当前位置:网站首页>On redis (II) -- cluster version
On redis (II) -- cluster version
2022-07-02 03:07:00 【walker_ sunxy】
Preface
I shared it briefly before Stand-alone version Redis. Include :
- Why Redis And why not Redis
- Redis Why so soon?
- Redis Data structure of
- Redis The reason for the high throughput of single thread
Stand-alone version Redis Fast response 、 The amount of concurrency supported is high , If there is persistent memory , It can even ensure that data is not lost . Then we can use the stand-alone version directly Redis As a database ?
Suppose we use a stand-alone version Redis As a storage medium .Redis It is generally divided into two uses , Cache and persist databases .
Let's first look at the most common situation , power failure / restart :
- Business database : Using persistent memory can ensure no data loss after restart . But in the process of power failure, the whole business will be paralyzed without data source .
- cache : If the cache is powered down , It will not directly paralyze the business , After all, there is complete data in the business database . If Redis Downtime , It will lead to cache avalanche —— All caches are invalidated , All requests are made directly to the database , This leads to a surge in database pressure , This leads to an increase in service response time .
In case of power failure , stand-alone Redis As a business database, it certainly does not meet the conditions ; As caching , If the amount of data is small 、 If the request is small , It doesn't affect business use very much ( There is no need for caching in this scenario ).
If restart is not considered , stand-alone Redis Is there no problem ?
Data volume 、 When the number of visits is small , It seems that there really won't be any problem , We still consider the amount of data 、 High traffic .
For example, now there is a single machine redis, Need to store hundreds of millions key. When Redis Persistence , If the amount of data increases , The amount of memory needed will also increase , The main thread fork Child processes may block . Even in memory 、CPU With sufficient resources , A data backup takes a long time , Lead to Redis The service for is not available .
however , If you don't ask for persistence Redis data , that , increase cpu Hardware performance and memory capacity will be a good choice . But there is a second problem , It's the hardware cost : A piece of 128G The price of the memory module is much higher than four pieces 32G The sum of the price of the memory module ,cpu It's the same thing . The cost of hardware will increase exponentially with the continuous improvement of performance
in summary , Stand-alone version Redis There are two main problems :
- Usability ( After power failure , Business is not available )
- Bloated data ( stand-alone CPU Operations on large amounts of data )
- Backup blocking causes service unavailability
- Cost index growth
Then what shall I do? ? The single machine is not enough , Just add a few more machines ! So let's see Redis Provides several common resource usage strategies in a multi machine environment , See if you can solve the above two problems
One 、 Master slave synchronization (Master-Slave)
Master slave synchronization is , Multiple Redis node , A master node (master), Multiple secondary nodes (slave). The read request will be sent to each node , Writing a request will only send master, then slave The timing will start from master Pull new write operations to ensure data consistency .

How to add one from the stand-alone version slave Node transition to master-slave mode ? for example , Now there are examples 1(ip:192.168.19.3) And examples 2(ip:192.168.19.5), We are in the instance of 2 After executing the following command , example 2 It becomes an example 1 Slave Library , And from the example 1 Copy data on :
replicaof 192.168.19.3 6379
For the first time master Of RDB Full file synchronization , stay RDB The operations after the file contents are incremental synchronization .

Then repeat 1 and 3 The process of .
Two 、 Sentinel mechanism (Sentinel)
The master-slave synchronization mentioned above only ensures Redis Data is backed up in time . It can share some of the access pressure of the main database , And ensure the availability of the slave Library . But if the main library fails , That will directly affect the synchronization of slave Libraries , Because there is no corresponding master database for data replication from the slave database .
sentry (Sentinel) It is to solve this problem that . It realizes the key mechanism of automatic switching between master and slave libraries , It effectively solves three problems of failover in master-slave replication mode .
- Does the main library really hang up ?
- Which slave database should be selected as the master database ?
- How to inform the slave database and client about the new master database ?
Now let's look at these three questions Sentinel The corresponding three functions , monitor 、 Select the master and notify .
2.1 monitor
Sentinels need to determine if the main library is offline . Here are two concepts , namely Subjective offline and Objective offline ,
The sentinel process will use PING The command detects itself and the master 、 Network connection of slave library , Used to determine the state of an instance . If the sentry finds that the main database response timed out , that , The sentinel will mark it as “ Subjective offline ”. If it's a slave Library , that , The sentry simply marked it as Subjective offline That's it , Because the offline effect of the slave library is not too big , The external service of the cluster will not be interrupted .
If it's a master library , that , The Sentry can't simply mark it as “ Subjective offline ”. Because it's possible that there is such a situation : That's the sentinel misjudged , In fact, there is no fault in the main database . But , Once the master-slave switch is started , Subsequent selection and notification operations will bring additional computational and communication overhead .
So how to reduce misjudgment ? In everyday life , When we have to judge something important , I often discuss it with my family or friends , Then make a decision . The sentry mechanism is similar , It is usually deployed in a cluster mode composed of multiple instances , This is also known as the sentry cluster . Introduce several sentinel examples to judge together , You can avoid a single sentry because your network is not good , And misjudge that the main database is offline . meanwhile , The probability of multiple sentinel networks being unstable at the same time is small , They make decisions together , The miscalculation rate can also be reduced . When judging whether the main database is offline , It can't has the final say of a sentinel , Only most sentinel instances , It is judged that the master database has “ Subjective offline ” 了 , The master library will be marked as “ Objective offline ”, This name also shows that the offline of the main database has become an objective fact . The principle of judgment is : The minority is subordinate to the majority .
“ Objective offline ” The standard is , When there is N A sentinel instance , It's better to have N/2 + 1 The main database is “ Subjective offline ”, In order to determine the main database as “ Objective offline ”.
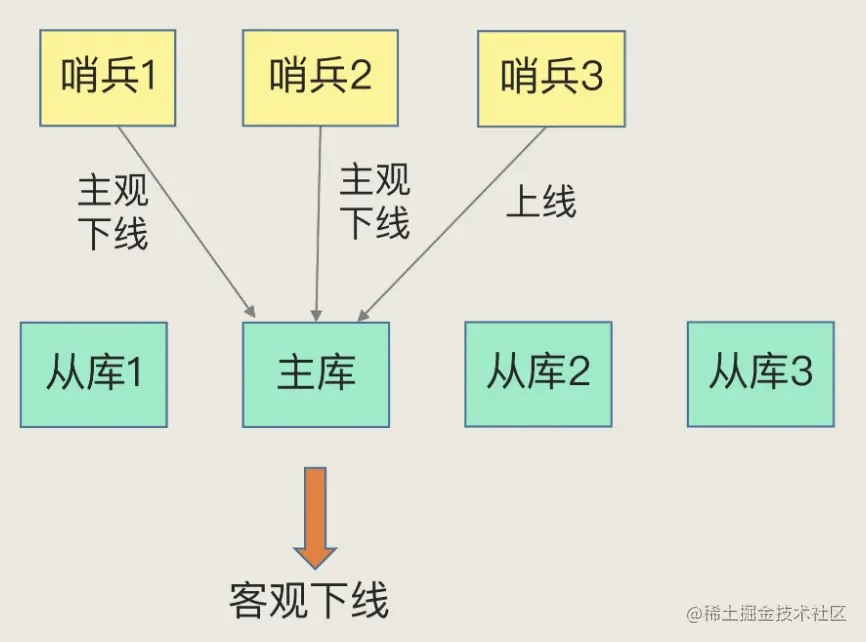
2.2 Elector
When the Sentinels judge that the main library is offline , The next decision-making process is about to begin , That is, from many repositories , Select a slave library to be the new master library .
Generally speaking , I call the Sentinel's process of selecting a new master library “ Screening + Scoring ”.
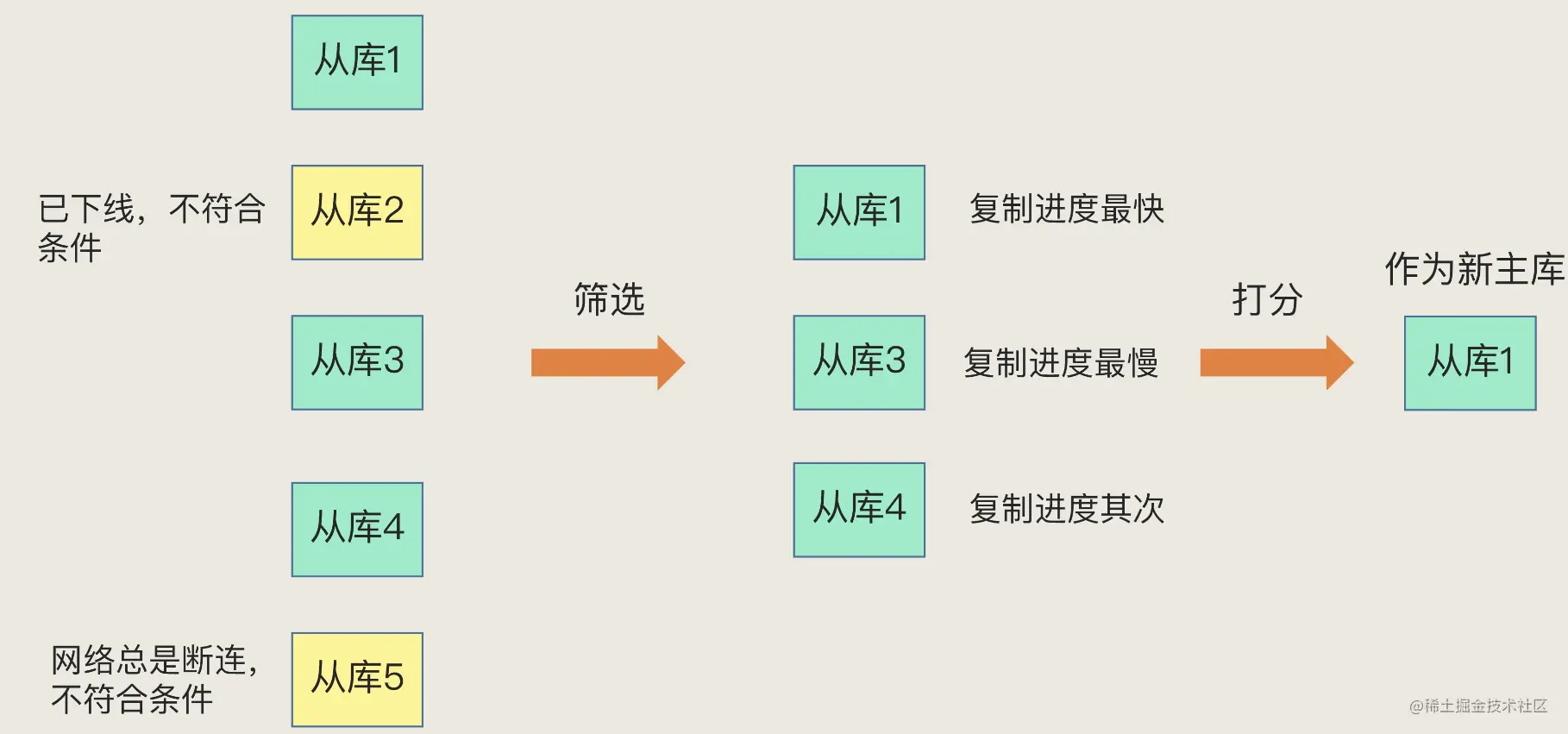
filter : Network connection status ( Now? + Before ). In the election , In addition to checking the current online status of the slave Library , We also need to judge the network connection status before it . If the slave database is always disconnected from the master database , And the number of disconnection times exceeds a certain threshold , We have reason to believe that , The network condition of this slave database is not very good , You can sift this out of the library .
Scoring :
- First , The one with the highest priority gets the highest score from the database . Users can manually set the priority of slave libraries .
- secondly , The slave database with the closest degree of synchronization with the old master database gets a high score .
- Last , There is a default rule : With the same priority and replication schedule ,ID The one with the smallest number gets the highest score from the library , Will be selected as the new master library .
Sentinels are also in cluster mode , Also ensure the availability of services , Therefore, there will be corresponding guarantee mechanism . This is not in this chapter Redis Within the scope of cluster discussion , So don't expand the description .
3、 ... and 、 Redis Cluster
See here , Remember what we found at the beginning Redis Two problems of stand-alone version ? Usability and Bloated data .
The above master-slave mode + Sentinel mode is enough to ensure Redis Availability of services , But it doesn't seem to solve the problem of data bloating , Redis Cluster It provides us with a solution to this problem .
3.1 Data slicing
Cluster slicing , Also called fragment cluster , It means starting multiple Redis Instances form a cluster , And then according to certain rules , Divide the received data into multiple copies , Each copy is saved with an instance .
In this way, a single copy of data can be reduced to the extent that the backup does not affect the main process of the instance , And it can also solve the problem of hardware cost .
The data are scattered , Users need to check a piece of data ,Redis How to know which instance this data is in ?
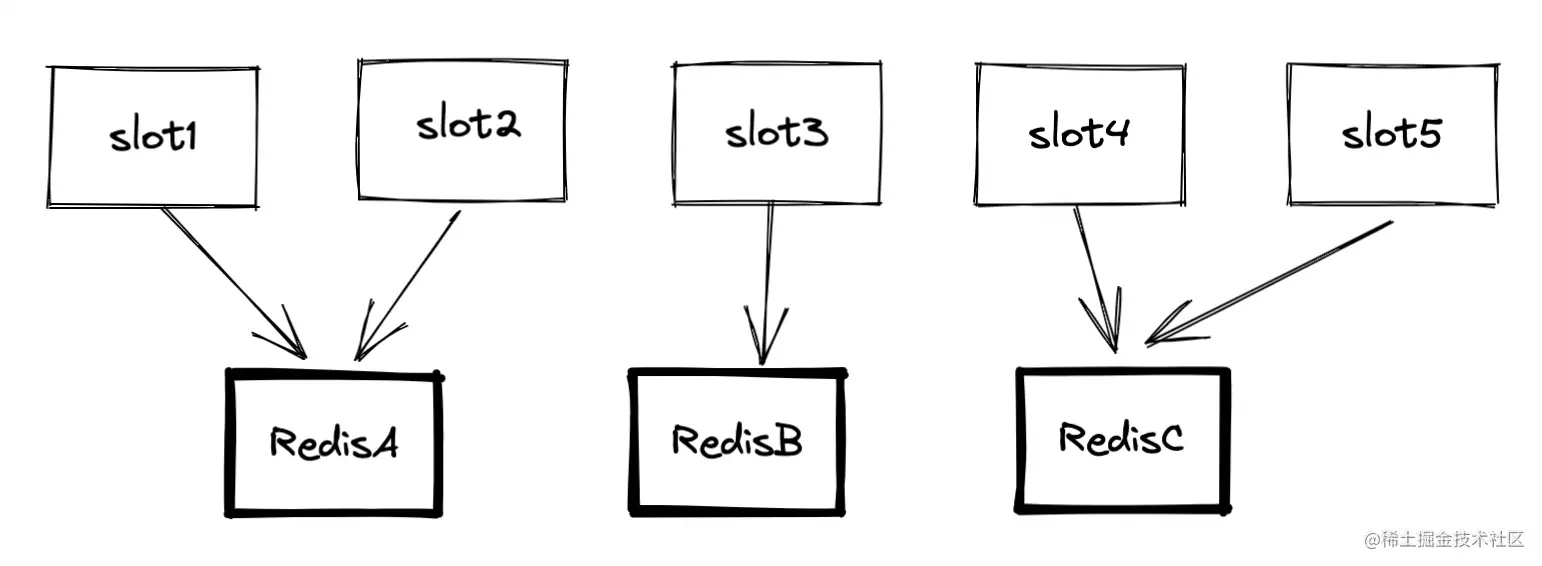
We need to figure out the slice clusters and Redis Cluster The connection and difference between . Slice clustering is a general mechanism for storing large amounts of data , This mechanism can have different implementation schemes . Redis Cluster The scheme adopts hash Slot (Hash Slot, I'm going to call it Slot), To handle the mapping between data and instances . stay Redis Cluster In the plan , A slice cluster has 16384 individual hash Slot , these hash Slots are similar to data partitions , Each key value pair will be based on its key, Mapped to a hash In groove . The specific mapping process is divided into two steps :
- First of all, according to the key value pair key, according to CRC16 The algorithm computes a 16 bit Value ;
- then , To use this 16bit It's worth it 16384 modulus , obtain 0~16383 Modulus in range , Each module represents a corresponding number hash Slot .
About CRC16 Algorithm , It's not the point of our discussion . We just need each one key Can calculate one 0~16383 Just count .
every last 0~16383 The number of is called a slot( Slot ). One Redis The instance has multiple slots , All in the cluster Redis The slots of the instance must add up to 16384. let me put it another way , In manual allocation hash When you slot , Need to put 16384 All the slots are allocated , otherwise Redis The cluster is not working properly .
3.2 How the client locates the data ?
When locating key value pair data , Where it is hash Slots can be calculated , This calculation can be performed when the client sends a request . however , To further navigate to the instance , Also need to know hash On which instance are the slots distributed .
Redis The instance will put its own hash Slot information is sent to other instances connected to it , To complete hash Diffusion of slot allocation information ,Redis The cluster using P2P Of Gossip( Gossip ) agreement , Gossip The working principle of the protocol is that nodes communicate and exchange information with each other , After a period of time, all nodes will know the complete information of the cluster , This way is similar to spreading rumors When instances are interconnected , Every instance has all hash The mapping relationship of slots . Equivalent to every instance has a slot Mapping table with instance address .
When the client sends an operation request for a key value pair to an instance , If the key value pair is not mapped on this instance hash Slot , that , This instance will return the following to the client MOVED Command response results , This result includes the access address of the new instance .
GET hello:key
(error) MOVED 13320 192.168.19.5:6379
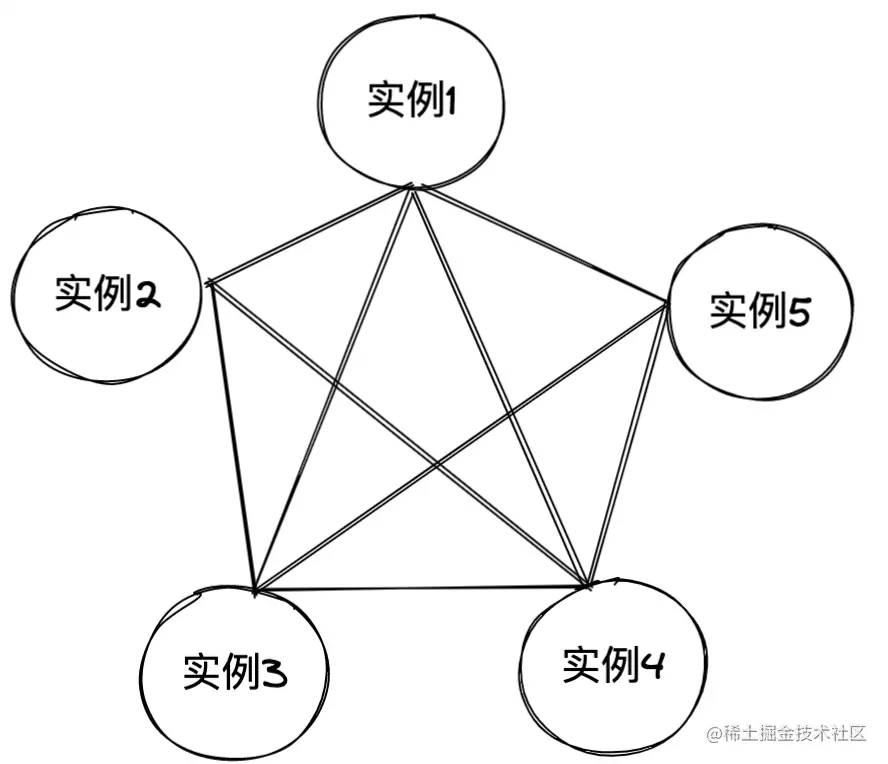
Pictured above , The user connects to any Redis example , You can query all in the cluster key. For example, connect the instance 2, Inquire about key = “hello”. example 2 Will be based on key Calculation hash The value of the slot .
- If the slot is in the instance 2 On , Then the direct query result returns ;
- If not in the instance 2 On , Then return to exist key The instance address of .
The client will also cache the requested key The address of the corresponding instance .
If the instance slot changes , For example, several instances have been added or deleted manually , The remaining instances can still automatically synchronize new hash The instance location corresponding to the slot .
3.3 The practical application
Redis Cluster Pattern solves the problem of data bloating , But alone Redis Cluster Patterns are not available , If any instance is powered off or disconnected , All of this instance hash The data of the slot will be in an unavailable state .
So in the actual use scenario , The above three cluster modes will be combined .
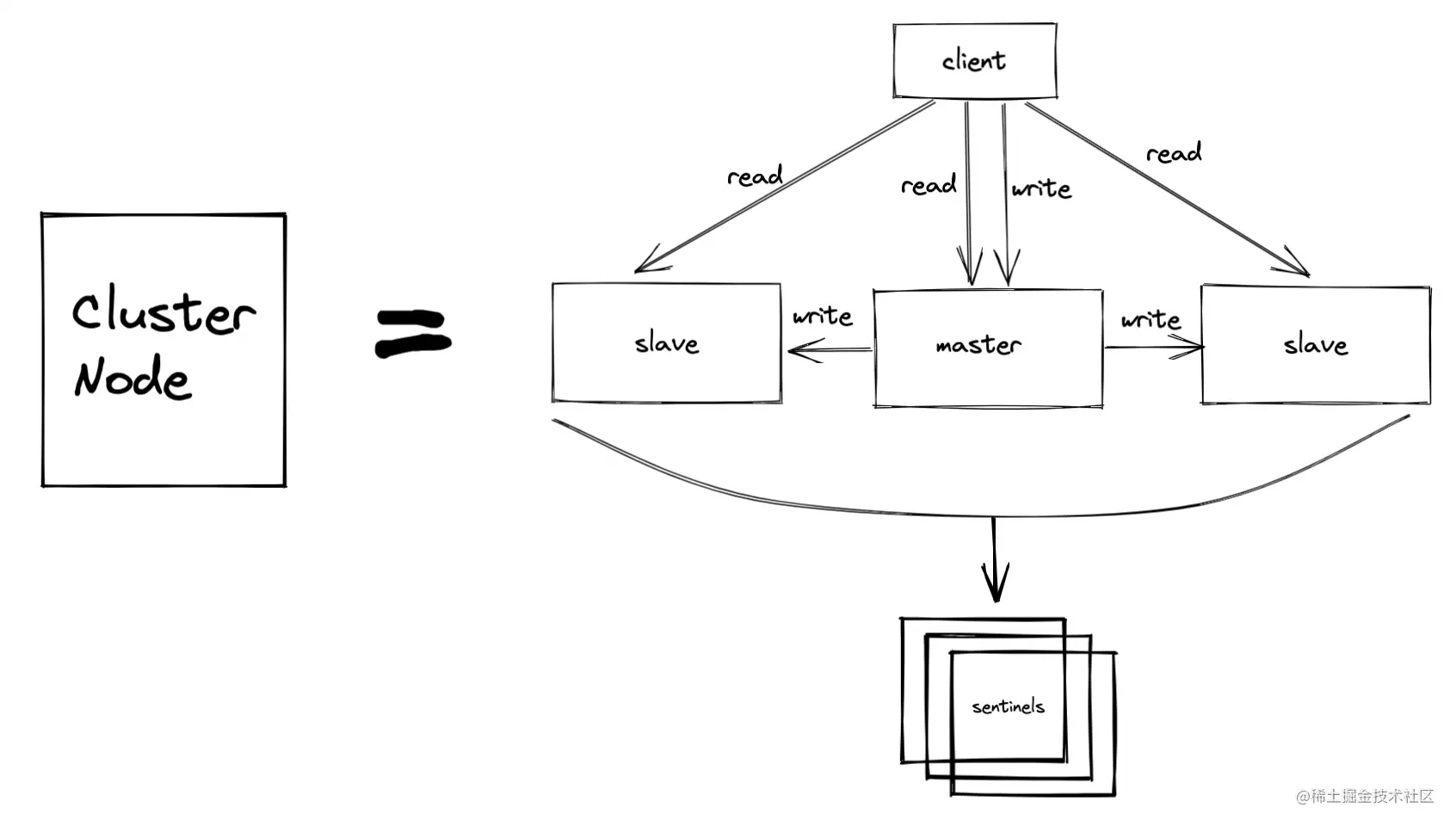
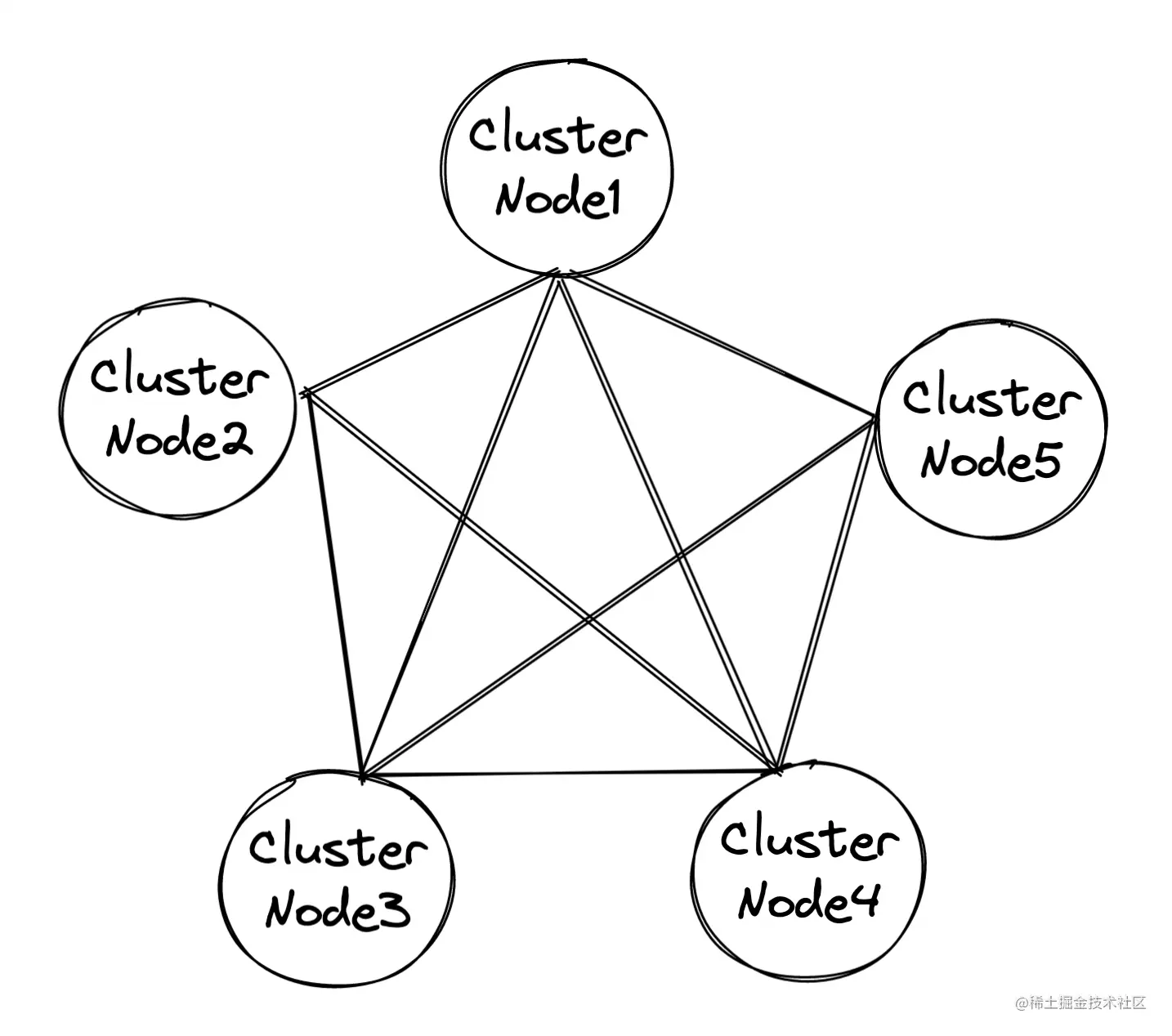
So far, we have solved the two problems raised at the beginning .
- Guaranteed availability : cluster node Master slave synchronization and sentinel election mechanism in
- Avoid bloated data :cluster node Data slice of cluster
Four 、 Summary
At the beginning, we propose a stand-alone version Redis As two drawbacks of database . Then it introduces Redis How do the official cluster solutions solve these two drawbacks .
Except Redis The official cluster scheme , There are also many excellent open source Redis Cluster approach . such as :
Twitter twemproxy
Produced by pea pods in China Codis
These two open source solutions and Redis The biggest difference between the official cluster scheme is Management mode of data nodes .
- Redis It's decentralization ,hash The mapping of slots and nodes will be saved for each node , adopt Gossip Protocol propagation ;
- These two schemes are centralized . There is a separate agent node management hash Mapping of slots and nodes .
How should we choose decentralization and centralization ?
边栏推荐
- 使用开源项目【Banner】实现轮播图效果(带小圆点)
- Use the open source project [banner] to achieve the effect of rotating pictures (with dots)
- Golang configure export goprivate to pull private library code
- Systemserver service and servicemanager service analysis
- 流线线使用阻塞还是非阻塞
- Gradle notes
- Verilog 状态机
- MongoDB非關系型數據庫
- Mongodb base de données non relationnelle
- 【无标题】
猜你喜欢

Coordinatorlayout + tablayout + viewpager2 (there is another recyclerview nested inside), and the sliding conflict of recyclerview is solved
![寻找重复数[抽象二分/快慢指针/二进制枚举]](/img/9b/3c001c3b86ca3f8622daa7f7687cdb.png)
寻找重复数[抽象二分/快慢指针/二进制枚举]

2022-2028 global aluminum beverage can coating industry research and trend analysis report

ZABBIX API creates hosts in batches according to the host information in Excel files
verilog 并行块实现
![[JVM] detailed description of the process of creating objects](/img/6e/0803b6b63c48337985faae8d5cbe1a.png)
[JVM] detailed description of the process of creating objects

Missing numbers from 0 to n-1 (simple difficulty)

Jvm-01 (phased learning)

The capacity is upgraded again, and the new 256gb large capacity specification of Lexar rexa 2000x memory card is added
QT implementation interface jump
随机推荐
Is bone conduction earphone better than traditional earphones? The sound production principle of bone conduction earphones is popular science
实现一个自定义布局的扫码功能
JS introduction < 1 >
2022-2028 global wood vacuum coating machine industry research and trend analysis report
West digital decided to raise the price of flash memory products immediately after the factory was polluted by materials
[question 008: what is UV in unity?]
数据传输中的成帧
Software testing learning notes - network knowledge
[staff] pitch representation (bass clef | C1 36 note pitch representation | C2 48 note pitch representation | C3 60 note pitch representation)
Pychart creates new projects & loads faster & fonts larger & changes appearance
Use the open source project [banner] to achieve the effect of rotating pictures (with dots)
Principle of computer composition - interview questions for postgraduate entrance examination (review outline, key points and reference)
Multi threaded query, double efficiency
[Chongqing Guangdong education] Sichuan University concise university chemistry · material structure part introductory reference materials
3124. Word list
只需简单几步 - 开始玩耍微信小程序
浅谈线程池相关配置
Mathematical calculation in real mode addressing
Formatting logic of SAP ui5 currency amount display
Gradle 笔记