当前位置:网站首页>ucore lab8 文件系统 实验报告
ucore lab8 文件系统 实验报告
2022-07-06 09:24:00 【芜湖韩金轮】
实验目的
- 了解基本的文件系统系统调用的实现方法;
- 了解一个基于索引节点组织方式的Simple FS文件系统的设计与实现;
- 了解文件系统抽象层-VFS的设计与实现;
实验内容
实验七完成了在内核中的同步互斥实验。本次实验涉及的是文件系统,通过分析了解ucore文件系统的总体架构设计,完善读写文件操作,从新实现基于文件系统的执行程序机制(即改写do_execve),从而可以完成执行存储在磁盘上的文件和实现文件读写等功能。
练习
练习0:填写已有实验
本实验依赖实验1/2/3/4/5/6/7。请把你做的实验1/2/3/4/5/6/7的代码填入本实验中代码中有“LAB1”/“LAB2”/“LAB3”/“LAB4”/“LAB5”/“LAB6” /“LAB7”的注释相应部分。并确保编译通过。注意:为了能够正确执行lab8的测试应用程序,可能需对已完成的实验1/2/3/4/5/6/7的代码进行进一步改进。
使用meld软件将lab7和lab8文件夹进行比较,发现以下文件需要复制:
- proc.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- trap.c
- sche.c
- monitor.c
- check_sync.c
- kdebug.c
其余文件不用修改,直接使用即可
练习1: 完成读文件操作的实现(需要编码)
首先了解打开文件的处理流程,然后参考本实验后续的文件读写操作的过程分析,编写在sfs_inode.c中sfs_io_nolock读文件中数据的实现代码。
请在实验报告中给出设计实现”UNIX的PIPE机制“的概要设方案,鼓励给出详细设计方案
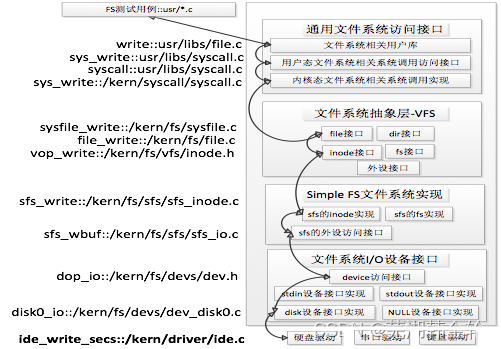
ucore的文件系统架构
ucore模仿了UNIX的文件系统设计,ucore的文件系统架构主要由四部分组成:
- 通用文件系统访问接口层:该层提供了一个从用户空间到文件系统的标准访问接口。这一层访问接口让应用程序能够通过一个简单的接口获得ucore内核的文件系统服务。
- 文件系统抽象层:向上提供一个一致的接口给内核其他部分(文件系统相关的系统调用实现模块和其他内核功能模块)访问。向下提供一个同样的抽象函数指针列表和数据结构屏蔽不同文件系统的实现细节。
- Simple FS文件系统层:一个基于索引方式的简单文件系统实例。向上通过各种具体函数实现以对应文件系统抽象层提出的抽象函数。向下访问外设接口
- 外设接口层:向上提供device访问接口屏蔽不同硬件细节。向下实现访问各种具体设备驱动的接口,比如disk设备接口/串口设备接口/键盘设备接口等。
ucore文件系统总体结构:
重要数据结构
file文件结构:
struct file {
enum {
FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED,
} status; //访问文件的执行状态
bool readable; //文件是否可读
bool writable; //文件是否可写
int fd; //文件在filemap中的索引值
off_t pos; //访问文件的当前位置
struct inode *node; //该文件对应的内存inode指针
atomic_t open_count; //打开此文件的次数
};
inode:inode数据结构,它是位于内存的索引节点,把不同文件系统的特定索引节点信息(甚至不能算是一个索引节点)统一封装起来,避免了进程直接访问具体文件系统
struct inode {
union {
//不同文件系统特定inode信息的union域
struct device __device_info; //设备文件系统内存inode信息
struct sfs_inode __sfs_inode_info; //SFS文件系统内存inode信息
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; //此inode所属文件系统类型
atomic_t ref_count; //此inode的引用计数
atomic_t open_count; //打开此inode对应文件的个数
struct fs *in_fs; //抽象的文件系统,包含访问文件系统的函数指针
const struct inode_ops *in_ops; //抽象的inode操作,包含访问inode的函数指针
};
打开文件的处理流程
先假定用户进程需要打开的文件已经存在在硬盘上。以user/sfs_filetest1.c为例,首先用户进程会调用在main函数中的如下语句:
int fd1 = safe_open("/test/testfile", O_RDWR | O_TRUNC);
如果ucore能够正常查找到这个文件,就会返回一个代表文件的文件描述符fd1,这样在接下来的读写文件过程中,就直接用这样fd1来代表就可以了。
具体过程
(1)通用文件访问接口层的处理流程
首先用户会在进程中调用 safe_open()函数,然后依次调用如下函数: open->sys_open->syscall,从而引起系统调用进入到内核态。到到了内核态后,通过中断处理例程,会调用到sys_open内核函数,并进一步调用sysfile_open内核函数。到了这里,需要把位于用户空间的字符串”/test/testfile”拷贝到内核空间中的字符串path中,并进入到文件系统抽象层的处理流程完成进一步的打开文件操作中。
(2)文件系统抽象层的处理流程
分配一个空闲的file数据结构变量file在文件系统抽象层的处理中(当前进程的打开文件数组current->fs_struct->filemap[]中的一个空闲元素),到了这一步还仅仅是给当前用户进程分配了一个file数据结构的变量,还没有找到对应的文件索引节点。进一步调用vfs_open函数来找到path指出的文件所对应的基于inode数据结构的VFS索引节点node。然后调用vop_open函数打开文件。然后层层返回,通过执行语句file->node=node;,就把当前进程的current->fs_struct->filemap[fd](即file所指变量)的成员变量node指针指向了代表文件的索引节点node。这时返回fd。最后完成打开文件的操作。
(3)SFS文件系统层的处理流程
在第二步中,vop_lookup函数调用了sfs_lookup函数。
下面分析sfs_lookup函数:
static int sfs_lookup(struct inode *node, char *path, struct inode **node_store) {
struct sfs_fs *sfs = fsop_info(vop_fs(node), sfs);
assert(*path != '\0' && *path != '/'); //以“/”为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。
vop_ref_inc(node);
struct sfs_inode *sin = vop_info(node, sfs_inode);
if (sin->din->type != SFS_TYPE_DIR) {
vop_ref_dec(node);
return -E_NOTDIR;
}
struct inode *subnode;
int ret = sfs_lookup_once(sfs, sin, path, &subnode, NULL); //循环进一步调用sfs_lookup_once查找以“test”子目录下的文件“testfile1”所对应的inode节点。
vop_ref_dec(node);
if (ret != 0) {
return ret;
}
*node_store = subnode; //当无法分解path后,就意味着找到了需要对应的inode节点,就可顺利返回了。
return 0;
}
sfs_lookup函数先以“/”为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。然后循环进一步调用sfs_lookup_once查找以“test”子目录下的文件“testfile1”所对应的inode节点。最后当无法分解path后,就意味着找到了需要对应的inode节点,就可顺利返回了。
完成sfs_io_nolock函数
sfs_io_nolock函数主要用来将磁盘中的一段数据读入到内存中或者将内存中的一段数据写入磁盘。
该函数会进行一系列的边缘检查,检查访问是否越界、是否合法。之后将具体的读/写操作使用函数指针统一起来,统一成针对整块的操作。然后完成不落在整块数据块上的读/写操作,以及落在整块数据块上的读写。下面是该函数的代码(包括补充的代码,其中将有较为详细的注释)
static int
sfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin, void *buf, off_t offset, size_t *alenp, bool write)
{
//创建一个磁盘索引节点指向要访问文件的内存索引节点
struct sfs_disk_inode *din = sin->din;
assert(din->type != SFS_TYPE_DIR);
//确定读取的结束位置
off_t endpos = offset + *alenp, blkoff;
*alenp = 0;
// 进行一系列的边缘,避免非法访问
if (offset < 0 || offset >= SFS_MAX_FILE_SIZE || offset > endpos) {
return -E_INVAL;
}
if (offset == endpos) {
return 0;
}
if (endpos > SFS_MAX_FILE_SIZE) {
endpos = SFS_MAX_FILE_SIZE;
}
if (!write) {
if (offset >= din->size) {
return 0;
}
if (endpos > din->size) {
endpos = din->size;
}
}
int (*sfs_buf_op)(struct sfs_fs *sfs, void *buf, size_t len, uint32_t blkno, off_t offset);
int (*sfs_block_op)(struct sfs_fs *sfs, void *buf, uint32_t blkno, uint32_t nblks);
//确定是读操作还是写操作,并确定相应的系统函数
if (write) {
sfs_buf_op = sfs_wbuf, sfs_block_op = sfs_wblock;
}
else {
sfs_buf_op = sfs_rbuf, sfs_block_op = sfs_rblock;
}
//
int ret = 0;
size_t size, alen = 0;
uint32_t ino;
uint32_t blkno = offset / SFS_BLKSIZE; // The NO. of Rd/Wr begin block
uint32_t nblks = endpos / SFS_BLKSIZE - blkno; // The size of Rd/Wr blocks
//--------------------------补充部分----------------------------------------------
// 判断被需要操作的区域的数据块中的第一块是否是完全被覆盖的,
// 如果不是,则需要调用非整块数据块进行读或写的函数来完成相应操作
if ((blkoff = offset % SFS_BLKSIZE) != 0) {
// 第一块数据块中进行操作的偏移量
blkoff = offset % SFS_BLKSIZE;
// 第一块数据块中进行操作的数据长度
size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset);
//获取这些数据块对应到磁盘上的数据块的编号
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
//对数据块进行读或写操作
if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0) {
goto out;
}
//已经完成读写的数据长度
alen += size;
if (nblks == 0) {
goto out;
}
buf += size, blkno++; nblks--;
}
读取中间部分的数据,将其分为大小为size的块,然后一块一块操作,直至完成
size = SFS_BLKSIZE;
while (nblks != 0)
{
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
//对数据块进行读或写操作
if ((ret = sfs_block_op(sfs, buf, ino, 1)) != 0) {
goto out;
}
//更新相应的变量
alen += size, buf += size, blkno++, nblks--;
}
// 最后一页,可能出现不对齐的现象:
if ((size = endpos % SFS_BLKSIZE) != 0)
{
// 获取该数据块对应到磁盘上的数据块的编号
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// 进行非整块的读或者写操作
if ((ret = sfs_buf_op(sfs, buf, size, ino, 0)) != 0) {
goto out;
}
alen += size;
}
out:
*alenp = alen;
if (offset + alen > sin->din->size) {
sin->din->size = offset + alen;
sin->dirty = 1;
}
return ret;
}
总的来说就是分为三部分来读取文件,每次通过sfs_bmap_load_nolock函数获取文件索引编号,然后调用sfs_buf_op或者sfs_block_op完成实际的文件读写操作。
回答问题
- 请在实验报告中给出设计实现”UNIX的PIPE机制“的概要设方案,鼓励给出详细设计方案
管道可用于具有亲缘关系进程间的通信,管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。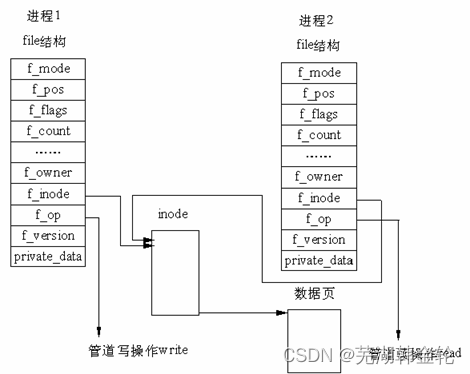
管道可以看作是由内核管理的一个缓冲区,一端连接进程A的输出,另一端连接进程B的输入。进程A会向管道中放入信息,而进程B会取出被放入管道的信息。当管道中没有信息,进程B会等待,直到进程A放入信息。当管道被放满信息的时候,进程A会等待,直到进程B取出信息。当两个进程都结束的时候,管道也自动消失。管道基于fork机制建立,从而让两个进程可以连接到同一个PIPE上。
基于此,我们可以模仿UNIX,设计一个PIPE机制。
- 首先我们需要在磁盘上保留一定的区域用来作为PIPE机制的缓冲区,或者创建一个文件为PIPE机制服务
- 对系统文件初始化时将PIPE也初始化并创建相应的inode
- 在内存中为PIPE留一块区域,以便高效完成缓存
- 当两个进程要建立管道时,那么可以在这两个进程的进程控制块上新增变量来记录进程的这种属性
- 当其中一个进程要对数据进行写操作时,通过进程控制块的信息,可以将其先对临时文件PIPE进行修改
- 当一个进行需要对数据进行读操作时,可以通过进程控制块的信息完成对临时文件PIPE的读取
- 增添一些相关的系统调用支持上述操作
至此,PIPE的大致框架已经完成。
练习2: 完成基于文件系统的执行程序机制的实现(需要编码)
改写proc.c中的load_icode函数和其他相关函数,实现基于文件系统的执行程序机制。执行:make qemu。如果能看看到sh用户程序的执行界面,则基本成功了。如果在sh用户界面上可以执行”ls”,”hello”等其他放置在sfs文件系统中的其他执行程序,则可以认为本实验基本成功。
请在实验报告中给出设计实现基于”UNIX的硬链接和软链接机制“的概要设方案,鼓励给出详细设计方案
alloc_proc
在proc.c中,根据注释我们需要先初始化fs中的进程控制结构,即在alloc_proc函数中我们需要做一下修改,加上一句proc->filesp = NULL;从而完成初始化。
static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
// Lab7内容
// ...
//LAB8:EXERCISE2 YOUR CODE HINT:need add some code to init fs in proc_struct, ...
// LAB8 添加一个filesp指针的初始化
proc->filesp = NULL;
}
return proc;
}
load_icode
load_icode函数的主要工作就是给用户进程建立一个能够让用户进程正常运行的用户环境。基本流程:
- 调用mm_create函数来申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化;
- 调用setup_pgdir来申请一个页目录表所需的一个页大小的内存空间,并把描述ucore内核虚空间映射的内核页表(boot_pgdir所指)的内容拷贝到此新目录表中,最后让mm->pgdir指向此页目录表,这就是进程新的页目录表了,且能够正确映射内核虚空间;
- 将磁盘中的文件加载到内存中,并根据应用程序执行码的起始位置来解析此ELF格式的执行程序,并根据ELF格式的执行程序说明的各个段(代码段、数据段、BSS段等)的起始位置和大小建立对应的vma结构,并把vma插入到mm结构中,从而表明了用户进程的合法用户态虚拟地址空间;
- 调用根据执行程序各个段的大小分配物理内存空间,并根据执行程序各个段的起始位置确定虚拟地址,并在页表中建立好物理地址和虚拟地址的映射关系,然后把执行程序各个段的内容拷贝到相应的内核虚拟地址中
- 需要给用户进程设置用户栈,并处理用户栈中传入的参数
- 先清空进程的中断帧,再重新设置进程的中断帧,使得在执行中断返回指令“iret”后,能够让CPU转到用户态特权级,并回到用户态内存空间,使用用户态的代码段、数据段和堆栈,且能够跳转到用户进程的第一条指令执行,并确保在用户态能够响应中断;
大致可以简单分为以下部分:
将文件加载到内存中执行,根据注释的提示分为了一共七个步骤:
- 建立内存管理器
- 建立页目录
- 将文件逐个段加载到内存中,这里要注意设置虚拟地址与物理地址之间的映射
- 建立相应的虚拟内存映射表
- 建立并初始化用户堆栈
- 处理用户栈中传入的参数
- 最后很关键的一步是设置用户进程的中断帧
完整代码如下:
//从磁盘上读取可执行文件,并且加载到内存中,完成内存空间的初始化
static int load_icode(int fd, int argc, char **kargv)
{
//判断当前进程的内存管理是否已经被释放掉了,我们需要要求当前内存管理器为空
if (current->mm != NULL)
{
panic("load_icode: current->mm must be empty.\n");
}
int ret = -E_NO_MEM;
//1.调用mm_create函数来申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化
struct mm_struct *mm;
if ((mm = mm_create()) == NULL) {
goto bad_mm;
}
//2.申请新目录项的空间并完成目录项的设置
if (setup_pgdir(mm) != 0) {
goto bad_pgdir_cleanup_mm;
}
//创建页表
struct Page *page;
//3.从文件从磁盘中加载程序到内存
struct elfhdr __elf, *elf = &__elf;
//3.1调用load_icode_read函数读取ELF文件
if ((ret = load_icode_read(fd, elf, sizeof(struct elfhdr), 0)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
//判断这个文件是否合法
if (elf->e_magic != ELF_MAGIC) {
ret = -E_INVAL_ELF;
goto bad_elf_cleanup_pgdir;
}
struct proghdr __ph, *ph = &__ph;
uint32_t i;
uint32_t vm_flags, perm;
//e_phnum代表程序段入口地址数目
for (i = 0; i < elf->e_phnum; ++i)
{
//3.2循环读取程序的每个段的头部
if ((ret = load_icode_read(fd, ph, sizeof(struct proghdr), elf->e_phoff + sizeof(struct proghdr) * i)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
if (ph->p_type != ELF_PT_LOAD) {
continue ;
}
if (ph->p_filesz > ph->p_memsz) {
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
if (ph->p_filesz == 0) {
continue ;
}
//3.3建立对应的VMA
vm_flags = 0, perm = PTE_U; //建立虚拟地址与物理地址之间的映射
// 根据ELF文件中的信息,对各个段的权限进行设置
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
//虚拟内存地址设置为合法的
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
//3.4为数据段代码段等分配页
off_t offset = ph->p_offset;
size_t off, size;
//计算数据段和代码段的开始地址
uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
//计算数据段和代码段终止地址
end = ph->p_va + ph->p_filesz;
while (start < end)
{
// 为TEXT/DATA段逐页分配物理内存空间
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL)
{
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// 将磁盘上的TEXT/DATA段读入到分配好的内存空间中去
//每次读取size大小的块,直至全部读完
if ((ret = load_icode_read(fd, page2kva(page) + off, size, offset)) != 0)
{
goto bad_cleanup_mmap;
}
start += size, offset += size;
}
//3.5为BBS段分配页
//计算BBS的终止地址
end = ph->p_va + ph->p_memsz;
if (start < la) {
if (start == end) {
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la)
{
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
// 如果没有给BSS段分配足够的页,进一步进行分配
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// 将分配到的空间清零初始化
memset(page2kva(page) + off, 0, size);
start += size;
}
}
sysfile_close(fd);//关闭文件,加载程序结束
// 4.设置用户栈
vm_flags = VM_READ | VM_WRITE | VM_STACK; //设置用户栈的权限
//将用户栈所在的虚拟内存区域设置为合法的
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL);
//设置当前进程的mm、cr3等
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
//为用户空间设置trapeframe
uint32_t argv_size=0, i;
//确定传入给应用程序的参数具体应当占用多少空间
uint32_t total_len = 0;
for (i = 0; i < argc; ++i)
{
total_len += strnlen(kargv[i], EXEC_MAX_ARG_LEN) + 1;
// +1表示字符串结尾的'\0'
}
// 用户栈顶减去所有参数加起来的长度,与4字节对齐找到真正存放字符串参数的栈的位置
char *arg_str = (USTACKTOP - total_len) & 0xfffffffc;
//存放指向字符串参数的指针
int32_t *arg_ptr = (int32_t *)arg_str - argc;
// 根据参数需要在栈上占用的空间来推算出,传递了参数之后栈顶的位置
int32_t *stacktop = arg_ptr - 1;
*stacktop = argc;
for (i = 0; i < argc; ++i)
{
uint32_t arg_len = strnlen(kargv[i], EXEC_MAX_ARG_LEN);
strncpy(arg_str, kargv[i], arg_len);
*arg_ptr = arg_str;
arg_str += arg_len + 1;
++arg_ptr;
}
//6.设置进程的中断帧
//设置tf相应的变量的设置,包括:tf_cs、tf_ds tf_es、tf_ss tf_esp, tf_eip, tf_eflags
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = stacktop;
tf->tf_eip = elf->e_entry;
tf->tf_eflags |= FL_IF;
ret = 0;
out:
return ret;
//一些错误的处理
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf_cleanup_pgdir:
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
goto out;
}
运行make qemu:
输入ls和hello:

运行make grade查看成绩: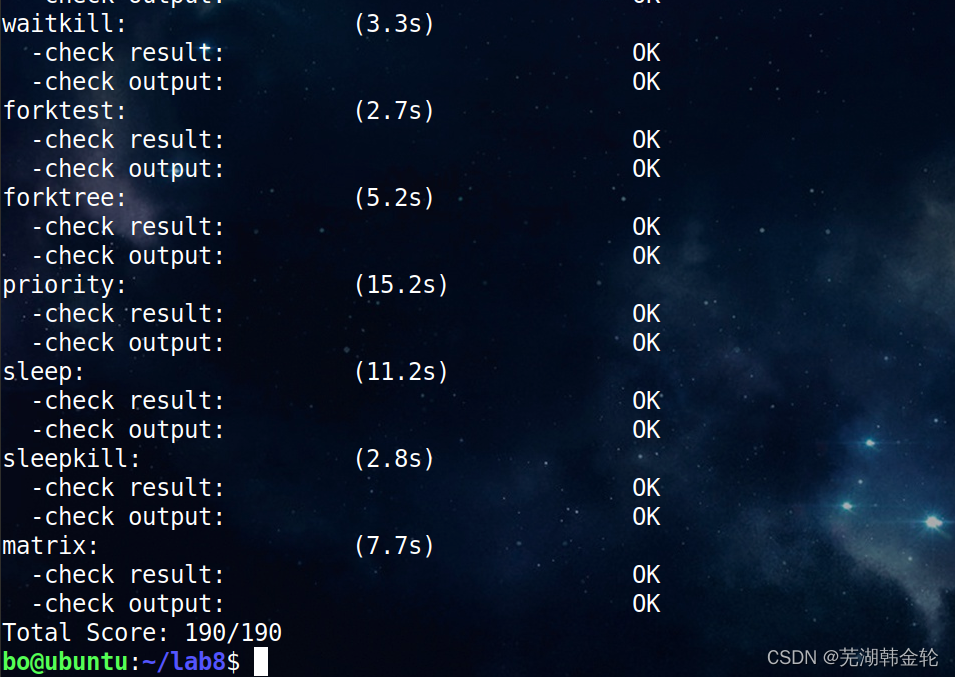
回答问题
- 请在实验报告中给出设计实现基于”UNIX的硬链接和软链接机制“的概要设方案,鼓励给出详细设计方案
硬链接:是给文件一个副本,同时建立两者之间的连接关系
软链接:符号连接
硬链接和软链接的主要特征:
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件
软链接的创建与使用没有类似硬链接的诸多限制:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling
link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
保存在磁盘上的inode信息均存在一个nlinks变量用于表示当前文件的被链接的计数,因而支持实现硬链接和软链接机制;
- 创建硬链接link时,为
new_path创建对应的file,并把其inode指向old_path所对应的inode,inode的引用计数加1。 - 创建软连接link时,创建一个新的文件(inode不同),并把
old_path的内容存放到文件的内容中去,给该文件保存在磁盘上时disk_inode类型为SFS_TYPE_LINK,再完善对于该类型inode的操作即可。 - 删除一个软链接B的时候,直接将其在磁盘上的
inode删掉即可;但删除一个硬链接B的时候,除了需要删除掉B的inode之外,还需要将B指向的文件A的被链接计数减1,如果减到了0,则需要将A删除掉; - 问硬链接的方式与访问软链接是一致的;
祝贺你通过自己的努力,完成了ucore OS lab1-lab8!
边栏推荐
- {1,2,3,2,5} duplicate checking problem
- Statistics 8th Edition Jia Junping Chapter IX summary of knowledge points of classified data analysis and answers to exercises after class
- 指針:最大值、最小值和平均值
- 浙大版《C语言程序设计实验与习题指导(第3版)》题目集
- 函数:计算字符串中大写字母的个数
- 数字电路基础(一)数制与码制
- MySQL中什么是索引?常用的索引有哪些种类?索引在什么情况下会失效?
- Four methods of exchanging the values of a and B
- Express
- “Hello IC World”
猜你喜欢
Build your own application based on Google's open source tensorflow object detection API video object recognition system (II)
Vysor uses WiFi wireless connection for screen projection_ Operate the mobile phone on the computer_ Wireless debugging -- uniapp native development 008
![[HCIA continuous update] advanced features of routing](/img/05/a9ed32ec8c19b236355d48f7c2ad80.jpg)
[HCIA continuous update] advanced features of routing

Fundamentals of digital circuits (III) encoder and decoder

关于交换a和b的值的四种方法
王爽汇编语言学习详细笔记一:基础知识
“Hello IC World”
Statistics, 8th Edition, Jia Junping, Chapter 6 Summary of knowledge points of statistics and sampling distribution and answers to exercises after class
Statistics 8th Edition Jia Junping Chapter 3 after class exercises and answer summary

Mysql的事务是什么?什么是脏读,什么是幻读?不可重复读?
随机推荐
[Ogg III] daily operation and maintenance: clean up archive logs, register Ogg process services, and regularly back up databases
Mysql的事务是什么?什么是脏读,什么是幻读?不可重复读?
指针 --按字符串相反次序输出其中的所有字符
Keil5 MDK's formatting code tool and adding shortcuts
函数:求方程的根
关于超星脚本出现乱码问题
Statistics, 8th Edition, Jia Junping, Chapter 11 summary of knowledge points of univariate linear regression and answers to exercises after class
Face and eye recognition based on OpenCV's own model
我的第一篇博客
Global and Chinese market of RF shielding room 2022-2028: Research Report on technology, participants, trends, market size and share
Four methods of exchanging the values of a and B
后台登录系统,JDBC连接数据库,做小案例练习
Numpy Quick Start Guide
Public key box
Global and Chinese markets of electronic grade hexafluorobutadiene (C4F6) 2022-2028: Research Report on technology, participants, trends, market size and share
Es full text index
Zhejiang University Edition "C language programming experiment and exercise guide (3rd Edition)" topic set
Résumé des points de connaissance et des réponses aux exercices après la classe du chapitre 7 de Jia junping dans la huitième édition des statistiques
How to transform functional testing into automated testing?
Fundamentals of digital circuits (II) logic algebra