & case study: Blackjack of off-Policy Evaluation, we completed the evaluation of the off-policy Monte Carlo Method and comparision between off-policy and on-policy method. In this article, we will summarize the policy improvement for both Monte Carlo Method.
For generalized Policy improvement, we do not let q(s,a) or v(s) converge and just let the loop of evaluation and improvement keep going. Finally, the result will go to the optimal policy.
However, I have a confusion that in Monte Carlo methods, if our policy is deterministic, we could not get q(s,a) or v(s,a) for every pair of state and action. How could we improve our policy by partially missed value / state-action function?
On-policy Method
we have to compromise between exploitation and exploration. So the policy will be soft-greedy policy.
Code:
## settings
import math
import numpy as np
import random
# visualization
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
import copy
# state
# card scope
CARD_MINIMUM = 4;
CARD_MAXIMUM = 20;
CARD_TERMINAL = 21;
# rival's shown card
SHOWN_NUMBER_MINIMUM = 1;
SHOWN_NUMBER_MAXIMUM = 10;
# if we have usable Ace
ACE_ABLE = 1;
ACE_DISABLE = 0;
# action we can take
STICK = 0;
HIT = 1;
ACTION = [STICK,HIT];
# Reward of result
R_proceed = 0;
R_WIN = 1;
R_DRAW = 0;
R_LOSE = -1;
# loop number
LOOP_IMPROVEMENT = 1000;
LOOP_EVALUATION =1000;
# soft policy
SIGMA = 0.1;
#policy
# our target policy stick at 20&21, or hit
pi_a_s = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
for card in range(CARD_MINIMUM,CARD_MAXIMUM+1):
if card < 20:
pi_a_s[card,:,:,STICK] = SIGMA/len(ACTION);
pi_a_s[card,:,:,HIT] = 1+SIGMA/len(ACTION)-SIGMA;
else:
pi_a_s[card,:,:,STICK] = 1+SIGMA/len(ACTION)-SIGMA;
pi_a_s[card,:,:,HIT] = SIGMA/len(ACTION);
# rival policy stick on 17 or greater,
pi_rival_a_s = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
for card in range(CARD_MINIMUM,CARD_MAXIMUM+1):
if card < 17:
pi_rival_a_s[card,:,:,STICK] = 0;
pi_rival_a_s[card,:,:,HIT] = 1;
else:
pi_rival_a_s[card,:,:,STICK] = 1;
pi_rival_a_s[card,:,:,HIT] = 0;
# behavior policy random
b_a_s = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
for card in range(CARD_MINIMUM,CARD_MAXIMUM+1):
for act in ACTION:
b_a_s[card,:,:,act]= 1.0/len(ACTION);
# function
#actions taken by policy and current sum_card
def get_action(sum_card,showncard,usable_ace,policy):
p=[];
for act in ACTION:
p.append(policy[sum_card,showncard,usable_ace,act]);
return np.random.choice(ACTION,p=p);
## set class for agent/rival to get sampling
class Agent_rival_class():
def __init__(self):
self.total_card=0;
self.card_set=[];
self.action_set=[];
self.last_action=HIT;
self.state = 'NORMAL&HIT';
self.showncard=0;
self.usable_ace=ACE_DISABLE;
for initial in range(0,2):
card = random.randint(1,14);
if card > 10:
card = 10;
if card == 1:
if self.usable_ace == ACE_ABLE:
card = 1;
else:
card = 11;
self.usable_ace = ACE_ABLE;
if initial == 0:
self.showncard = card;
if self.showncard == 11:
self.showncard = 1;
self.card_set.append(card);
self.total_card += card;
Agent_rival_class.check(self);
def check(self):
if self.total_card == 21:
self.state = 'TOP';
if self.total_card > 21:
self.state = 'BREAK';
if self.total_card < 21 and self.last_action == STICK:
self.state = 'NORMAL&STICK';
def behave(self,behave_policy):
self.last_action = get_action(self.total_card,self.showncard,self.usable_ace,behave_policy);
self.action_set.append(self.last_action);
if self.last_action == HIT:
card = random.randint(1,14);
if card > 10:
card = 10;
if card == 1:
if self.usable_ace == ACE_ABLE:
card = 1;
else:
card = 11;
self.usable_ace = ACE_ABLE;
self.total_card += card;
# make sure cards in set cards are from 1 to 10. without 11.
if card ==11:
self.card_set.append(1);
if self.total_card > 21 and self.usable_ace == ACE_ABLE:
self.total_card -= 10;
self.usable_ace = ACE_DISABLE;
Agent_rival_class.check(self);
# visualization function
def visual_func_s_a_1_4(func,sub_limit,sup_limit,title):
fig, axes = plt.subplots(1,4,figsize=(30,50))
plt.subplots_adjust(left=None,bottom=None,right=None,top=None,wspace=0.5,hspace=0.5)
FONT_SIZE = 10;
xlabel=[]
ylabel=[]
for i in range(4,20+1):
ylabel.append(str(i))
for j in range(1,10+1):
xlabel.append(str(j))
# ordinary sample
#for 1,1 no Ace and stick
axes[0].set_xticks(range(0,10,1))
axes[0].set_xticklabels(xlabel)
axes[0].set_yticks(range(0,17,1) )
axes[0].set_yticklabels(ylabel)
axes[0].set_title('when no usable Ace and STICK',fontsize=FONT_SIZE)
im1 = axes[0].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_DISABLE,STICK],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,2 no Ace and hit
axes[1].set_xticks(range(0,10,1))
axes[1].set_xticklabels(xlabel)
axes[1].set_yticks(range(0,17,1) )
axes[1].set_yticklabels(ylabel)
axes[1].set_title('when no usable Ace and HIT',fontsize=FONT_SIZE)
im1 = axes[1].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_DISABLE,HIT],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,3 Ace and stick
axes[2].set_xticks(range(0,10,1))
axes[2].set_xticklabels(xlabel)
axes[2].set_yticks(range(0,17,1) )
axes[2].set_yticklabels(ylabel)
axes[2].set_title(' when usable Ace and STICK',fontsize=FONT_SIZE)
im1 = axes[2].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_ABLE,STICK],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,4 Ace and hit
axes[3].set_xticks(range(0,10,1))
axes[3].set_xticklabels(xlabel)
axes[3].set_yticks(range(0,17,1) )
axes[3].set_yticklabels(ylabel)
axes[3].set_title(' when usable Ace and HIT',fontsize=FONT_SIZE)
im1 = axes[3].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_ABLE,HIT],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
fig.suptitle(title,fontsize=15)
fig.colorbar(im1,ax=axes.ravel().tolist())
def visual_func_s_a_1_2(func,sub_limit,sup_limit,title):
fig, axes = plt.subplots(1,2,figsize=(30,50))
plt.subplots_adjust(left=None,bottom=None,right=None,top=None,wspace=0.5,hspace=0.5)
FONT_SIZE = 10;
xlabel=[]
ylabel=[]
for i in range(4,20+1):
ylabel.append(str(i))
for j in range(1,10+1):
xlabel.append(str(j))
# ordinary sample
#for 1,1
axes[0].set_xticks(range(0,10,1))
axes[0].set_xticklabels(xlabel)
axes[0].set_yticks(range(0,17,1) )
axes[0].set_yticklabels(ylabel)
axes[0].set_title('when usable Ace',fontsize=FONT_SIZE)
im1 = axes[0].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_ABLE],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,2
axes[1].set_xticks(range(0,10,1))
axes[1].set_xticklabels(xlabel)
axes[1].set_yticks(range(0,17,1) )
axes[1].set_yticklabels(ylabel)
axes[1].set_title('when no usable Ace',fontsize=FONT_SIZE)
im1 = axes[1].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_DISABLE],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
fig.suptitle(title,fontsize=15)
fig.colorbar(im1,ax=axes.ravel().tolist())
# main programme
#rewards obtained
Q_s_a_ordinary = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64);
Q_n_ordinary=np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)));
V_s_ordinary = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2),dtype = np.float64);
V_n_ordinary=np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
Q_s_a_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64);
Q_ratio_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
V_s_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2),dtype = np.float64);
V_ratio_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2),dtype = np.float64)
# choose the policy to decide off-policy or on-policy
# initialization of policies
# TARGET_POLICY will change in policy improvement
BEHAVIOR_POLICY = pi_a_s;
TARGET_POLICY = pi_a_s;
POLICY_UPDATION=[];
POLICY_UPDATION.append(copy.deepcopy(TARGET_POLICY));
xlabel=[];
policy_start=[];
policy_optimal=[];
# policy evaluation
for every_loop_improvement in range(0,LOOP_IMPROVEMENT):
for every_loop_evaluation in range(0,LOOP_EVALUATION):
S=[];
agent = Agent_rival_class();
rival = Agent_rival_class();
R_T = 0;
ratio = 1;
# obtain samples
# initialization of 21
if agent.state=='TOP' or rival.state=='TOP':
continue;
S.append([agent.total_card,rival.showncard,agent.usable_ace]);
while(agent.state=='NORMAL&HIT'):
# change the policy for behavioral policy
agent.behave(BEHAVIOR_POLICY);
S.append([agent.total_card,rival.showncard,agent.usable_ace]);
if agent.state == 'BREAK':
R_T = -1;
elif agent.state == 'TOP':
R_T = 1;
else:
while(rival.state=='NORMAL&HIT'):
rival.behave(pi_rival_a_s);
if rival.state == 'BREAK':
R_T = 1;
elif rival.state == 'TOP':
R_T = 0;
else:
if agent.total_card > rival.total_card:
R_T = 1;
elif agent.total_card < rival.total_card:
R_T = -1;
else:
R_T = 0;
# policy evaluation & policy improvement
G = R_T; # because R in the process is zero.
for i in range(1,len(agent.action_set)+1):
j = -i;
ratio *= TARGET_POLICY[ S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j] ]/BEHAVIOR_POLICY[ S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j] ];
# q_s_a for ordinary sample
Q_s_a_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] = Q_s_a_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] *\
Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]/(Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]+1) \
+ ratio*G/(Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]+1);
Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] +=1 ;
# V_s for ordinary sample
V_s_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]] = V_s_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]] *\
V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]]/(V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]]+1) \
+ ratio*G/(V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]]+1);
V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]] +=1 ;
# q_s_a for weighed sample
if ratio != 0 or Q_s_a_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] != 0:
Q_s_a_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] = Q_s_a_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] * \
Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] / (ratio + Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]) \
+ ratio * G / (ratio + Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]) ;
Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] += ratio;
# V_s for ordinary sample
if ratio != 0 or V_s_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] != 0:
V_s_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] = V_s_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] * \
V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] / (ratio + V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]]) \
+ ratio * G / (ratio + V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]]) ;
V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] += ratio;
# policy improvement
action_max =ACTION[ np.argmax( Q_s_a_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],:] ) ];
TARGET_POLICY[ S[j-1][0],S[j-1][1] ,S[j-1][2] ,: ] = SIGMA/len(ACTION);
TARGET_POLICY[ S[j-1][0],S[j-1][1],S[j-1][2],action_max ] = 1+SIGMA/len(ACTION)-SIGMA;
if action_max != agent.action_set[j]:
POLICY_UPDATION.append(copy.deepcopy(TARGET_POLICY));
break;
# visualization
# policy optimal
POLICY_RESULT = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
POLICY_RESULT_BY_POLICY = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
for card_num in range(CARD_MINIMUM,CARD_MAXIMUM+1):
for shown_num in range(SHOWN_NUMBER_MINIMUM,SHOWN_NUMBER_MAXIMUM+1):
for ace in range(0,2):
POLICY_RESULT[card_num,shown_num,ace] = ACTION[ np.argmax( Q_s_a_ordinary[card_num,shown_num,ace,:] ) ]
POLICY_RESULT_BY_POLICY[card_num,shown_num,ace] = ACTION[ np.argmax( TARGET_POLICY[card_num,shown_num,ace,:] ) ]
print(len(POLICY_UPDATION))
for i in range(0,len(POLICY_UPDATION)):
if i%100000 == 0:
POLICY_MIDDLE=np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
for card_num in range(CARD_MINIMUM,CARD_MAXIMUM+1):
for shown_num in range(SHOWN_NUMBER_MINIMUM,SHOWN_NUMBER_MAXIMUM+1):
for ace in range(0,2):
POLICY_MIDDLE[card_num,shown_num,ace] = ACTION[ np.argmax( POLICY_UPDATION[i][card_num,shown_num,ace,:] ) ]
visual_func_s_a_1_2(POLICY_MIDDLE,-1,1,'policy loop number: '+str(i));
visual_func_s_a_1_2(POLICY_RESULT,-1,1,'optimal policy');
# for state-action function
# oridnary sample
visual_func_s_a_1_4(Q_s_a_ordinary,-1,1,'state-action function in ordinary sample')
# weighed sample
visual_func_s_a_1_4(Q_s_a_weigh,-1,1,'state-action function in weighed sample')
# for value function
# ordinary sample
visual_func_s_a_1_2(V_s_ordinary,-1,1,'value function in ordinary sample')
# weighed sample
visual_func_s_a_1_2(V_s_weigh,-1,1,'value function in weighed sample')
# optimal policy show
visual_func_s_a_1_2(POLICY_RESULT,-1,1,'optimal policy by q_a_s')
# updation number
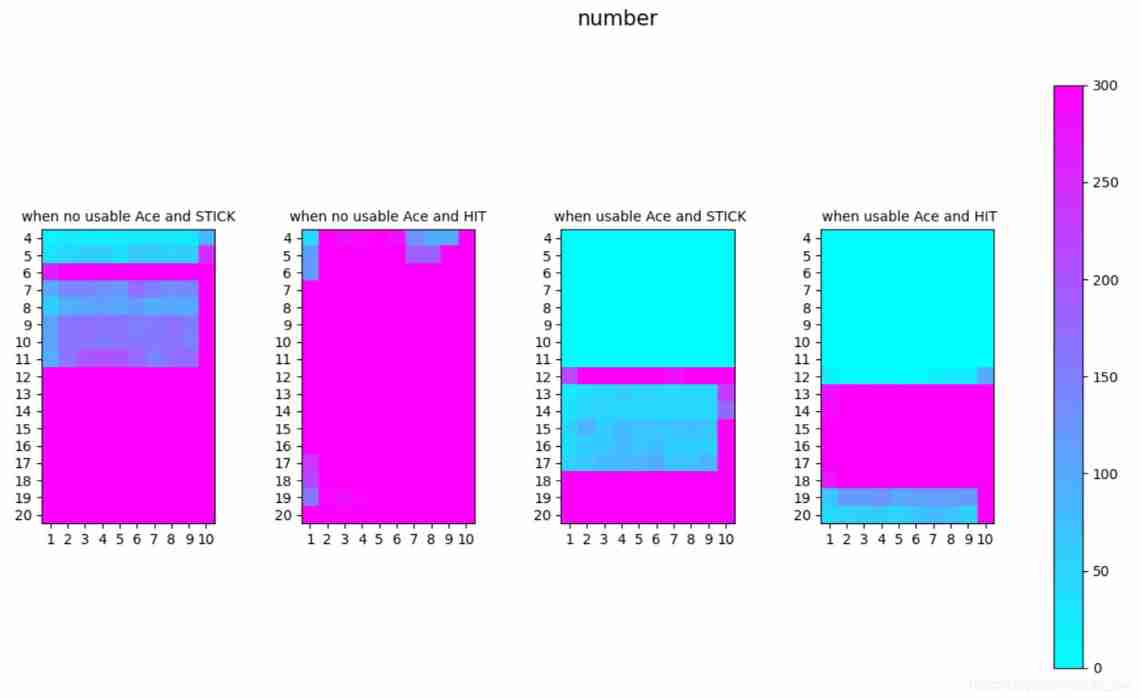
visual_func_s_a_1_4(Q_n_ordinary,0,300,'number')
plt.show();Result:



Off-policy Method
Code
## settings
import math
import numpy as np
import random
# visualization
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
import copy
# state
# card scope
CARD_MINIMUM = 4;
CARD_MAXIMUM = 20;
CARD_TERMINAL = 21;
# rival's shown card
SHOWN_NUMBER_MINIMUM = 1;
SHOWN_NUMBER_MAXIMUM = 10;
# if we have usable Ace
ACE_ABLE = 1;
ACE_DISABLE = 0;
# action we can take
STICK = 0;
HIT = 1;
ACTION = [STICK,HIT];
# Reward of result
R_proceed = 0;
R_WIN = 1;
R_DRAW = 0;
R_LOSE = -1;
# loop number
LOOP_IMPROVEMENT = 1000;
LOOP_EVALUATION =1000;
#policy
# our target policy stick at 20&21, or hit
pi_a_s = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
for card in range(CARD_MINIMUM,CARD_MAXIMUM+1):
if card < 20:
pi_a_s[card,:,:,STICK] = 0;
pi_a_s[card,:,:,HIT] = 1;
else:
pi_a_s[card,:,:,STICK] = 1;
pi_a_s[card,:,:,HIT] = 0;
# rival policy stick on 17 or greater,
pi_rival_a_s = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
for card in range(CARD_MINIMUM,CARD_MAXIMUM+1):
if card < 17:
pi_rival_a_s[card,:,:,STICK] = 0;
pi_rival_a_s[card,:,:,HIT] = 1;
else:
pi_rival_a_s[card,:,:,STICK] = 1;
pi_rival_a_s[card,:,:,HIT] = 0;
# behavior policy random
b_a_s = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
for card in range(CARD_MINIMUM,CARD_MAXIMUM+1):
for act in ACTION:
b_a_s[card,:,:,act]= 1.0/len(ACTION);
# function
#actions taken by policy and current sum_card
def get_action(sum_card,showncard,usable_ace,policy):
p=[];
for act in ACTION:
p.append(policy[sum_card,showncard,usable_ace,act]);
return np.random.choice(ACTION,p=p);
## set class for agent/rival to get sampling
class Agent_rival_class():
def __init__(self):
self.total_card=0;
self.card_set=[];
self.action_set=[];
self.last_action=HIT;
self.state = 'NORMAL&HIT';
self.showncard=0;
self.usable_ace=ACE_DISABLE;
for initial in range(0,2):
card = random.randint(1,14);
if card > 10:
card = 10;
if card == 1:
if self.usable_ace == ACE_ABLE:
card = 1;
else:
card = 11;
self.usable_ace = ACE_ABLE;
if initial == 0:
self.showncard = card;
if self.showncard == 11:
self.showncard = 1;
self.card_set.append(card);
self.total_card += card;
Agent_rival_class.check(self);
def check(self):
if self.total_card == 21:
self.state = 'TOP';
if self.total_card > 21:
self.state = 'BREAK';
if self.total_card < 21 and self.last_action == STICK:
self.state = 'NORMAL&STICK';
def behave(self,behave_policy):
self.last_action = get_action(self.total_card,self.showncard,self.usable_ace,behave_policy);
self.action_set.append(self.last_action);
if self.last_action == HIT:
card = random.randint(1,14);
if card > 10:
card = 10;
if card == 1:
if self.usable_ace == ACE_ABLE:
card = 1;
else:
card = 11;
self.usable_ace = ACE_ABLE;
self.total_card += card;
# make sure cards in set cards are from 1 to 10. without 11.
if card ==11:
self.card_set.append(1);
if self.total_card > 21 and self.usable_ace == ACE_ABLE:
self.total_card -= 10;
self.usable_ace = ACE_DISABLE;
Agent_rival_class.check(self);
# visualization function
def visual_func_s_a_1_4(func,sub_limit,sup_limit,title):
fig, axes = plt.subplots(1,4,figsize=(30,50))
plt.subplots_adjust(left=None,bottom=None,right=None,top=None,wspace=0.5,hspace=0.5)
FONT_SIZE = 10;
xlabel=[]
ylabel=[]
for i in range(4,20+1):
ylabel.append(str(i))
for j in range(1,10+1):
xlabel.append(str(j))
# ordinary sample
#for 1,1 no Ace and stick
axes[0].set_xticks(range(0,10,1))
axes[0].set_xticklabels(xlabel)
axes[0].set_yticks(range(0,17,1) )
axes[0].set_yticklabels(ylabel)
axes[0].set_title('when no usable Ace and STICK',fontsize=FONT_SIZE)
im1 = axes[0].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_DISABLE,STICK],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,2 no Ace and hit
axes[1].set_xticks(range(0,10,1))
axes[1].set_xticklabels(xlabel)
axes[1].set_yticks(range(0,17,1) )
axes[1].set_yticklabels(ylabel)
axes[1].set_title('when no usable Ace and HIT',fontsize=FONT_SIZE)
im1 = axes[1].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_DISABLE,HIT],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,3 Ace and stick
axes[2].set_xticks(range(0,10,1))
axes[2].set_xticklabels(xlabel)
axes[2].set_yticks(range(0,17,1) )
axes[2].set_yticklabels(ylabel)
axes[2].set_title(' when usable Ace and STICK',fontsize=FONT_SIZE)
im1 = axes[2].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_ABLE,STICK],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,4 Ace and hit
axes[3].set_xticks(range(0,10,1))
axes[3].set_xticklabels(xlabel)
axes[3].set_yticks(range(0,17,1) )
axes[3].set_yticklabels(ylabel)
axes[3].set_title(' when usable Ace and HIT',fontsize=FONT_SIZE)
im1 = axes[3].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_ABLE,HIT],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
fig.suptitle(title,fontsize=15)
fig.colorbar(im1,ax=axes.ravel().tolist())
def visual_func_s_a_1_2(func,sub_limit,sup_limit,title):
fig, axes = plt.subplots(1,2,figsize=(30,50))
plt.subplots_adjust(left=None,bottom=None,right=None,top=None,wspace=0.5,hspace=0.5)
FONT_SIZE = 10;
xlabel=[]
ylabel=[]
for i in range(4,20+1):
ylabel.append(str(i))
for j in range(1,10+1):
xlabel.append(str(j))
# ordinary sample
#for 1,1
axes[0].set_xticks(range(0,10,1))
axes[0].set_xticklabels(xlabel)
axes[0].set_yticks(range(0,17,1) )
axes[0].set_yticklabels(ylabel)
axes[0].set_title('when usable Ace',fontsize=FONT_SIZE)
im1 = axes[0].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_ABLE],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
#for 1,2
axes[1].set_xticks(range(0,10,1))
axes[1].set_xticklabels(xlabel)
axes[1].set_yticks(range(0,17,1) )
axes[1].set_yticklabels(ylabel)
axes[1].set_title('when no usable Ace',fontsize=FONT_SIZE)
im1 = axes[1].imshow(func[CARD_MINIMUM:CARD_MAXIMUM+1,SHOWN_NUMBER_MINIMUM:SHOWN_NUMBER_MAXIMUM+1,ACE_DISABLE],cmap=plt.cm.cool,vmin=sub_limit, vmax=sup_limit)
fig.suptitle(title,fontsize=15)
fig.colorbar(im1,ax=axes.ravel().tolist())
# main programme
#rewards obtained
Q_s_a_ordinary = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64);
Q_n_ordinary=np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)));
V_s_ordinary = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2),dtype = np.float64);
V_n_ordinary=np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
Q_s_a_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64);
Q_ratio_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2,len(ACTION)),dtype = np.float64)
V_s_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2),dtype = np.float64);
V_ratio_weigh = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2),dtype = np.float64)
# choose the policy to decide off-policy or on-policy
# initialization of policies
# TARGET_POLICY will change in policy improvement
BEHAVIOR_POLICY = b_a_s;
TARGET_POLICY = pi_a_s;
POLICY_UPDATION=[];
POLICY_UPDATION.append(copy.deepcopy(TARGET_POLICY));
xlabel=[];
policy_start=[];
policy_optimal=[];
# policy evaluation
for every_loop_improvement in range(0,LOOP_IMPROVEMENT):
for every_loop_evaluation in range(0,LOOP_EVALUATION):
S=[];
agent = Agent_rival_class();
rival = Agent_rival_class();
R_T = 0;
ratio = 1;
# obtain samples
# initialization of 21
if agent.state=='TOP' or rival.state=='TOP':
continue;
S.append([agent.total_card,rival.showncard,agent.usable_ace]);
while(agent.state=='NORMAL&HIT'):
# change the policy for behavioral policy
agent.behave(BEHAVIOR_POLICY);
S.append([agent.total_card,rival.showncard,agent.usable_ace]);
if agent.state == 'BREAK':
R_T = -1;
elif agent.state == 'TOP':
R_T = 1;
else:
while(rival.state=='NORMAL&HIT'):
rival.behave(pi_rival_a_s);
if rival.state == 'BREAK':
R_T = 1;
elif rival.state == 'TOP':
R_T = 0;
else:
if agent.total_card > rival.total_card:
R_T = 1;
elif agent.total_card < rival.total_card:
R_T = -1;
else:
R_T = 0;
# policy evaluation & policy improvement
G = R_T; # because R in the process is zero.
for i in range(1,len(agent.action_set)+1):
j = -i;
ratio *= TARGET_POLICY[ S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j] ]/BEHAVIOR_POLICY[ S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j] ];
# q_s_a for ordinary sample
Q_s_a_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] = Q_s_a_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] *\
Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]/(Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]+1) \
+ ratio*G/(Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]+1);
Q_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] +=1 ;
# V_s for ordinary sample
V_s_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]] = V_s_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]] *\
V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]]/(V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]]+1) \
+ ratio*G/(V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]]+1);
V_n_ordinary[S[j-1][0],S[j-1][1],S[j-1][2]] +=1 ;
# q_s_a for weighed sample
if ratio != 0 or Q_s_a_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] != 0:
Q_s_a_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] = Q_s_a_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] * \
Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] / (ratio + Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]) \
+ ratio * G / (ratio + Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]]) ;
Q_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2],agent.action_set[j]] += ratio;
# V_s for ordinary sample
if ratio != 0 or V_s_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] != 0:
V_s_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] = V_s_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] * \
V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] / (ratio + V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]]) \
+ ratio * G / (ratio + V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]]) ;
V_ratio_weigh[S[j-1][0],S[j-1][1],S[j-1][2]] += ratio;
# policy improvement
action_max =ACTION[ np.argmax( Q_s_a_ordinary[S[j-1][0],S[j-1][1],S[j-1][2],:] ) ];
TARGET_POLICY[ S[j-1][0],S[j-1][1] ,S[j-1][2] ,: ] = 0;
TARGET_POLICY[ S[j-1][0],S[j-1][1],S[j-1][2],action_max ] = 1;
if action_max != agent.action_set[j]:
POLICY_UPDATION.append(copy.deepcopy(TARGET_POLICY));
break;
# visualization
# policy optimal
POLICY_ORIGINAL = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
POLICY_RESULT = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
POLICY_RESULT_BY_POLICY = np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
for card_num in range(CARD_MINIMUM,CARD_MAXIMUM+1):
for shown_num in range(SHOWN_NUMBER_MINIMUM,SHOWN_NUMBER_MAXIMUM+1):
for ace in range(0,2):
POLICY_ORIGINAL[card_num,shown_num,ace] = ACTION[ np.argmax( pi_a_s[card_num,shown_num,ace,:] ) ]
POLICY_RESULT[card_num,shown_num,ace] = ACTION[ np.argmax( Q_s_a_ordinary[card_num,shown_num,ace,:] ) ]
POLICY_RESULT_BY_POLICY[card_num,shown_num,ace] = ACTION[ np.argmax( TARGET_POLICY[card_num,shown_num,ace,:] ) ]
visual_func_s_a_1_2(POLICY_ORIGINAL,-1,1,'original policy')
print(len(POLICY_UPDATION))
for i in range(0,len(POLICY_UPDATION)):
if i%100000 == 0:
POLICY_MIDDLE=np.zeros((CARD_MAXIMUM+1,SHOWN_NUMBER_MAXIMUM+1,2));
for card_num in range(CARD_MINIMUM,CARD_MAXIMUM+1):
for shown_num in range(SHOWN_NUMBER_MINIMUM,SHOWN_NUMBER_MAXIMUM+1):
for ace in range(0,2):
POLICY_MIDDLE[card_num,shown_num,ace] = ACTION[ np.argmax( POLICY_UPDATION[i][card_num,shown_num,ace,:] ) ]
visual_func_s_a_1_2(POLICY_MIDDLE,-1,1,'policy loop number: '+str(i));
visual_func_s_a_1_2(POLICY_RESULT,-1,1,'optimal policy');
plt.show();
'''
# visualization
# for state-action function
# oridnary sample
visual_func_s_a_1_4(Q_s_a_ordinary,-1,1,'state-action function in ordinary sample')
# weighed sample
visual_func_s_a_1_4(Q_s_a_weigh,-1,1,'state-action function in weighed sample')
# for value function
# ordinary sample
visual_func_s_a_1_2(V_s_ordinary,-1,1,'value function in ordinary sample')
# weighed sample
visual_func_s_a_1_2(V_s_weigh,-1,1,'value function in weighed sample')
# optimal policy show
visual_func_s_a_1_2(POLICY_RESULT,-1,1,'optimal policy by q_a_s')
# updation number
visual_func_s_a_1_4(Q_n_ordinary,0,300,'number')
plt.show();
'''
Result
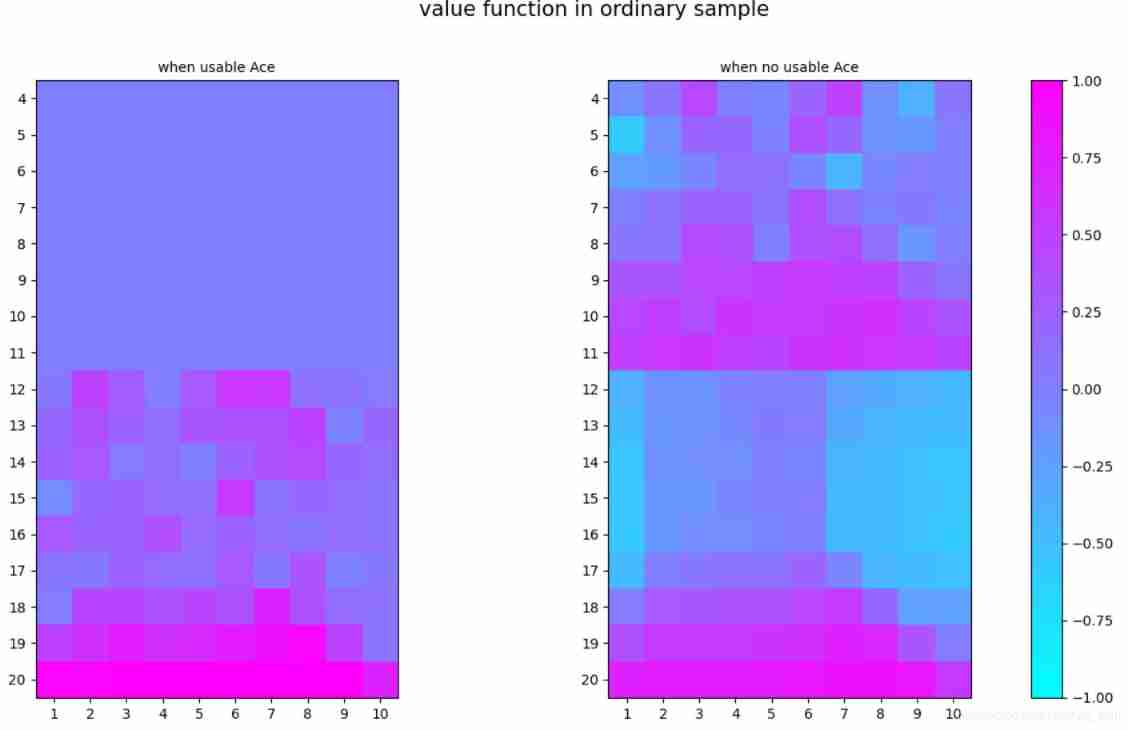
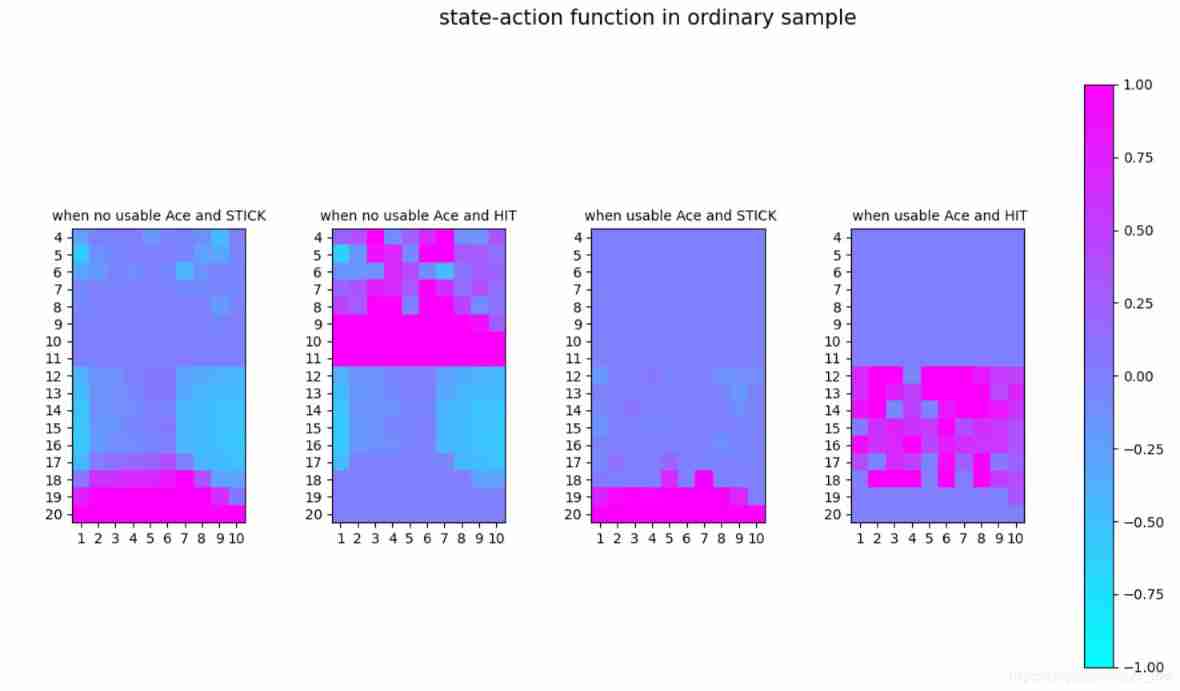
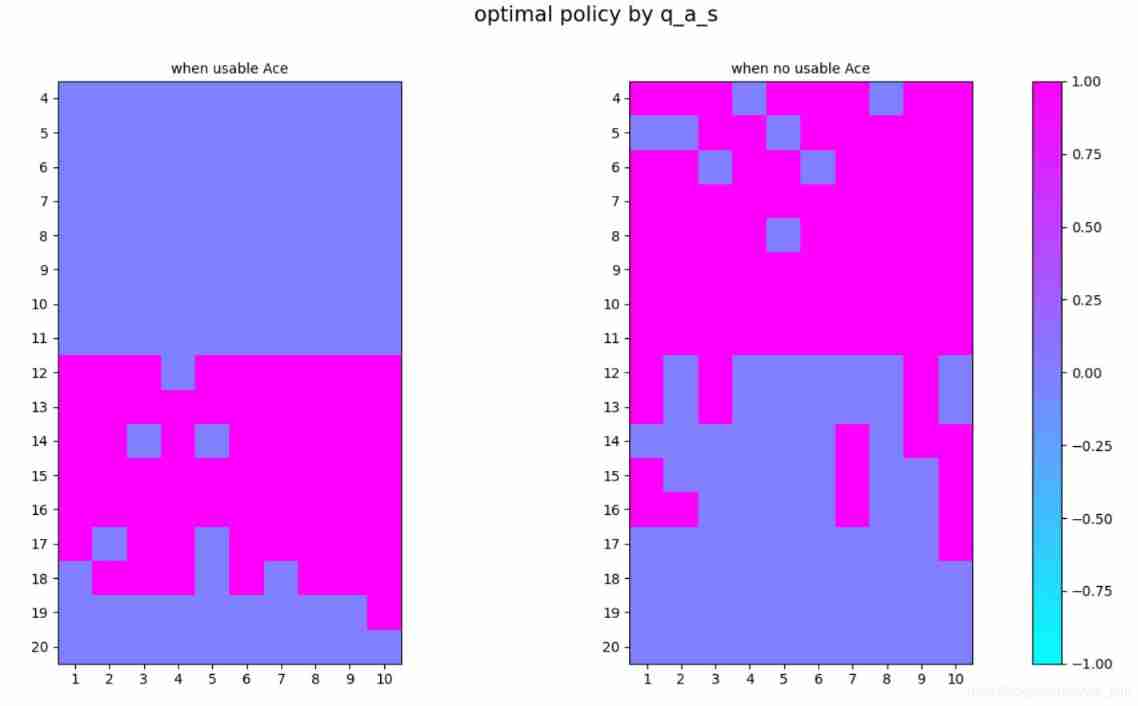
After many loops( 10^6 ), the result still does not converge. After we check the updation number in every state&action pairs in below picture. We could see in many places, there are still very few visits. So how to guarantee the exploration will be the key of improving quality of off-policy.
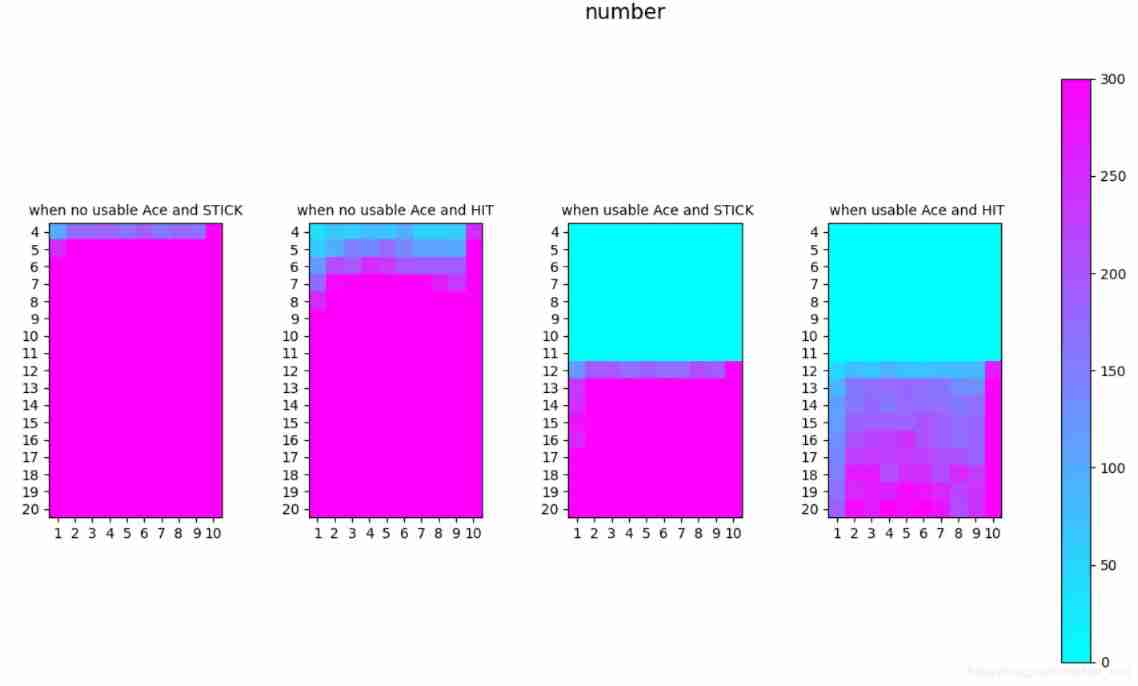
This is the show of course of policy improvement.

Reference resources :
边栏推荐
- 3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
- CV learning notes - scale invariant feature transformation (SIFT)
- Retinaface: single stage dense face localization in the wild
- After clicking the Save button, you can only click it once
- Yocto technology sharing phase IV: customize and add software package support
- Working mode of 80C51 Serial Port
- Opencv interview guide
- CV learning notes - feature extraction
- It is difficult to quantify the extent to which a single-chip computer can find a job
- Application of external interrupts
猜你喜欢

2312、卖木头块 | 面试官与狂徒张三的那些事(leetcode,附思维导图 + 全部解法)
CV learning notes convolutional neural network

Serial communication based on 51 single chip microcomputer
CV learning notes - image filter
Opencv notes 17 template matching

LeetCode - 715. Range 模块(TreeSet) *****
LeetCode - 1670 设计前中后队列(设计 - 两个双端队列)

Connect Alibaba cloud servers in the form of key pairs
CV learning notes - camera model (Euclidean transformation and affine transformation)
Opencv feature extraction sift
随机推荐
CV learning notes - clustering
Opencv notes 17 template matching
Opencv gray histogram, histogram specification
Leetcode-513:找树的左下角值
Dynamic layout management
[combinatorics] Introduction to Combinatorics (combinatorial idea 3: upper and lower bound approximation | upper and lower bound approximation example Remsey number)
LeetCode - 460 LFU 缓存(设计 - 哈希表+双向链表 哈希表+平衡二叉树(TreeSet))*
JS foundation - prototype prototype chain and macro task / micro task / event mechanism
Opencv histogram equalization
3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
My notes on intelligent charging pile development (II): overview of system hardware circuit design
Serial port programming
Leetcode 300 longest ascending subsequence
Deep learning by Pytorch
LeetCode - 703 数据流中的第 K 大元素(设计 - 优先队列)
Not many people can finally bring their interests to college graduation
Liquid crystal display
LeetCode - 1670 设计前中后队列(设计 - 两个双端队列)
Installation and removal of MySQL under Windows
CV learning notes - scale invariant feature transformation (SIFT)