当前位置:网站首页>JDBC transactions, batch processing, and connection pooling (super detailed)
JDBC transactions, batch processing, and connection pooling (super detailed)
2022-07-06 14:14:00 【Want to enter a big factory】
Preface
I summed up yesterday JDBC Coding steps , Let's talk about today JDBC Business 、 Batch processing and JDBC Related concepts and usage of connection pool ,( notes : All code statements of the author are aimed at MySQL Database implementation )
One 、JDBC Business
extraction : Let's start with a question , Suppose there is a balance table in our database , There are two records , The following table :
+----+-----------+---------+
| id | name | balance |
+----+-----------+---------+
| 1 | Jack ma, | 2800 |
| 2 | ma | 10100 |
+----+-----------+---------+
Now we have the following needs : We need Ma Yun's 100 Block to Ma Huateng , The ideal result is Ma Yun's balance=2700, And Ma Huateng's balance=10200; We are idea Simulate in the code :
@Test
public void noTransaction(){
//1. Get connected
Connection connection = null;
//2. organization sql sentence
String sql = "Update account2 set balance = balance-100 where id=1";
String sql2 = "Update account2 set balance = balance+100 where id=2";
PreparedStatement preparedStatement =null;
//3. establish PreparedStatement object
try {
connection = JDBCUtils.getConnection();// By default ,connection Is the default auto submit
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();// Article 1 with a
int i =1/0;
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();// Second
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
// close resource
JDBCUtils.close(null,preparedStatement,connection);
}
}notes :JDBCUtils The tool class is to complete the connection to the database , And closing resources , There is no detail here
If try-catch There is no... In the code block int i =1/0; This statement , Obviously, two statements can be executed successfully , The test results are shown in the table below :

But if there is int i =1/0, Will throw a java.lang.ArithmeticException: / by zero abnormal ,try-catch In the sentence , As long as the code throws an exception , The following code will not execute , So there's a problem : It's Ma Yun's 100 yuan that has indeed been transferred , But Ma Huateng didn't receive 100 block , this 100 The piece disappeared out of thin air , This is a serious mistake in our actual development , For example, transfer and withdraw money in the bank , Maybe a little friend will say , Then why write this exception , You don't write it , Ma Huateng received it ? Here I just want to throw out the role of transactions from this problem , Next, the author uses transactions to solve this problem .
JDBC Basic introduction to transaction
1.JDBC In the program, when a Connection When an object is created , By default, transactions are automatically committed when : One at a time sql When the sentence is , If it works , It will automatically submit to the database , Instead of rolling back
2.JDBC In order to make multiple SQL Statement as a whole , Need to use transactions
3. call Connection When setAutoCommit(false) You can cancel auto commit transactions
4. Of all the SQL After the statements are executed successfully , call Commit(): Method commit transaction
5. When one of the operations fails or an exception occurs , call rollback(): Method to roll back the transaction
I believe you can see that the affairs here are still a little vague , Next, the author uses the code to solve the above transfer problem . Go straight to the code !
@Test
public void useTransaction(){
//1. Get connected
Connection connection = null;
//2. organization sql sentence
String sql = "Update account2 set balance = balance-100 where id=1";
String sql2 = "Update account2 set balance = balance+100 where id=2";
PreparedStatement preparedStatement =null;
//3. establish PreparedStatement object
try {
connection = JDBCUtils.getConnection();// By default ,connection Is the default auto submit
// take connection Set to no longer submit automatically
connection.setAutoCommit(false); // Started the business
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();// Article 1 with a
int i =1/0;// Throw an exception , The following code is no longer executed
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();// Second
// Commit the transaction here
connection.commit();
} catch (SQLException e) {
// After throwing an exception , We can roll back transactions , Revoke the execution of SQL
// The default rollback is to the state where the transaction started
System.out.println(" An exception occurred during execution , Rollback undo transaction ");
try {
connection.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
throw new RuntimeException(e);
}finally {
// close resource
JDBCUtils.close(null,preparedStatement,connection);
}
}We will first connection Set not to commit automatically , In this way, transaction rollback can be used after an exception occurs , Effectively avoid the transfer problem , Let's take a look at the results :
The result is obvious : Ma Yun's 100 yuan didn't go out , And Ma Huateng didn't receive 100 yuan , On the console , We directly print out the abnormal information . I believe I can see here , The little partner should have a new understanding of affairs
Two 、JDBC The batch
extraction : Let's look at another problem :
Suppose we need to add thousands of data to a table , What will happen ?
Basic introduction to batch processing :
1. When you need to insert or update records in batches , May adopt java Batch update mechanism of , This mechanism runs multiple statements and submits them to the database for batch processing at one time , In general, it's more efficient than a single commit process
2.JDBC The batch processing statement of includes the following methods :
addBatch(): Add... That needs batch processing SQL Statement or argument
executeBatch(): Execute batch statements ;
clearBatch(): Statement to empty the batch package
3.JDBC Connect MySQL when , If you want to use batch processing , Please try again url China Canada parameters ?rewriteBatchedStatement=true
4. Batch processing is often associated with PreparedStatement Use together , You can reduce the number of compilations , And reduce the number of runs , The efficiency is greatly improved ;
First , We use traditional methods to solve this problem :
@Test
public void noBatch()throws Exception{
// Use JDBCUtils Tool classes create connection objects
Connection connection = JDBCUtils.getConnection();
// organization SQL sentence
String sql ="insert into admin2 values(null,?,?)";
// perform SQL sentence
PreparedStatement preparedStatement = connection.prepareStatement(sql);
System.out.println(" It's going to work ");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
preparedStatement.setString(1,"jack"+i);
preparedStatement.setString(2,"666");
preparedStatement.executeUpdate();
}
long end = System.currentTimeMillis();
System.out.println(" Traditional approach Time consuming = "+ (end-start));
JDBCUtils.close(null,preparedStatement,connection);
}Let's take a look at the time-consuming of traditional methods :

It's obviously very time-consuming , We are just a java Program , In actual development , We will have many users to operate the database , Many java File to add to the database , Then the time efficiency will be very low , Obviously, it is not conducive to our development . So how to solve this problem ? We use batch processing to solve this problem :
// Add data in batch mode
@Test
public void batch() throws Exception{
Connection connection = JDBCUtils.getConnection();
String sql ="insert into admin2 values(null,?,?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
System.out.println(" It's going to work ");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
preparedStatement.setString(1,"jack"+i);
preparedStatement.setString(2,"666");
// What will be done SQL Statement into the batch package
preparedStatement.addBatch();
// When there are 1000 records , Then execute in batch
if ((i+1) % 1000 ==0){
preparedStatement.executeBatch();
// Empty one
preparedStatement.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println(" Batch mode Time consuming = "+ (end-start));
JDBCUtils.close(null,preparedStatement,connection);
}Let's take a look at the time-consuming batch processing :

There is a lot of time difference between batch processing and traditional processing , In actual development , Batch processing is obviously more effective
that , How is batch processing executed , Why does it execute so fast ? very good , If you have such an idea , To a large extent, it shows that you are thinking about problems ️
Let's see addBatch() The underlying source code of the method :
public void addBatch() throws SQLException {
synchronized(this.checkClosed().getConnectionMutex()){
if(this.batchedArgs == null){
this.batchedArgs = new ArrayList();
}
for(int i =0;i<this.parameterValues.length;++i){
this.checkAllParametersSet(this.parameterValues[i],this.parameterStreams[i],i);
}
this.batchedArgs.add(new PreparedStatement.BatchParams(this.parameterValues,this.parameterValues);
}
}Author himself debug after , I still feel that my understanding is not deep enough , I checked on the Internet again about this method , Just to summarize :
1. The first step is to create ArrayList - elementData => object[] 2.elementData => Object[] Will store our preprocessed SQL sentence 3. When elementData After full , Just follow 1.5 Double expansion 4. When added to the specified value , will executeBatch 5. Batch processing will reduce our occurrence sql Statement to network overhead , And reduce the number of compilations , So it's efficient
3、 ... and 、JDBC Connection pool
JDBC Necessity of connection pool
When we develop based on database , The traditional mode basically follows the following steps :
1. Registration drive
2. Get the connection
3. Add, delete, modify and check
4. Release resources
Disadvantages of ordinary mode :
1. Conventional JDBC Database connection use DriverManager To get , Every time you establish a connection to the database, you need to Connection Load into memory , Revalidation ip Address , User name and password (0.05s~1s), Database connection is required when , Just ask the database for a , Frequent database connection operations will occupy a lot of system resources , Easy to cause server crash
2. Every database connection , You have to disconnect it after use , If the program fails to close due to an exception , Will result in database memory leak , Eventually, it will cause the database to restart
3. The traditional way to get a connection , Cannot control the connection data created , If there are too many connections , It can also cause memory leaks ,MySQL collapse
Database connection pool technology
Basic introduction :
1. Put a certain number of connections in the buffer pool in advance , When you need to establish a database connection , Just from “ Buffer pool ” Take out one of , Put it back after use
2. The database connection pool is responsible for allocation 、 Manage and release database connections , It allows applications to reuse an existing database connection , Instead of re establishing a
3. When the number of connections the application requests from the connection pool exceeds the maximum number of connections , These requests will be added to the waiting queue
Schematic diagram of database connection pool :
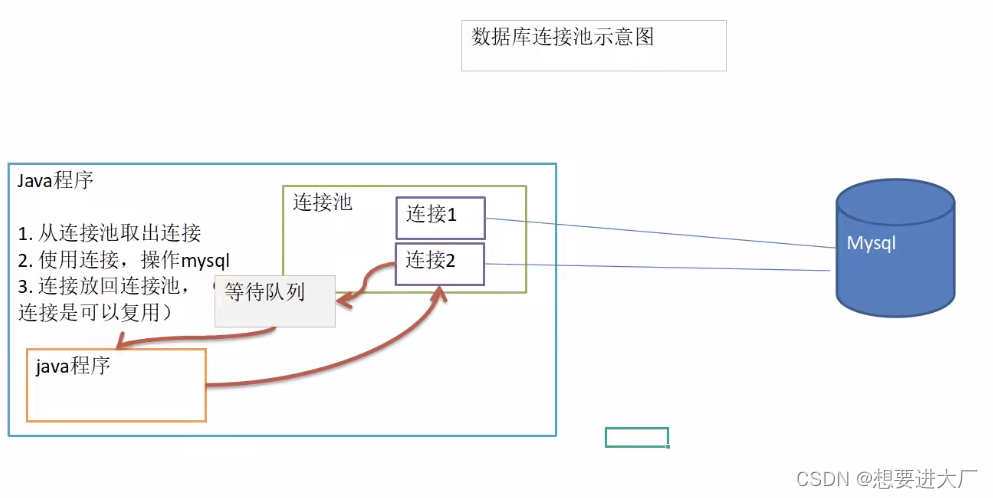
Advantages of database connection pool :
1. Resource reuse
Because database connections can be reused , Avoid frequent creation , Release causes a lot of performance overhead , While reducing system consumption , It also increases the stability of the system operating environment ;
2. The system reacts faster
The principle of database connection pool is to create several database connections in advance in the connection pool , At this time, the initialization work has been completed , The operations that request database connection are directly allocated by the connection pool , Can be used directly , It avoids the time cost in the process of database connection initialization and release , Thus reducing the response time of the system ;
3. New means of resource allocation
A system where multiple applications share the same database , It can be configured in the application layer through the database connection pool , Set the maximum number of connections , It avoids an application monopolizing all database resources
4. Unified management , Avoid database connection leaks
Type of database connection pool
JDBC The database connection pool is used javax.sql.DateSource To express ,DataSource It's just an interface , Often referred to as a data source , It includes connection pool and connection pool management ,DataSource To replace DriverManager To get Connection, Fast acquisition , At the same time, it can also greatly improve the speed of database access
1.C3P0 Database connection pool , Relatively slow , Good stability
2.DBCP Database connection pool , Speed is relative to C3P0 Faster , But not stable
3.Proxool Database connection pool , It has the function of monitoring connection pool status , More stable C3P0 almost
4.BoneCP Database connection pool , Fast
5.Druid( Druid ) It is the database connection pool provided by Ali , Set DBCP、C3P0、Proxool All in one connection pool ( The most commonly used , Most used )
This article focuses on C3P0 Database connection pool and Druid connection pool ;
C3P0 Database connection pool :
Get the pre work of the connection : Need to put c3p0.jar Package import idea in , And add to the project ;
<c3p0-config>
<named-config name="xyx_edu">
<!-- Drive class -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<!-- url-->
<property name="jdbcUrl">jdbc:mysql://127.0.0.1:3306/xyx_db02</property>
<!-- user name -->
<property name="user">root</property>
<!-- password -->
<property name="password">???</property>
<!-- Number of connections per growth -->
<property name="acquireIncrement">5</property>
<!-- Initial number of connections -->
<property name="initialPoolSize">10</property>
<!-- Minimum connections -->
<property name="minPoolSize">5</property>
<!-- maximum connection -->
<property name="maxPoolSize">50</property>
<!-- The maximum number of command objects that can be connected -->
<property name="maxStatements">5</property>
<!-- The maximum number of command objects that can be connected per connection object -->
<property name="maxStatementsPerConnection">2</property>
</named-config>
</c3p0-config>Mode one :
// The way 1: Related parameters , Specify in the program user,url,password etc.
@SuppressWarnings({"all"})
@Test
public void testC3P0_01() throws Exception{
//1. Create a data source object
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
//2. Through the configuration file mysql.properties Get relevant connection information
Properties properties = new Properties();
properties.load(new FileInputStream("src//mysql.Properties"));
// Get relevant information
String user = properties.getProperty("user");
String url = properties.getProperty("url");
String password = properties.getProperty("password");
String driver = properties.getProperty("driver");
//3. To data source comboPooledDataSource Set the relevant parameters
// The management of connections is done by comboPooledDataSource To manage
comboPooledDataSource.setDriverClass(driver);
comboPooledDataSource.setJdbcUrl(url);
comboPooledDataSource.setUser(user);
comboPooledDataSource.setPassword(password);
//4. Set the number of initialization connections
comboPooledDataSource.setInitialPoolSize(10);
comboPooledDataSource.setMaxPoolSize(50);// maximum connection
//5. Get the connection ( The core approach ) from DataSource Interface implemented
Connection connection = comboPooledDataSource.getConnection();
connection.close();
}Be careful :connection.close() The physical connection to the database is not closed , Just release the database connection , Returned to the database connection pool
Mode two :
// The second way Use the profile template to complete
//1. take c3p0-config-xml file copy to src Under the table of contents
//2. This file specifies to connect the database and connection pool to the relevant parameters
@Test
public void testC3P0_02() throws Exception{
// Create the specified parameters to the database connection pool ( data source )
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource("xyx_edu");
// Close the connection
connection.close();
}Both of these methods are desirable , But the second one is more recommended , Reduced code redundancy , Reduce the amount of coding .
Druid connection pool (Druid)
Get the connection pre work :
1. take druid.jar Package imported into the idea in , And add to project
2. take druid Copy the configuration file to src Under the table of contents
3. modify src Under the table of contents druid Database table name in the configuration file , password , And the minimum number of connections and the maximum number of connections
#key=value
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/xyx_db02?rewriteBatchedStatements=true
username=root
password=???
#initial connection Size
initialSize=10
#min idle connecton size
minIdle=5
#max active connection size
maxActive=50
#max wait time (5000 mil seconds)
maxWait=5000Get the connection
@Test
public void testDruid() throws Exception{
//1. Join in Druid jar package
//2. Join in The configuration file druid.properties , Copy the file to the project to src Catalog
//3. establish Properties object , Read configuration file
Properties properties = new Properties();
properties.load(new FileInputStream("src//druid.properties"));
//4. Create a specified parameter to the database connection pool
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection connection = dataSource.getConnection();
connection.close();
}边栏推荐
猜你喜欢
Windows platform mongodb database installation
Hackmyvm target series (4) -vulny
xray與burp聯動 挖掘
Xray and Burp linked Mining
. Net6: develop modern 3D industrial software based on WPF (2)
HackMyvm靶机系列(2)-warrior
Hackmyvm target series (6) -videoclub
外网打点(信息收集)
Attack and defense world misc practice area (GIF lift table ext3)

"Gold, silver and four" job hopping needs to be cautious. Can an article solve the interview?
随机推荐
Xray and burp linkage mining
Package bedding of components
Experiment 7 use of common classes (correction post)
强化学习基础记录
实验四 数组
7-6 local minimum of matrix (PTA program design)
Experiment five categories and objects
7-4 hash table search (PTA program design)
Intranet information collection of Intranet penetration (5)
网络层—简单的arp断网
Intensive literature reading series (I): Courier routing and assignment for food delivery service using reinforcement learning
实验六 继承和多态
Record an edu, SQL injection practice
【头歌educoder数据表中数据的插入、修改和删除】
Spot gold prices rose amid volatility, and the rise in U.S. prices is likely to become the key to the future
Read only error handling
7-3 construction hash table (PTA program design)
On the idea of vulnerability discovery
7-11 mechanic mustadio (PTA program design)
Strengthen basic learning records