当前位置:网站首页>系统设计学习(三)Design Amazon‘s sales rank by category feature
系统设计学习(三)Design Amazon‘s sales rank by category feature
2022-07-06 09:19:00 【几何学家】
老规矩,先看题
Use cases
We’ll scope the problem to handle only the following use case
Service calculates the past week’s most popular products by category
User views the past week’s most popular products by category
Service has high availability
Out of scope
The general e-commerce site:Design components only for calculating sales rank Constraints and assumptions
State assumptions Traffic is not evenly distributed
Items can be in multiple categories
Items cannot change categories
There are no subcategories ie foo/bar/baz Results must be updated hourly
More popular products might need to be updated more frequently
10 million products
1000 categories
1 billion transactions per month
100 billion read requests per month
100:1 read to write ratio
那么接下来的第一步是进行计算,理清楚,如果要进行粗略的使用情况的计算的话
首先看下每笔交易要用到多大的存储空间
creared_at 5bytes
product_at 8bytes
category_id 4bytes
seller_id 8bytes
buyer_id 8bytes
quantity 4bytes
total_price 5bytes
total 40bytes
因为他说一个月1billion次交易,所以每个月要花费40gb去进行存储这些交易国恒
如果三年的话需要1.44tb进行存储
那么完成粗略的计算之后我们要简单的设计一下这个系统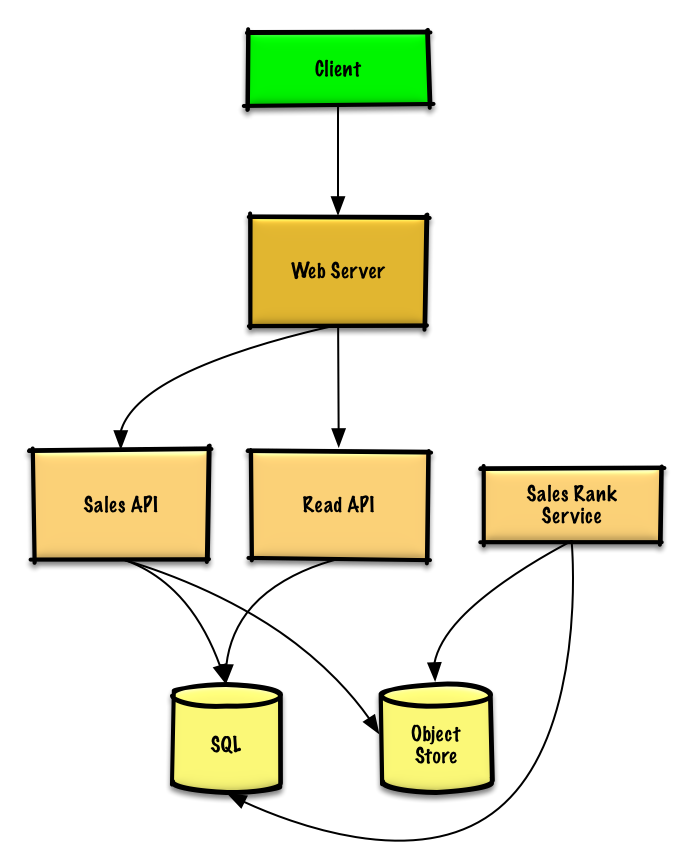
完成了系统轮廓的设计之后我们要进行细节的填充了
首先,既然服务要统计过去一周最受欢迎的商品的话,那他就一定要统计所有的订单的信息,我们可以使用sale api去存储处理好的日志,在Object Store而不是管理我们自己的文件系统
我们假设看到的日志如下
timestamp product_id category_id qty total_price seller_id buyer_id
t1 product1 category1 2 20.00 1 1
t2 product1 category2 2 20.00 2 2
t2 product1 category2 1 10.00 2 3
t3 product2 category1 3 7.00 3 4
t4 product3 category2 7 2.00 4 5
t5 product4 category1 1 5.00 5 6
...
Sales Rank service可以使用sale api打印的日志作为输入数据,然后内部使用mapreduce进行一个分布式日志的统计,最后得出sales_rank等信息存储在一个SQL数据库中
我们将使用一个多部的mapreduce
1.转换数据为 (category, product_id), sum(quantity)
2.进行一个分布式的排序
class SalesRanker(MRJob):
def within_past_week(self, timestamp):
"""Return True if timestamp is within past week, False otherwise."""
...
def mapper(self, _ line):
"""Parse each log line, extract and transform relevant lines. Emit key value pairs of the form: (category1, product1), 2 (category2, product1), 2 (category2, product1), 1 (category1, product2), 3 (category2, product3), 7 (category1, product4), 1 """
timestamp, product_id, category_id, quantity, total_price, seller_id, \
buyer_id = line.split('\t')
if self.within_past_week(timestamp):
yield (category_id, product_id), quantity
def reducer(self, key, value):
"""Sum values for each key. (category1, product1), 2 (category2, product1), 3 (category1, product2), 3 (category2, product3), 7 (category1, product4), 1 """
yield key, sum(values)
def mapper_sort(self, key, value):
"""Construct key to ensure proper sorting. Transform key and value to the form: (category1, 2), product1 (category2, 3), product1 (category1, 3), product2 (category2, 7), product3 (category1, 1), product4 The shuffle/sort step of MapReduce will then do a distributed sort on the keys, resulting in: (category1, 1), product4 (category1, 2), product1 (category1, 3), product2 (category2, 3), product1 (category2, 7), product3 """
category_id, product_id = key
quantity = value
yield (category_id, quantity), product_id
def reducer_identity(self, key, value):
yield key, value
def steps(self):
"""Run the map and reduce steps."""
return [
self.mr(mapper=self.mapper,
reducer=self.reducer),
self.mr(mapper=self.mapper_sort,
reducer=self.reducer_identity),
]
结果是下面的排好序的列表,我们可以将其存入sales_rank表
(category1, 1), product4
(category1, 2), product1
(category1, 3), product2
(category2, 3), product1
(category2, 7), product3
sales_rank表的解构大概如下
id int NOT NULL AUTO_INCREMENT
category_id int NOT NULL
total_sold int NOT NULL
product_id int NOT NULL
PRIMARY KEY(id)
FOREIGN KEY(category_id) REFERENCES Categories(id)
FOREIGN KEY(product_id) REFERENCES Products(id)
我们将在 id 、 category_id 和 product_id 上创建索引以加快查找速度(记录时间而不是扫描整个表)并将数据保存在内存中。
这样的话,当用户想要访问过去一周最受欢迎的产品(每一个类别里面)的时候
client发送请求到webserver,执行反向代理,
webserver直接请求read api,
read api读数据从sql数据库中
我们使用一个公共的rest api
$ curl https://amazon.com/api/v1/popular?category_id=1234
返回:
{
"id": "100",
"category_id": "1234",
"total_sold": "100000",
"product_id": "50",
},
{
"id": "53",
"category_id": "1234",
"total_sold": "90000",
"product_id": "200",
},
{
"id": "75",
"category_id": "1234",
"total_sold": "80000",
"product_id": "3",
},
接下来的话就是对现有的结构进行一个扩展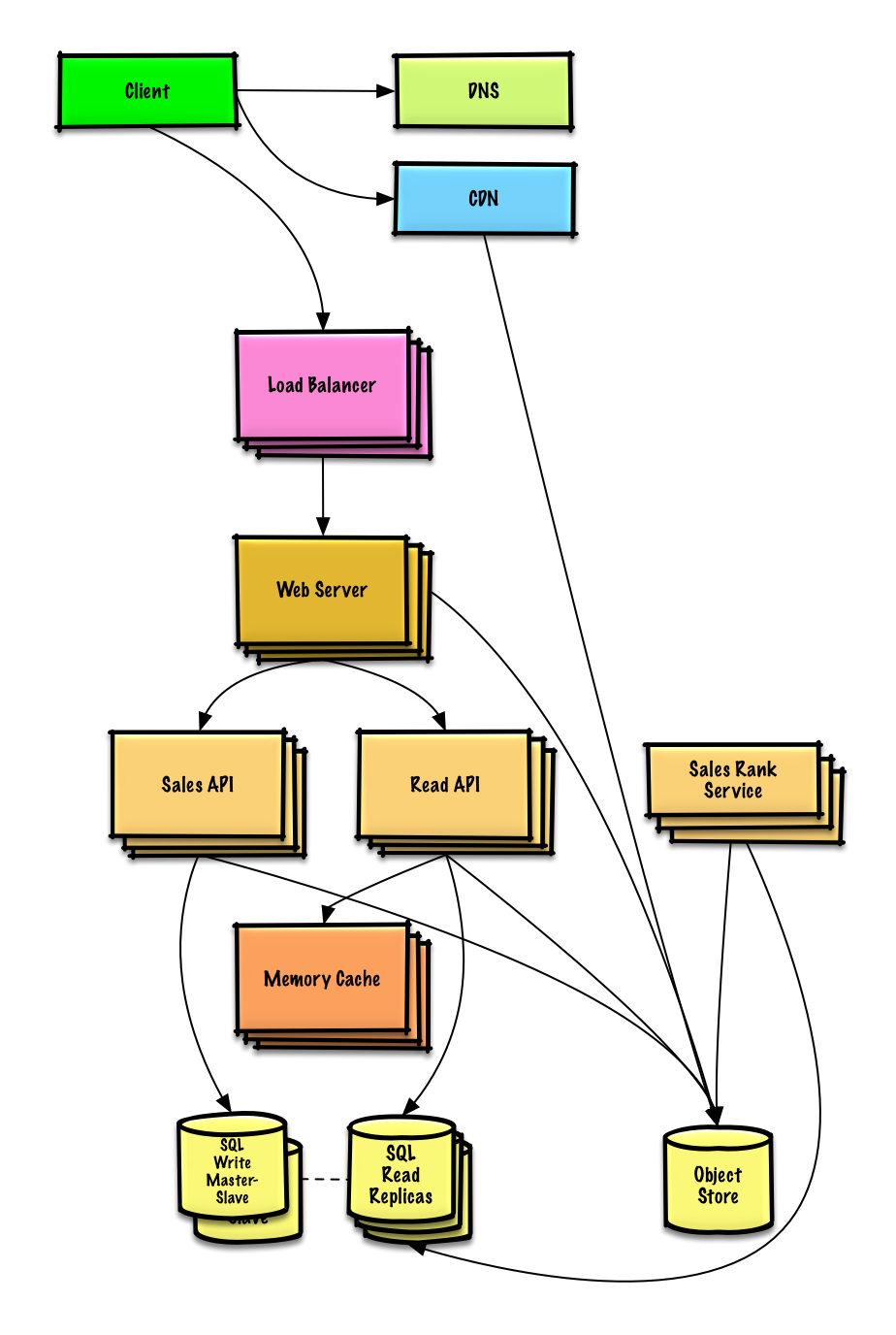
边栏推荐
- Affichage du changement de valeur du Buff de gain de l'interface graphique de défaillance
- Realization of the code for calculating the mean square error of GPS Height Fitting
- Shortest Hamilton path (pressure DP)
- 一文搞定 UDP 和 TCP 高频面试题!
- 3月15号 Go 1.18 正式版发布 了解最新特色以及使用方法
- 编辑距离(多源BFS)
- FairyGUI簡單背包的制作
- 341. Flatten nested list iterator
- 音乐播放(Toggle && PlayerPrefs)
- C code implementation of robust estimation in rtklib's pntpos function (standard single point positioning spp)
猜你喜欢
rtklib单点定位spp使用抗差估计遇到的问题及解决
Edit distance (multi-source BFS)
![[GNSS data processing] Helmert variance component estimation analysis and code implementation](/img/4e/ff0334cf9a2a37096778a8c5719a4e.jpg)
[GNSS data processing] Helmert variance component estimation analysis and code implementation
Office prompts that your license is not genuine pop-up box solution
Matlab读取GNSS 观测值o文件代码示例
![[algorithm] sword finger offer2 golang interview question 12: the sum of the left and right sub arrays is equal](/img/11/ee0628a68542236fc641966579a31a.png)
[algorithm] sword finger offer2 golang interview question 12: the sum of the left and right sub arrays is equal

Fairygui bar subfamily (scroll bar, slider, progress bar)
Novatel board oem617d configuration step record
2022国赛Re1 baby_tree
FGUI工程打包发布&导入Unity&将UI显示出来的方式
随机推荐
Exception: ioexception:stream closed
rtklib单点定位spp使用抗差估计遇到的问题及解决
平衡二叉树详解 通俗易懂
Introduction to the daily practice column of the Blue Bridge Cup
GNSS positioning accuracy index calculation
Edit distance (multi-source BFS)
Fairygui character status Popup
十分钟彻底掌握缓存击穿、缓存穿透、缓存雪崩
Particle system for introduction to unity3d Foundation (attribute introduction + case production of flame particle system)
最短Hamilton路径 (状压DP)
【GNSS】抗差估计(稳健估计)原理及程序实现
编辑距离(多源BFS)
堆排序【手写小根堆】
Mysql database reports an error: row size too large (> 8126) Changing some columns to TEXT or BLOB or using ROW_ FORMAT=DY
Mixed use of fairygui button dynamics
抗差估计在rtklib的pntpos函数(标准单点定位spp)中的c代码实现
Unity3d, Alibaba cloud server, platform configuration
Fabrication of fairygui simple Backpack
[算法] 剑指offer2 golang 面试题6:排序数组中的两个数字之和
[algorithm] sword finger offer2 golang interview question 13: sum of numbers of two-dimensional submatrix