当前位置:网站首页>Differences and application scenarios between MySQL index clock B-tree, b+tree and hash indexes
Differences and application scenarios between MySQL index clock B-tree, b+tree and hash indexes
2022-07-06 13:08:00 【Geometer】
As mentioned earlier , A good index can speed up mysql Retrieval speed of , But in fact, there are different types of indexes , For example, different tools can also play a suitable effect in different application scenarios
mysql The current indexes mainly include B-TREE ,B+TREE ,HASH
1.HASH Indexes
Hash indexed key,value The format of is very suitable for indexing , For each row of data , The storage engine will calculate one hashcode,, Hash index will all hashcode Store in index , Save the pointer of each row of data at the same time
The disadvantage of hash index :
1. Hash index only contains hash value and row pointer , Do not store field values , Therefore, you cannot use the values in the index to read rows , To adopt hashcode
2.hash The index is suitable for comparing equivalent queries , For some range queries, they are not stored in the order of index values , Therefore, it is not suitable for sorting
3. A lot of hash Conflict between , The cost of maintenance operations can be high
2.B-Tree Indexes
B Tree is a balanced multi-path search tree , We call the maximum number of subtrees of nodes in the tree B The steps of the tree . It's usually written as m.
B Tree lookup operation :
B The search of a tree is actually very similar to a binary sort tree , It can be understood as m Sort tree by fork
① Let the keywords to be found first key Compare with the keywords in the node , If it is equal to a keyword , Then the search is successful .
② If it is not equal to all keywords , Then look at key In which range , Then go to the subtree pointed to by the corresponding pointer to find .
example : If Key Than the first keyword K1 Still small , Then go P0 Look in the subtree pointed to by the pointer , If it's better than the last keyword KN Also big , Then go PN Look in the subtree pointed to by the pointer .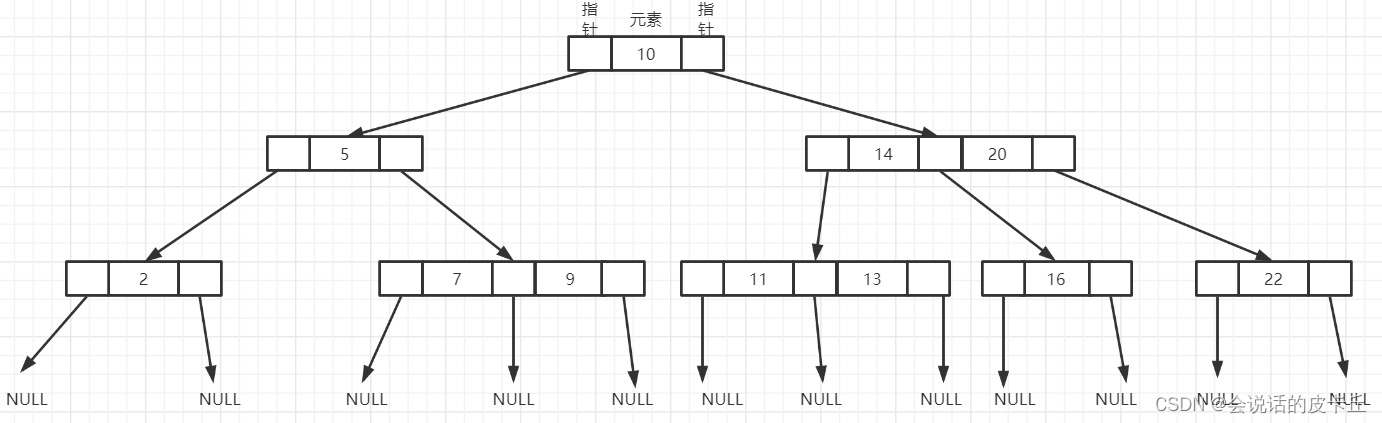
First step : Heel node 10 Compare , Not equal but better 10 Big , Go to the subtree on the right to find ;
The second step : And keywords in the right subtree 14 Compare , Not equal but better 14 Small , So go to the left sub tree to find ;
The third step : And keywords in the left subtree 11 Compare , equal , Get its data, return .
B Operations such as inserting and deleting trees are not described in detail , You can read this post if you need it https://www.cnblogs.com/xiaofengshan/p/15443140.html
advantage :
B Trees can store keys and values at the same time in internal nodes , therefore , Putting frequently accessed data close to the root node will greatly improve the query efficiency of hot data . This characteristic makes B Trees in It is more efficient in the scenario of repeated query of specific data .
3.B+ Tree index
B+ Trees are B- A variation of a tree , It's also a multi-channel search tree . A tree m Step B+ Trees mainly have these characteristics :
Each node has at most m Little girl ;
The range of the number of non root node key values :⌈m/2⌉ - 1 <= k <= m-1
Adjacent leaf nodes are connected by pointers , And it is sorted by keyword size .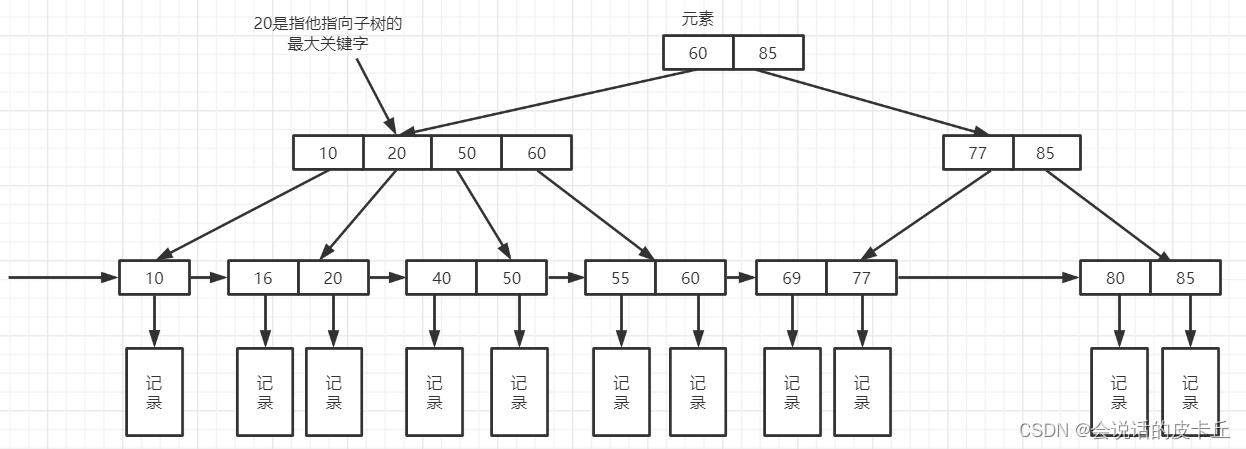
advantage :
When a full data traversal is needed ,B+ Trees only need to use O(logN) Time to find the smallest node , And then through the chain O(N) The order of traversal can be . and B Trees need to traverse every layer of the tree , This will require more memory replacements , So it takes more time
B+ Trees and B- The main differences between trees are as follows :
B- The nodes inside the tree hold the data ; and B+ The nodes inside the tree do not store data , Index only , Only its leaf node stores data .
B+ The adjacent leaf nodes of the tree are connected by linked list pointers ,B- Trees are not .
During the search ,B- The tree ends when it finds the value , and B+ The tree needs to find the data in the leaf node through the index to finish
B- Any keyword in the tree appears in only one node , and B+ Trees can appear many times .
边栏推荐
- 记录:newInstance()过时的代替方法
- Introduction pointer notes
- Error: symbol not found
- RTKLIB: demo5 b34f.1 vs b33
- Error: sorting and subscript out of bounds
- [untitled]
- 记录:Navicat Premium初次无法连接数据库MySQL之解决
- TYUT太原理工大学2022软工导论考试题型大纲
- Ten minutes to thoroughly master cache breakdown, cache penetration, cache avalanche
- rtklib单点定位spp使用抗差估计遇到的问题及解决
猜你喜欢
On March 15, the official version of go 1.18 was released to learn about the latest features and usage
Basic DOS commands
![[algorithm] sword finger offer2 golang interview question 12: the sum of the left and right sub arrays is equal](/img/11/ee0628a68542236fc641966579a31a.png)
[algorithm] sword finger offer2 golang interview question 12: the sum of the left and right sub arrays is equal
![[algorithm] sword finger offer2 golang interview question 10: subarray with sum K](/img/63/7422489d09a64ec9f0e79378761bf1.png)
[algorithm] sword finger offer2 golang interview question 10: subarray with sum K
堆排序【手写小根堆】
rtklib单点定位spp使用抗差估计遇到的问题及解决
![[dry goods] cycle slip detection of suggestions to improve the fixed rate of RTK ambiguity](/img/9d/7284c1399964d3fb48886f12e4941c.jpg)
[dry goods] cycle slip detection of suggestions to improve the fixed rate of RTK ambiguity
Code example of MATLAB reading GNSS observation value o file
阿里云微服务(四) Service Mesh综述以及实例Istio
![[algorithm] sword finger offer2 golang interview question 6: sum of two numbers in the sorting array](/img/d5/4bda133498f71ae9fd7a64c6cba8f0.png)
[algorithm] sword finger offer2 golang interview question 6: sum of two numbers in the sorting array
随机推荐
阿里云微服务(四) Service Mesh综述以及实例Istio
记录:newInstance()过时的代替方法
Rt-ppp test using rtknavi
【无标题】
[算法] 剑指offer2 golang 面试题5:单词长度的最大乘积
系统设计学习(一)Design Pastebin.com (or Bit.ly)
10 minutes pour maîtriser complètement la rupture du cache, la pénétration du cache, l'avalanche du cache
First acquaintance with C language (Part 2)
如何保障 MySQL 和 Redis 的数据一致性?
wsl常用命令
[GNSS data processing] Helmert variance component estimation analysis and code implementation
The port is occupied because the service is not shut down normally
闇の連鎖(LCA+树上差分)
Shortest Hamilton path (pressure DP)
错误: 找不到符号
GNSS positioning accuracy index calculation
121 distributed interview questions and answers
几道高频的JVM面试题
《软件测试》习题答案:第一章
RTKLIB: demo5 b34f. 1 vs b33