当前位置:网站首页>强化学习基础记录
强化学习基础记录
2022-07-06 09:22:00 【喜欢库里的强化小白】
DDPG(Deep Deterministic Policy Gradient),基于Actor-Critic框架,是为了解决连续动作控制问题而提出的。该算法针对确定性策略,即给定状态,选出确定动作,而不是像随机性策略那样,进行抽样。
一、环境介绍
这里使用的是gym环境的’Pendulum-v1’,做简要介绍,详细介绍附上链接。
链接: OpenAI Gym 经典控制环境介绍——Pendulum-v1
(1)游戏规则:杆子进行转动,通过训练,使杆子能够朝上。
(2)状态空间: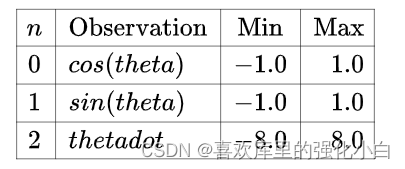
(3)动作空间:
这里我用了[-1,1]的动作空间,如果要改成和环境一样的配置,只需要将Actor网络实现中的tanh前乘2,并将choose_action中也进行相应修改即可。
(4)奖励:
(5)初始状态和终止状态:
二、算法简单介绍
Actor-Critic
DDPG可以简单的看成是DQN算法加上Actor-Critic框架,DDPG算法中所使用的AC框架是基于动作价值函数Q的框架。Actor学习策略函数,Critic学习动作价值函数Q;上图中的学习思路看着很绕,但是其实很好理解,举一个容易理解的比喻:Actor相当于一个运动员,Critic相当于一个裁判;运动员Actor要做动作,运动员肯定是想要动作做得越来越好,从而提高自己的技术,裁判给运动员打分,运动员根据这个打分来改进自己的动作,得到更高的分数,从而达到改进自己技术的目的;裁判Critic也要提高自己,让自己的打分越来越精准,这样才能让运动员的技术也越来越高,Critic是靠环境给的奖励reward来改进自己提高自己的水平。
链接: DDPG参考文章Off-Policy:
这里采用了Off-Policy的思想,采用了经验回放的思想,打破样本之间的关联性。DDPG的特点:
<1>经验回放的使用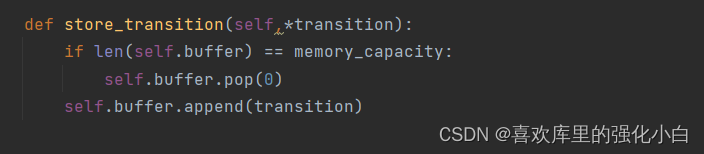
<2>双目标网络的使用:
在DQN中,通过对Q网络设置目标网络和行为网络,来稳定学习。在DDPG中,无论是Actor网络还是Critic网络,都具有目标网络,这也是很多博主所说的四网络方式。
<3>软更新的使用:
与DQN直接给目标网络喂参数的方法不同,这里采用软更新的方式对目标网络进行更新,使得学习更加稳定。其中目标网络不进行反向传递,相当于一个参照,行为网络通过训练,进行反向传播,以接近目标网络。
<4>探索性:
由于确定性动作,使得学习的探索性会降低,因此在选择动作的时候,可以使用贪心策略来增加探索性,同时也可以通过加入高斯噪声等方式,增加随机性。在这里,仅仅采用贪心策略。伪代码

实现
实现参考了网上的代码,进行了修改,起初效果不好,奖励一直上不去,后来请教了实验室的师兄,找到了一些问题,最后改来改去解决了问题。
总结原因可能有以下几个:
<1>经验池存满batch_size就要进行更新,不是存满才更新;
<2>软更新一定要在两个网络进行训练之后进行;
<3>每局的步数太少。
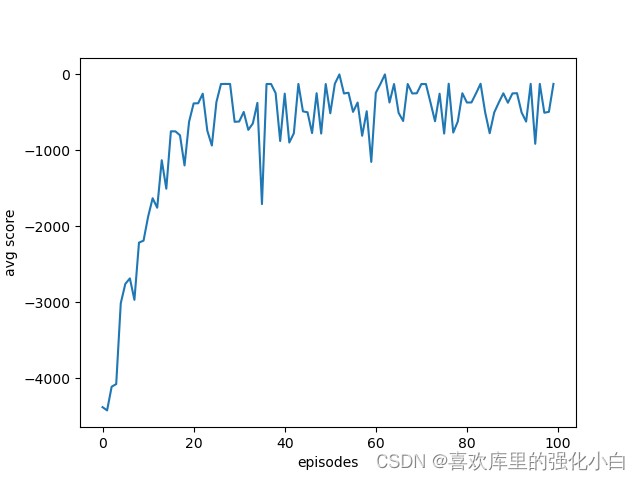
通过曲线可以看到,奖励升高,逐渐趋于0,由于训练太慢,只进行了100次迭代,因此没有达到最理想的效果。
import random
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
batch_size = 32
lr_actor = 0.001
lr_critic = 0.001
gamma = 0.90
epsilon = 0.9
episodes = 100
memory_capacity = 10000
#target_replace_iter = 100
tau = 0.02
env = gym.make('Pendulum-v1')
n_actions = env.action_space.shape[0]
n_states = env.observation_space.shape[0]
class Actor(nn.Module):
def __init__(self):
super(Actor, self).__init__()
self.fc1 = nn.Linear(n_states,256)
self.fc2 = nn.Linear(256,256)
self.out = nn.Linear(256,n_actions)
def forward(self,x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
actions = torch.tanh(self.out(x))
return actions
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.fc1 = nn.Linear(n_states + n_actions,256)
self.fc2 = nn.Linear(256,256)
self.q_out = nn.Linear(256,1)
def forward(self,state,aciton):
x = torch.cat([state,aciton],dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
q_value = self.q_out(x)
return q_value
class AC():
def __init__(self):
self.eval_actor,self.target_actor = Actor(),Actor()
self.eval_critic,self.target_critic = Critic(),Critic()
#self.learn_step_counter = 0
self.memory_counter = 0
self.buffer = []
self.target_actor.load_state_dict(self.eval_actor.state_dict())
self.target_critic.load_state_dict(self.eval_critic.state_dict())
self.actor_optim = torch.optim.Adam(self.eval_actor.parameters(),lr = lr_actor)
self.critic_optim = torch.optim.Adam(self.eval_critic.parameters(),lr = lr_critic)
def choose_action(self,state):
if np.random.uniform() > epsilon:
action = np.random.uniform(-1,1,1)
else:
inputs = torch.tensor(state, dtype=torch.float).unsqueeze(0)
action = self.eval_actor(inputs).squeeze(0)
action = action.detach().numpy()
return action
def store_transition(self,*transition):
if len(self.buffer) == memory_capacity:
self.buffer.pop(0)
self.buffer.append(transition)
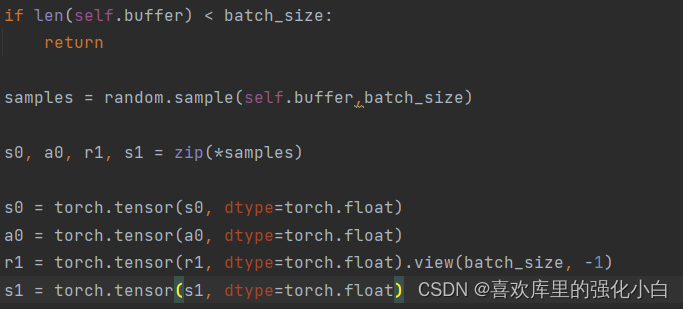
def learn(self):
if len(self.buffer) < batch_size:
return
samples = random.sample(self.buffer,batch_size)
s0, a0, r1, s1 = zip(*samples)
s0 = torch.tensor(s0, dtype=torch.float)
a0 = torch.tensor(a0, dtype=torch.float)
r1 = torch.tensor(r1, dtype=torch.float).view(batch_size, -1)
s1 = torch.tensor(s1, dtype=torch.float)
def critic_learn():
a1 = self.target_actor(s1).detach()
y_true = r1 + gamma * self.target_critic(s1, a1).detach()
y_pred = self.eval_critic(s0, a0)
loss_fn = nn.MSELoss()
loss = loss_fn(y_pred, y_true)
self.critic_optim.zero_grad()
loss.backward()
self.critic_optim.step()
def actor_learn():
loss = -torch.mean(self.eval_critic(s0, self.eval_actor(s0)))
self.actor_optim.zero_grad()
loss.backward()
self.actor_optim.step()
def soft_update(net_target, net, tau):
for target_param, param in zip(net_target.parameters(), net.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
critic_learn()
actor_learn()
soft_update(self.target_critic, self.eval_critic, tau)
soft_update(self.target_actor, self.eval_actor, tau)
ac = AC()
returns = []
for i in range(episodes):
s = env.reset()
episode_reward_sum = 0
for step in range(500):
# 开始一个episode (每一个循环代表一步)
#env.render()
a = ac.choose_action(s)
s_, r, done, info = env.step(a)
ac.store_transition(s, a, r, s_)
episode_reward_sum += r
s = s_
ac.learn()
returns.append(episode_reward_sum)
print('episode%s---reward_sum: %s' % (i, round(episode_reward_sum, 2)))
plt.figure()
plt.plot(range(len(returns)),returns)
plt.xlabel('episodes')
plt.ylabel('avg score')
plt.savefig('./plt_ddpg.png',format= 'png')
边栏推荐
猜你喜欢
C language Getting Started Guide

优先队列PriorityQueue (大根堆/小根堆/TopK问题)
C language Getting Started Guide
.Xmind文件如何上传金山文档共享在线编辑?
Custom RPC project - frequently asked questions and explanations (Registration Center)
ABA问题遇到过吗,详细说以下,如何避免ABA问题
撲克牌遊戲程序——人機對抗

1. Preliminary exercises of C language (1)

仿牛客技术博客项目常见问题及解答(二)
Cookie和Session的区别
随机推荐
1. C language matrix addition and subtraction method
9. Pointer (upper)
[during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission
js判断对象是否是数组的几种方式
Zatan 0516
Mode 1 two-way serial communication is adopted between machine a and machine B, and the specific requirements are as follows: (1) the K1 key of machine a can control the ledi of machine B to turn on a
Programme de jeu de cartes - confrontation homme - machine
3. C language uses algebraic cofactor to calculate determinant
[modern Chinese history] Chapter 6 test
3. Input and output functions (printf, scanf, getchar and putchar)
[au cours de l'entrevue] - Comment expliquer le mécanisme de transmission fiable de TCP
Redis实现分布式锁原理详解
C language to achieve mine sweeping game (full version)
7-5 走楼梯升级版(PTA程序设计)
[面試時]——我如何講清楚TCP實現可靠傳輸的機制
简述xhr -xhr的基本使用
强化学习系列(一):基本原理和概念
关于双亲委派机制和类加载的过程
仿牛客技术博客项目常见问题及解答(三)
7-7 7003 组合锁(PTA程序设计)