当前位置:网站首页>System design learning (I) design pastebin com (or Bit.ly)
System design learning (I) design pastebin com (or Bit.ly)
2022-07-06 13:08:00 【Geometer】
The idea of this project is to study system design recently , I want to sort out what I learned every time , At the same time, it can also help you better understand what I learned .
In fact, I personally feel that the system design is not often tested in domestic interviews , But personally, I think it's very useful , Compared with eight part essay , It has more practical value , Therefore, in the interview in North America, you often get ( Even if it's new grad),anyway, In the spirit of not being particularly utilitarian , I want to learn this course , It should be beneficial in the long run .
Learning how to design scalable systems will help you become a better engineer.
In fact, the essence of system design should be to find trade off The process of
Just to give you an example , With CAP Take the principle as an example :
Consistency - Every read receives the most recent write or an error
Availability - Every request receives a response, without guarantee that it contains the most recent version of the information
Partition Tolerance - The system continues to operate despite arbitrary partitioning due to network failures
The network cannot meet these three conditions at the same time , So you need to consistency and availability Find one of them trade off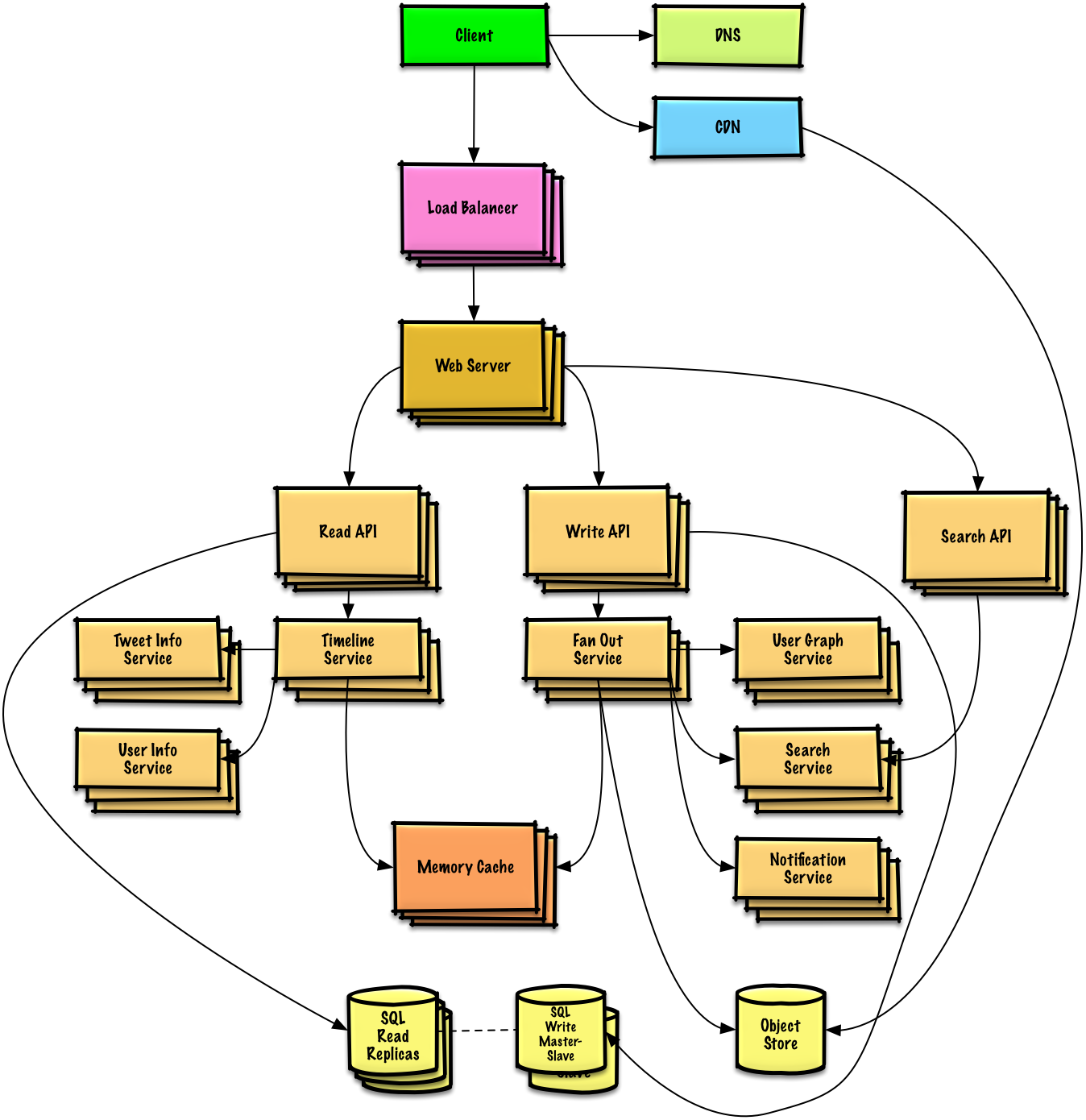
The following link can help you
scalability
Design Pastebin.com (or Bit.ly)
Let's take a look at the title requirements first
We’ll scope the problem to handle only the following use cases:
User enters a block of text and gets a randomly generated link Expiration
Default setting does not expire
Can optionally set a timed expiration
User enters a paste’s url and views the contents
User is anonymous
Service tracks analytics of pages Monthly visit stats
Service deletes expired pastes Service has high availability
Out of scope User:
registers for an account
User verifies email
User logs into a registered account
User edits the document
User can set visibility
User can set the shortlink
Constraints and assumptions:
State assumptions
Traffic is not evenly distributed
Following a short link should be fast
Pastes are text only
Page view analytics do not need to be realtime 10 million
users 10 million paste writes per month 100
million paste reads per month 10:1 read to write ratio
After getting the title, we can get :
1 KB content per paste
shortlink - 7 bytes
expiration_length_in_minutes - 4 bytes
created_at - 5 bytes
paste_path - 255 bytes
total = ~1.27 KB
That is to say, each piece of data will probably consume 1.27KB Resources for
so
It will consume about every month 12.7GB
It can also be calculated that about four write operations are performed per second , Forty read operations
After getting these basic information, we can use it in system design !
Draw what you need outline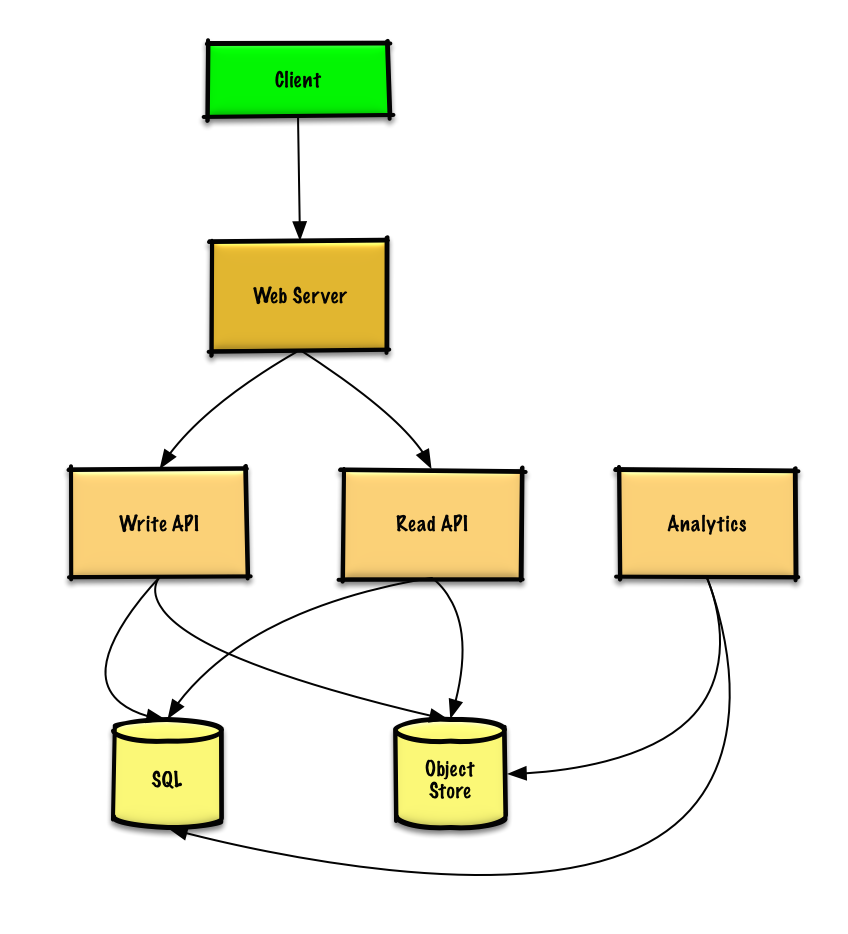
The next step is to start the formal design :
Let's look at the first one case:User enters a block of text and gets a randomly generated link Expiration
Therefore, there should be a relational database to store as a hash table url A mapping to a file , But beyond that NoSQL It can also act as a hash table , About whether to use relational or non relational database , I think we still need to find one trade off, The following discussion is based on relational database :
client Send a create request to web server, Run the reverse proxy
web server request write api server
write api server The following operations have been done :
1. Generate a url( Check url Does it exist in hash table , If there is , Regenerate a , otherwise , Storage , If it supports user creation url Words , It can also not be generated url Switch to the user's url, Of course, it also needs to be checked )
2. preservation SQL database
3. Save to Object Store
4. Go back to this url
First, define the table structure of the database
shortlink char(7) NOT NULL//url
expiration_length_in_minutes int NOT NULL// Expiration time
created_at datetime NOT NULL// Creation time
paste_path varchar(255) NOT NULL// route , It's a hash table Of value
PRIMARY KEY(shortlink)
Set the primary key to shortlink Create an index back , The database uses this index to enforce uniqueness , Besides, it can also be found in create_at Create an additional index on the field to speed up the search , And save these data in memory to speed up the search
In order to generate url, have access to ip+ The timestamp is hashing , Reuse Base 62 Encoding , Take before 7 Bits as output ,62^7 Probably able to map 36 Billion relationship
url = base_encode(md5(ip_address+timestamp))[:URL_LENGTH]
Use a common REST API
$ curl -X POST --data '{ "expiration_length_in_minutes": "60", \
"paste_contents": "Hello World!" }' https://pastebin.com/api/v1/paste
Returnee
{
"shortlink": "foobar"
}
Use case: User enters a paste’s url and views the contents
client Send a request to web server
web server call read api
read api Do the following :
Check sql Of url, If url In a relational database , Then we find value, otherwise , Return error
Use case: Service tracks analytics of pages
Because real-time analysis is not required , So we can simply use MapReduce To make statistics
class HitCounts(MRJob):
def extract_url(self, line):
"""Extract the generated url from the log line."""
...
def extract_year_month(self, line):
"""Return the year and month portions of the timestamp."""
...
def mapper(self, _, line):
"""Parse each log line, extract and transform relevant lines. Emit key value pairs of the form: (2016-01, url0), 1 (2016-01, url0), 1 (2016-01, url1), 1 """
url = self.extract_url(line)
period = self.extract_year_month(line)
yield (period, url), 1
def reducer(self, key, values):
"""Sum values for each key. (2016-01, url0), 2 (2016-01, url1), 1 """
yield key, sum(values)
Use case: Service deletes expired pastes
If you want to delete expired data , You need to scan the entire database regularly , Find the expired timestamp , Then delete ( The latter is marked as expired )
The above is the basic implementation of the system
Then we need to consider scalability 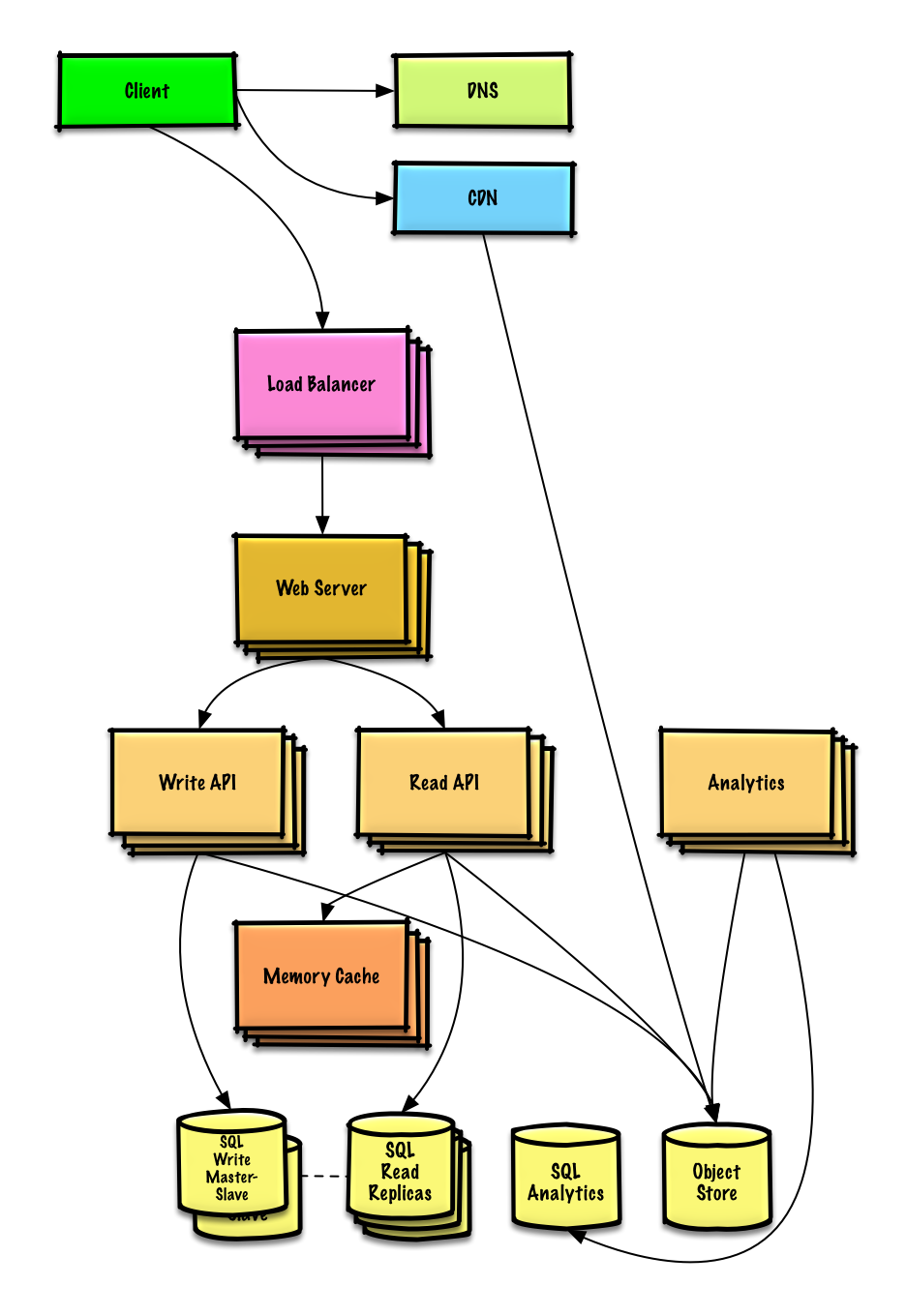
About scalability , I think everyone should have his own opinion , But it is very important to keep repeating the test , Find bottlenecks , There are three steps to find a solution to the bottleneck
It is very important to discuss the bottleneck problem , For example, what problems can be solved by adding load balancing of multiple servers ?CDN? Master slave copy ? How to find between these trade off Well ? There is no standard answer to these things
边栏推荐
- TYUT太原理工大学2022数据库之关系代数小题
- [算法] 剑指offer2 golang 面试题6:排序数组中的两个数字之和
- 167. Sum of two numbers II - input ordered array - Double pointers
- 【无标题】
- 编辑距离(多源BFS)
- [untitled]
- 阿里云微服务(四) Service Mesh综述以及实例Istio
- 121 distributed interview questions and answers
- Comparative analysis of the execution efficiency of MySQL 5.7 statistical table records
- Ten minutes to thoroughly master cache breakdown, cache penetration, cache avalanche
猜你喜欢
系统设计学习(三)Design Amazon‘s sales rank by category feature
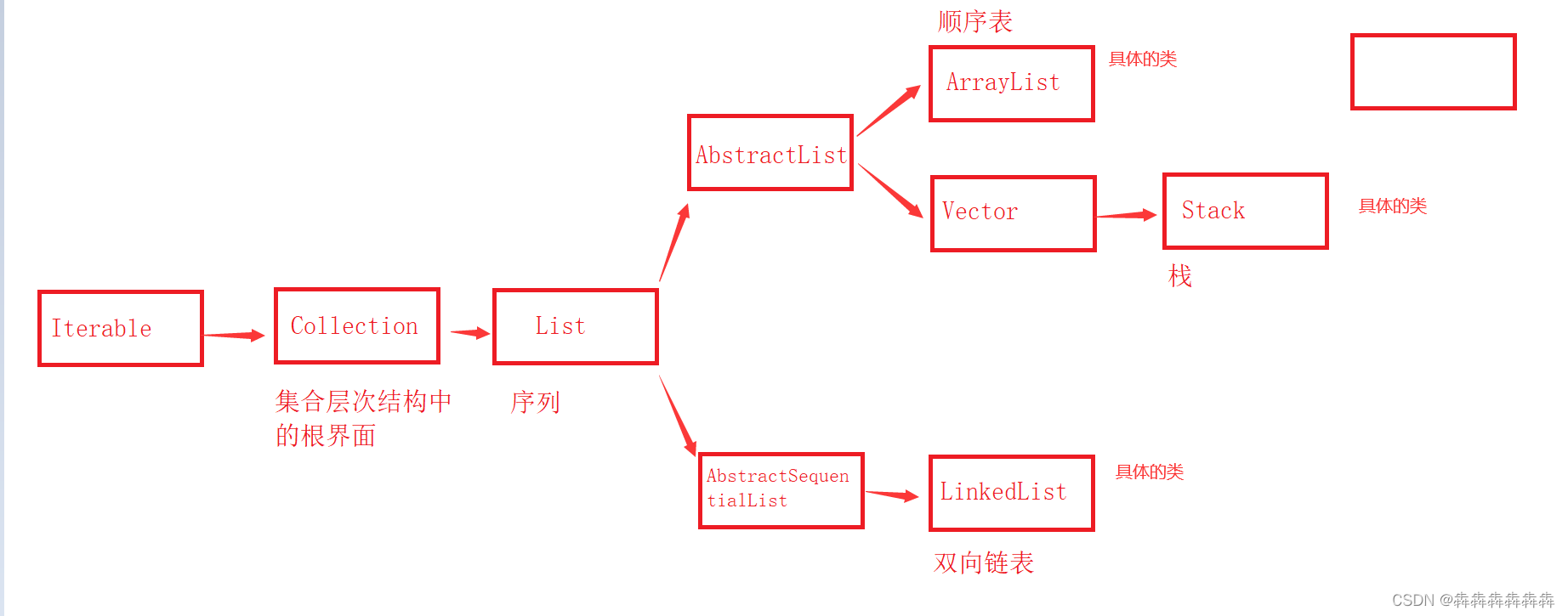
Iterable、Collection、List 的常见方法签名以及含义
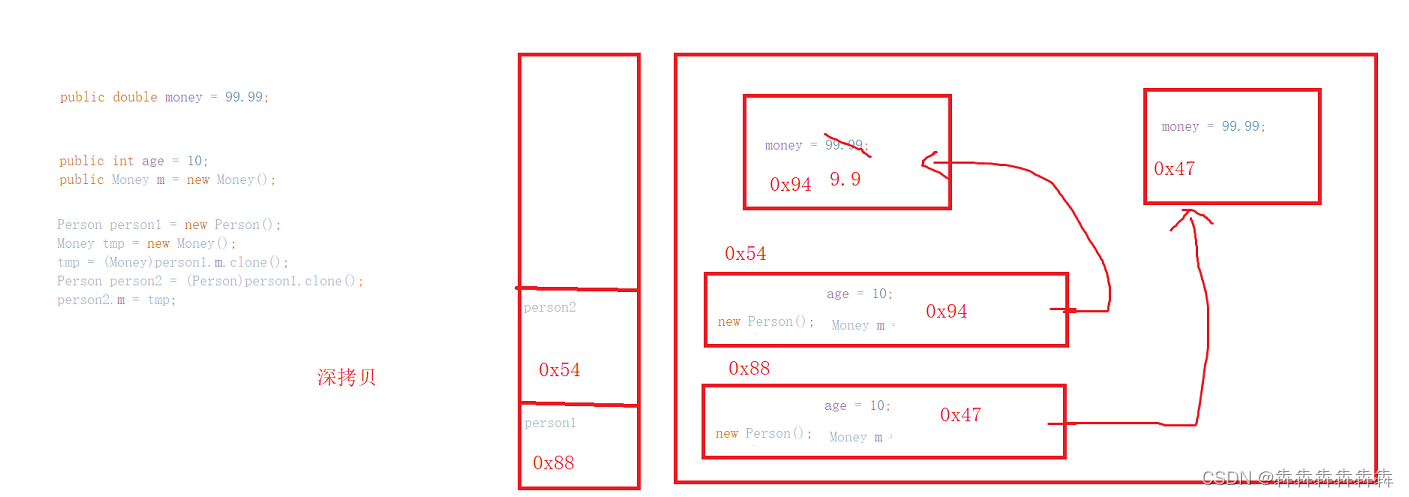
抽象类和接口
阿里云微服务(一)服务注册中心Nacos以及REST Template和Feign Client

服务未正常关闭导致端口被占用
![[algorithm] sword finger offer2 golang interview question 2: binary addition](/img/c2/6f6c3bd4d70252ba73addad6a3a9c1.png)
[algorithm] sword finger offer2 golang interview question 2: binary addition
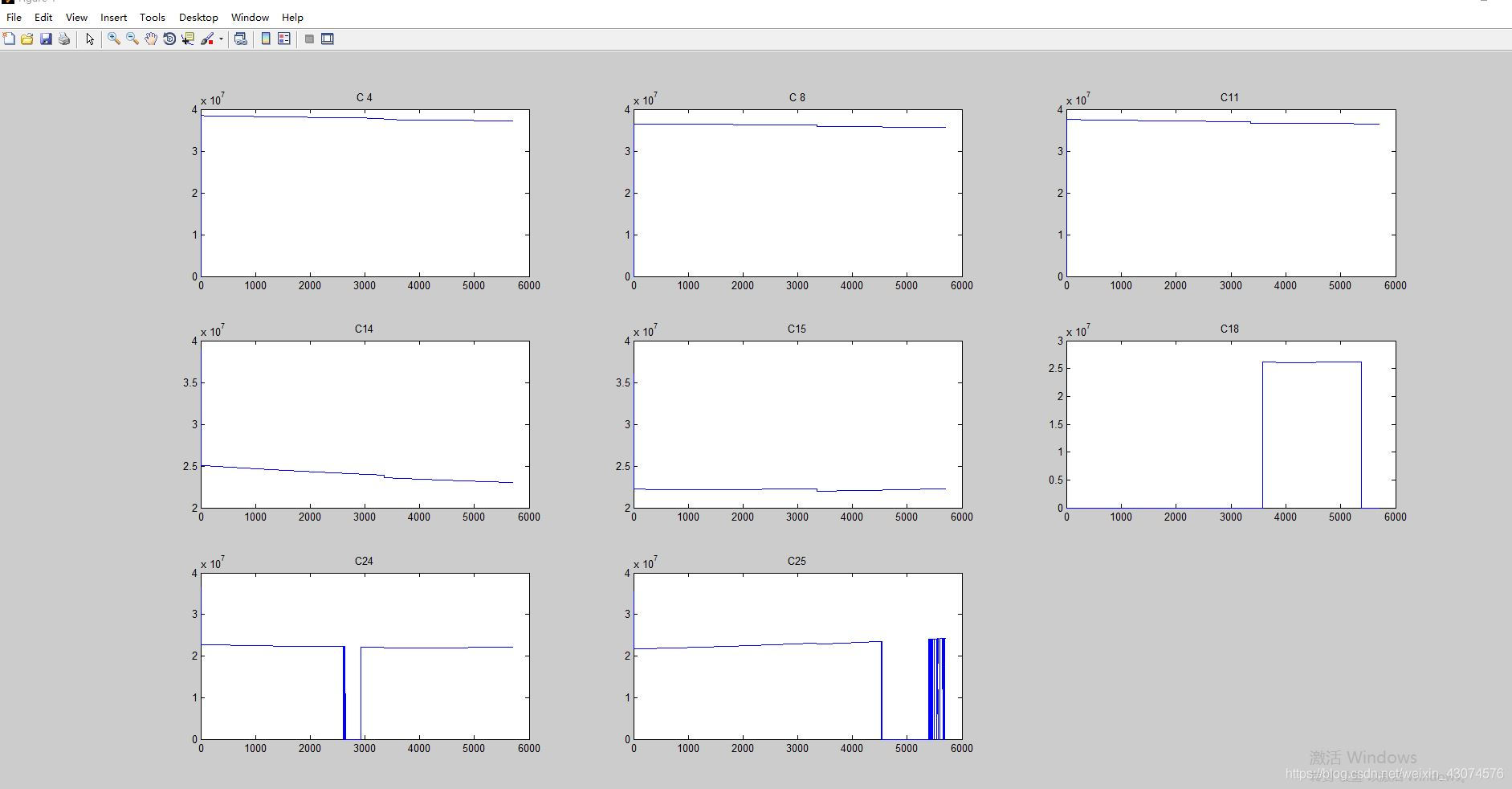
Code example of MATLAB reading GNSS observation value o file
阿里云微服务(三)Sentinel开源流控熔断降级组件
The earth revolves around the sun
![Fundamentals of UD decomposition of KF UD decomposition [1]](/img/e9/564e0163c3756c0ba886913f1cfaef.jpg)
Fundamentals of UD decomposition of KF UD decomposition [1]
随机推荐
Sharing ideas of on-chip transplantation based on rtklib source code
Experience summary of autumn recruitment of state-owned enterprises
【无标题】
Fairygui bar subfamily (scroll bar, slider, progress bar)
[algorithm] sword finger offer2 golang interview question 2: binary addition
[rtklib 2.4.3 B34] version update introduction I
Code example of MATLAB reading GNSS observation value o file
Implementation of Excel import and export functions
TYUT太原理工大学2022数据库大题之分解关系模式
《软件测试》习题答案:第一章
The earth revolves around the sun
167. Sum of two numbers II - input ordered array - Double pointers
闇の連鎖(LCA+树上差分)
[算法] 剑指offer2 golang 面试题9:乘积小于k的子数组
Novatel board oem617d configuration step record
One article to get UDP and TCP high-frequency interview questions!
Itext 7 生成PDF总结
异常:IOException:Stream Closed
基本Dos命令
Answer to "software testing" exercise: Chapter 1