当前位置:网站首页>ES全文索引
ES全文索引
2022-07-06 09:24:00 【小白阿远】
ES全文索引的好处:
1.作为数据库(代替MySQL);
2.在大数据条件下做检索服务、同义词处理、相关度排名、复杂数据分析、海量数据的近实时处理;
3.记录和日志的分析
4.全文检索
5.关系型数据库的补充,传统数据库的替代
6.站内搜索、垂直搜索
1.docker
应用容器引擎
“Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。”
2.docker安装
a.更新源: apt-get update
b.安装docker: apt-get install docker.io
c.查看docker: docker ps # 查看是否安装成功
# 根据自己情况而定,提示没有权限的时候执行每条命令前要加上sudo
3.docker安装ES
1、拉取es镜像
docker pull bitnami/elasticsearch
2、创建es容器
docker run -d -p 9200:9200 -p 9300:9300 --name elasticsearch bitnami/elasticsearch
# 根据自己情况而定,提示没有权限的时候执行每条命令前要加上sudo
3.在网页中测试是否安装成功例:

1.在flask项目中使用ES索引
创建一个关于es索引的文件夹

es.py中
实例es对象、初始化连接一个 Elasticsearch 操作对象、根据id获取文档数据以及插入文档id
建立和es容器的链接
from elasticsearch import Elasticsearch
from celery_task import celery_app
# 建立连接
es = Elasticsearch("http://101.42.224.35:9200/")
class ES(object):
"""
es 对象
"""
def __init__(self, index_name: str):
self.es = es
self.index_name = index_name
def get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)
def insert_one(self, doc: dict):
self.es.index(index=self.index_name, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, body=doc)
def search(self, query, count: int = 30, fields=None):
fields = fields if fields else ["title", 'pub_date']
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": fields
},
# 'wildcard': {
# 'content': {
# 'value': '*' + query + '*'
# }
# }
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_data
def _search(self, query: dict, count: int = 20, fields=None): # count: 返回的数据大小
results = []
match_data = self.search(query, count, fields)
for hit in match_data['hits']['hits']:
results.append(hit['_source'])
return results
def create_index(self):
if self.es.indices.exists(index=self.index_name) is True:
self.es.indices.delete(index=self.index_name)
self.es.indices.create(index=self.index_name, ignore=400)
def delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
passone_scripts.py
将数据库数据导入es
# 需要注意端口号和数据库是否为本地数据库以及需要导入的数据库的名字和数据库的解码方式
import pymysql
import traceback
from elasticsearch import Elasticsearch
def get_db_data():
# 打开数据库连接(ip/数据库用户名/登录密码/数据库名)
db = pymysql.connect(host="127.0.0.1", user="用户名", password="密码",
database="数据库名字", charset='utf8')
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
sql = "SELECT * FROM course"
# 使用 execute() 方法执行 SQL 查询
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
# 关闭数据库连接
db.close()
return results
def insert_data_to_es():
es = Elasticsearch("http://101.42.224.35:9200/")
# 清空数据
es.indices.delete(index='course')
try:
i = -1
for row in get_db_data():
print(row)
print(row[1], row[2])
i += 1
es.index(index='course', body={
'id': i,
'table_name': 'table_name',
'pid': row[4],
'title': row[5],
'desc': str(row[6]),
})
except:
error = traceback.format_exc()
print("Error: unable to fecth data", error)
if __name__ == "__main__":
insert_data_to_es()模型类中需要定义索引并设置为支持中文
__searchable__ = ['title'] #搜索相关的字段
__analyzer__ = ChineseAnalyzer()#支持中文索引在视图中用es重新定义一下接口,最后将数据返回出去
在python中使用的方法----es.searche()
es = ES(index_name='Tag')
result = es._search(q, fields=['title', 'desc'])
import traceback
from common.es.es import ES
class GetTag(Resource):
def get(self):
"""
获取前端数据
使用es全文搜索
"""
parser = reqparse.RequestParser()
parser.add_argument('q')
args = parser.parse_args()
q= args.get('q')
try:
es = ES(index_name='Tag')
result = es._search(q, fields=['title', 'desc'])
return marshal(result, tag_fields)
except:
error = traceback.format_exc()
print('111111111111', error)
return {'message': error}, 500通过以上配置和重写的接口就可以实现全文es索引的使用
边栏推荐
- Hackmyvm target series (3) -visions
- JDBC transactions, batch processing, and connection pooling (super detailed)
- This article explains in detail how mockmvc is used in practical work
- 《统计学》第八版贾俊平第九章分类数据分析知识点总结及课后习题答案
- Web vulnerability - File Inclusion Vulnerability of file operation
- 内网渗透之内网信息收集(三)
- Constants, variables, and operators of SystemVerilog usage
- 《统计学》第八版贾俊平第四章总结及课后习题答案
- MSF generate payload Encyclopedia
- Detailed explanation of network foundation
猜你喜欢
Windows platform mongodb database installation
Hackmyvm target series (3) -visions

《统计学》第八版贾俊平第十章方差分析知识点总结及课后习题答案

Binary search tree concept
记一次edu,SQL注入实战

关于超星脚本出现乱码问题
Intranet information collection of Intranet penetration (2)

Intranet information collection of Intranet penetration (5)
小程序web抓包-fiddler
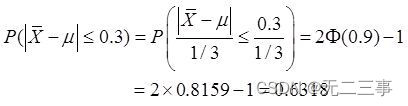
Statistics, 8th Edition, Jia Junping, Chapter 6 Summary of knowledge points of statistics and sampling distribution and answers to exercises after class
随机推荐
Hackmyvm target series (6) -videoclub
captcha-killer验证码识别插件
JDBC read this article is enough
7-14 error ticket (PTA program design)
List and data frame of R language experiment III
Wu Enda's latest interview! Data centric reasons
Proceedingjoinpoint API use
链队实现(C语言)
XSS (cross site scripting attack) for security interview
Record an edu, SQL injection practice
Realize applet payment function with applet cloud development (including source code)
Xray and burp linkage mining
This article explains in detail how mockmvc is used in practical work
On the idea of vulnerability discovery
MySQL interview questions (4)
Chain team implementation (C language)
搭建域环境(win)
Middleware vulnerability recurrence Apache
HackMyvm靶机系列(7)-Tron
Hcip -- MPLS experiment