当前位置:网站首页>这次,彻底搞清楚MySQL索引
这次,彻底搞清楚MySQL索引
2022-07-06 09:20:00 【李孛欢】
目录
一:索引的基本概述
废话不多说,直接看官方给索引的定义:一种帮助mysql提高查询效率的数据结构。因此索引优点是:大大地加快了数据查询的速度!!不过,索引还有它的缺点:
- 维护索引需要耗费数据库的资源
- 索引需要磁盘的空间
- 当对表的数据进行增删改的时候,因为要维护索引,速度会受到影响
再看索引的分类(innodb):主键索引:设定为主键后数据库会自动为其建立索引,innodb为聚簇索引。单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。唯一索引:索引的值必须唯一,但是允许有空值。复合索引:即一个索引包含多个列。主键索引的索引列值不能为空,而唯一索引的索引列值可以为空。
最后我们来看看索引的基本操作,首先我们来看主键索引,它是自动创建的。我们在数据库中创建一个user表,再来看它的索引。可以看到索引名字Key_name是PRIMARY,索引类型是BTREE,这里是B+树,并不是B树。
--主键索引在建表时自动创建--
create table user(id varchar(20) primary key, name varchar(20));
------
show index from user;
再来看普通索引(单值索引),创建有两种方式,一种是建表的时候创建,一种是建表之后创建。上面的user表已经建立,我们先看看怎么给name字段加上索引。可以用下面的sql语句,结果如下。
CREATE index name_index on user(name);
------
show index from user;
我们也可以在创建表的时候来创建普通索引,建表时创建索引是不能主动指定索引名的,默认与字段名一致,创建方法及结果如下所示。
create table teacher(id varchar(20) primary key, name varchar(20),key(name));
------
show index from teacher;
然后我们再来看唯一索引,其也可以建表时和建表后创建,与普通索引创建类似,只不过是用了unique关键字,如图所示,分别为建表时和建表后。注意唯一索引Null时YES,也就是索引列值可以为空。
create table teacher2(id varchar(20) primary key, name varchar(20),unique(name));
------
show index from teacher2;
create table teacher3(id varchar(20) primary key, name varchar(20));
create unique index name_index on teacher3(name);
show index from teacher3;
最后我们来看复合索引的创建,它是基于多个列共同创建一个索引,它和普通索引创建方式差不多,建表时创建就是key(name,age,bir),建表后创建就是create index name_index on user(name,age,bir),具体就不演示了。注意一个点,创建索引的时候name,age,bir是有顺序和数量的,利用索引的时候首先需要符合最左前缀原则。顾名思义,就是以最左边的为起点任何连续的索引都能匹配上。另外,mysql引擎在查询时为了更好的利用索引会动态调整查询字段顺序,以便利用索引。比如上面这种情况,如果只有最左前缀原则的话,那查询时只有基于name和name,age以及name,age,bir可以利用到索引。那么引入动态调整后,bir,age,name和name,bir,age也是可以用到索引的,只要包含了最左前缀即可。
二:索引的底层原理——B+树解析
首先我们思考一个问题,我们在数据库中查询某个数据,是在一个有序的集合中查询快还是一个无序的集合中查询快? 在一个无序的集合中我们可能运气好,一次就找到了,但是也有可能运气差,遍历整个集合最后才查找到,如果数据库的数据量很大,这是很不稳定且速度慢的。而如果是一个有序集合,我们查询的次数和速度都是比较稳定的,且相比无序集合速度更快。因此MySQL会根据索引主键值对数据进行排序,并且使用指针将其连接。可以看到底层的索引节点分为三部分:主键值,具体数据,指向下一个节点的指针。

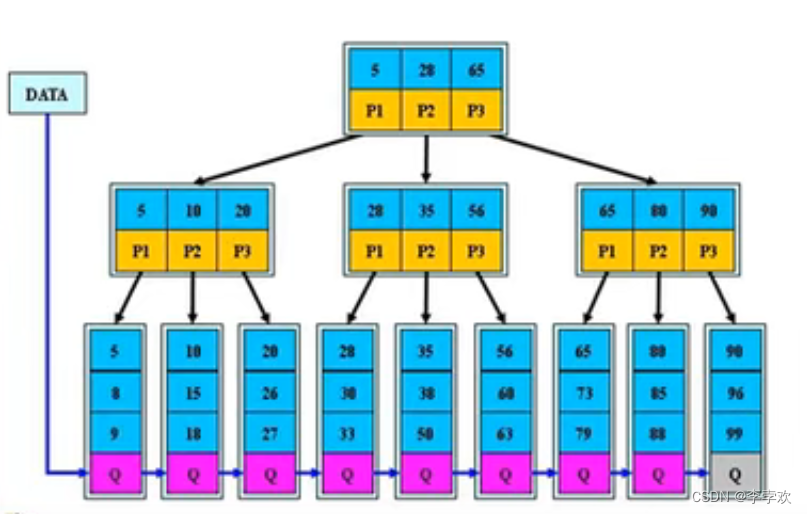
不过问题来了,这样就形成了一个链表结构,如下图所示,我们知道链表查询的时间复杂度是O(n),这对于海量数据的查询是非常慢的。所以MySQL对其又进行了优化,按页存储数据,默认存储16KB,然后做一个页目录,根据页目录来查询数据,如下图所示。页目录是不存储具体数据的,它主要存储每页第一个节点的主键值和指针。这样一来,我们查找数据首先去页目录里面找,根据主键值和指针,再定位到具体的数据,这样就可以提高查询效率了。当数据量过高的时候,我们可以给页目录增加页目录,这样就可以存储更多的数据了!上面这种结构就是B+树。

下面我们来看一下,这种设计能够存储多少数据。我们先看2层的B+树,即根节点和若干个叶子节点,每个节点就是我们上面说的一页。先看根节点,其内部结构为:主键+指针。每页数据16KB,一般表的类型为INT(占用4个字节)或者BIGINT(8个字节),指针大小再innodb源码中设置为6字节,我们取主键为8字节。这样的话,根节点就可以存储16KB/(8B+6B) = 1170个指针,而每个指针指向一页。再看每页能够存多少条数据,每条数据由主键+指针+数据值,我们按小了算,每页16KB存储20条数据。这样的话,2层的B+树就能够存储1170 * 20 = 23400条数据。三层就是两层页目录加叶子节点,能够存储 1170 * 1170 * 20 = 27,378,000 条数据,达到千万级别。四层就可以达到百亿级别的数据。
下面我们再具体看看B+树的一些介绍,以及为什么不选择B树作为索引的数据结构。B+树是对B树的优化,我们先来看看B树。
B树是一种自平衡树,一个m阶的B树,会满足一些特征,包括B树的阶就是节点最多包含子节点的个数,每个非叶子节点会包含关键字信息还有指针信息,最重要的是B树的搜索可能在非叶子节点结束,B树的搜索从根节点开始根据关键字进行二分查找,如果在非叶子节点命中则结束,否则就通过指针继续往下查找。而B+树的搜索过程与B树基本相同,区别在于B+树只有在叶子节点搜索到了才结束,所有的关键字都会出现在叶子节点所组成的链表中,且链表的关键字从左往右是有序的。非叶子节点相当于是叶子节点的索引,不是具体的数据。B+树如下图所示。
可以看到,B树的非叶子节点也会存储数据data,这样的话,根据我们上面的计算,每个页目录(16KB)能够存储的指针个数就会减少,那么存储同样的数据量,B树的层数就可能高于B+树!!这样就会增加磁盘IO的次数(每查询一个节点(页)就会进行一次磁盘IO),I/O读写次数是影响索引检索效率的主要因素,进而影响查询的效率。另外,B树在基于范围查询的操作上的性能没有B+树好,因为B+树的叶子节点使用了指针顺序的链接在一起,只要遍历叶子节点就可以实现整棵树的遍历,相比较B+树来说,由于B树的叶子节点是相互独立的,所以对于范围查询,需要从根节点再次出发查询,增加了磁盘I/O操作次数。最后,B+树的增删文件(节点)时,效率更高,因为B+树的叶子节点包含了所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
MySQL的innodb存储引擎在设计时是将根节点常驻内存的,也就是查找某一键值的行记录最多只需要1-3次磁盘IO操作(3层B+树)。主键索引最多两次IO就可以找到,普通索引会先找到主键索引再进行查找,所以会多一次磁盘IO。
AVL树相较于B树效率就更低了,第一是每个节点存储的数据量太少,第二是树的高度更高,磁盘IO次数就更高了。那么为啥不能用哈希表作为索引的数据结构呢? 主要有以下几种原因
- 模糊查找不支持:哈希表是把索引字段映射成对应的哈希码然后再存放在对应的位置, 这样的话,如果我们要进行模糊查找的话,显然哈希表这种结构是不支持的,只能遍历这个表。而B+树则可以通过最左前缀原则快速找到对应的数据。
- 范围查找不支持:如果我们要进行范围查找,例如查找 ID 为 1 ~ 500 的人,哈希表同样不支持,只能遍历全表
- 哈希冲突问题:索引字段通过哈希映射成哈希码,如果很多字段都刚好映射到相同值的哈希码的话,那么形成的索引结构将会是一条很长的链表,这样的话,查找的时间就会大大增加
三:聚簇索引和非聚簇索引
先看定义,聚簇索引:将数据存储和索引放到了一块,索引结构的叶子节点保存了行数据。非聚簇索引:将数据和索引分开存储,索引结构叶子节点指向了数据对应的位置。说白了咱们上面画的那种索引就是聚簇索引,将数据存储和索引放到了一块!!聚簇索引不一定是主键索引,主键索引一定是聚簇索引。实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引,剩下的都是非聚簇索引,非聚簇索引可以理解为建立在非聚簇索(辅助索引)引之上的索引。辅助索引叶子节点存储的不再是行的物理位置,而是主键值,辅助索引访问数据总是要进行二次查找。如下图所示。
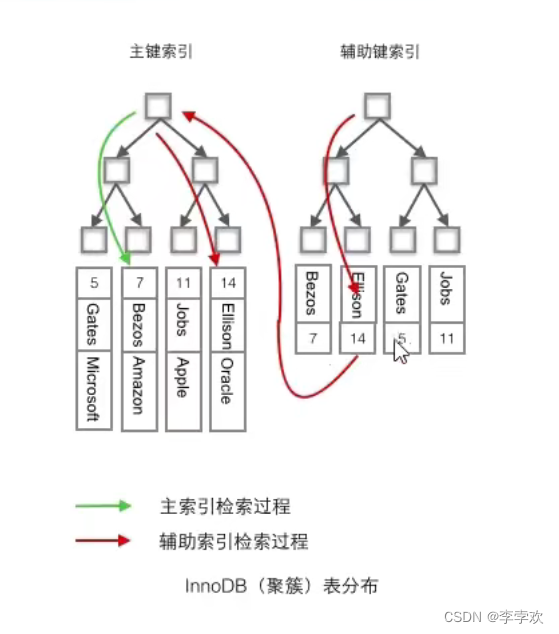
- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id=14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
- 若对Name列进行条件搜索,则需要两个步骤∶第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)。
- 聚簇索引默认是主键,如果表中没有定义主键,InnoDB会选择一个唯一且非空的索引代替。
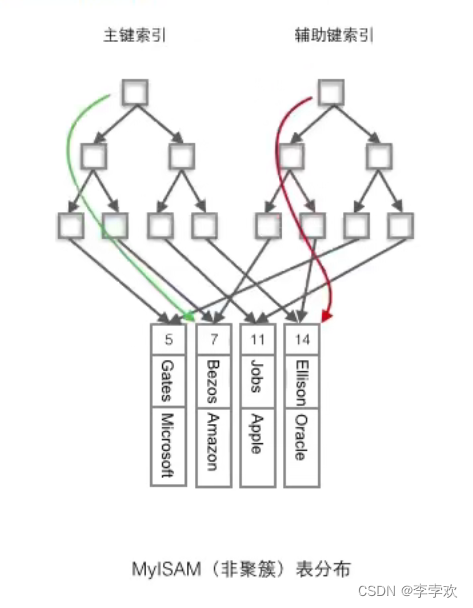
MyISAM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
那么问题来了,每次使用辅助索引检索都要经过两次B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗?聚簇索引的优势在哪?
- 由于行数据和聚簇的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问时,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键ID来组织数据,获得数据更快。
- 辅助索引的叶子节点,存储主键值,而不是数据的存放地址。好处是索引的维护成本更低,当行数据发生变化时,索引树的节点也需要分裂变化,或者是我们需要查找的数据,在上一次IO读写的缓存中没有,需要发生一次新的IO操作时,可以避免对辅时索引的维护工作,只需要维护聚簇索引树就行了。另一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用存储空间大小。
四:无法利用索引的情况
- 查询语句中使用LIKE关键字:在查询语句中使用LIKE 关键字进行查询时,如果匹配字符串的第一个字符为"%",索引不会被使用。如果"%""不是在第一个位置,索引就会被使用
- 查询语句中使用多列索引(复合索引):多列索引是在表的多个字段上创建一个索引,只有查询条件中使用了这些字段中的第一个字段,索引才会被使用。
- 查询语句中使用OR关键字:查询语句只有OR关键字时,如果OR前后的两个条件的列都是索引,那么查询中将使用索引。如果OR前后有一个条件的列不是索引,那么查询中将不使用索引。
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引
如果觉得对你有帮助,可以给博主点个赞加个关注~~~
边栏推荐
- 167. Sum of two numbers II - input ordered array - Double pointers
- View UI plus releases version 1.1.0, supports SSR, supports nuxt, and adds TS declaration files
- The latest tank battle 2022 - full development notes-3
- 凡人修仙学指针-2
- Redis cache obsolescence strategy
- String abc = new String(“abc“),到底创建了几个对象
- vector
- 西安电子科技大学22学年上学期《信号与系统》试题及答案
- 20220211-CTF-MISC-006-pure_ Color (use of stegsolve tool) -007 Aesop_ Secret (AES decryption)
- 5. Download and use of MSDN
猜你喜欢
C语言入门指南
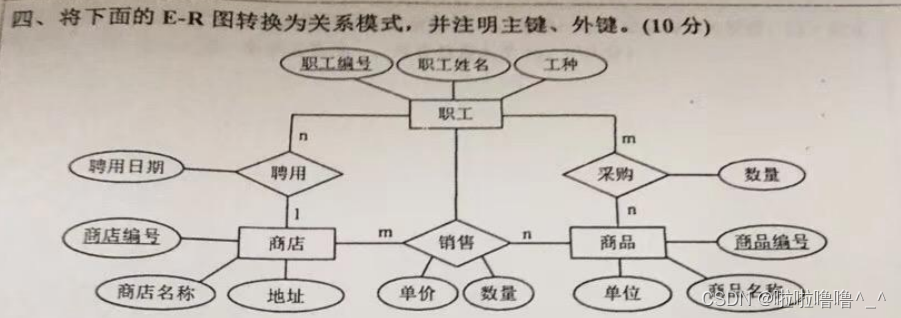
TYUT太原理工大学2022数据库大题之E-R图转关系模式
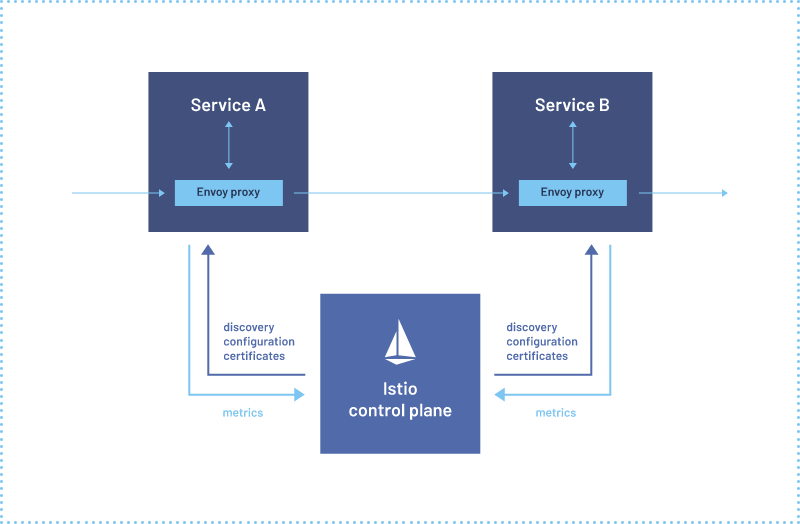
Alibaba cloud microservices (IV) service mesh overview and instance istio

5.MSDN的下载和使用
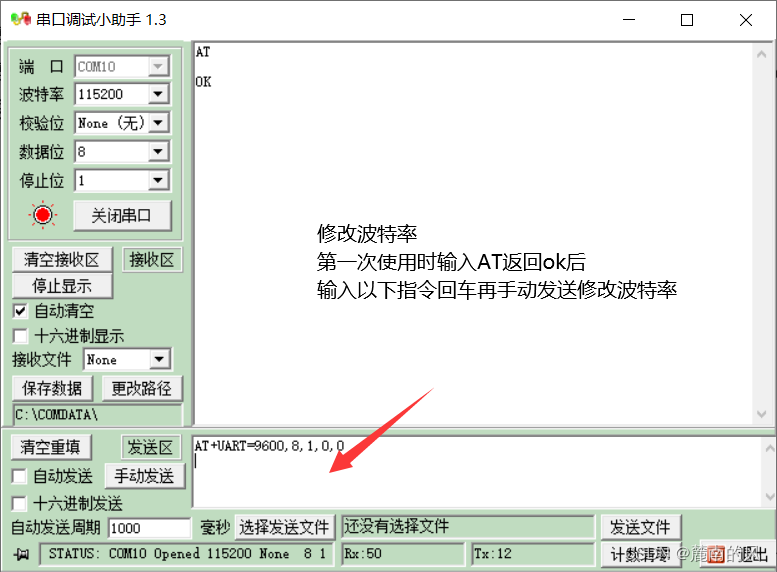
(超详细onenet TCP协议接入)arduino+esp8266-01s接入物联网平台,上传实时采集数据/TCP透传(以及lua脚本如何获取和编写)

Tyut Taiyuan University of technology 2022 "Mao Gai" must be recited
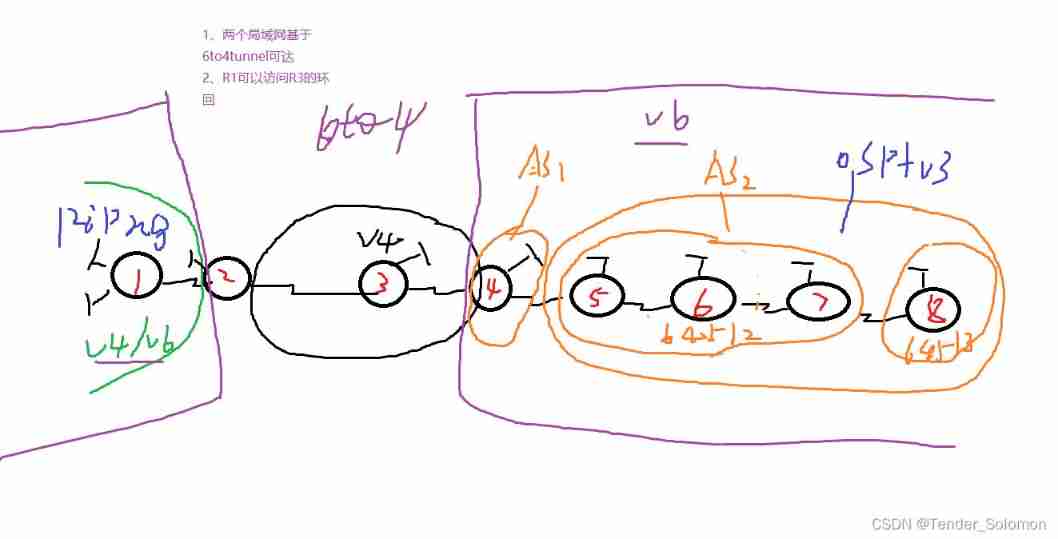
IPv6 experiment

There is always one of the eight computer operations that you can't learn programming

View UI Plus 发布 1.2.0 版本,新增 Image、Skeleton、Typography组件
System design learning (I) design pastebin com (or Bit.ly)
随机推荐
Questions and answers of "basic experiment" in the first semester of the 22nd academic year of Xi'an University of Electronic Science and technology
Cloud native trend in 2022
3.C语言用代数余子式计算行列式
TYUT太原理工大学2022数据库考试题型大纲
The latest tank battle 2022 full development notes-1
2.C语言初阶练习题(2)
(超详细onenet TCP协议接入)arduino+esp8266-01s接入物联网平台,上传实时采集数据/TCP透传(以及lua脚本如何获取和编写)
(super detailed II) detailed visualization of onenet data, how to plot with intercepted data flow
9. Pointer (upper)
Introduction pointer notes
用栈实现队列
[中国近代史] 第九章测验
162. Find peak - binary search
[中国近代史] 第六章测验
View UI plus releases version 1.1.0, supports SSR, supports nuxt, and adds TS declaration files
8. C language - bit operator and displacement operator
最新坦克大战2022-全程开发笔记-1
4.分支语句和循环语句
Change vs theme and set background picture
【快趁你舍友打游戏,来看道题吧】