当前位置:网站首页>强化学习系列(一):基本原理和概念
强化学习系列(一):基本原理和概念
2022-07-06 09:21:00 【zhugby】
目录
一、什么是强化学习?
这几年强化学习在学术界是非常的火热,想必大家或多或少都听过这个名词。什么是强化学习呢?强化学习是机器学习领域的一个分支,指的是agent在与环境的互动过程中为了达成一个目标而进行的学习过程。以TSP问题为例:agent是旅行商,他观察环境environment变化(要访问的客户点的地理位置地图)根据当前自己所处的state(也就是自己当前所处的位置)做出action(下一个要访问的节点位置),每做出一个action,environment都会发生变化,agent会得到一个新的state,然后选择新的action不断执行下去。处于当前的state选择action的依据是Policy,为各个action分配选择的概率。通常来说TSP问题的目标是使得路径距离最短,那么reward就可以设置为两个节点之间的距离的负数,训练的目的goal是使得路径的总reward和最大。
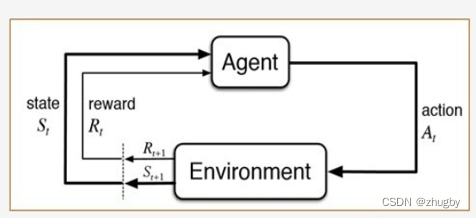
二、强化学习的结构
那我们简单梳理一下强化学习的基本元素及关系,将上面常见的图改一改,把强化学习的结构分为三层如下所示:
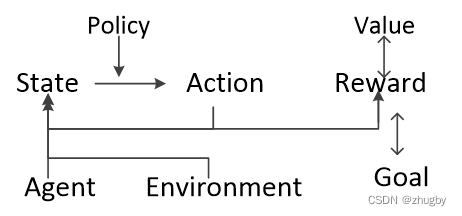
第一层:
agent:执行动作的主体
environment:强化学习所处的环境
goal:强化学习的目标
强化学习是agent在与环境的互动过程中为了达成一个目标而进行的学习过程。
第二层:
state:当前agent的状态
action:执行的动作/行为
reward:执行动作得到的实时的奖励
state和action的循环往复过程构成了强化学习的主体部分。
需要注意的是:reward与 goal不是同一个概念,reward是执行某一个动作之后得到的实时的奖励,goal是强化学习最终的目标(一般来说使reward之和最大),但goal决定了reward。
第三层:
也是核心元素,包括两个函数,价值函数(Value function)和策略函数(Policy function)。下一节中详细介绍。
三、价值函数
1)Policy function:
Policy决定了某个state下应该选取哪一个action,也就是说,状态时Policy的输入,action是Policy的输出。策略Policy为每一个动作分配概率,例如:π(s1|a1) = 0.3,说明在状态s1下选择动作a1的概率是0.3,而该策略只依赖于当前的状态,不依赖于以前时间的状态,因此整个过程也是一个马尔可夫决策过程。强化学习的核心和训练目标就是要选择一个合适的Policy/ ,使得reward之和
,使得reward之和 最大。
最大。
2)Value function:
价值函数分为两种,一种是V状态价值函数(state value function),一种是Q状态行动函数(state action value function)。Q值评估的是动作的价值,代表agent做了这个动作之后一直到最终状态奖励总和的期望值;V值评估的是状态的价值,代表agent在这个状态下一直到最终状态的奖励总和的期望。价值越高,表示我从当前状态到最终状态能获得的平均奖励将会越高,因此我选择价值高的动作就可以了。
通常情况下来说,状态价值函数V是针对特定策略定义的,因为计算奖励的期望值取决于选取各个action的概率。状态行动函数V表面上与策略policy没什么关系,他取决于状态转移概率,但在强化学习中状态转移函数一般不变。要注意,Q值和V值之间可以互相转化。
3)Q与V之间的转化
一个状态的V值,就是这个状态下所有动作的Q值在Policy下的期望,用公式表示为:
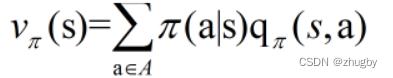
一个动作的Q值,就是执行动作后转移到的新的状态 的V值的期望加上实时的reward值。用公式表示为:
的V值的期望加上实时的reward值。用公式表示为:
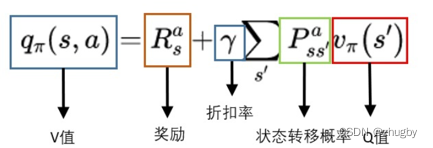
总结一下,状态S的价值是子节点动作action的Q值期望;动作act的价值是子节点状态S的V值期望。不同的策略Policy下,计算出来的期望Q、V是不一样的 ,因此可以通过价值函数来评估Policy的质量。
3)Q值更新——贝尔曼公式
强化学习的过程就是在不断的更新价值Q的过程,也就是贝尔曼公式:
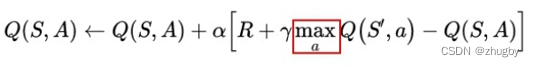
其中![]() 代表的是Q的现实值;γ是折扣系数,位于[0,1)之间,表示模型的远见程度,γ越小,意味着当下的reward越比未来的重要;
代表的是Q的现实值;γ是折扣系数,位于[0,1)之间,表示模型的远见程度,γ越小,意味着当下的reward越比未来的重要; 是学习率;
是学习率;![]() 是Q的估计值;Q更新等于Q估计值加上学习率乘以真实值减去估计值的差距。
是Q的估计值;Q更新等于Q估计值加上学习率乘以真实值减去估计值的差距。
四、强化学习的特点:
1.trial and error(试错学习)
在不断试错中学习经验,对好的行为赋予更高的奖励。
2.delayed reward(延迟奖励)
选择action的时候,考虑的不是实时的reward值,而是考虑该动作之后一直到最终状态奖励总和的期望值Q,选择Q值最大的动作。
五、强化学习的优点:
1.在建模难、建模不准确的问题方面,RL可以通过Agent与环境的不断交互,学习到最优策略;
2.在传统方法难以解决高维度的问题方面,RL提供了包括值函数近似以及直接策略搜索等近似算法;
3.在难以求解动态与随机性质问题方面,RL可在Agent与环境之间的交互以及状态转移过程中加入随机因素;
4.跟监督学习相比,克服了需要大量标注数据集的约束,求解速度快,适合解决现实大规模问题;
5.可迁移学习,泛化能力强,对未知数和扰动具有鲁棒性。
对于OR领域来说,很多组合优化问题(TSP、VRP、MVC等)都可以变成序列决策/马尔可夫决策问题,与强化学习的“动作选择”具有天然动作相似的特征,且RL的“离线训练,在线求解”使得组合优化的在线实时求解成为可能。近年来涌现出很多强化学习解决组合优化问题的新方法,为运筹优化的研究提供了新视角,也成为OR领域的一大研究热点。
囿于本人水平有限,以上内容是在翻阅文献、知乎、B站视频之后根据自己的理解总结和概括的,欢迎大家指出错误!
边栏推荐
- [the Nine Yang Manual] 2016 Fudan University Applied Statistics real problem + analysis
- View UI plus releases version 1.1.0, supports SSR, supports nuxt, and adds TS declaration files
- Service ability of Hongmeng harmonyos learning notes to realize cross end communication
- 稻 城 亚 丁
- 最新坦克大战2022-全程开发笔记-3
- Implement queue with stack
- 魏牌:产品叫好声一片,但为何销量还是受挫
- 4.二分查找
- 9.指针(上)
- Differences and application scenarios between MySQL index clock B-tree, b+tree and hash indexes
猜你喜欢

Tyut Taiyuan University of technology 2022 "Mao Gai" must be recited
1.C语言矩阵加减法
TYUT太原理工大学2022数据库大题之E-R图转关系模式

C语言实现扫雷游戏(完整版)

优先队列PriorityQueue (大根堆/小根堆/TopK问题)
3.输入和输出函数(printf、scanf、getchar和putchar)
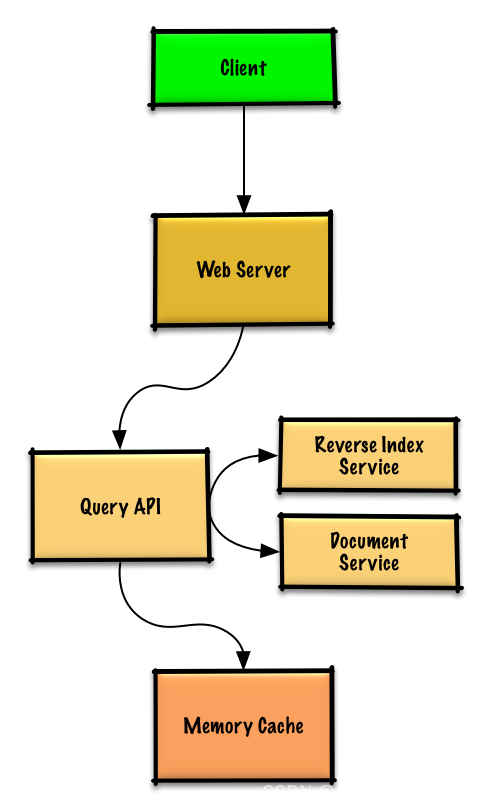
Design a key value cache to save the results of the most recent Web server queries

IPv6 experiment
hashCode()与equals()之间的关系
C language to achieve mine sweeping game (full version)
随机推荐
2. C language matrix multiplication
5. Function recursion exercise
2.C语言矩阵乘法
MySQL limit x, -1 doesn't work, -1 does not work, and an error is reported
The latest tank battle 2022 - full development notes-3
Questions and answers of "Fundamentals of RF circuits" in the first semester of the 22nd academic year of Xi'an University of Electronic Science and technology
3. C language uses algebraic cofactor to calculate determinant
1. C language matrix addition and subtraction method
Differences and application scenarios between MySQL index clock B-tree, b+tree and hash indexes
MySQL Database Constraints
C语言实现扫雷游戏(完整版)
编写程序,模拟现实生活中的交通信号灯。
(超详细二)onenet数据可视化详解,如何用截取数据流绘图
受检异常和非受检异常的区别和理解
(ultra detailed onenet TCP protocol access) arduino+esp8266-01s access to the Internet of things platform, upload real-time data collection /tcp transparent transmission (and how to obtain and write L
20220211-CTF-MISC-006-pure_ Color (use of stegsolve tool) -007 Aesop_ Secret (AES decryption)
最新坦克大战2022-全程开发笔记-1
Implement queue with stack
Inheritance and polymorphism (I)
vector