当前位置:网站首页>ucorelab4
ucorelab4
2022-07-06 09:25:00 【湖大金胜宇】
lab4
实验目的
- 了解内核线程创建/执行的管理过程
- 了解内核线程的切换和基本调度过程
实验内容
实验2/3完成了物理和虚拟内存管理,这给创建内核线程(内核线程是一种特殊的进程)打下了提供内存管理的基础。当一个程序加载到内存中运行时,首先通过ucore OS的内存管理子系统分配合适的空间,然后就需要考虑如何分时使用CPU来“并发”执行多个程序,让每个运行的程序(这里用线程或进程表示)“感到”它们各自拥有“自己”的CPU。
本次实验将首先接触的是内核线程的管理。内核线程是一种特殊的进程,内核线程与用户进程的区别有两个:
- 内核线程只运行在内核态
- 用户进程会在在用户态和内核态交替运行
- 所有内核线程共用ucore内核内存空间,不需为每个内核线程维护单独的内存空间
- 而用户进程需要维护各自的用户内存空间
相关原理介绍可看附录B:【原理】进程/线程的属性与特征解析。
练习0:填写已有实验
本实验依赖实验1/2/3。请把你做的实验1/2/3的代码填入本实验中代码中有“LAB1”,“LAB2”,“LAB3”的注释相应部分。
使用meld将实验1/2/3的代码中相应的部分填入实验四中的代码中:

其中,需要修改的部分为:
default_pmm.c
pmm.c
swap_fifo.c
vmm.c
trap.c
练习1:分配并初始化一个进程控制块(需要编码)
alloc_proc函数(位于kern/process/proc.c中)负责分配并返回一个新的struct proc_struct结构,用于存储新建立的内核线程的管理信息。ucore需要对这个结构进行最基本的初始化,你需要完成这个初始化过程。
【提示】在alloc_proc函数的实现中,需要初始化的proc_struct结构中的成员变量至少包括:state/pid/runs/kstack/need_resched/parent/mm/context/tf/cr3/flags/name。
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 请说明proc_struct中struct context context和struct trapframe *tf成员变量含义和在本实验中的作用是啥?(提示通过看代码和编程调试可以判断出来)
准备知识
进程的一些相关知识
进程包括了正在运行的一个程序的所有状态信息,包括代码、数据、寄存器等。
进程的一些特点:
动态性:可以动态地创建、结束进程
并发行:进程可以被独立调用并占用处理机运行
独立性:不同进程间工作不受影响
制约性:多个进程因访问共享数据、资源或进程间同步而产生制约
进程控制块(PCB)是管理控制进程运行所用信息的集合。PCB是进程存在的唯一标志,每个进程在操作系统中都有一个对应的PCB,操作系统用PCB来描述进程的基本信息以及运行变化情况。PCB通常包含进程标识符、处理机的信息、进程调度信息、进程控制信息。
进程切换(上下文切换):暂停当前的进程,从运行状态变为其他状态,调用另一个进程从就绪状态改为运行状态。在这一过程中,切换前需要保存进程上下文,以便于之后恢复该进程,且尽可能地快速切换(因此通常用汇编写进程切换过程的代码)。CPU给每个任务一定的服务时间,当时间片轮转的时候,需要把当前状态保存下来,同时加载下一个任务,这时候就进行上下文切换。
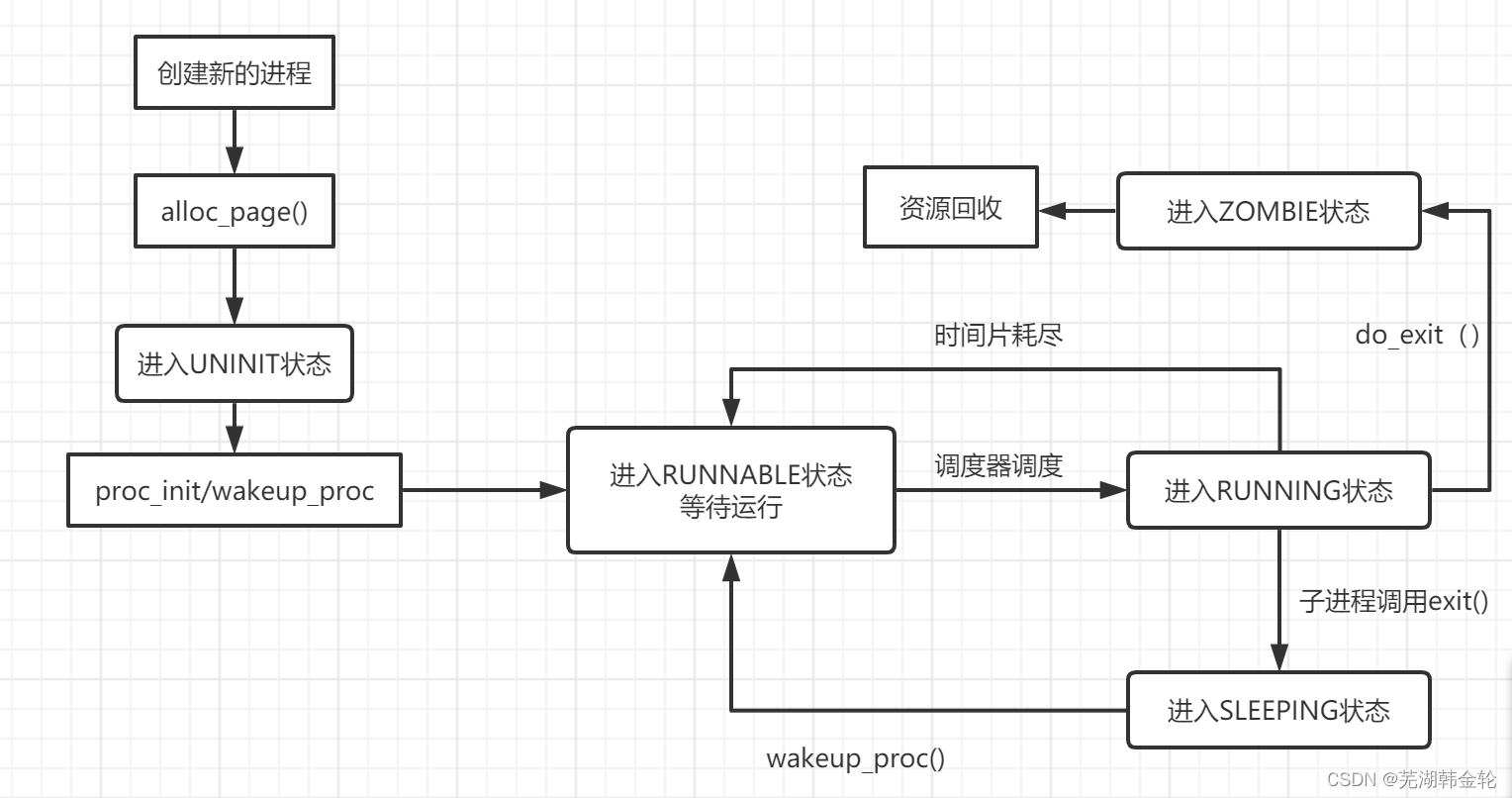
经典的进程五状态模型(new,ready,waitting,running,terminated):
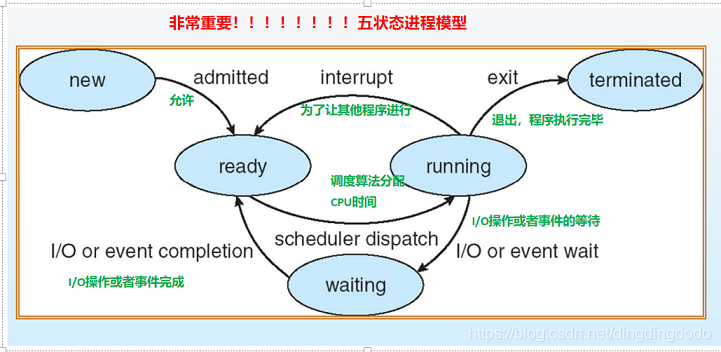
进程挂起:处于挂起状态的进程映像在磁盘上,目的是减少进程占用内存。与之相对的成为进程激活,将处于挂起状态的进程激活,将进程从外存转到内存。
实现
操作系统是以进程为中心设计的,所以其首要任务是为进程建立档案,进程档案用于表示、标识或描述进程,即进程控制块。这里需要完成的就是一个进程控制块的初始化。
而这里我们分配的是一个内核线程的 PCB,它通常只是内核中的一小段代码或者函数,没有用户空间。而由于在操作系统启动后,已经对整个核心内存空间进行了管理,通过设置页表建立了核心虚拟空间(即 boot_cr3 指向的二级页表描述的空间)。所以内核中的所有线程都不需要再建立各自的页表,只需共享这个核心虚拟空间就可以访问整个物理内存了。
首先在 kern/process/proc.h 中定义了 PCB,即进程控制块的结构体 proc_struct,如下:
struct proc_struct {
//进程控制块
enum proc_state state; //进程状态
int pid; //进程ID
int runs; //运行时间
uintptr_t kstack; //内核栈位置
volatile bool need_resched; //是否需要调度
struct proc_struct *parent; //父进程
struct mm_struct *mm; //进程的虚拟内存
struct context context; //进程上下文
struct trapframe *tf; //当前中断帧的指针
uintptr_t cr3; //当前页表地址
uint32_t flags; //进程
char name[PROC_NAME_LEN + 1];//进程名字
list_entry_t list_link; //进程链表
list_entry_t hash_link; //进程哈希表
};
结合实验指导书来分析PCB参数的含义:
- state:进程所处的状态。
- PROC_UNINIT // 未初始状态
- PROC_SLEEPING // 睡眠(阻塞)状态
- PROC_RUNNABLE // 运行与就绪态
- PROC_ZOMBIE // 僵死状态
- pid:进程 id 号。
- kstack:记录了分配给该进程/线程的内核桟的位置。
- need_resched:是否需要调度
- parent:用户进程的父进程。
- mm:即实验三中的描述进程虚拟内存的结构体
- context:进程的上下文,用于进程切换。
- tf:中断帧的指针,总是指向内核栈的某个位置。中断帧记录了进程在被中断前的状态。
- cr3:记录了当前使用的页表的地址
查看alloc_proc函数,可知该函数负责创建并初始化一个新的proc_struct结构存储内核线程信息,通过kmalloc函数便可以为相关的数据信息申请获得内存空间,之后进行初始化即可。初始过程中有一个小技巧,对于包含较多变量的成员变量或占据空间较大的变量,可以使用memset进行初始化。注意思考每种变量较为合理的初始化(初始化为0或是一些特殊值之类的)。根据代码注释的提示将变量一个个初始化即可,总的来说较为容易。
// alloc_proc -负责创建并初始化一个新的proc_struct结构存储内核线程信息
static struct proc_struct *
alloc_proc(void)
{
//为创建的线程申请空间
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL)
{
//LAB4:EXERCISE1 YOUR CODE
//因为没有分配物理页,故将线程状态初始为初始状态
proc->state=PROC_UNINIT;
proc->pid=-1; //id初始化为-1
proc->runs=0; //运行时间为0
proc->kstack=0;
proc->need_resched=0; //不需要释放CPU,因为还没有分配
proc->parent=NULL; //当前没有父进程,初始为null
proc->mm=NULL; //当前未分配内存,初始为null
//用memset非常方便将context变量中的所有成员变量置为0
//避免了一一赋值的麻烦。。
memset(&(proc -> context), 0, sizeof(struct context));
proc->tf=NULL; //当前没有中断帧,初始为null
proc->cr3=boot_cr3; //内核线程,cr3 等于boot_cr3
proc->flags=0;
memset(proc -> name, 0, PROC_NAME_LEN);
}
return proc;
}
整个分配初始化函数的运行过程为:
- 在堆上分配一块内存空间用来存放进程控制块
- 初始化进程控制块内的各个参数
- 返回分配的进程控制块
问题一:struct context context和struct trapframe *tf 成员 变量的含义和作用
根据提示我们查看相关的代码(通过查找定义tf以及context的函数):
首先我们找到了kernel_thread函数和copy_thread函数,可知该函数对tf进行了设置,并对context的esp和eip进行了设置(具体设置过程在代码注释中给出):
/* kernel_thread函数采用了局部变量tf来放置保存内核线程的临时中断帧,并把中断帧的指针传递给do_fork函数,而do_fork函数会调用copy_thread函数来在新创建的进程内核栈上专门给进程的中断帧分配一块空间 */
int kernel_thread(int (*fn)(void *), void *arg, uint32_t clone_flags) {
struct trapframe tf;
memset(&tf, 0, sizeof(struct trapframe));
//kernel_cs和kernel_ds表示内核线程的代码段和数据段在内核中
tf.tf_cs = KERNEL_CS;
tf.tf_ds = tf.tf_es = tf.tf_ss = KERNEL_DS;
//fn指实际的线程入口地址
tf.tf_regs.reg_ebx = (uint32_t)fn;
tf.tf_regs.reg_edx = (uint32_t)arg;
//kernel_thread_entry用于完成一些初始化工作
tf.tf_eip = (uint32_t)kernel_thread_entry;
return do_fork(clone_flags | CLONE_VM, 0, &tf);
}
static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf)
{
//将tf进行初始化
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf;
proc->tf->tf_regs.reg_eax = 0;
//设置tf的esp,表示中断栈的信息
proc->tf->tf_esp = esp;
proc->tf->tf_eflags |= FL_IF;
//对context进行设置
//forkret主要对返回的中断处理,基本可以认为是一个中断处理并恢复
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
通过上述函数并结合switch.S中对context的操作,将各种寄存器的值保存到context中。我们可以知道context是与上下文切换相关的,而tf则与中断的处理相关。
具体回答:
context作用:
进程的上下文,用于进程切换。主要保存了前一个进程的现场(各个寄存器的状态)。在uCore中,所有的进程在内核中也是相对独立的。使用context 保存寄存器的目的就在于在内核态中能够进行上下文之间的切换。实际利用context进行上下文切换的函数是在kern/process/switch.S中定义switch_to。
tf作用:
中断帧的指针,总是指向内核栈的某个位置:当进程从用户空间跳到内核空间时,中断帧记录了进程在被中断前的状态。当内核需要跳回用户空间时,需要调整中断帧以恢复让进程继续执行的各寄存器值。除此之外,uCore内核允许嵌套中断。因此为了保证嵌套中断发生时tf 总是能够指向当前的trapframe,uCore 在内核栈上维护了 tf 的链。
练习2:为新创建的内核线程分配资源(需要编码)
创建一个内核线程需要分配和设置好很多资源。kernel_thread函数通过调用do_fork函数完成具体内核线程的创建工作。do_kernel函数会调用alloc_proc函数来分配并初始化一个进程控制块,但alloc_proc只是找到了一小块内存用以记录进程的必要信息,并没有实际分配这些资源。ucore一般通过do_fork实际创建新的内核线程。do_fork的作用是,创建当前内核线程的一个副本,它们的执行上下文、代码、数据都一样,但是存储位置不同。在这个过程中,需要给新内核线程分配资源,并且复制原进程的状态。你需要完成在kern/process/proc.c中的do_fork函数中的处理过程。它的大致执行步骤包括:
- 调用alloc_proc,首先获得一块用户信息块。
- 为进程分配一个内核栈。
- 复制原进程的内存管理信息到新进程(但内核线程不必做此事)
- 复制原进程上下文到新进程
- 将新进程添加到进程列表
- 唤醒新进程
- 返回新进程号
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 请说明ucore是否做到给每个新fork的线程一个唯一的id?请说明你的分析和理由。
准备知识
根据注释提示我们了解几个函数用途以及用法:
//创建一个proc并初始化所有成员变量
void alloc_proc(void)
//为一个内核线程分配物理页
static int setup_kstack(struct proc_struct *proc)
//暂时未看出其用处,可能是之后的lab会用到
static int copy_mm(uint32_t clone_flags, struct proc_struct *proc)
//复制原进程上下文到新进程
static void copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf)
//返回一个pid
static int get_pid(void)
//将proc加入到hash_list
static void hash_proc(struct proc_struct *proc)
// 唤醒该线程,即将该线程的状态设置为可以运行
void wakeup_proc(struct proc_struct *proc);

上图是eflags寄存器
宏定义:
#define local_intr_save(x) \ do {
x = __intr_save(); } while (0)
#define FL_IF 0x00000200
#define local_intr_restore(x) __intr_restore(x);
下面是具体的实现过程:
根据要求可知,do_fork()函数的实现大致步骤包括七步,然后根据注释大致实现过程如下:
①调用alloc_proc()函数申请内存块,如果失败,直接返回处理。alloc_proc()函数在练习一中实现过,如果分配进程PCB失败,也就是说,进程一开始就是NULL,那么就会被if(proc!=NULL)判定为否,那么就不会分配初始化资源,连初始化资源都没有了,那么就会返回NULL。
②调用setup_kstack()函数为进程分配一个内核栈。从下面此函数代码中可以看到,如果页不为空的时候,会return 0,也就是说分配内核栈成功了(这样推测的根据在于,最后一个return -E_NO_MEM,大概推测就是一个初始化的或者错误的状态,因为在这个函数最开始不需要实现的部分,这个值就赋值给了ret),那么就会返回0,否则返回一个奇怪的东西。因此,我们调用该函数分配一个内核栈空间,并判断是否分配成功。
static int
setup_kstack(struct proc_struct *proc) {
struct Page *page = alloc_pages(KSTACKPAGE);
if (page != NULL) {
proc->kstack = (uintptr_t)page2kva(page);
return 0;
}
return -E_NO_MEM;
}
③调用copy_mm()函数,复制父进程的内存信息到子进程。对于这个函数可以看到,进程proc复制还是共享当前进程current,是根据clone_flags来决定的,如果是clone_flags & CLONE_VM(为真),那么就可以拷贝。这个函数里面似乎没有做任何事情,仅仅是确定了一下current当前进程的虚拟内存是否为空,那么具体的操作,只需要传入它所需要的clone_flag就可以,其余事情不需要我们去做。
static int
copy_mm(uint32_t clone_flags, struct proc_struct *proc) {
assert(current->mm == NULL);
/* do nothing in this project */
return 0;
}
④调用copy_thread()函数复制父进程的中断帧和上下文信息。copy_thread()函数需要传入的三个参数,第一个是比较熟悉,练习一中已经实现的PCB模块proc结构体的对象,第二个参数,是一个栈,判断的依据是它的数据类型,在练习一中的PCB模块中,为栈定义的数据类型就是uintptr_t,第三个参数也很熟悉,它是练习一PCB中的中断帧的指针。
static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) {
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf;
proc->tf->tf_regs.reg_eax = 0;
proc->tf->tf_esp = esp;
proc->tf->tf_eflags |= FL_IF;
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
⑤将新进程添加到进程的(hash)列表中。调用hash_proc这个函数可以将当前的新进程添加到进程的哈希列表中,分析hash函数的特点,直接调用hash(proc)即可。
hash_proc(struct proc_struct *proc) {
list_add(hash_list + pid_hashfn(proc->pid), &(proc->hash_link));
}
⑥唤醒新进程。
⑦返回新进程pid。
do_fork函数的实现:
int
do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
int ret = -E_NO_FREE_PROC;
struct proc_struct *proc;
if (nr_process >= MAX_PROCESS) {
goto fork_out;
}
ret = -E_NO_MEM;
//1:调用alloc_proc()函数申请内存块,如果失败,直接返回处理
if ((proc = alloc_proc()) == NULL) {
goto fork_out;
}
//2.将子进程的父节点设置为当前进程
proc->parent = current;
//3.调用setup_stack()函数为进程分配一个内核栈
if (setup_kstack(proc) != 0) {
goto bad_fork_cleanup_proc;
}
//4.调用copy_mm()函数复制父进程的内存信息到子进程
if (copy_mm(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
//5.调用copy_thread()函数复制父进程的中断帧和上下文信息
copy_thread(proc, stack, tf);
//6.将新进程添加到进程的hash列表中
bool intr_flag;
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc); //建立映射
nr_process ++; //进程数加1
list_add(&proc_list, &(proc->list_link));//将进程加入到进程的链表中
}
local_intr_restore(intr_flag);
// 7.一切就绪,唤醒子进程
wakeup_proc(proc);
// 8.返回子进程的pid
ret = proc->pid;
fork_out:
return ret;
bad_fork_cleanup_kstack:
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
}
问题一:ucore是否做到给每个新fork的线程一个唯一的id?
uCore中,每个新fork的线程都存在唯一的一个ID,理由如下:
- 在函数get_pid中,如果静态成员last_pid小于next_safe,则当前分配的last_pid一定是安全的,即唯一的PID。
- 但如果last_pid大于等于next_safe,或者last_pid的值超过MAX_PID,则当前的last_pid就不一定是唯一的PID,此时就需要遍历proc_list,重新对last_pid和next_safe进行设置,为下一次的get_pid调用打下基础。
接下来不妨分析该函数的内容:
在该函数中使用到了两个静态的局部变量 next_safe 和 last_pid,根据命名推测,在每次进入 get_pid 函数的时候,这两个变量的数值之间的取值均是合法的 pid(也就是说没有被使用过),这样的话,如果有严格的 next_safe > last_pid + 1,那么就可以直接取 last_pid + 1 作为新的 pid(需要 last_pid 没有超出 MAX_PID 从而变成 1);
如果在进入函数的时候,这两个变量之后没有合法的取值,也就是说 next_safe > last_pid + 1 不成立,那么进入循环,在循环之中首先通过 if (proc->pid == last_pid) 这一分支确保了不存在任何进程的 pid 与 last_pid 重合,然后再通过 if (proc->pid > last_pid && next_safe > proc->pid) 这一判断语句保证了不存在任何已经存在的 pid 满足:last_pid < pid < next_safe,这样就确保了最后能够找到这么一个满足条件的区间,获得合法的 pid;
之所以在该函数中使用了如此曲折的方法,维护一个合法的 pid 的区间,是为了优化时间效率,如果简单的暴力的话,每次需要枚举所有的 pid,并且遍历所有的线程,这就使得时间代价过大,并且不同的调用 get_pid 函数的时候不能利用到先前调用这个函数的中间结果;
getpid函数如下:
// get_pid - alloc a unique pid for process
static int
get_pid(void) {
//实际上,之前定义了MAX_PID=2*MAX_PROCESS,意味着ID的总数目是大于PROCESS的总数目的
//因此不会出现部分PROCESS无ID可分的情况
static_assert(MAX_PID > MAX_PROCESS);
struct proc_struct *proc;
list_entry_t *list = &proc_list, *le;
//next_safe和last_pid两个变量,这里需要注意! 它们是static全局变量!!!
static int next_safe = MAX_PID, last_pid = MAX_PID;
//++last_pid>-MAX_PID,说明pid以及分到尽头,需要从头再来
if (++ last_pid >= MAX_PID)
{
last_pid = 1;
goto inside;
}
if (last_pid >= next_safe)
{
inside:
next_safe = MAX_PID;
repeat:
//le等于线程的链表头
le = list;
//遍历一遍链表
//循环扫描每一个当前进程:当一个现有的进程号和last_pid相等时,则将last_pid+1;
//当现有的进程号大于last_pid时,这意味着在已经扫描的进程中
//[last_pid,min(next_safe, proc->pid)] 这段进程号尚未被占用,继续扫描。
while ((le = list_next(le)) != list)
{
proc = le2proc(le, list_link);
//如果proc的pid与last_pid相等,则将last_pid加1
//当然,如果last_pid>=MAX_PID,then 将其变为1
//确保了没有一个进程的pid与last_pid重合
if (proc->pid == last_pid)
{
if (++ last_pid >= next_safe)
{
if (last_pid >= MAX_PID)
{
last_pid = 1;
}
next_safe = MAX_PID;
goto repeat;
}
}
//last_pid<pid<next_safe,确保最后能够找到这么一个满足条件的区间,获得合法的pid;
else if (proc->pid > last_pid && next_safe > proc->pid)
{
next_safe = proc->pid;
}
}
}
return last_pid;
}
练习3:阅读代码,理解 proc_run 函数和它调用的函数如何完成进程切换的。(无编码工作)
请在实验报告中简要说明你对proc_run函数的分析。并回答如下问题:
- 在本实验的执行过程中,创建且运行了几个内核线程?
- 语句
local_intr_save(intr_flag);....local_intr_restore(intr_flag);在这里有何作用?请说明理由
完成代码编写后,编译并运行代码:make qemu
如果可以得到如 附录A所示的显示内容(仅供参考,不是标准答案输出),则基本正确。
准备知识
根据实验指导书,uCore中,内核的第一个进程idleproc会执行cpu_idle函数,并从中调用schedule函数,准备开始调度进程,完成进程调度和进程切换。
void cpu_idle(void) {
while (1)
if (current->need_resched)
schedule();
}
schedule函数代码分析:
/* 宏定义: #define le2proc(le, member) \ to_struct((le), struct proc_struct, member)*/
void
schedule(void) {
bool intr_flag; //定义中断变量
list_entry_t *le, *last; //当前list,下一list
struct proc_struct *next = NULL; //下一进程
local_intr_save(intr_flag); //中断禁止函数
{
current->need_resched = 0; //设置当前进程不需要调度
//last是否是idle进程(第一个创建的进程),如果是,则从表头开始搜索
//否则获取下一链表
last = (current == idleproc) ? &proc_list : &(current->list_link);
le = last;
do {
//一直循环,直到找到可以调度的进程
if ((le = list_next(le)) != &proc_list) {
next = le2proc(le, list_link);//获取下一进程
if (next->state == PROC_RUNNABLE) {
break; //找到一个可以调度的进程,break
}
}
} while (le != last); //循环查找整个链表
if (next == NULL || next->state != PROC_RUNNABLE) {
next = idleproc; //未找到可以调度的进程
}
next->runs ++; //运行次数加一
if (next != current) {
proc_run(next); //运行新进程,调用proc_run函数
}
}
local_intr_restore(intr_flag); //允许中断
}
可以看到ucore实现的是FIFO调度算法:
1 调度开始时,先屏蔽中断。
2 在进程链表中,查找第一个可以被调度的程序
3 运行新进程,允许中断
chedule函数会先清除调度标志,并从当前进程在链表中的位置开始,遍历进程控制块,直到找出处于就绪状态的进程。
之后执行proc_run函数,将环境切换至该进程的上下文并继续执行。
提到上下文切换,就需要使用switch_to函数:
switch_to: # switch_to(from, to)
# save from's registers
movl 4(%esp), %eax #保存from的首地址
popl 0(%eax) #将返回值保存到context的eip
movl %esp, 4(%eax) #保存esp的值到context的esp
movl %ebx, 8(%eax) #保存ebx的值到context的ebx
movl %ecx, 12(%eax) #保存ecx的值到context的ecx
movl %edx, 16(%eax) #保存edx的值到context的edx
movl %esi, 20(%eax) #保存esi的值到context的esi
movl %edi, 24(%eax) #保存edi的值到context的edi
movl %ebp, 28(%eax) #保存ebp的值到context的ebp
# restore to's registers
movl 4(%esp), %eax #保存to的首地址到eax
movl 28(%eax), %ebp #保存context的ebp到ebp寄存器
movl 24(%eax), %edi #保存context的ebp到ebp寄存器
movl 20(%eax), %esi #保存context的esi到esi寄存器
movl 16(%eax), %edx #保存context的edx到edx寄存器
movl 12(%eax), %ecx #保存context的ecx到ecx寄存器
movl 8(%eax), %ebx #保存context的ebx到ebx寄存器
movl 4(%eax), %esp #保存context的esp到esp寄存器
pushl 0(%eax) #将context的eip压入栈中
ret
所以switch_to函数主要完成的是进程的上下文切换,先保存当前寄存器的值,然后再将下一进程的上下文信息保存到对于寄存器中。
proc_run函数
void
proc_run(struct proc_struct *proc) {
if (proc != current) {
bool intr_flag;//定义中断变量
struct proc_struct *prev = current, *next = proc;
local_intr_save(intr_flag); //屏蔽中断
{
current = proc;//修改当前进程为新进程
load_esp0(next->kstack + KSTACKSIZE);//修改esp
lcr3(next->cr3);//修改页表项,完成进程间的页表切换
switch_to(&(prev->context), &(next->context));//上下文切换
}
local_intr_restore(intr_flag); //允许中断
}
}
实现思路:
- 让 current 指向 next 内核线程 initproc;
- 设置任务状态段 ts 中特权态 0 下的栈顶指针 esp0 为 next 内核线程 initproc 的内核栈的栈顶,即 next->kstack + KSTACKSIZE ;
- 设置 CR3 寄存器的值为 next 内核线程 initproc 的页目录表起始地址 next->cr3,这实际上是完成进程间的页表切换;
- 由 switch_to函数完成具体的两个线程的执行现场切换,即切换各个寄存器,当 switch_to 函数执行完“ret”指令后,就切换到 initproc 执行了
问题一:在本实验的执行过程中,创建且运行了几个内核线程?
两个,分别是idleproc和initproc。
- idleproc:第一个内核进程,完成内核中各个子系统的初始化,之后立即调度,执行其他进程。
- initproc:用于完成实验的功能而调度的内核进程。
问题二:语句A在这里有何作用?请说明理由。
作用分别是屏蔽中断和打开中断,以免进程切换时其他进程再进行调度。也就是保护进程切换不会被中断,以免进程切换时其他进程再进行调度,相当于互斥锁。之前在第六步添加进程到列表的时候也需要有这个操作,是因为进程进入列表的时候,可能会发生一系列的调度事件,比如我们所熟知的抢断等,加上这么一个保护机制可以确保进程执行不被打乱。
实验结果
输入make qemu和实验指导书中对照:
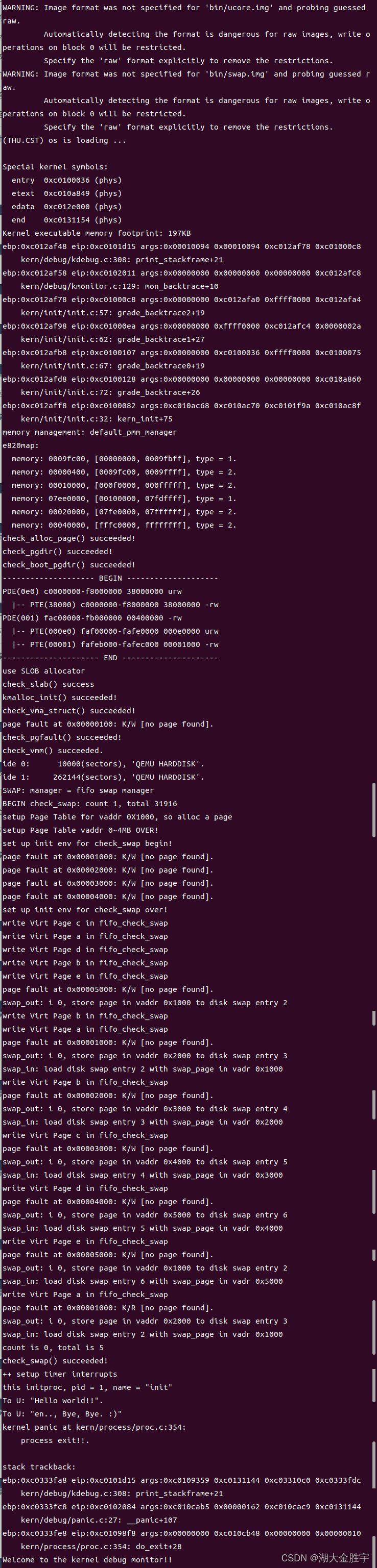
发现相同,说明实验实现是成功的。
接下来,输入make grade可以得出以下结果:
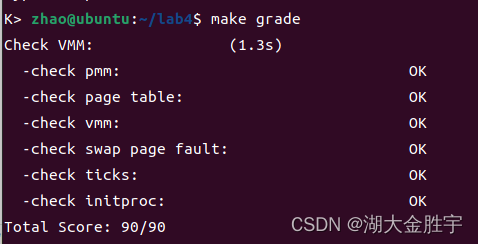
扩展练习Challenge:实现支持任意大小的内存分配算法
这不是本实验的内容,其实是上一次实验内存的扩展,但考虑到现在的slab算法比较复杂,有必要实现一个比较简单的任意大小内存分配算法。可参考本实验中的slab如何调用基于页的内存分配算法(注意,不是要你关注slab的具体实现)来实现first-fit/best-fit/worst-fit/buddy等支持任意大小的内存分配算法。
实现过程
通过少量的修改,即可使用实验2扩展练习实现的 Slub 算法。
- 初始化 Slub 算法:在初始化物理内存最后初始化 Slub ;
void pmm_init(void) {
...
kmem_int();
}
- 在 vmm.c 中使用 Slub 算法:
为了使用Slub算法,需要声明仓库的指针。
struct kmem_cache_t *vma_cache = NULL;
struct kmem_cache_t *mm_cache = NULL;
在虚拟内存初始化时创建仓库。
void vmm_init(void) {
mm_cache = kmem_cache_create("mm", sizeof(struct mm_struct), NULL, NULL);
vma_cache = kmem_cache_create("vma", sizeof(struct vma_struct), NULL, NULL);
...
}
在 mm_create 和 vma_create 中使用 Slub 算法。
struct mm_struct *mm_create(void) {
struct mm_struct *mm = kmem_cache_alloc(mm_cache);
...
}
struct vma_struct *vma_create(uintptr_t vm_start, uintptr_t vm_end, uint32_t vm_flags) {
struct vma_struct *vma = kmem_cache_alloc(vma_cache);
...
}
在 mm_destroy 中释放内存。
void
mm_destroy(struct mm_struct *mm) {
...
while ((le = list_next(list)) != list) {
...
kmem_cache_free(mm_cache, le2vma(le, list_link)); //kfree vma
}
kmem_cache_free(mm_cache, mm); //kfree mm
...
}
- 在 proc.c 中使用 Slub 算法:
声明仓库指针。
struct kmem_cache_t *proc_cache = NULL;
在初始化函数中创建仓库。
void proc_init(void) {
...
proc_cache = kmem_cache_create("proc", sizeof(struct proc_struct), NULL, NULL);
...
}
在 alloc_proc 中使用 Slub 算法。
static struct proc_struct *alloc_proc(void) {
struct proc_struct *proc = kmem_cache_alloc(proc_cache);
...
}
参考答案分析:
与参考答案思路几乎一致。
实验中涉及的知识点列举:
- 进程
- 进程控制块
- 进程状态
- 进程挂起
- 线程
- 概念
- 优缺点
- 用户线程与内核线程
- 线程与进程的比较
心得和体会:
这次实验比起lab1、lab2以及lab3实验,总体来说实验的内容更少了,但是所需要的知识却更加的深入了。学习到了更多知识。
}
kmem_cache_free(mm_cache, mm); //kfree mm
...
}
- 在 proc.c 中使用 Slub 算法:
声明仓库指针。
```c
struct kmem_cache_t *proc_cache = NULL;
在初始化函数中创建仓库。
void proc_init(void) {
...
proc_cache = kmem_cache_create("proc", sizeof(struct proc_struct), NULL, NULL);
...
}
在 alloc_proc 中使用 Slub 算法。
static struct proc_struct *alloc_proc(void) {
struct proc_struct *proc = kmem_cache_alloc(proc_cache);
...
}
参考答案分析:
与参考答案思路几乎一致。
实验中涉及的知识点列举:
- 进程
- 进程控制块
- 进程状态
- 进程挂起
- 线程
- 概念
- 优缺点
- 用户线程与内核线程
- 线程与进程的比较
心得和体会:
这次实验比起lab1、lab2以及lab3实验,总体来说实验的内容更少了,但是所需要的知识却更加的深入了。学习到了更多知识。
边栏推荐
- ucore lab5用户进程管理 实验报告
- Detailed introduction to dynamic programming (with examples)
- Dlib detects blink times based on video stream
- Mysql的事务
- What to do when programmers don't modify bugs? I teach you
- Stc-b learning board buzzer plays music 2.0
- MySQL development - advanced query - take a good look at how it suits you
- How to change XML attribute - how to change XML attribute
- 转行软件测试必需要知道的知识
- 安全测试入门介绍
猜你喜欢

线程及线程池
Interview answering skills for software testing

51 lines of code, self-made TX to MySQL software!
Leetcode simple question: check whether the numbers in the sentence are increasing

What are the commonly used SQL statements in software testing?
ucore lab1 系统软件启动过程 实验报告
Practical cases, hand-in-hand teaching you to build e-commerce user portraits | with code
UCORE lab5 user process management experiment report
Soft exam information system project manager_ Project set project portfolio management --- Senior Information System Project Manager of soft exam 025
MySQL数据库(四)事务和函数

随机推荐
ucore lab7 同步互斥 实验报告
Threads et pools de threads
If the position is absolute, touchablehighlight cannot be clicked - touchablehighlight not clickable if position absolute
Interview answering skills for software testing
How to rename multiple folders and add unified new content to folder names
Global and Chinese markets for complex programmable logic devices 2022-2028: Research Report on technology, participants, trends, market size and share
Introduction to variable parameters
Introduction to safety testing
Stc-b learning board buzzer plays music 2.0
Common Oracle commands
Lab 8 文件系统
Face and eye recognition based on OpenCV's own model
UCORE lab8 file system experiment report
The minimum number of operations to convert strings in leetcode simple problem
Global and Chinese markets for GaN on diamond semiconductor substrates 2022-2028: Research Report on technology, participants, trends, market size and share
Heap, stack, queue
ucore lab6 调度器 实验报告
Cadence physical library lef file syntax learning [continuous update]
Oracle foundation and system table
Leetcode simple question: check whether two strings are almost equal