当前位置:网站首页>UCORE lab5 user process management experiment report
UCORE lab5 user process management experiment report
2022-07-06 15:14:00 【Wuhu hanjinlun】
The experiment purpose
- Understand the first user process creation process
- Understand the implementation mechanism of the system call framework
- understand ucore How to implement system call sys_fork/sys_exec/sys_exit/sys_wait For process management
Experimental content
experiment 4 Completed the kernel thread , But so far , All operations are executed in kernel mode . experiment 5 The user process... Will be created , Let the user process execute in user mode , And when necessary ucore When supported , You can use system calls to make ucore Provide services . To do this, you need to construct the first user process , And through system call sys_fork/sys_exec/sys_exit/sys_wait To support running different applications , Complete the basic management of the execution process of the user process . See the appendix for the introduction of relevant principles B.
practice
practice 0: Fill in the existing experiment
This experiment relies on experiments 1/2/3/4. Please take your experiment 1/2/3/4 Fill in the code in this experiment. There are “LAB1”/“LAB2”/“LAB3”/“LAB4” The corresponding part of the notes . Be careful : In order to execute correctly lab5 Test application for , It may be necessary to test the completed experiments 1/2/3/4 Code for further improvements .
experiment 0 Mainly before 4 The code of this experiment is added , Include
- kdebug.c
- trap.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- proc.c
The relevant codes of seven documents . In addition to direct supplement , There are some places where the code needs to be modify perhaps improvement :
It is suggested that you can directly copy answer The file of
alloc_proc function :
stay lab4 On the basis of , Added wait_state ,proc->cptr , proc->optr , proc->yptr Four variables , In fact, we only need take wait_state Initialize to 0, The three pointers are initialized to NULL that will do . Avoid errors when managing user processes due to undefined or uninitialized processes .
static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
// .....
// The following two sentences are new
proc->wait_state = 0;
proc->cptr = proc->optr = proc->yptr = NULL;
}
return proc;
}
These two lines of code are mainly about the waiting state of the initialization process 、 And process related pointers , For example, the parent process 、 Subprocesses 、 Compatriots, etc . Among them wait_state Is a new entry in the process control block .
Because this involves user processes , Naturally, scheduling problems need to be involved , So the process waiting state and various pointers need to be initialized .
do_fork function
Add a check on the waiting state of the current process , And the use of set_links Function to set the relationship between processes .
The codes added and deleted are :
proc->parent = current;
// The following sentence is the added code
assert(current->wait_state == 0);
if (setup_kstack(proc) != 0) {
goto bad_fork_cleanup_proc;
}
if (copy_mm(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
copy_thread(proc, stack, tf);
bool intr_flag;
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc);
//list_add(&proc_list, &(proc->list_link));
//nr_process ++; These two sentences are lab4 To be deleted from
// The following sentence is to be added
set_links(proc);
}
local_intr_restore(intr_flag);
trap_dispatch function :
Set every 100 After time interruption , The currently executing process is ready to be scheduled . meanwhile , Comment out the original "100ticks" Output
ticks ++;
if (ticks % TICK_NUM == 0) {
assert(current != NULL);
current->need_resched = 1;
// In the original code print_ticks(); Change to the above two sentences
}
break;
idt_init function
Set the interrupt gate of a specific interrupt number , Dedicated for user process access to system calls , That is, set interrupt T_SYSCALL The trigger privilege level of is DPL_USER
oid idt_init(void) {
// ......
// Add the following sentence
SETGATE(idt[T_SYSCALL], 1, GD_KTEXT, __vectors[T_SYSCALL], DPL_USER);
// ......
}
practice 1: Load the application and execute ( Need to code )
do_execve Function call load_icode( be located kern/process/proc.c in ) To load and parse a in memory ELF Execute file format applications , Set up the corresponding user memory space to place the code segments of the application 、 Data segments, etc , And it should be set proc_struct Member variables in the structure trapframe The content in , Make sure that after executing this process , It can be executed from the starting address set by the application . Set the correct trapframe Content .
Please briefly describe your design and implementation process in the experimental report .
Please describe in the experiment report when you create a user mode process and load the application ,CPU How to make this application finally execute in user mode . That is, the user state process is ucore Select occupancy CPU perform (RUNNING state ) The whole process of implementing the first instruction of the application program .
do_execve function
do_execve Function call load_icode To load and parse a in memory ELF Execute file format applications
// The main purpose is to clean up the memory space of the original process , Prepare space and resources for the implementation of new processes
int do_execve(const char *name, size_t len, unsigned char *binary, size_t size)
{
struct mm_struct *mm = current->mm;
if (!user_mem_check(mm, (uintptr_t)name, len, 0)) {
return -E_INVAL;
}
if (len > PROC_NAME_LEN) {
len = PROC_NAME_LEN;
}
char local_name[PROC_NAME_LEN + 1];
memset(local_name, 0, sizeof(local_name));
memcpy(local_name, name, len);
// If mm Not for NULL, Then do not execute the process
if (mm != NULL)
{
// take cr3 The base address of the page table points to boot_cr3, That is, the kernel page table
lcr3(boot_cr3);// Switch to kernel mode
if (mm_count_dec(mm) == 0)
{
// The next three steps are to empty the memory management area of the process
exit_mmap(mm);// Empty the memory management part and the corresponding page table
put_pgdir(mm);// Empty the page table
mm_destroy(mm);// Clear Memory
}
current->mm = NULL;// Finally, let its current page table point to null , It's convenient to put your own things
}
int ret;
// Fill in the new content ,load_icode The execution program will be loaded , Create a new memory mapping relationship , So as to complete the new implementation
if ((ret = load_icode(binary, size)) != 0) {
goto execve_exit;
}
// Give the process a new name
set_proc_name(current, local_name);
return 0;
execve_exit:
do_exit(ret);
panic("already exit: %e.\n", ret);
}
do_execve The main work of function is to Reclaim the user space occupied by itself , And then call load_icode, Cover the memory space with a new program , Form a new process to execute the new program .
Let's analyze load_icode function
load_icode function
load_icode The main job of the function is to give the user process Create a user environment that allows user processes to run normally . This function has more than a hundred lines , The following important work has been completed :
- call
mm_createFunction to apply for the memory management data structure of the process mm Required memory space , Also on mm Conduct initialization ; - call
setup_pgdirTo apply for a page size memory space required for a page directory table , And describe ucore Kernel virtual space mapping Kernel page table (boot_pgdirTo refer to ) The content of Copy In this new catalog table , Finally letmm->pgdirPoint to the table of contents on this page , This is the new page directory table of the process , And can correctly map the kernel virtual space ; - This code is parsed according to the starting position of the application execution code ELF Format execution program , And call
mm_mapFunctions are based on ELF The format of the execution program describes the various paragraphs ( Code segment 、 Data segment 、BSS Duan et al ) The starting position and size of the corresponding vma structure , And put vma Insert into mm In structure , Thus, it shows the legal user state virtual address space of user process ; - The call depends on the size of each segment of the executing program Allocate physical memory space , And according to the starting position of each segment of the execution program Determine the virtual address , And establish the mapping relationship between physical address and virtual address in the page table , Then copy the contents of each segment of the execution program to the corresponding kernel virtual address , So far, the application execution code and data have been placed in the virtual memory according to the address set at compile time ;
- You need to set the user stack for the user process , Call... For this
mm_mmapFunction to build the user stack vma structure , Make it clear that the position of the user stack is at the top of the user virtual space , The size is 256 A page , namely 1MB, Allocate a certain amount of physical memory and establish the virtual address of the stack <------> Physical address mapping relationship ; - thus , In process memory management vma and mm The data structure has been established , So the
mm->pgdirAssign values to thecr3In the register , That is, the virtual memory space of the user process is updated , At this timeinitprocHas been hello Code and data coverage , Became the first user process , But at this time, the execution site of the user process has not been established ; - First Clear the interrupt frame of the process , Again Reset the interrupt frame of the process , Make the interrupt return instruction “
iret” after , To be able to make CPU Go to the user state privilege level , And return to the user state memory space , Code snippets using user mode 、 Segments and stacks , And can jump to the first instruction execution of the user process , And ensure that the interrupt can be responded to in the user state ;
The specific implementation part is as follows :
/* load_icode - Load the contents of the binary program (ELF Format ) As a new content of the current process 1. @binary: Memory address of binary program contents 2. @size: Size of binary program contents */
static int
load_icode(unsigned char *binary, size_t size) {
...
/* tf_cs Set to user mode tf_ds=tf_es=tf_ss= User mode tf_esp Set as the top of the user stack tf_eip Set as the entry of binary program tf_eflags Set to open interrupt */
// below 6 The sentence is the part supplemented according to the notes
tf->tf_cs = USER_CS;// take tf_cs Set to user mode
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;//tf_ds=tf_es=tf_ss It also needs to be set to user mode
tf->tf_esp = USTACKTOP;// Need to put esp Set as the top of the user stack , Directly use the parameters when creating the user stack before USTACKTOP Can .
tf->tf_eip = elf->e_entry;//eip It's the entrance to the program ,elf Class e_entry Function directly declares , Use it directly .
tf->tf_eflags = FL_IF;//FL_IF Turn on interrupt
ret = 0;
...
}
Question answering
Please describe in the experiment report when you create a user mode process and load the application ,CPU How to make this application finally execute in user mode . That is, the user state process is ucore Select occupancy CPU perform (RUNNING state ) The whole process of implementing the first instruction of the application program .
- call
schedulefunction , The scheduler occupies CPU After all the resources , User mode process calledexecsystem call , Thus, it goes to the processing routine of the system call - After that, the normal interrupt processing routine , Then control shifted to
syscall.cMediumsyscallfunction , Then it is transferred to according to the system call numbersys_execfunction , Called in this functiondo_execveFunction to complete the loading of the specified application - stay
do_execveSeveral settings are made in , Including the page table of the current process , Switch to the kernel PDT, callload_icodeFunction to initialize the memory space of the entire user thread , Including stack settings and adding ELF Loading of executables , After throughcurrent->tfThe pointer modifies the current system calltrapframe, This enables the user state to be switched when the final interrupt returns , And at the same time, it can correctly transfer control to the entrance of the application - At the completion of the
do_execAfter the function , The process of normal interrupt return , Because the interrupt processing routine is on the stack eip It has been modified to be the entrance of the application , and CS Upper CPL It's user mode , thereforeiretWhen the interrupt returns, the stack will be switched to the user's stack , And complete the privilege level switch , And jump to the entrance of the required application - Start executing the first code of the application
practice 2: The parent process copies its own memory space to the child process ( Need to code )
The function that creates the child process do_fork The current process will be copied in execution ( The parent process ) Of the user memory address space to the new process ( Subprocesses ), Finish copying memory resources . Specifically through copy_range function ( be located kern/mm/pmm.c in ) Realized , Please add copy_range The implementation of the , Ensure that... Can be performed correctly .
Please briefly explain how to design and implement in the experiment report ”Copy on Write Mechanism “, Give the outline design , Encourage detailed design .
Copy-on-write( abbreviation COW) The basic concept of is that if there are multiple users for a resource A( Such as memory block ) Read it , Then each user only needs to get one pointing to the same resource A The pointer to , You can use this resource . If a user needs to access this resource A Write operation , The system will copy the resource , So that the “ Write operations ” The user gets a copy of the resource A Of “ private ” Copy — resources B, Resources can be B Write operation . The “ Write operations ” Users are interested in resources B Changes to the are invisible to other users , Because other users still see resources A.
We first analyze the parent process call fork The system calls the process of generating sub processes :
- Parent process call
forksystem call , Enter the normal interrupt processing mechanism , It's up tosyscallFunction to process - stay
syscallFunction , According to the system call , Leave it tosys_forkFunction processing - This function further calls
do_forkfunction , This function is mainly used to create sub processes 、 And copy the memory space of the parent process to the logic of the child process - stay
do_forkFunction , callcopy_mmCopy memory space , In this function , Called furtherdup_mmap, In this function , Traversed all the legal virtual memory space of the parent process , And copy the contents of these spaces into the memory space of the child process , The specific function of memory replication is what we need to improve in this exercisecopy_range - stay
copy_rangeFunction , Copy the memory space to be copied from the memory space of the parent process to the memory space of the child process in page units
The conclusion is :copy_range Calling procedure of function :do_fork()---->copy_mm()---->dup_mmap()---->copy_range()
(1)do_fork() function
if (copy_mm(clone_flags, proc) != 0) {
//3. call copy_mm() Function copies the memory information of the parent process to the child process
goto bad_fork_cleanup_kstack;
do_fork Function called copy_mm function , Create a process , And put in CPU Medium scheduling , This time we mainly focus on how to copy memory between parent and child processes .
(2)copy_mm() function
lock_mm(oldmm);// Open the mutex , Avoid multiple processes accessing memory at the same time
{
ret = dup_mmap(mm, oldmm);// call dup_mmap function
}
unlock_mm(oldmm);// Release the mutex
use The mutex , Used to avoid multiple processes accessing memory at the same time , Here is the next level call : Called dup_mmap() function .
(3)dup_mmap() function
bool share = 0;
if (copy_range(to->pgdir, from->pgdir, vma->vm_start, vma->vm_end, share) != 0) {
// call copy_range function
return -E_NO_MEM;
}
Let's first look at the parameters passed in , It's two memories mm, In the last function copy_mm in , The two memories passed in are called mm and oldmm, among , first mm Just called mm_create() Statement , But not initialized , There is no distribution ; the second oldmm yes current Memory space of the process , thus it can be seen , Previous mm Is the memory to be copied , The copied source content is oldmm( The parent process ) In content .
(4) Realization copy_range function
copy_range The specific execution process of the function is as follows : Traverse Every virtual page in a certain memory space specified by the parent process , If this virtual page exists , The same address corresponding to the child process ( But the page table of contents is different , So it's not a memory space ) also Apply to allocate a physical page , Then put all the contents in the former Copy Go to the latter , Then the physical page and the corresponding virtual address of the child process ( It's actually a linear address ) Establish a mapping relationship ; In this exercise, you need to complete the copy of memory and the establishment of mapping , The specific process is as follows :
- Find the kernel virtual address corresponding to a physical page specified by the parent process
- Find the virtual address of the kernel corresponding to the corresponding physical page of the child process that needs to be copied
- Copy the contents of the former into the latter
- This physical page is currently allocated to the child process mapping A virtual page in the virtual address space of the child process corresponding to
The complete code is :
// Move the actual code segment and data segment into the new sub process , Then set the relevant contents of the page table
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
// Make sure start and end Divisibility PGSIZE
assert(start % PGSIZE == 0 && end % PGSIZE == 0);
assert(USER_ACCESS(start, end));
// Copy in pages
do {
// obtain A&B Of pte Address
pte_t *ptep = get_pte(from, start, 0), *nptep;
if (ptep == NULL)
{
start = ROUNDDOWN(start + PTSIZE, PTSIZE);
continue ;
}
if (*ptep & PTE_P) {
if ((nptep = get_pte(to, start, 1)) == NULL) {
return -E_NO_MEM;
}
uint32_t perm = (*ptep & PTE_USER);
//get page from ptep
struct Page *page = pte2page(*ptep);
// by B One page space
struct Page *npage=alloc_page();
assert(page!=NULL);
assert(npage!=NULL);
int ret=0;
// The following four sentences of code are the implementation part of this exercise
//1. Find the kernel virtual page address of the parent process
void * kva_src = page2kva(page);
//2. Find the kernel virtual page address of the child process
void * kva_dst = page2kva(npage);
//3. Copy the contents of the parent process to the child process
memcpy(kva_dst, kva_src, PGSIZE);
//4. Establish the mapping relationship between the physical address and the starting position of the page address of the child process
ret = page_insert(to, npage, start, perm);
assert(ret == 0);
}
start += PGSIZE;
} while (start != 0 && start < end);
return 0;
}
practice 2 The problem is challenge Middle answer
practice 3: Read and analyze the source code , Understand process execution fork/exec/wait/exit The implementation of the , And the implementation of system call ( No coding required )
Please briefly explain your understanding of fork/exec/wait/exit Analysis of functions . And answer the following questions :
- Please analyze fork/exec/wait/exit How the implementation affects the execution state of the process ?
- Please give me ucore Execution state lifecycle diagram of a user state process in ( Package execution status , Execute the transformation relationship between states , And the event or function call that produces the transformation ).( Characters can be drawn )
fork
Complete the copy of the process , from do_fork Function completion , The main process is as follows :
- First, check whether the current total number of processes has reached the limit , If the limit is reached , Then the return
E_NO_FREE_PROC - Allocate and initialize process control blocks (
alloc_procfunction ) - Allocate and initialize the kernel stack (
setup_stackfunction ) - according to
clone_flagFlag copy or share process memory management structure (copy_mmfunction ) - Set the process in the kernel ( In the future, it also includes user mode ) Interrupt frames and execution context required for normal operation and scheduling (
copy_threadfunction ) - Put the set process control block into
hash_listandproc_listIn the linked list of two global processes - Since then , The process is ready to execute , Set the process status to “ be ready ” state
- Set the return code to that of the child process id Number
int ret = -E_NO_FREE_PROC;//1. First, check whether the current total number of processes has reached the limit
if ((proc = alloc_proc()) == NULL) {
//2. call alloc_proc() Function request memory block
goto fork_out;
}
proc->parent = current;// Set the parent node of the child process as the current process
assert(current->wait_state == 0);// Make sure that the current process is waiting
if (setup_kstack(proc) != 0) {
//3. call setup_stack() Function to allocate a kernel stack for the process
goto bad_fork_cleanup_proc;
}
if (copy_mm(clone_flags, proc) != 0) {
//4. call copy_mm() Function copies the memory information of the parent process to the child process
goto bad_fork_cleanup_kstack;
}
copy_thread(proc, stack, tf);//5. call copy_thread() Function copies the interrupt frame and context information of the parent process
//6. Add a new process to the process's (hash) In the list
bool intr_flag;
local_intr_save(intr_flag);// Mask interrupt ,intr_flag Set as 1
{
proc->pid = get_pid();// Get the current process PID
hash_proc(proc); // establish hash mapping
set_links(proc);// Set the process link
}
local_intr_restore(intr_flag);// Resume interrupt
wakeup_proc(proc);//7. Wake up a new process
ret = proc->pid;//8. Returns the current process's PID
exec
Complete the creation of user process , At the same time, it enables the user process to enter the execution . from do_exec Function completion , The main process is as follows :
- Check whether the address and length of the process name are legal , If the legitimate , Then save the name temporarily in the function stack , Otherwise return to
E_INVAL; - take
cr3The page table base address points to the kernel page table , Then realize the memory management area of the process Release ; - call
load_icodeLoad the code into memory and establish a new memory mapping relationship , If loading error , So calledpanicReport errors ; - call
set_proc_nameReset the process name .
The complete code is practicing 1 It's done
wait
Complete the recycling of the memory space occupied by the kernel stack and process control block of the sub process . from do_wait Function completion , The main process is as follows :
- First check the
code_storeThe pointer address is within the legal range - according to
PIDFind the child process that needs to waitPCB, Loop to ask the status of the waiting child process , Until the state of a child process changes toZOMBIE- If there is no child process to wait , Then the return
E_BAD_PROC - If the child process is in an executable state , Then sleep the current process , Try again after being awakened
- If the child process is in an executable state , Then sleep the current process , Try again after being awakened
- If there is no child process to wait , Then the return
if (pid != 0) {
// If pid!=0, Then find the process id by pid Child process in exit state of
proc = find_proc(pid);
if (proc != NULL && proc->parent == current) {
haskid = 1;
if (proc->state == PROC_ZOMBIE) {
goto found;// Find the process
}
}
}
else {
// If pid==0, Then randomly find a child process in the exit state
proc = current->cptr;
for (; proc != NULL; proc = proc->optr) {
haskid = 1;
// If the child process is not in zombie state , Then it will become sleep , Because you need to wait for the subprocess to exit , Then call schedule Function suspends itself , Select another process to execute . If it is zombie , Then the process will be cleared .
if (proc->state == PROC_ZOMBIE) {
goto found;
}
}
}
if (haskid) {
// If not , Then the parent process goes back to sleep , And repeat the search process
current->state = PROC_SLEEPING;
current->wait_state = WT_CHILD;
schedule();
if (current->flags & PF_EXITING) {
do_exit(-E_KILLED);
}
goto repeat;
}
return -E_BAD_PROC
exit
Complete some resource recycling during the exit process of the current process . from do_exit Function completion , The main process is as follows :
- Release Virtual memory space of the process
- Set the current process status to
PROC_ZOMBIEThat is, marked as a zombie process - If the parent process is waiting for the current process to exit , Then wake up the parent process
- If the current process has child processes , Set the subprocess to
initprocCan be inherited by child processes. , And complete the final recycling of the process in the zombie state in the sub process - Active call scheduling function To schedule , Choose a new process to execute
The code is as follows :
do_exit(int error_code) {
if (current == idleproc) {
panic("idleproc exit.\n");
}
if (current == initproc) {
panic("initproc exit.\n");
}
struct mm_struct *mm = current->mm;
if (mm != NULL) {
// If the process is a user process , Ready to reclaim memory , First of all, it should not be empty
lcr3(boot_cr3);// Switch to the page table in kernel mode , Switch from user mode to kernel mode
if (mm_count_dec(mm) == 0) {
exit_mmap(mm);
put_pgdir(mm);// Free the memory occupied by the page directory
mm_destroy(mm);// Release mm Memory footprint , Recycle page directory 、 Free memory
}
current->mm = NULL;// Finally, point its memory address to null , Complete memory recycling
}
current->state = PROC_ZOMBIE;// Set zombie status , Wait for the parent process to recycle
current->exit_code = error_code;// Wait for the parent process to do the final recycling
bool intr_flag;
struct proc_struct *proc;
local_intr_save(intr_flag);
{
proc = current->parent;
if (proc->wait_state == WT_CHILD) {
wakeup_proc(proc);// If the parent process is waiting for the child process , Then wake up
}
while (current->cptr != NULL) {
/* If the current process has child processes ( Orphan process ), You need to set the parent process pointer of these child processes to the kernel thread initproc, And each sub process pointer needs to be inserted To initproc In the linked list of child processes . If the execution state of a child process is PROC_ZOMBIE, You need to wake up initproc To complete the final recycling of this sub process .*/
proc = current->cptr;
current->cptr = proc->optr;
proc->yptr = NULL;
if ((proc->optr = initproc->cptr) != NULL) {
initproc->cptr->yptr = proc;
}
proc->parent = initproc;
initproc->cptr = proc;
if (proc->state == PROC_ZOMBIE) {
if (initproc->wait_state == WT_CHILD) {
wakeup_proc(initproc);
}
}
}
}
local_intr_restore(intr_flag);
schedule();// Select a new process to execute
panic("do_exit will not return!! %d.\n", current->pid);
}
syscall system call
The definition of system call is mainly in syscall.c in , Many system call functions are defined here , Include sys_exit、sys_fork、sys_wait、sys_exec etc. .syscall Is a way for kernel programs to provide kernel services for user programs .
In the interrupt handling routine , The program will , perform syscall function ( Pay attention to syscall Functions are kernel code , Not in the user library syscall function ). kernel syscall The function retrieves the values of the six registers one by one , And execute different system calls according to the system call number . The essence of those system calls is that of other kernel functions wrapper. The following is a syscall Function implementation code :
COPYvoid syscall(void) {
struct trapframe *tf = current->tf;
uint32_t arg[5];
int num = tf->tf_regs.reg_eax;
if (num >= 0 && num < NUM_SYSCALLS) {
if (syscalls[num] != NULL) {
arg[0] = tf->tf_regs.reg_edx;
arg[1] = tf->tf_regs.reg_ecx;
arg[2] = tf->tf_regs.reg_ebx;
arg[3] = tf->tf_regs.reg_edi;
arg[4] = tf->tf_regs.reg_esi;
tf->tf_regs.reg_eax = syscalls[num](arg);
return ;
}
}
print_trapframe(tf);
panic("undefined syscall %d, pid = %d, name = %s.\n",
num, current->pid, current->name);
}
After the corresponding kernel functions are completed , Reserved before the program passes trapframe Return to user status . A system call ends .
Question answering
- Please analyze fork/exec/wait/exit How the implementation affects the execution state of the process ?
- fork A new sub thread will be created , Change the status of the child thread from UNINIT The state becomes RUNNABLE state , Do not change the state of the parent process
- exec Complete the creation of user process , At the same time, it enables the user process to enter the execution , Do not change the process state
- wait Complete subprocess resource recycling , If there are finished subprocesses or no subprocesses , Then the call will end immediately , It does not affect the process state ; otherwise , The process needs to wait for the child process to end , Process from RUNNIG The state becomes SLEEPING state .
- exit Complete the recycling of resources , Process from RUNNIG The state becomes ZOMBIE state .
- Please give me ucore Execution state lifecycle diagram of a user state process in ( Package execution status , Execute the transformation relationship between states , And the event or function call that produces the transformation ).( Characters can be drawn )
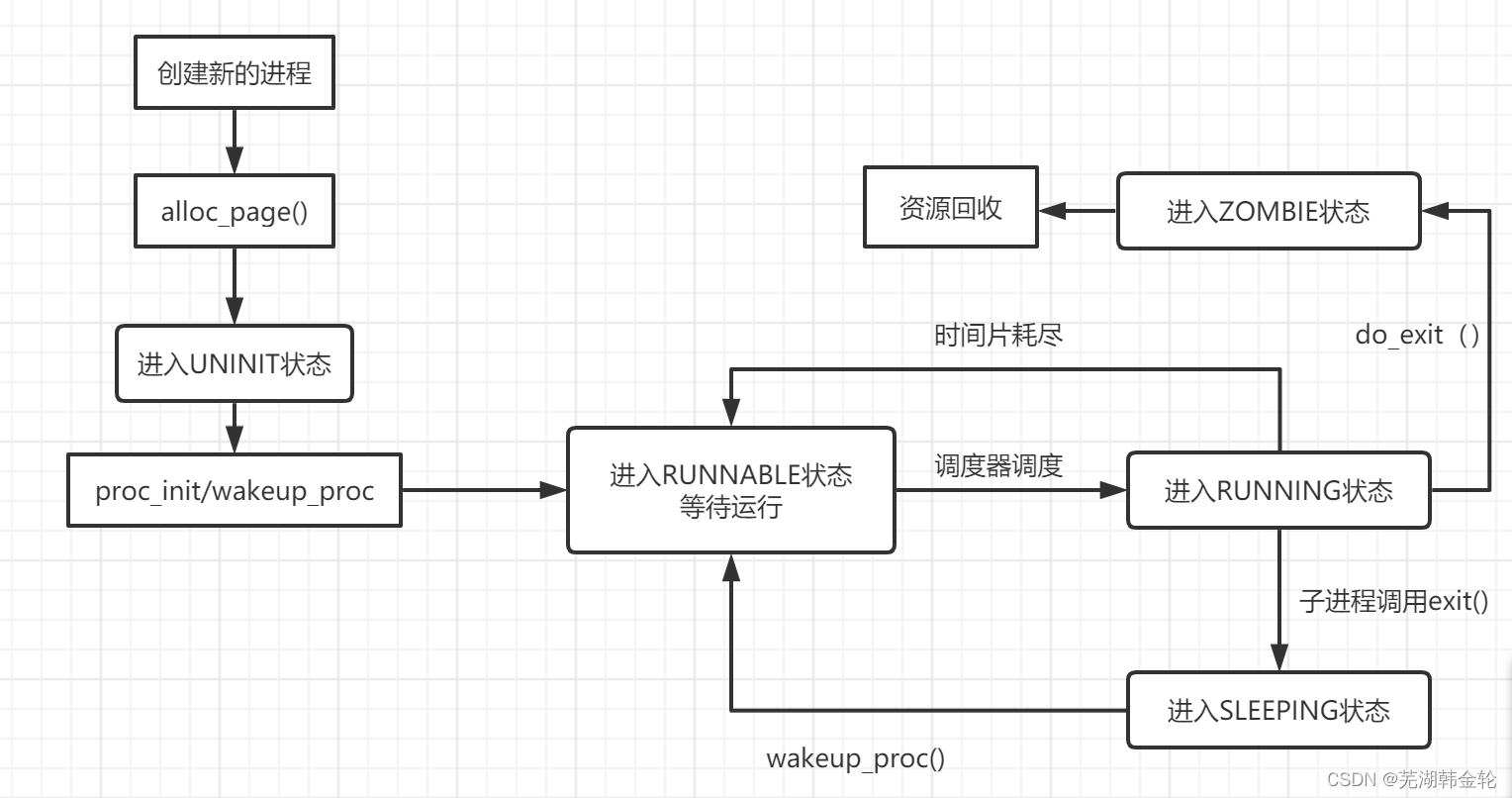
It should be noted that , from RUNNABLE To RUNNING when , The process is proc_run Function called as an argument , from RUNNING To RUNABLE when , It is the process that actively calls proc_run function
This completes the exercise , function make qemu View the run results :
function make grade Check your grades 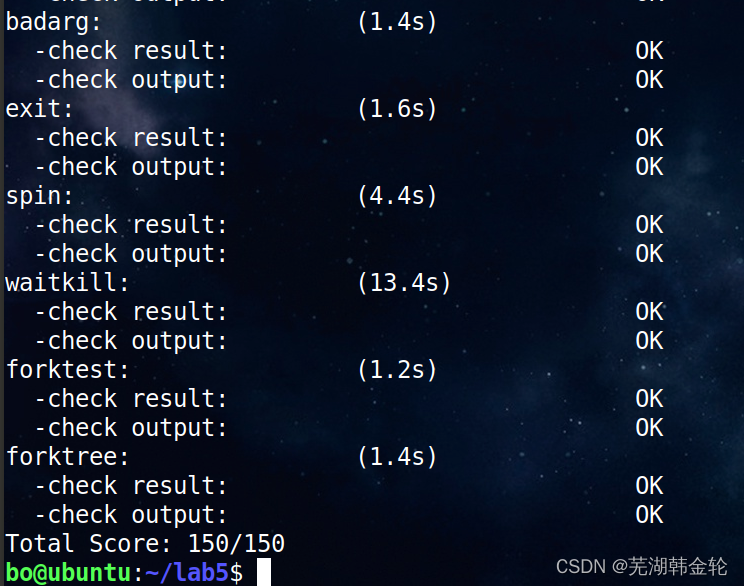
Extended exercises Challenge : Realization Copy on Write (COW) Mechanism
Give the implementation source code , Test cases and design reports ( Included in cow Various state transitions in case ( Similar to finite state automata ) Explanation ).
This extended exercise involves this experiment and the previous experiment “ Virtual memory management ”. stay ucore Operating system , When a user parent process creates its own child process , The parent process will set its requested user space to read-only , Child processes can share pages in the user memory space occupied by the parent process ( This is a shared resource ). When any one of these processes modifies a page in this user's memory space ,ucore Will pass page fault The exception learns the operation , And finish copying memory pages , So that both processes have their own memory pages . Changes made by such a process are not visible to another process . Please be there. ucore To achieve such COW Mechanism .
because COW The implementation is more complex , Easy to introduce bug, Please refer to https://dirtycow.ninja/ See if you can ucore Of COW Simulate this error and solution in the implementation . Need an explanation .
This is a big challenge.
First ,Copy on Write When copying an object, it is not really copying the original object to another location in memory , Instead, set a in the memory mapping table of the new object The pointer , Point to the location of the source object , And put that piece of memory Copy-On-Write Bit is set to 1. Generally speaking, the benefits of doing this : If the copied object is only for the content " read " operation , It doesn't really need to be copied , This pointer to the source object can complete the task , This saves replication time and memory . But the problem is , If the copied object needs to write the content , A single pointer may not meet the requirements , Because such changes to the content will affect the correct execution of other processes , So we need to copy this area , Of course, you don't need to copy all , It only needs Copy some areas that need to be modified , This greatly saves memory and improves efficiency .
Because if you set the original content to read only , When writing this paragraph, it will cause Page Fault, At this time, we know that this paragraph needs to be written , stay Page Fault You can handle it accordingly . That is to say, using Page Fault To realize the judgment of authority , Or it's a sign of true replication .
Based on the principle and previous user process creation 、 Copy 、 Operation and other mechanisms , design idea :
- Set a marker bit , Used to mark whether a piece of memory is shared , actually
dup_mmapThere is a pair of... In the function share Set up , So first we need to share Set to 1, Can be said share . - stay
pmm.cIn Chinese, it meanscopy_rangeAdd processing for shared pages , If share by 1, Then map the page of the child process to the page of the parent process . Because after two processes share a page , No matter any process modifies the page , Will affect another page , Therefore, both the child process and the parent process need to maintain the shared page read-only . - When the program tries to modify a read-only memory page , Will trigger
Page Faultinterrupt , At this time, we can detect that the interruption is caused by access beyond permission , It indicates that the process accesses the shared page and needs to be modified , Therefore, the kernel needs to reallocate pages for the process at this time 、 Copy page content 、 Establish a mapping relationship
Based on this idea , Modify the code
First , take vmm.c Medium dup_mmap Function squadron share Modify the setting of variables , because dup_mmap The function is called copy_range function ,copy_range The function has an argument of share, So modify share by 1 It marks the start of the sharing mechanism .
int dup_mmap(struct mm_struct *to, struct mm_struct *from) {
...
bool share = 1;
if (copy_range(to->pgdir, from->pgdir, vma->vm_start, vma->vm_end, share)!= 0) {
return -E_NO_MEM;
}
...
}
after , stay pmm.c In Chinese, it means copy_range Add processing for shared pages , If share by 1, Then map the page of the child process to the page of the parent process . Because after two processes share a page , No matter any process modifies the page , Will affect another page , Therefore, both the child process and the parent process need to maintain the shared page read-only .
// Make changes here , Make the child process share a page with the parent process , But keep both read-only
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
assert(start % PGSIZE == 0 && end % PGSIZE == 0);
assert(USER_ACCESS(start, end));
do {
//call get_pte to find process A's pte according to the addr start
pte_t *ptep = get_pte(from, start, 0), *nptep;
if (ptep == NULL) {
start = ROUNDDOWN(start + PTSIZE, PTSIZE);
continue ;
}
if (*ptep & PTE_P) {
if ((nptep = get_pte(to, start, 1)) == NULL) {
return -E_NO_MEM;
}
uint32_t perm = (*ptep & PTE_USER);
//get page from ptep
struct Page *page = pte2page(*ptep);
assert(page!=NULL);
//----------------- Modification part ---------------------
int ret=0;
// Due to the previous setting of sharable , Therefore, we will continue to implement if sentence
if (share) {
// If share=1, Complete page sharing
page_insert(from, page, start, perm & (~PTE_W));
ret = page_insert(to, page, start, perm & (~PTE_W));
} else {
// If you don't share Just allocate the page normally , Consistent with the previous implementation
struct Page *npage=alloc_page();
assert(npage!=NULL);
uintptr_t src_kvaddr = page2kva(page);
uintptr_t dst_kvaddr = page2kva(npage);
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
ret = page_insert(to, npage, start, perm);
}
assert(ret == 0);
}
//----------------- Modification part ---------------------
start += PGSIZE;
} while (start != 0 && start < end);
return 0;
}
Finish here , The sharing of reading has been realized , But there is no treatment for writing , Therefore, we need to deal with page errors caused by writing pages that can only be read : When the program tries to modify a read-only memory page , Will trigger Page Fault interrupt , At this time, we can detect that the interruption is caused by access beyond permission , It indicates that the process accesses the shared page and needs to be modified , Therefore, the kernel needs to reallocate pages for the process at this time 、 Copy page content 、 Establish a mapping relationship .
These steps are mainly do_pgfault in , We can detect the error and deal with it accordingly .
int do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr)
{
.....
if (*ptep == 0)
{
// If the physical page does not exist , Allocate physical pages and establish relevant mapping relationships
if (pgdir_alloc_page(mm->pgdir, addr, perm) == NULL)
{
cprintf("pgdir_alloc_page in do_pgfault failed\n");
goto failed;
}
}
// adopt error_code & 3==3 Judge to be COW The resulting error
else if (error_code & 3 == 3)
{
// Therefore, we need to complete the allocation of physical pages , And realize the replication of code and data
// actually , We will copy_range The process is executed here , Execute the process only when it must be executed
struct Page *page = pte2page(*ptep);
struct Page *npage = pgdir_alloc_page(mm->pgdir, addr, perm);
uintptr_t src_kvaddr = page2kva(page);
uintptr_t dst_kvaddr = page2kva(npage);
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
}
else
{
...
}
...
}
function make qemu View the run results 
Here is another COW Realization
Summary of the experiment
This experiment mainly involves some knowledge of processes , Such as creating , management , The specific implementation of switching to user mode process ; load ELF Specific implementation of executable file ; The specific implementation of the system call mechanism . And learned that through system calls sys_fork/sys_exec/sys_exit/sys_wait To support running different applications , Complete the basic management of the execution process of the user process . In the study , There is also something you don't understand . Not very understanding of virtual memory space , I don't understand the code tf->tf_cs = USER_CS; And other related parameters , And the relevant knowledge of interruption is not in place . In the future, we will increase our understanding of interruption , Review what you didn't understand in the experiment .
The teacher of the theory class said that process management is a very important knowledge point of the operating system , The five states of the process are also mentioned in particular , This is also reflected in the experiment . Several exercises also basically have notes , It's not very complicated , But the workload is not small ( This should be the longest experimental report I have ever written ).challenge Realized COW, stay Linux It is also reflected on the website, so there are many relevant materials , It was very detailed , Yes challenge The implementation of is very helpful , and challenge There are also notes .
Finish this experiment , Have a deeper understanding of process management , At the same time, I have a further understanding of the knowledge learned in the theory class , It can also check omissions and fill vacancies , Find the knowledge points you have forgotten or failed to learn well .
边栏推荐
- Opencv recognition of face in image
- Emqtt distribution cluster and node bridge construction
- MySQL数据库(五)视 图 、 存 储 过 程 和 触 发 器
- Pedestrian re identification (Reid) - data set description market-1501
- STC-B学习板蜂鸣器播放音乐
- Global and Chinese market of pinhole glossmeter 2022-2028: Research Report on technology, participants, trends, market size and share
- Daily code 300 lines learning notes day 9
- 软件测试工作太忙没时间学习怎么办?
- Global and Chinese markets of PIM analyzers 2022-2028: Research Report on technology, participants, trends, market size and share
- UCORE lab7 synchronous mutual exclusion experiment report
猜你喜欢

软件测试有哪些常用的SQL语句?
MySQL数据库(四)事务和函数
The salary of testers is polarized. How to become an automated test with a monthly salary of 20K?
Eigen User Guide (Introduction)
Fundamentals of digital circuits (II) logic algebra
Opencv recognition of face in image
Example 071 simulates a vending machine, designs a program of the vending machine, runs the program, prompts the user, enters the options to be selected, and prompts the selected content after the use
Sleep quality today 81 points
Interview answering skills for software testing

Heap, stack, queue

随机推荐
CSAPP家庭作业答案7 8 9章
Description of Vos storage space, bandwidth occupation and PPS requirements
Opencv recognition of face in image
[Ogg III] daily operation and maintenance: clean up archive logs, register Ogg process services, and regularly back up databases
Build your own application based on Google's open source tensorflow object detection API video object recognition system (II)
Servlet
想跳槽?面试软件测试需要掌握的7个技能你知道吗
pytest
Vysor uses WiFi wireless connection for screen projection_ Operate the mobile phone on the computer_ Wireless debugging -- uniapp native development 008
A method and implementation of using VSTO to prohibit excel cell editing
MySQL development - advanced query - take a good look at how it suits you
Cadence physical library lef file syntax learning [continuous update]
Mysql database (II) DML data operation statements and basic DQL statements
Build your own application based on Google's open source tensorflow object detection API video object recognition system (I)
线程及线程池
The salary of testers is polarized. How to become an automated test with a monthly salary of 20K?
[pytorch] simple use of interpolate
基于485总线的评分系统双机实验报告
Example 071 simulates a vending machine, designs a program of the vending machine, runs the program, prompts the user, enters the options to be selected, and prompts the selected content after the use
Capitalize the title of leetcode simple question