当前位置:网站首页>Machine Learning - Logistic Regression
Machine Learning - Logistic Regression
2022-08-05 11:05:00 【Ding Jiaxiong】
8. 逻辑回归
A classification model in machine learning,逻辑回归是一种分类算法
解决二分类问题的利器
8.1 应用场景
广告点击率
是否为垃圾邮件
是否患病
金融诈骗
虚假账号
8.2 原理
逻辑回归中,其输入值是什么
如何判断逻辑回归的输出
8.2.1 输入
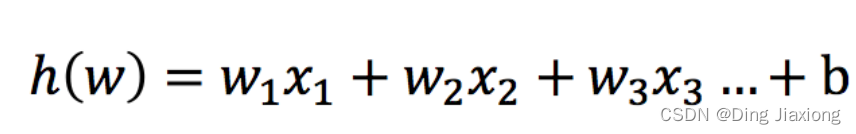
8.2.2 激活函数
sigmod函数
判断标准
- 回归的结果输入到sigmoid函数当中
- 输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值
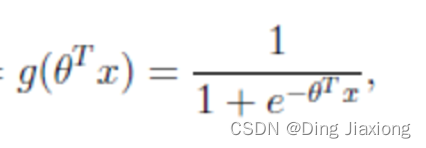
8.2.3 Logistic regression final classification
Determine whether it belongs to a certain category by the probability value of belonging to a certain category,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)
8.3 损失以及优化
8.3.1 损失
逻辑回归的损失,称之为对数似然损失
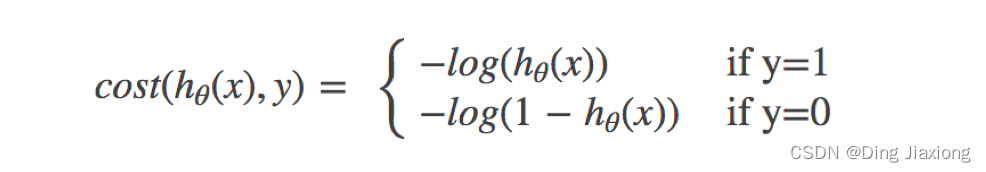
8.3.2 优化
- 使用梯度下降优化算法,去减少损失函数的值
- 更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率
8.4 API
8.4.1 sklearn.linear_model.LogisticRegression(solver=‘liblinear’, penalty=‘l2’, C = 1.0)
solver可选参数:{‘liblinear’, ‘sag’, ‘saga’,‘newton-cg’, ‘lbfgs’}
- 默认: ‘liblinear’;用于优化问题的算法
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和’saga’对于大型数据集会更快
- 对于多类问题,只有’newton-cg’, ‘sag’, 'saga’和’lbfgs’可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类
penalty:正则化的种类
C:正则化力度
8.4.2 LogisticRegression方法相当于 SGDClassifier(loss=“log”, penalty=" ")
SGDClassifier实现了一个普通的随机梯度下降学习.而使用LogisticRegression实现了SAG小批量梯度下降
8.5 案例
癌症分类预测-良/恶性乳腺癌肿瘤预测
8.6 分类评估方法
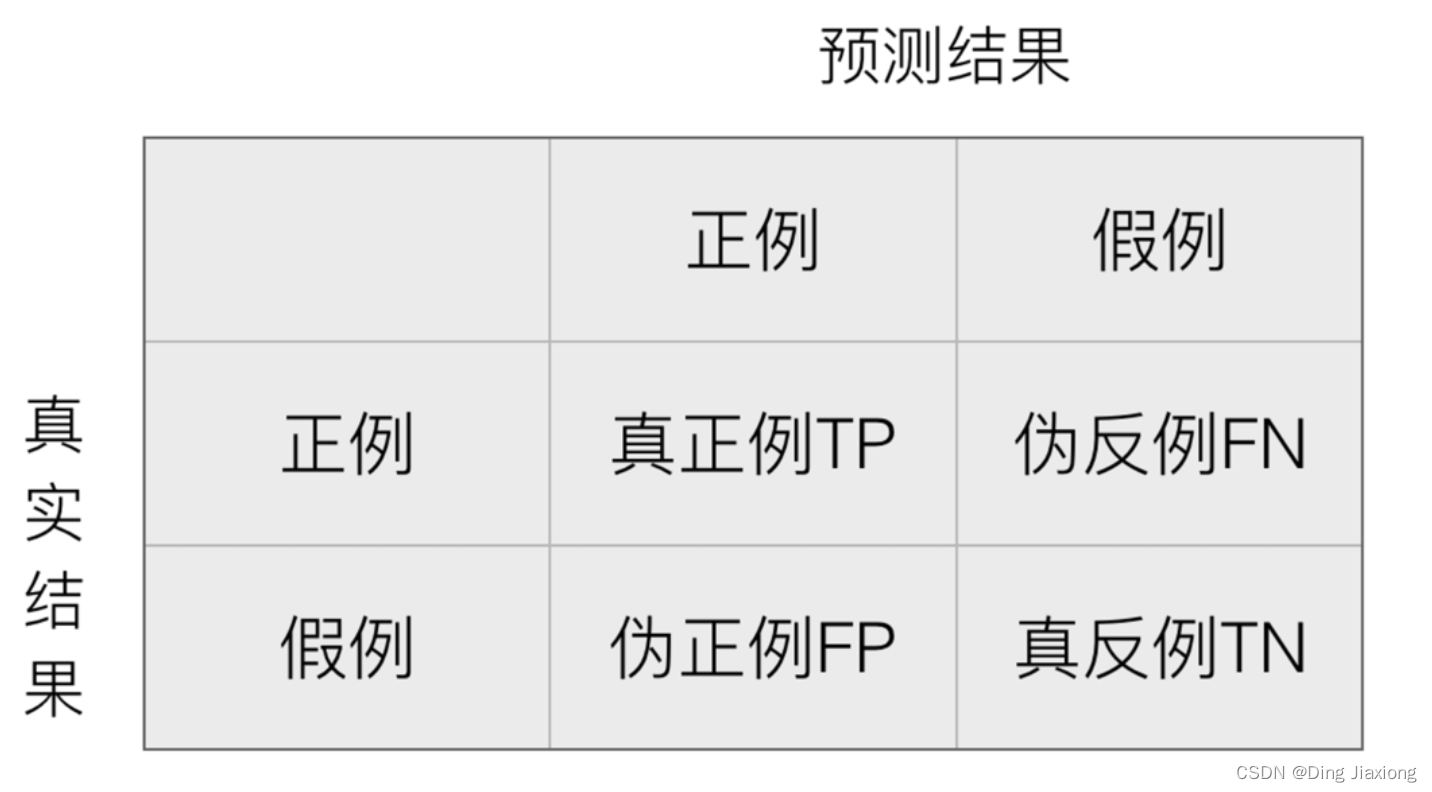
8.6.1 混淆矩阵
- 在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
8.6.2 精确率(Precision)与召回率(Recall)
精确率
- 预测结果为正例样本中真实为正例的比例
召回率
- 真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力)
8.6.3 F1-score
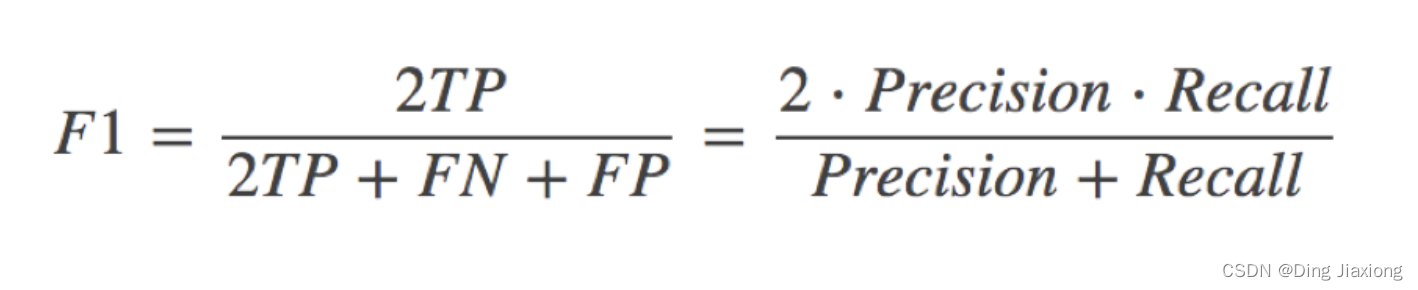
反映了模型的稳健型
8.6.4 分类评估报告api
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
- target_names:目标类别名称
- return:每个类别精确率与召回率
8.6.5 ROC曲线与AUC指标
TPR与FPR
TPR = TP / (TP + FN)
- 所有真实类别为1的样本中,预测类别为1的比例
FPR = FP / (FP + TN)
- 所有真实类别为0的样本中,预测类别为1的比例
ROC曲线
- ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5
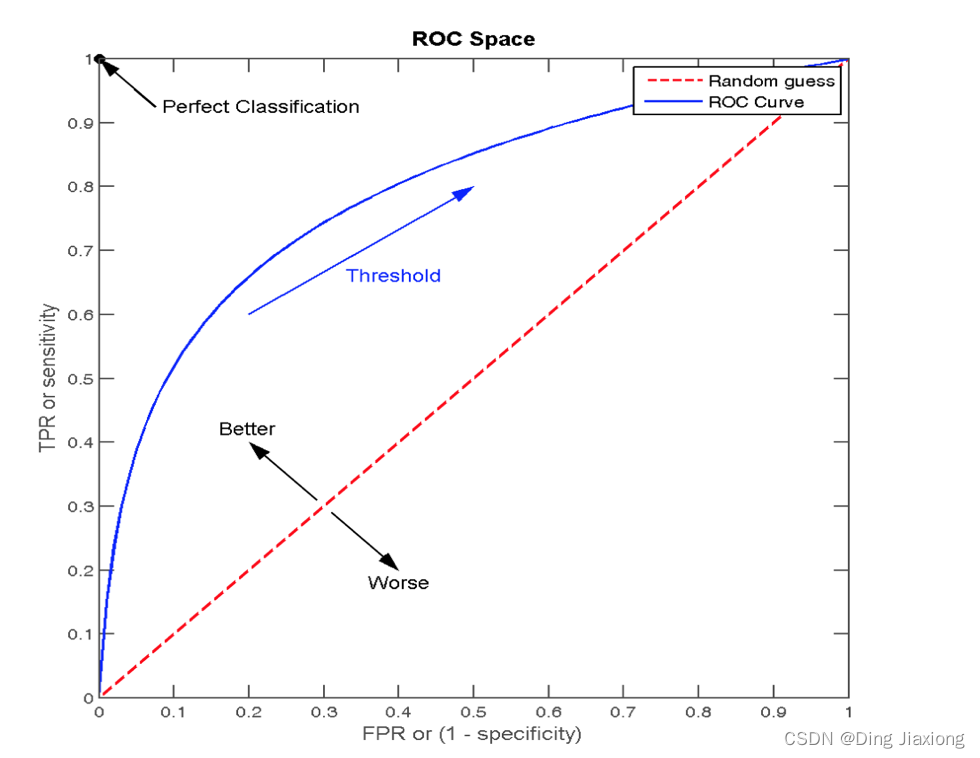
AUC指标
AUC的概率意义是随机取一对正负样本,正样本得分大于负样本的概率
AUC的最小值为0.5,最大值为1,取值越高越好
AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测.绝大多数预测的场合,不存在完美分类器
0.5<AUC<1,优于随机猜测.这个分类器(模型)妥善设定阈值的话,能有预测价值
- 最终AUC的范围在[0.5,1]之间,越接近1越好
AUC计算API
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
- 计算ROC曲线面积,即AUC值
- y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
- y_score:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值
总结
- AUC只能用来评价二分类
- AUC非常适合评价样本不平衡中的分类器性能
8.7 ROC曲线的绘制
总的ROC曲线绘制出来了,AUC就定了,分对的概率也能求出来了
8.7.1 绘制ROC曲线的意义
很明显,不断地把可能分错的情况扣除掉,从概率最高往下取的点,每有一个是负样本,就会导致分错排在它下面的所有正样本,所以要把它下面的正样本数扣除掉
8.7.2 AUC——Area Under roc Curve
ROC曲线的积分,也是ROC曲线下面的面积
边栏推荐
- 365 days challenge LeetCode1000 questions - Day 050 add a row to the binary tree binary tree
- Integration testing of software testing
- GCC编译的时候头文件搜索规则
- Http-Sumggling缓存漏洞分析
- Guys, I am a novice. I use flinksql to write a simple count of user visits according to the document, but it ends after executing it once.
- hdu4545 魔法串
- Go学习笔记(篇二)初识Go
- 金融业“限薪令”出台/ 软银出售过半阿里持仓/ DeepMind新实验室成立... 今日更多新鲜事在此...
- Go compilation principle series 6 (type checking)
- UDP communication
猜你喜欢

Http-Sumggling Cache Vulnerability Analysis
Http-Sumggling缓存漏洞分析

手把手教你定位线上MySQL慢查询问题,包教包会

Android development with Kotlin programming language II Conditional control

《分布式云最佳实践》分论坛,8 月 11 日深圳见

Machine Learning - Ensemble Learning
微服务结合领域驱动设计落地

MySQL 中 auto_increment 自动插入主键值

金融业“限薪令”出台/ 软银出售过半阿里持仓/ DeepMind新实验室成立... 今日更多新鲜事在此...

Naive bayes
随机推荐
hdu4545 魔法串
Leetcode刷题——623. 在二叉树中增加一行
60行从零开始自己动手写FutureTask是什么体验?
大佬们 我是新手,我根据文档用flinksql 写个简单的用户访问量的count 但是执行一次就结束
TiDB 6.0 Placement Rules In SQL Usage Practice
Common operations of oracle under linux and daily accumulation of knowledge points (functions, timed tasks)
shell编程流程控制练习
Image segmentation model - a combination of segmentation_models_pytorch and albumations to achieve multi-category segmentation
How OpenHarmony Query Device Type
Linux:记一次CentOS7安装MySQL8(博客合集)
GPU-CUDA-图形渲染分析
一张图看懂 SQL 的各种 join 用法!
Linux: Remember to install MySQL8 on CentOS7 (blog collection)
STM32入门开发:编写XPT2046电阻触摸屏驱动(模拟SPI)
TiDB 6.0 Placement Rules In SQL 使用实践
【加密解密】明文加密解密-已实现【已应用】
Support Vector Machine SVM
Android 开发用 Kotlin 编程语言 二 条件控制
支持向量机SVM
Microcontroller: temperature control DS18B20