当前位置:网站首页>整形和浮点型是如何在内存中的存储
整形和浮点型是如何在内存中的存储
2022-07-03 15:16:00 【小蜗牛向冲】
目录
前言
大家好吖!这期和大家分享整形和浮点型是如何在数据是如何在内存中存储。
1 数据类型
前面我们已经知道了基本的内置类型:

类型的意义:
1. 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
2. 如何看待内存空间的视角。
1.1 类型的基本归类:
整形家族:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
char 的类型取决于编译器,在VS编译器中的char是signed char.
浮点数家族:
float
double
其中的float类型精度低,存储范围小。
而double类型精度高,存储范围大。
构造类型:
> 数组类型
> 结构体类型 struct
> 枚举类型 enum
> 联合类型 union
指针类型
int *pi;
char *pc;
float* pf;
void* pv;
空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
今天我要重点和大家分享的是整形家族和浮点数家族是如何在内存中存储的。
2 整形在内存中的存储
2.1二进制的三种形式
原码:直接用二进制表示。
反码:原码符号位不变,其他位按位取反。
补码:反码+1。
注意:
1 其中正数的原码、反码和补码相同。负数的二进制变换规则如上。
2 补码变为原码有二种办法:
方法1
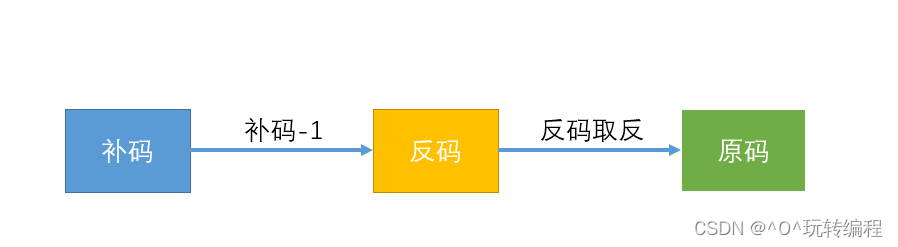
方法2
那么整形到底是以哪种形式的二进制存储在内存中的呢?
实际是整形是以补码的形式存储在内存中的。
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。
这什么是的啥啊?
其实刚刚学到这里,我也有点懵逼,为什么要用补码存呢?下面我给大家举例
1-1这的运算结果是怎么进行的呢
1的原码(在32位平台上):00000000000000000000000000000001
-1的原码(在32位平台上):10000000000000000000000000000001
-1的反码(在32位平台上):111111111111111111111111111111111110
-1的补码(在32位平台上):111111111111111111111111111111111111
因为CPU只有加法器,所以1-1---->1+(-1)
显然无论是1的原码还是反码和-1的原码或者补码相加都得不到结果。
而补码确可以100000000000000000000000000000000(这里33),而我们是32位平台,所以最终结果为00000000000000000000000000000000(0,看到这里是不是觉的补码很神奇。所以:整数在内存中存的是补码。
虽然我们明白内存中存的是补码,但我们还是不知道补码在内存中是怎么存的,下面我们就要说到大小端字。
2.2 大小端字的介绍
下面我们以整数1来理解
大端字节序存储
就是把一个数据的高位字节序的内容放在低地址处,低位字节序的内容反在高地址处。
我们用16进制表示分布

小端字节序存储
就是把一个数据的高位字节序的内容放在高地址处,低位字节序的内容反在低地址处。
下面是在vs中的存储分布
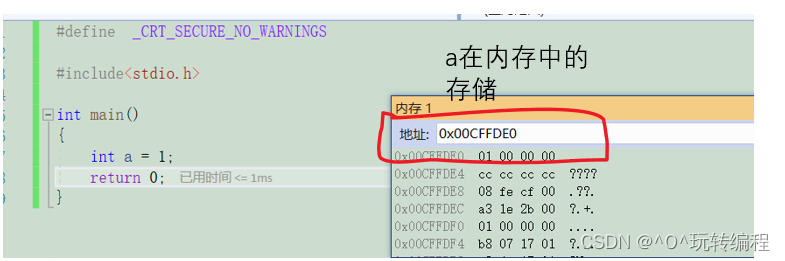
大小端字节序的存储是和硬件有关,有硬件是小端存储,的有是大端存储。
3 浮点数在内存中的存储
很多人多会想,整形是以补码的形式存储在内存中,存储方式于大小端有关,那么浮点型又是怎么存储的呢?
 从上面我们可能看出肯定不是和整形的存储方式有关。
从上面我们可能看出肯定不是和整形的存储方式有关。
3.1 浮点数存储规则
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
那么1.0就可以写成。(-1)^0* 1.0*2^0(2^n次方是二进制的科学计算法的形式)
其中二点S = 0,M = 1.0,E = 0
那么9.5我们就可以写成
(-1)^0*1.0011*2^3
而9.6呢?
我们发现我们始终都无法表示出0.6,只能不断的接近这个数,所以浮点型在内存中的存储是一个精确值而不是一个准确值。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。
对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。 IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的 xxxxxx部分。比如保存1.01的时 候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位 浮点数为例,留给M只有23位, 将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们 知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数 是127;对于11位的E,这个中间 数是1023。比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即 10001001。
指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将 有效数字M前加上第一位的1。 比如: 0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为 1.0*2^(-1),其阶码为-1+127=126,表示为 01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为:0 01111110 00000000000000000000000
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值, 有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于 0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
好了,浮点型的规则就介绍怎么多。
结束语
简单总结一下,整形的存储是通过补码的形式存入(通过大小端的形式),浮点型存储主要存的是一个符号位E的二进制位级M的精确位数。大家有所获的话,三连支持一下吧!

边栏推荐
- [cloud native training camp] module 7 kubernetes control plane component: scheduler and controller
- 5.4-5.5
- Puppet automatic operation and maintenance troubleshooting cases
- Finally, someone explained the financial risk management clearly
- Composite type (custom type)
- 【Transform】【NLP】首次提出Transformer,Google Brain团队2017年论文《Attention is all you need》
- 视觉上位系统设计开发(halcon-winform)
- Global and Chinese market of marketing automation 2022-2028: Research Report on technology, participants, trends, market size and share
- [Yu Yue education] scientific computing and MATLAB language reference materials of Central South University
- Global and Chinese markets for indoor HDTV antennas 2022-2028: Research Report on technology, participants, trends, market size and share
猜你喜欢
![[transform] [NLP] first proposed transformer. The 2017 paper](/img/33/f639ab527d5adedfdc39f8d8117c3e.png)
[transform] [NLP] first proposed transformer. The 2017 paper "attention is all you need" by Google brain team

Composite type (custom type)
![[transform] [practice] use pytoch's torch nn. Multiheadattention to realize self attention](/img/94/a9c7010fe9f14454469609ac4dd871.png)
[transform] [practice] use pytoch's torch nn. Multiheadattention to realize self attention

Kubernetes advanced training camp pod Foundation

Troubleshooting method of CPU surge
![[cloud native training camp] module VIII kubernetes life cycle management and service discovery](/img/87/92638402820b32a15383f19f6f8b91.png)
[cloud native training camp] module VIII kubernetes life cycle management and service discovery
Introduction to redis master-slave, sentinel and cluster mode
redis缓存穿透,缓存击穿,缓存雪崩解决方案

Basic SQL tutorial

Série yolov5 (i) - - netron, un outil de visualisation de réseau
随机推荐
Mmdetection learning rate and batch_ Size relationship
Detailed comments on MapReduce instance code on the official website
Série yolov5 (i) - - netron, un outil de visualisation de réseau
The state does not change after the assignment of El switch
Yolov5系列(一)——網絡可視化工具netron
[probably the most complete in Chinese] pushgateway entry notes
Didi off the shelf! Data security is national security
5-1 blocking / non blocking, synchronous / asynchronous
Concurrency-01-create thread, sleep, yield, wait, join, interrupt, thread state, synchronized, park, reentrantlock
Byte practice plane longitude 2
【pytorch学习笔记】Datasets and Dataloaders
Dataframe returns the whole row according to the value
[Yu Yue education] scientific computing and MATLAB language reference materials of Central South University
Use of Tex editor
4-24--4-28
Zero copy underlying analysis
[attention mechanism] [first vit] Detr, end to end object detection with transformers the main components of the network are CNN and transformer
Web server code parsing - thread pool
Chapter 04_ Logical architecture
Yolov5 advanced 8 format conversion between high and low versions