当前位置:网站首页>ucore lab6 调度器 实验报告
ucore lab6 调度器 实验报告
2022-07-06 09:24:00 【芜湖韩金轮】
实验目的
- 理解操作系统的调度管理机制
- 熟悉 ucore 的系统调度器框架,以及缺省的Round-Robin 调度算法
- 基于调度器框架实现一个(Stride Scheduling)调度算法来替换缺省的调度算法
实验内容
实验五完成了用户进程的管理,可在用户态运行多个进程。但到目前为止,采用的调度策略是很简单的FIFO调度策略。本次实验,主要是熟悉ucore的系统调度器框架,以及基于此框架的Round-Robin(RR) 调度算法。然后参考RR调度算法的实现,完成Stride Scheduling调度算法。
练习
练习0:填写已有实验
本实验依赖实验1/2/3/4/5。请把你做的实验2/3/4/5的代码填入本实验中代码中有“LAB1”/“LAB2”/“LAB3”/“LAB4”“LAB5”的注释相应部分。并确保编译通过。注意:为了能够正确执行lab6的测试应用程序,可能需对已完成的实验1/2/3/4/5的代码进行进一步改进。
使用meld比较软件,发现以下文件需要更改:
- proc.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- trap.c
需要修改部分如下:trap.c中的trap_dispatch 函数:在时钟产生的地方需要对定时器做初始化,用于调度算法
static void trap_dispatch(struct trapframe *tf)
{
.....
case IRQ_OFFSET + IRQ_TIMER:
ticks ++;
assert(current != NULL);
run_timer_list(); //调用该函数更新定时器,并根据参数调用调度算法
break;
.....
}
run_timer_list函数被定义在sched.c中
proc.c中的proc_struct结构体:增加了一些用户调度算法的成员变量
static struct proc_struct * alloc_proc(void) {
......
// Lab6 新增code
proc->rq = NULL; //初始化运行队列为空
list_init(&(proc->run_link)); //初始化运行队列的指针
proc->time_slice = 0; //初始化时间片
proc->lab6_run_pool.left = proc->lab6_run_pool.right = proc->lab6_run_pool.parent = NULL;//初始化各类指针为空,包括父进程等待
proc->lab6_stride = 0; //进程运行进度初始化(针对于stride调度算法,下同)
proc->lab6_priority = 1; //初始化优先级
}
return proc;
}
相关的解释和定义可以在proc.h找到:
struct run_queue *rq; // 当前的进程在队列中的指针
list_entry_t run_link; // 运行队列的指针
int time_slice; // 时间片
skew_heap_entry_t lab6_run_pool; // FOR LAB6 ONLY: the entry in the run pool
uint32_t lab6_stride; // 代表现在执行到了什么地方
uint32_t lab6_priority; //进程优先级
其余文件直接复制到lab6即可
练习1: 使用 Round Robin 调度算法(不需要编码)
完成练习0后,建议大家比较一下(可用kdiff3等文件比较软件)个人完成的lab5和练习0完成后的刚修改的lab6之间的区别,分析了解lab6采用RR调度算法后的执行过程。执行make grade,大部分测试用例应该通过。但执行priority.c应该过不去。
请在实验报告中完成:
- 请理解并分析sched_class中各个函数指针的用法,并结合Round Robin 调度算法描ucore的调度执行过程
- 请在实验报告中简要说明如何设计实现”多级反馈队列调度算法“,给出概要设计,鼓励给出详细设计
RR调度算法执行过程
首先分析一下ucore是如何实现RR算法的:
Round Robin调度算法:让所有 runnable 态的进程分时轮流使用 CPU 时间。调度器维护当前 runnable进程的有序运行队列。当前进程的时间片用完之后,调度器将当前进程放置到运行队列的尾部,再从其头部取出进程进行调度。
首先,本实验中的调度都是基于调度类的成员函数实现的,相关定义在sched.h,sched_class定义了几个成员函数,等一下问题1也会分析:
struct sched_class {
//调度器的名字
const char *name;
//初始化运行队列
void (*init)(struct run_queue *rq);
// 将进程p插入到运行队列q中
void (*enqueue)(struct run_queue *rq, struct proc_struct *proc);
// 将进程p从运行队列q中删除
void (*dequeue)(struct run_queue *rq, struct proc_struct *proc);
// 返回运行队列中下一个可执行的过程
struct proc_struct *(*pick_next)(struct run_queue *rq);
// timetick的处理函数
void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);
};
在实验六中,实现一个调度算法,必须具有这五个函数,才能满足调度类。
练习1主要分析RR调度算法的执行过程。
RR算法的主要实现在default_sched.c中定义
具体执行过程如下:
(1)第一步:初始化rq的进程队列,并将其进程数量置零,具体在RR_init函数实现:
static void RR_init(struct run_queue *rq) {
list_init(&(rq->run_list)); //初始化运行队列
rq->proc_num = 0;
}
其中,struct run_queue的定义如下
struct run_queue {
list_entry_t run_list; //进程队列
unsigned int proc_num; //进程数量
int max_time_slice; //最大时间片长度(RR)
skew_heap_entry_t *lab6_run_pool;
//在stride调度算法中,为了“斜堆”数据结构创建的一种特殊进程队列,本质就是进程队列。
};
(2)第二步:进程入队的操作:进程队列是一个双向链表,一个进程加入队列的时候,会将其加入到队列的第一位,并给它初始数量的时间片;并更新队列的进程数量,具体在RR_enqueue函数实现:
static void
RR_enqueue(struct run_queue *rq, struct proc_struct *proc)
{
//进程运行队列不能为空
assert(list_empty(&(proc->run_link)));
//把进程控制块指针放到rq队列末尾
list_add_before(&(rq->run_list), &(proc->run_link));
//如果进程时间片用完,将其重置为max_time_slice
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {
proc->time_slice = rq->max_time_slice;
}
proc->rq = rq;
rq->proc_num ++;
}
(3)第三步:从就绪队列中取出这个进程,并将其调用list_del_init删除。同时,进程数量减一,具体在RR_dequeue函数实现:
static void
RR_dequeue(struct run_queue *rq, struct proc_struct *proc) {
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);
list_del_init(&(proc->run_link)); //将proc删除
rq->proc_num --;
}
(4)第四步:通过list_next函数的调用,会从队尾选择一个进程,代表当前应该去执行的那个进程。如果选不出来有处在就绪状态的进程,那么返回NULL,并将执行权交给内核线程idle,idle的功能是不断调用schedule,直到整个系统出现下一个可以执行的进程,具体在RR_pick_next函数实现:
static struct proc_struct *
RR_pick_next(struct run_queue *rq) {
list_entry_t *le = list_next(&(rq->run_list));
if (le != &(rq->run_list))
{
return le2proc(le, run_link);
}
return NULL;
}
(5)第五步:每一次时间片到时的时候,当前执行进程的时间片time_slice便减一。如果time_slice降到零,则设置此进程成员变量need_resched标识为1,这样在下一次中断来后执行trap函数时,会由于当前进程程成员变量need_resched标识为1而执行schedule函数,从而把当前执行进程放回就绪队列末尾,而从就绪队列头取出在就绪队列上等待时间最久的那个就绪进程执行,具体在RR_proc_tick函数实现:
static void
RR_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
if (proc->time_slice > 0) {
proc->time_slice --;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
(6)第6步:在schedule初始化的时候,需要填写一个初始化信息,那么这里就填上我们所实现的类函数,那么系统就可以按照这个方式去执行了:
struct sched_class default_sched_class = {
.name = "RR_scheduler",
.init = RR_init,
.enqueue = RR_enqueue,
.dequeue = RR_dequeue,
.pick_next = RR_pick_next,
.proc_tick = RR_proc_tick,
};
RR调度算法执行过程如上
回答问题
- 请理解并分析sched_class中各个函数指针的用法,并结合Round Robin 调度算法描ucore的调度执行过程
sched_class中各个函数指针的用法上面已经详细分析过,现在简单回顾一下:
struct sched_class {
const char *name;//调度类名
void (*init)(struct run_queue *rq);//调度队列初始化
void (*enqueue)(struct run_queue *rq, struct proc_struct *proc);//入队
void (*dequeue)(struct run_queue *rq, struct proc_struct *proc);//出队
struct proc_struct *(*pick_next)(struct run_queue *rq);//切换
void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);//触发
};
下面结合Round Robin调度算法来分析ucore系统的进程调度执行过程。
- ucore调用
sched_init函数用于初始化相关的就绪队列。 - 在
proc_init函数中,建立第一个内核进程,并将其添加至就绪队列中 - 当所有的初始化完成后,ucore执行
cpu_idle函数,并在其内部的schedule函数中,调用sched_class_enqueue将当前进程添加进就绪队列中(因为当前进程要被切换出CPU了)
然后,调用sched_class_pick_next获取就绪队列中可被轮换至CPU的进程。如果存在可用的进程,则调用sched_class_dequeue函数,将该进程移出就绪队列,并在之后执行proc_run函数进行进程上下文切换。 - 需要注意的是,每次时间中断都会调用函数
sched_class_proc_tick。该函数会减少当前运行进程的剩余时间片。如果时间片减小为0,则设置need_resched为1,并在时间中断例程完成后,在trap函数的剩余代码中进行进程切换。
下面回答第二个问题:
- 请在实验报告中简要说明如何设计实现”多级反馈队列调度算法“,给出概要设计,鼓励给出详细设计
多级反馈调度是一种采用多种调度队列的调度方式,它与多级队列调度最大的区别在于进程可以在不同的调度队列间移动,也就是说可以制定一些策略用以决定进程是否可以升级到优先级更高的队列或者降级到优先级更低的队列。通过该算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。通常实现时设计的多级反馈队列核心思想是:时间片大小随优先级级别增加而增加。同时,进程在当前时间片没有完成 则降到下一优先级。实现时可以维护多个队列,每个新的进程加入第一个队列,当需要选择一个进程调入执行时,从第一个队列开始向后查找,遇到某个队列非空,那么从这个队列中取出一个进程调入执行。如果从某个队列调入的进程在时间片用完之后仍然没有结束,则将这个进程加入其调入时所在队列之后的一个队列,并且时间片加倍。
下面根据书上MLFQ的五条规则和上面的RR调度算法来简单实现MLFQ算法
- 假设进程一共有3个调度优先级,分别为0、1、2,其中0位最高优先级,2位最低优先级。为了支持3个不同的优先级,在运行队列中开3个队列,分别命名为
rq -> run_list[0..3]。除此之外,在proc_struct中加入priority成员表示该进程现在所处的优先级,初始化为0,即直接加入最高优先级。 - 进程队列初始化,和RR算法实现一样,不同之处在于需要初始化3个队列,分别对应0、1、2,只需稍微修改
RR_init函数即可。 - 判断proc进程的时间片proc -> time_slice是否为0,如果为0,则proc -> priority += 1,说明该进程应当降级,否则不变。根据proc加入到对应优先级的列表中去。时间片的长度也和优先级有关,低优先级的时间片长度设置为高优先级的两倍,具体在
enqueue函数实现。 - 将proc进程从相应的优先级运行队列中删除,和RR算法差不多,在
dequeue函数实现。 - 通过算法选出下一个要执行的进程。在这里为了避免出现低优先级进程饥饿现象,可以设置为高优先级每处理100个单位时间后,低优先级处理30个单位时间 类似的思想。用这个方法来避免低优先级进程饥饿现象,具体在
pick_next函数实现。 - 每次时钟中断,减少当前进程的时间片。若为0,则将进程标记为需要调度,和RR算法类似,具体在
proc_tick函数实现。
练习2: 实现 Stride Scheduling 调度算法(需要编码)
首先需要换掉RR调度器的实现,即用default_sched_stride_c覆盖default_sched.c。然后根据此文件和后续文档对Stride度器的相关描述,完成Stride调度算法的实现。
后面的实验文档部分给出了Stride调度算法的大体描述。这里给出Stride调度算法的一些相关的资料(目前网上中文的资料比较欠缺)。
- strid-shed paper location1
- strid-shed paper location2
- 也可GOOGLE “Stride Scheduling” 来查找相关资料
执行:make grade。如果所显示的应用程序检测都输出ok,则基本正确。如果只是priority.c过不去,可执行 make run-priority 命令来单独调试它。大致执行结果可看附录。( 使用的是 qemu-1.0.1 )。
请在实验报告中简要说明你的设计实现过程。
Stride调度算法的相关介绍
ucore的Round-Robin算法可以保证每个进程得到的CPU资源是相等的,但我们希望调度器能够更加智能的为每个进程分配合理的CPU资源,让每个进程得到的时间资源与它们的优先级成正比关系。而Stride Scheduling调度算法就是这样的一种典型而简单的算法。
该算法的有如下几个特点:
- 可控性:可以证明Stride Scheduling对进程的调度次数正比于其优先级
- 确定性:在不考虑计时器事件的情况下,整个调度机制都是可预知和重现的。
该算法较为重要的两个变量:
- stride:步幅,表示该进程当前的调度权。每次需要调度时优先选择stride值最小的进程进行调度。每次调度后stride加上pass。
- pass:表示每次前进的步数。该值仅与优先级相关。可以令
P.pass =BigStride /P.priority,因此pass与优先级成反比。为每个进程分配的时间将与其优先级成正比,因为pass越小通常被调度次数就会越多。
该算法的基本思想为:
- 每个runnable的进程设置一个当前状态stride,表示该进程当前的调度权。另外定义其对应的pass值,表示对应进程在调度后,stride需要进行的累加值。
- 每次需要调度时,从当前 runnable 态的进程中选择 stride最小的进程调度。
- 对于获得调度的进程P,将对应的stride加上其对应的步长pass(只与进程的优先权有关系)。
- 在一段固定的时间之后,回到 2.步骤,重新调度当前stride最小的进程。
Stride算法的实现
(1)第一步:比较
通过comp函数,实现比较当前stride最小的进程,从而去调度它,具体实现如下:
static int
proc_stride_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, lab6_run_pool);
struct proc_struct *q = le2proc(b, lab6_run_pool);
int32_t c = p->lab6_stride - q->lab6_stride;//步数相减,通过正负比较大小关系
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
后面步骤同RR算法一样,实现五个函数
(2)第二步:初始化
这里的处理和之前的RR无区别。
唯一的不同在于,初始化进程队列的时候是对于lab6_run_pool(实验六进程池)进行操作,因为使用了斜堆的数据结构,代码中,为这个变量已经建立好了相应的结构,因此需要这样做。如果还是初始化rq,那么由于rq是基于双向链表实现的,会出现一些错误,具体实现如下:
static void
stride_init(struct run_queue *rq) {
/* LAB6: YOUR CODE */
list_init(&(rq->run_list));//初始化调度器类的信息
rq->lab6_run_pool = NULL;//初始化当前的运行队列为一个空的容器结构。
rq->proc_num = 0;//设置rq->proc_num为 0
}
(3)第三步:入队
初始化刚进入运行队列的进程 proc 的stride属性,然后比较队头元素与当前进程的步数大小,选择步数最小的运行,即将其插入放入运行队列中去,这里并未放置在队列头部。最后初始化时间片,然后将运行队列进程数目加一。
static void
stride_enqueue(struct run_queue *rq, struct proc_struct *proc) {
//将proc对应的堆插入到rq中
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);
//更新一下proc的时间片
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice)
proc->time_slice = rq->max_time_slice;
//将proc的rq指向总的rq,rq中的进程数+1
proc->rq = rq;
rq->proc_num++;
}
(4)第四步:出队
将进程从运行队列移走时,需要将进程从斜堆中删除,并将运行队列的进程计数减一。
static void
stride_dequeue(struct run_queue *rq, struct proc_struct *proc) {
//将proc从堆中删除
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);
//将rq的进程数减1
rq->proc_num--;
}
(5)第五步:选择进程调度
选择下一个要调度的进程,只需要选择stride值最小的进程即可,因此将堆顶进程取出,并将堆恢复即可。
static struct proc_struct *
stride_pick_next(struct run_queue *rq)
{
if (rq->lab6_run_pool == NULL)
{
return NULL;
}
//得到堆顶元素,并将其堆恢复
struct proc_struct *p = le2proc(rq->lab6_run_pool, lab6_run_pool);
//将p对应的进程的stride加上pass值
p->lab6_stride += BIG_STRIDE / p->lab6_priority;
return p;
}
(6)第六步:时间片部分
函数用于处理时钟,和RR算法类似,如果time slice大于0,则将值减一。否则认为其时间片用完,需要调度。
static void
stride_proc_tick(struct run_queue *rq, struct proc_struct *proc)
{
if (proc->time_slice == 0)
{
proc->need_resched = 1;
}
else
{
--proc->time_slice;
}
}
完成函数后,将原来的default_sched_class注释。用stride算法的调度类:
struct sched_class default_sched_class = {
.name = "stride_scheduler",
.init = stride_init,
.enqueue = stride_enqueue,
.dequeue = stride_dequeue,
.pick_next = stride_pick_next,
.proc_tick = stride_proc_tick,
};
运行make qemu 查看运行结果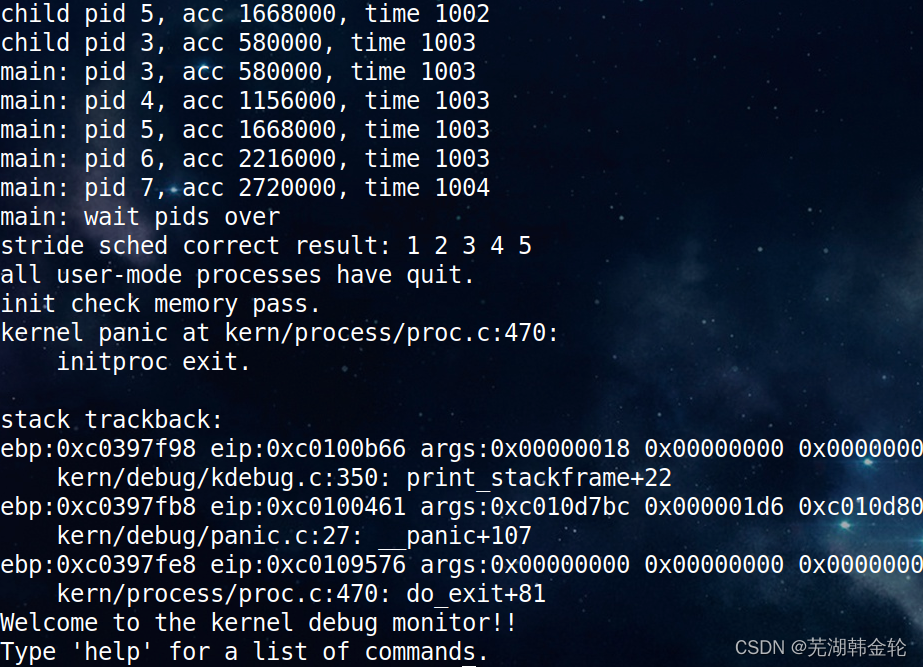
运行命令make grade查看成绩: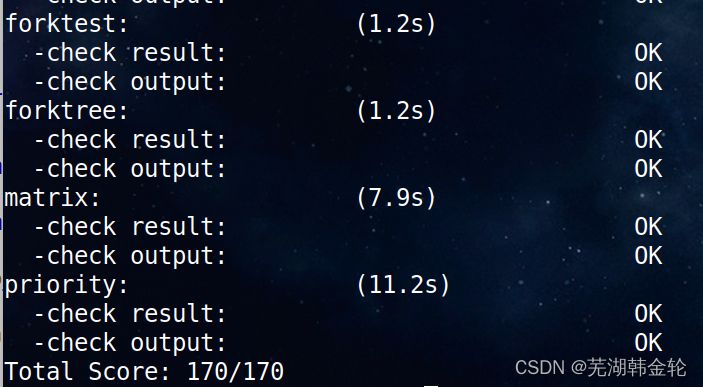
扩展练习 Challenge 1 :实现 Linux 的 CFS 调度算法
在ucore的调度器框架下实现下Linux的CFS调度算法。可阅读相关Linux内核书籍或查询网上资料,可了解CFS的细节,然后大致实现在ucore中。
下面开始实验:
CFS算法是想要让每个进程的运行时间尽可能相同,那么记录每个进程已经运行的时间即可。在进程控制块结构中增加一个属性表示运行时间。每次需要调度的时候,选择已经运行时间最少的进程调入CPU执行。CFS算法的实现时普遍采用了红黑树,但由于红黑树实现起来过于复杂且堆已经实现并且可以满足要求,故在此将采用堆来实现。
在run_queue中增添一个堆,练习2中已经用了 skew_heap_entry_t * lab6_run_pool;在此继续使用。
struct run_queue {
list_entry_t run_list;
unsigned int proc_num;
int max_time_slice;
// For LAB6 ONLY
skew_heap_entry_t *lab6_run_pool;
}
在proc_struct中增添了几个辅助完成该算法的变量:
struct proc_struct {
....
//---------------用于CFS算法--------------------------------------------------
int fair_run_time; //虚拟运行时间
int fair_priority; //优先级系数:从1开始,数值越大,时间过得越快
skew_heap_entry_t fair_run_pool; // 运行进程池
}
将proc初始化时将增添的三个变量一并初始化:
skew_heap_init(&(proc->fair_run_pool));
proc->fair_run_time = 0;
proc->fair_priority = 1;
具体实现算法:
比较函数:proc_fair_comp_f,实际上该函数和练习2的stride算法中的comp函数思想一致。
//类似于stride算法,这里需要比较的是两个进程的fair_run_time
static int proc_fair_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, fair_run_pool);
struct proc_struct *q = le2proc(b, fair_run_pool);
int c = p->fair_run_time - q->fair_run_time;
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
初始化:
//init函数
static void fair_init(struct run_queue *rq) {
//进程池清空,进程数为0
rq->lab6_run_pool = NULL;
rq->proc_num = 0;
}
加入队列:
//类似于stride调度
static void fair_enqueue(struct run_queue *rq, struct proc_struct *proc)
{
//将proc对应的堆插入到rq中
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &(proc->fair_run_pool), proc_fair_comp_f);
//更新一下proc的时间片
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice)
proc->time_slice = rq->max_time_slice;
proc->rq = rq;
rq->proc_num ++;
}
移出队列:
static void fair_dequeue(struct run_queue *rq, struct proc_struct *proc) {
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &(proc->fair_run_pool), proc_fair_comp_f);
rq->proc_num --;
}
选取下一个进程:
//pick_next,选择堆顶元素即可
static struct proc_struct * fair_pick_next(struct run_queue *rq) {
if (rq->lab6_run_pool == NULL)
return NULL;
skew_heap_entry_t *le = rq->lab6_run_pool;
struct proc_struct * p = le2proc(le, fair_run_pool);
return p;
}
需要更新虚拟运行时,增加的量为优先级系数
//每次更新时,将虚拟运行时间更新为优先级相关的系数
static void
fair_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
if (proc->time_slice > 0) {
proc->time_slice --;
proc->fair_run_time += proc->fair_priority;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
运行结果如下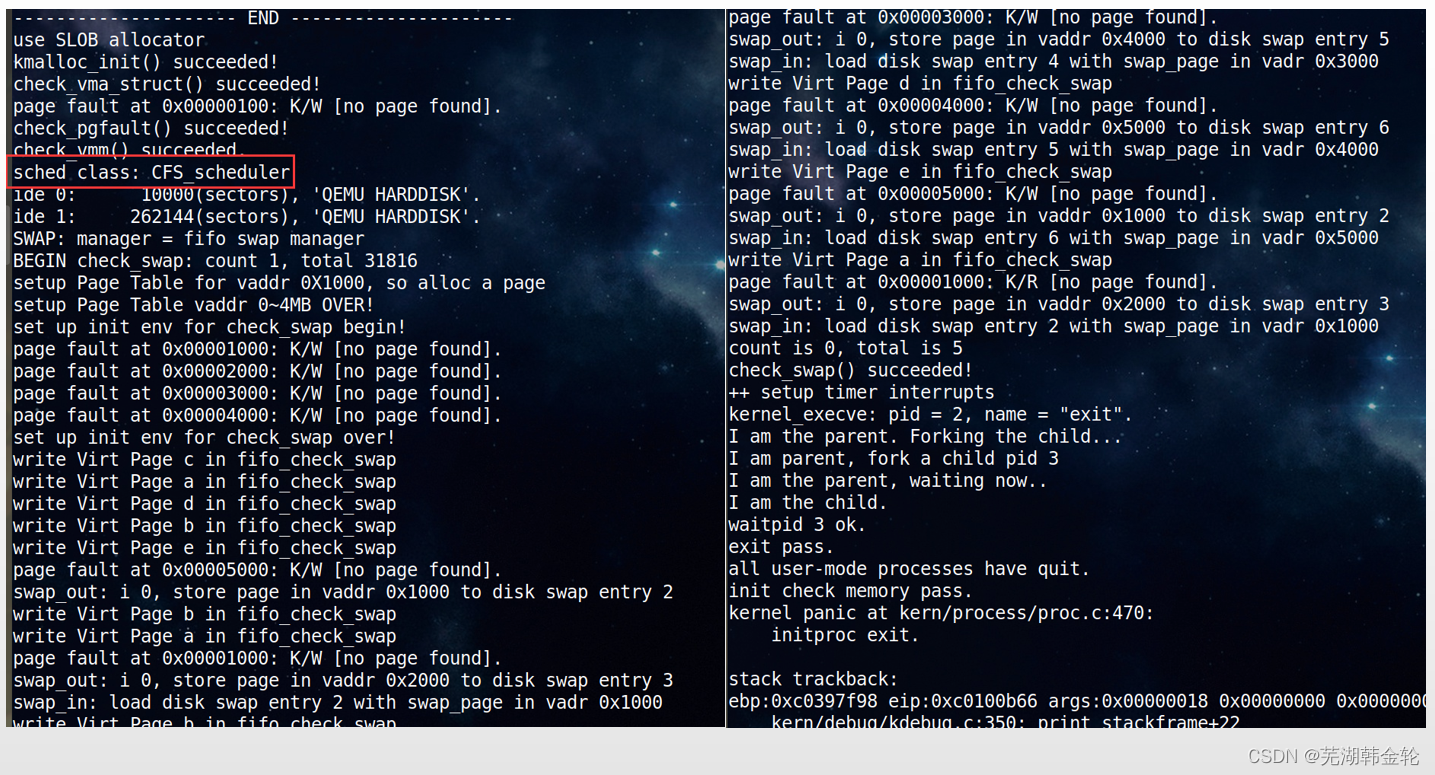
扩展练习 Challenge 2 :在ucore上实现尽可能多的各种基本调度算法(FIFO, SJF,…),并设计各种测试用例,能够定量地分析出各种调度算法在各种指标上的差异,说明调度算法的适用范围。
实验总结
通过本次实验对RR调度和Stride调度有了更深入的学习与理解,通过验收以及助教老师的提问对这部分内容掌握的更加牢固,这两个调度算法的实现都基于调度类五元组:初始化、入队、出队、选择下一个、中断处理。区别就在于Stride基于比较步长和进程执行进度的思想,要求频繁比较Stride值,因此选用了适应斜堆的函数,就代码而言,差别不大。相信本次实验的内容与收获会对今后的学习起到很好的帮助。
边栏推荐
- Global and Chinese markets for complex programmable logic devices 2022-2028: Research Report on technology, participants, trends, market size and share
- “Hello IC World”
- Flash implements forced login
- 线程的实现方式总结
- c语言学习总结(上)(更新中)
- 数据库多表链接的查询方式
- Detailed introduction to dynamic programming (with examples)
- Practical cases, hand-in-hand teaching you to build e-commerce user portraits | with code
- 指针:最大值、最小值和平均值
- 数字电路基础(三)编码器和译码器
猜你喜欢

Install and run tensorflow object detection API video object recognition system of Google open source
CSAPP homework answers chapter 789
1.支付系统
王爽汇编语言学习详细笔记一:基础知识

移植蜂鸟E203内核至达芬奇pro35T【集创芯来RISC-V杯】(一)
数字电路基础(二)逻辑代数

C language do while loop classic Level 2 questions

数字电路基础(三)编码器和译码器

Investment operation steps
基于485总线的评分系统双机实验报告
随机推荐
Global and Chinese markets for GaN on diamond semiconductor substrates 2022-2028: Research Report on technology, participants, trends, market size and share
关于交换a和b的值的四种方法
Database monitoring SQL execution
The salary of testers is polarized. How to become an automated test with a monthly salary of 20K?
Pointer -- eliminate all numbers in the string
[pointer] octal to decimal
Numpy Quick Start Guide
移植蜂鸟E203内核至达芬奇pro35T【集创芯来RISC-V杯】(一)
[HCIA continuous update] advanced features of routing
Function: string storage in reverse order
王爽汇编语言详细学习笔记二:寄存器
Want to learn how to get started and learn software testing? I'll give you a good chat today
What are the business processes and differences of the three basic business modes of Vos: direct dial, callback and semi direct dial?
How to learn automated testing in 2022? This article tells you
Emqtt distribution cluster and node bridge construction
5 minutes to master machine learning iris logical regression classification
“Hello IC World”
ucore lab7 同步互斥 实验报告
Global and Chinese markets of cobalt 2022-2028: Research Report on technology, participants, trends, market size and share
Numpy快速上手指南