当前位置:网站首页>System design learning (III) design Amazon's sales rank by category feature
System design learning (III) design Amazon's sales rank by category feature
2022-07-06 13:09:00 【Geometer】
Old rules , First look at the question
Use cases
We’ll scope the problem to handle only the following use case
Service calculates the past week’s most popular products by category
User views the past week’s most popular products by category
Service has high availability
Out of scope
The general e-commerce site:Design components only for calculating sales rank Constraints and assumptions
State assumptions Traffic is not evenly distributed
Items can be in multiple categories
Items cannot change categories
There are no subcategories ie foo/bar/baz Results must be updated hourly
More popular products might need to be updated more frequently
10 million products
1000 categories
1 billion transactions per month
100 billion read requests per month
100:1 read to write ratio
Then the first step is to calculate , Clear understanding , If you want to calculate the rough usage
First, let's see how much storage space each transaction needs
creared_at 5bytes
product_at 8bytes
category_id 4bytes
seller_id 8bytes
buyer_id 8bytes
quantity 4bytes
total_price 5bytes
total 40bytes
Because he said one month 1billion Transactions , So every month it costs 40gb To store these transactions Guoheng
If it takes three years 1.44tb For storage
Then after completing the rough calculation, we should simply design this system 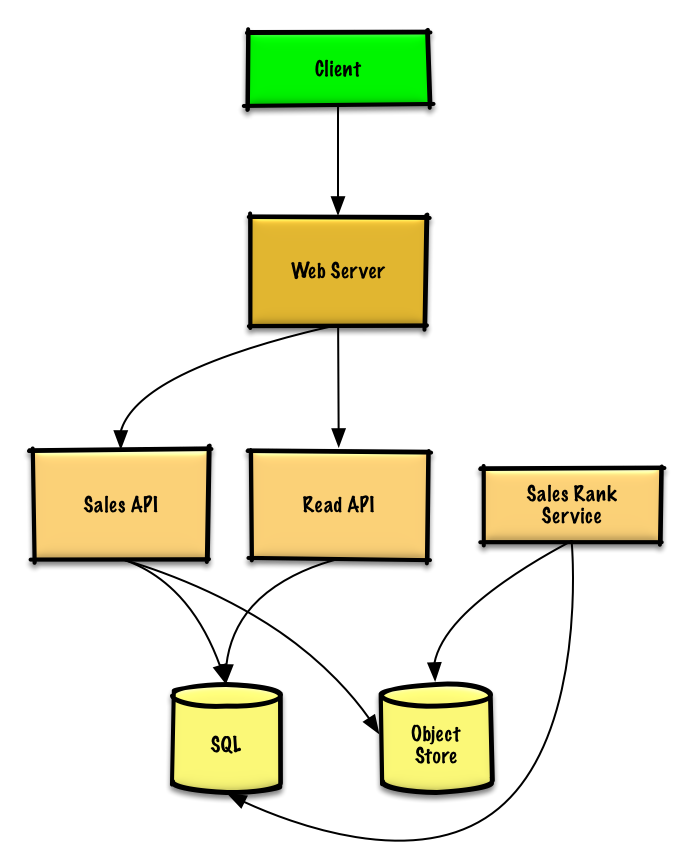
After completing the design of the system outline, we need to fill in the details
First , Since the service needs to count the most popular goods in the past week , Then he must count the information of all orders , We can use sale api Store the processed logs , stay Object Store Instead of managing our own file system
We assume that the log we see is as follows
timestamp product_id category_id qty total_price seller_id buyer_id
t1 product1 category1 2 20.00 1 1
t2 product1 category2 2 20.00 2 2
t2 product1 category2 1 10.00 2 3
t3 product2 category1 3 7.00 3 4
t4 product3 category2 7 2.00 4 5
t5 product4 category1 1 5.00 5 6
...
Sales Rank service have access to sale api Print the log as input data , Then use it internally mapreduce Conduct a distributed log statistics , At last, it comes to sales_rank Such information is stored in a SQL In the database
We will use a multipart mapreduce
1. Convert data to (category, product_id), sum(quantity)
2. Do a distributed sort
class SalesRanker(MRJob):
def within_past_week(self, timestamp):
"""Return True if timestamp is within past week, False otherwise."""
...
def mapper(self, _ line):
"""Parse each log line, extract and transform relevant lines. Emit key value pairs of the form: (category1, product1), 2 (category2, product1), 2 (category2, product1), 1 (category1, product2), 3 (category2, product3), 7 (category1, product4), 1 """
timestamp, product_id, category_id, quantity, total_price, seller_id, \
buyer_id = line.split('\t')
if self.within_past_week(timestamp):
yield (category_id, product_id), quantity
def reducer(self, key, value):
"""Sum values for each key. (category1, product1), 2 (category2, product1), 3 (category1, product2), 3 (category2, product3), 7 (category1, product4), 1 """
yield key, sum(values)
def mapper_sort(self, key, value):
"""Construct key to ensure proper sorting. Transform key and value to the form: (category1, 2), product1 (category2, 3), product1 (category1, 3), product2 (category2, 7), product3 (category1, 1), product4 The shuffle/sort step of MapReduce will then do a distributed sort on the keys, resulting in: (category1, 1), product4 (category1, 2), product1 (category1, 3), product2 (category2, 3), product1 (category2, 7), product3 """
category_id, product_id = key
quantity = value
yield (category_id, quantity), product_id
def reducer_identity(self, key, value):
yield key, value
def steps(self):
"""Run the map and reduce steps."""
return [
self.mr(mapper=self.mapper,
reducer=self.reducer),
self.mr(mapper=self.mapper_sort,
reducer=self.reducer_identity),
]
The result is an ordered list below , We can deposit it in sales_rank surface
(category1, 1), product4
(category1, 2), product1
(category1, 3), product2
(category2, 3), product1
(category2, 7), product3
sales_rank The deconstruction of the table is as follows
id int NOT NULL AUTO_INCREMENT
category_id int NOT NULL
total_sold int NOT NULL
product_id int NOT NULL
PRIMARY KEY(id)
FOREIGN KEY(category_id) REFERENCES Categories(id)
FOREIGN KEY(product_id) REFERENCES Products(id)
We will be in id 、 category_id and product_id Create an index on to speed up the search ( Record the time instead of scanning the entire table ) And keep the data in memory .
In this case , When users want to access the most popular products of the past week ( In each category ) When
client Send a request to webserver, Perform reverse proxy ,
webserver Direct request read api,
read api Read data from sql In the database
We use a public rest api
$ curl https://amazon.com/api/v1/popular?category_id=1234
return :
{
"id": "100",
"category_id": "1234",
"total_sold": "100000",
"product_id": "50",
},
{
"id": "53",
"category_id": "1234",
"total_sold": "90000",
"product_id": "200",
},
{
"id": "75",
"category_id": "1234",
"total_sold": "80000",
"product_id": "3",
},
The next step is to extend the existing structure 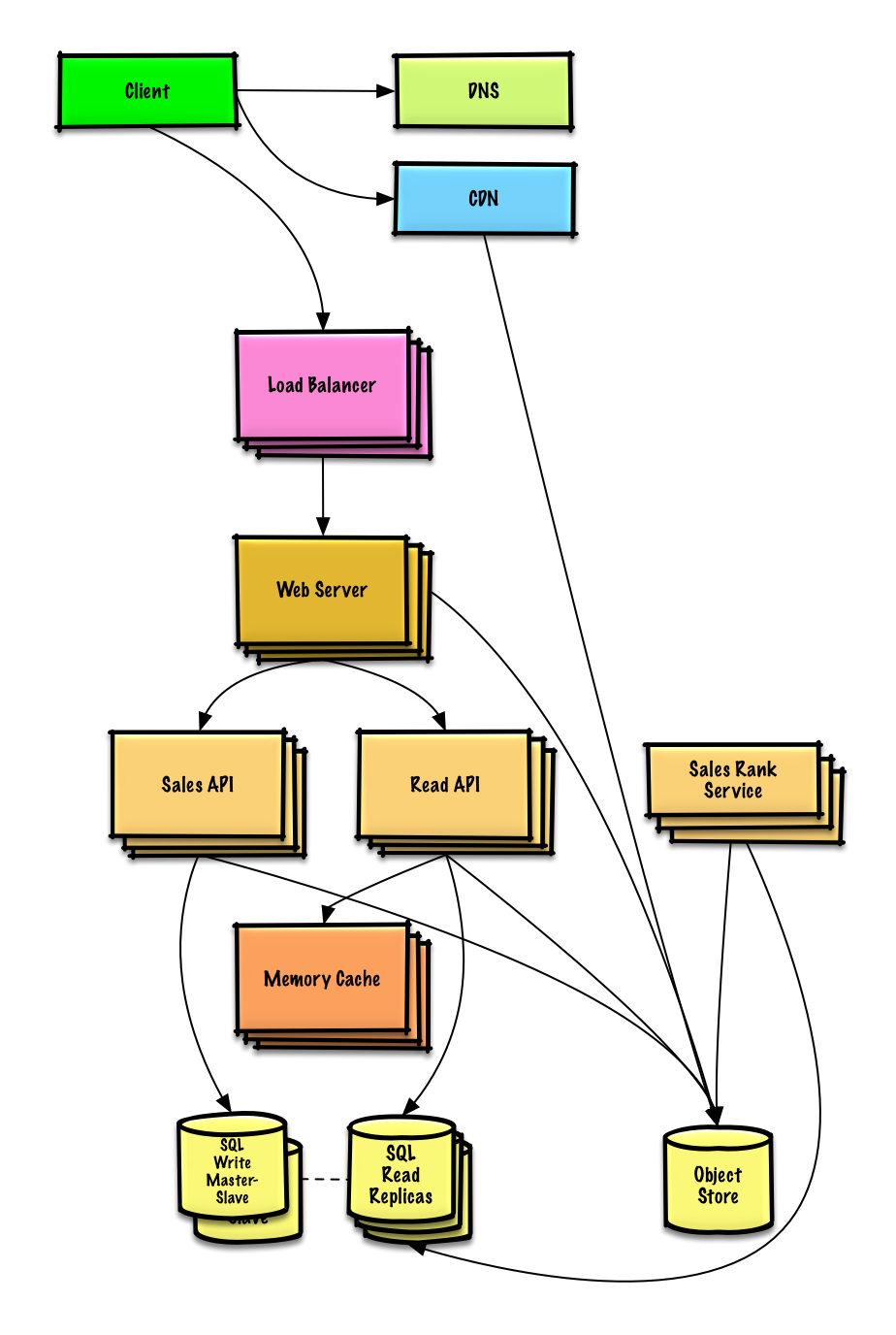
边栏推荐
- 记录:动态Web项目servlet访问数据库404错误之解决
- 异常:IOException:Stream Closed
- 系统设计学习(二)Design a key-value cache to save the results of the most recent web server queries
- 图书管理系统小练习
- How do architects draw system architecture blueprints?
- 10 minutes pour maîtriser complètement la rupture du cache, la pénétration du cache, l'avalanche du cache
- How to reduce the shutdown time of InnoDB database?
- [算法] 剑指offer2 golang 面试题5:单词长度的最大乘积
- [algorithm] sword finger offer2 golang interview question 3: the number of 1 in the binary form of the first n numbers
- The earth revolves around the sun
猜你喜欢

Record: the solution of MySQL denial of access when CMD starts for the first time
2-year experience summary, tell you how to do a good job in project management
![[algorithm] sword finger offer2 golang interview question 3: the number of 1 in the binary form of the first n numbers](/img/64/0f352232359c7d44f12b20a64c7bb4.png)
[algorithm] sword finger offer2 golang interview question 3: the number of 1 in the binary form of the first n numbers
![[untitled]](/img/b1/9a2bebebb24132a405fc4e7d854e51.png)
[untitled]

国企秋招经验总结
染色法判定二分图

The port is occupied because the service is not shut down normally
How do architects draw system architecture blueprints?
系统设计学习(一)Design Pastebin.com (or Bit.ly)
Novatel board oem617d configuration step record
随机推荐
国企秋招经验总结
[GNSS] robust estimation (robust estimation) principle and program implementation
MySQL shutdown is slow
Inheritance and polymorphism (Part 2)
Problems and solutions of robust estimation in rtklib single point location spp
Pride-pppar source code analysis
Detailed explanation of balanced binary tree is easy to understand
Experience summary of autumn recruitment of state-owned enterprises
The port is occupied because the service is not shut down normally
TYUT太原理工大学2022数据库大题之分解关系模式
[algorithm] sword finger offer2 golang interview question 2: binary addition
Iterable、Collection、List 的常见方法签名以及含义
RTKLIB: demo5 b34f. 1 vs b33
系统设计学习(三)Design Amazon‘s sales rank by category feature
Employment of cashier [differential constraint]
TYUT太原理工大学2022数据库之关系代数小题
Realization of the code for calculating the mean square error of GPS Height Fitting
Alibaba cloud side: underlying details in concurrent scenarios - pseudo sharing
[算法] 剑指offer2 golang 面试题5:单词长度的最大乘积
TYUT太原理工大学2022数据库题库选择题总结