当前位置:网站首页>Build your own application based on Google's open source tensorflow object detection API video object recognition system (II)
Build your own application based on Google's open source tensorflow object detection API video object recognition system (II)
2022-07-06 14:53:00 【gmHappy】
Based on the previous article, based on Google open source TensorFlow Object Detection API Video object recognition system builds its own application ( One ), Realize video object recognition
Based on the first part , newly build VideoTest.py, And put a video file into object_detection Under the table of contents
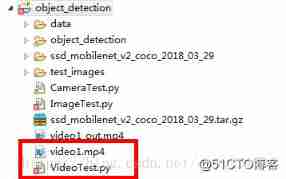
The main steps are as follows :
1. Use VideoFileClip Function to grab an image from a video .
2. use fl_image Function to replace the original image with the modified image , Each captured image used to transmit object recognition .
3. All the modified clip images are combined into a new video .
I don't say much nonsense , Go straight to the code :
# coding: utf-8
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
if tf.__version__ < '1.4.0':
raise ImportError('Please upgrade your tensorflow installation to v1.4.* or later!')
# This is needed to display the images.
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
##Model preparation##
# What model to download.
MODEL_NAME = 'ssd_mobilenet_v2_coco_2018_03_29'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
## Download Model##
#opener = urllib.request.URLopener()
#opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
## Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
## Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
import imageio
imageio.plugins.ffmpeg.download()
from moviepy.editor import VideoFileClip
from IPython.display import HTML
def detect_objects(image_np, sess, detection_graph):
# Expand dimensions , Expected for model : [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents an object detected
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represents the reliability of the detected object .
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Perform detection task .
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of test results
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
return image_np
def process_image(image):
# NOTE: The output you return should be a color image (3 channel) for processing video below
# you should return the final output (image with lines are drawn on lanes)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
image_process = detect_objects(image, sess, detection_graph)
return image_process
white_output = 'video1_out.mp4'
clip1 = VideoFileClip("video1.mp4").subclip(10,20)
white_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!s
white_clip.write_videofile(white_output, audio=False)
from moviepy.editor import *
clip1 = VideoFileClip("video1_out.mp4")
clip1.write_gif("final.gif")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
Code interpretation :
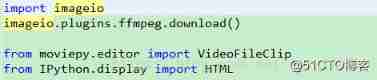
A necessary program for editing will be downloaded here ffmpeg.win32.exe, It's easy to disconnect during intranet downloading , You can use the download tool to download it and put it in the following path :
C:\Users\ user name \AppData\Local\imageio\ffmpeg\ffmpeg.win32.exe

First , Use VideoFileClip Function to extract images from video , extract 10 to 20S Image

And then use fl_image Function modifies the image of the clip by replacing the frame , And by calling process_image Apply object recognition on it API.fl_image It's a very useful function , You can extract an image and replace it with a modified image . Through this function, you can extract images from each video and apply object recognition ;
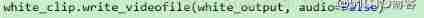
Last , Combine all the processed image clips into a new video .


So far, the object recognition in the video has been completed .
边栏推荐
- Vysor uses WiFi wireless connection for screen projection_ Operate the mobile phone on the computer_ Wireless debugging -- uniapp native development 008
- “Hello IC World”
- Function: find the maximum common divisor and the minimum common multiple of two positive numbers
- 《统计学》第八版贾俊平第九章分类数据分析知识点总结及课后习题答案
- ES全文索引
- 函数:求两个正数的最大公约数和最小公倍
- "If life is just like the first sight" -- risc-v
- What is the transaction of MySQL? What is dirty reading and what is unreal reading? Not repeatable?
- 关于交换a和b的值的四种方法
- To brush the video, it's better to see if you have mastered these interview questions. Slowly accumulating a monthly income of more than 10000 is not a dream.
猜你喜欢
Es full text index
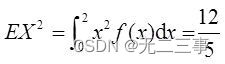
Statistics 8th Edition Jia Junping Chapter 5 probability and probability distribution

Fundamentals of digital circuit (V) arithmetic operation circuit

Want to learn how to get started and learn software testing? I'll give you a good chat today
“Hello IC World”

Markdown font color editing teaching
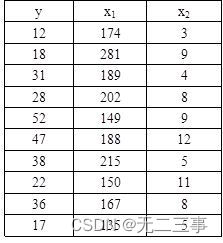
《统计学》第八版贾俊平第十二章多元线性回归知识点总结及课后习题答案
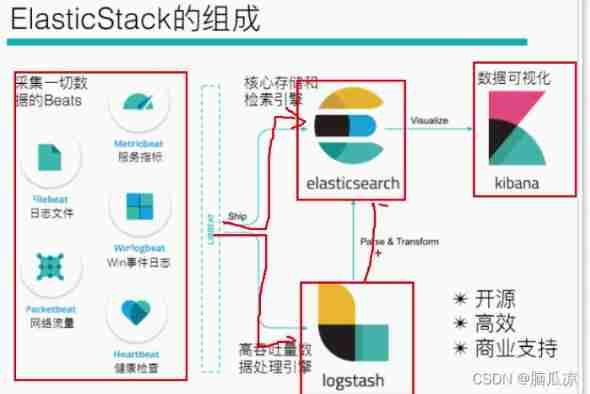
Logstack introduction and deployment -- elasticstack (elk) work notes 019
王爽汇编语言学习详细笔记一:基础知识

Matplotlib绘图快速入门
随机推荐
浙大版《C语言程序设计实验与习题指导(第3版)》题目集
Logstack introduction and deployment -- elasticstack (elk) work notes 019
“Hello IC World”
MySQL中什么是索引?常用的索引有哪些种类?索引在什么情况下会失效?
四元数---基本概念(转载)
Statistics, 8th Edition, Jia Junping, Chapter VIII, summary of knowledge points of hypothesis test and answers to exercises after class
Numpy Quick Start Guide
150 common interview questions for software testing in large factories. Serious thinking is very valuable for your interview
Four methods of exchanging the values of a and B
Solutions to common problems in database development such as MySQL
Database monitoring SQL execution
Realize applet payment function with applet cloud development (including source code)
Binary search tree concept
《统计学》第八版贾俊平第六章统计量及抽样分布知识点总结及课后习题答案
Proceedingjoinpoint API use
5 minutes to master machine learning iris logical regression classification
Flash implements forced login
指针--剔除字符串中的所有数字
Uibutton status exploration and customization
《统计学》第八版贾俊平第十二章多元线性回归知识点总结及课后习题答案