当前位置:网站首页>优先队列PriorityQueue (大根堆/小根堆/TopK问题)
优先队列PriorityQueue (大根堆/小根堆/TopK问题)
2022-07-06 09:21:00 【李孛欢】
PriorityQueue是从JDK1.5开始提供的新的数据结构接口,它是一种基于优先级堆的极大优先级队列。优先级队列是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素。
默认情况下,PriorityQueue是小顶堆,如代码所示
public static void main(String[] args) {
PriorityQueue<Integer> queue = new PriorityQueue<>();
queue.offer(1);
queue.offer(2);
queue.offer(3);
queue.offer(4);
queue.offer(5);
queue.offer(6);
while (!queue.isEmpty()){
System.out.print(queue.poll() + " ");
}
}输出结果:

我们也可以通过以下方式来构造大顶堆:
public static void main(String[] args) {
PriorityQueue<Integer> queue = new PriorityQueue<>((o1,o2) -> o2 - o1);//降序
queue.offer(1);
queue.offer(2);
queue.offer(3);
queue.offer(4);
queue.offer(5);
queue.offer(6);
while (!queue.isEmpty()){
System.out.print(queue.poll() + " ");
}
}输出结果:

Top K问题,力扣347和力扣692:
力扣347:给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例:
输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2]
代码如下:注意构造小顶堆的时候(o1,o2)-> o1.getValue() - o2.getValue() 不能省略。
public int[] topKFrequent(int[] nums, int k) {
//key为元素值,value为出现频率
HashMap<Integer,Integer> map = new HashMap<>();
PriorityQueue<Map.Entry<Integer, Integer>> queue
= new PriorityQueue<>((o1,o2)-> o1.getValue() - o2.getValue());
int[] res = new int[k];
for (int num : nums) {
map.put(num,map.getOrDefault(num,0) + 1);
}
Set<Map.Entry<Integer, Integer>> entries = map.entrySet();
for (Map.Entry<Integer, Integer> entry : entries) {
queue.offer(entry);
if(queue.size() > k){
queue.poll();
}
}
//留下的都是出现频率最高的
for(int i = 0; i < k; i++){
Map.Entry<Integer, Integer> poll = queue.poll();
res[i] = poll.getKey();
}
return res;力扣692:给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序排序。
示例:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。注意,按字母顺序 "i" 在 "love" 之前。
这题比上题难一点,因为当两个单词出现次数一致时还要考虑按字典序排序,其次是答案需要从高到底排序,这里主要体现在优先队列PriorityQueue的构造上。代码如下:
public List<String> topKFrequent(String[] words, int k) {
List<String> res = new ArrayList<>();
//key为元素,value为出现频率
HashMap<String,Integer> map = new HashMap<>();
for (String word : words) {
map.put(word,map.getOrDefault(word,0) + 1);
}
PriorityQueue<Map.Entry<String,Integer>> queue = new PriorityQueue<>(
((o1, o2) -> {
if(o1.getValue() == o2.getValue()){
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue() - o2.getValue();
})
);
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
queue.offer(entry);
if(queue.size() > k){
queue.poll();
}
}
for(int i = 0; i < k; i++){
res.add(queue.poll().getKey());
}
Collections.reverse(res);
return res;
}注意o2.getKey().compareTo(o1.getKey())是按字典倒序,为什么要这么做呢,是因为我们这里用到小顶堆,所以每次poll出来的都是最小频率元素,最后需要reverse一下,为了配合这个,所以我们构造优先队列的时候采用字典倒序。
边栏推荐
- 【话题终结者】
- 最新坦克大战2022-全程开发笔记-1
- Introduction pointer notes
- 稻 城 亚 丁
- 【九阳神功】2016复旦大学应用统计真题+解析
- C language Getting Started Guide
- 2.C语言初阶练习题(2)
- ArrayList的自动扩容机制实现原理
- C language to achieve mine sweeping game (full version)
- The overseas sales of Xiaomi mobile phones are nearly 140million, which may explain why Xiaomi ov doesn't need Hongmeng
猜你喜欢

2. Preliminary exercises of C language (2)

13 power map

Tyut Taiyuan University of technology 2022 introduction to software engineering summary
20220211-CTF-MISC-006-pure_ Color (use of stegsolve tool) -007 Aesop_ Secret (AES decryption)

arduino+水位传感器+led显示+蜂鸣器报警

Mortal immortal cultivation pointer-2

View UI plus released version 1.2.0 and added image, skeleton and typography components
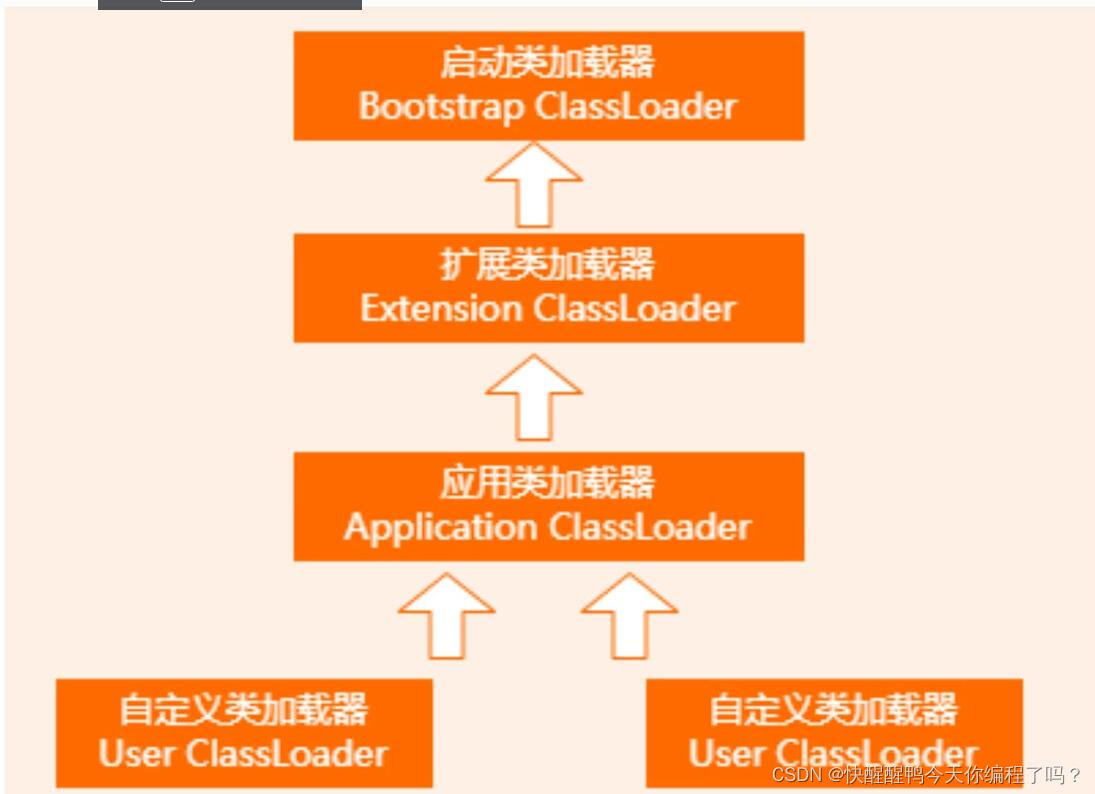
关于双亲委派机制和类加载的过程
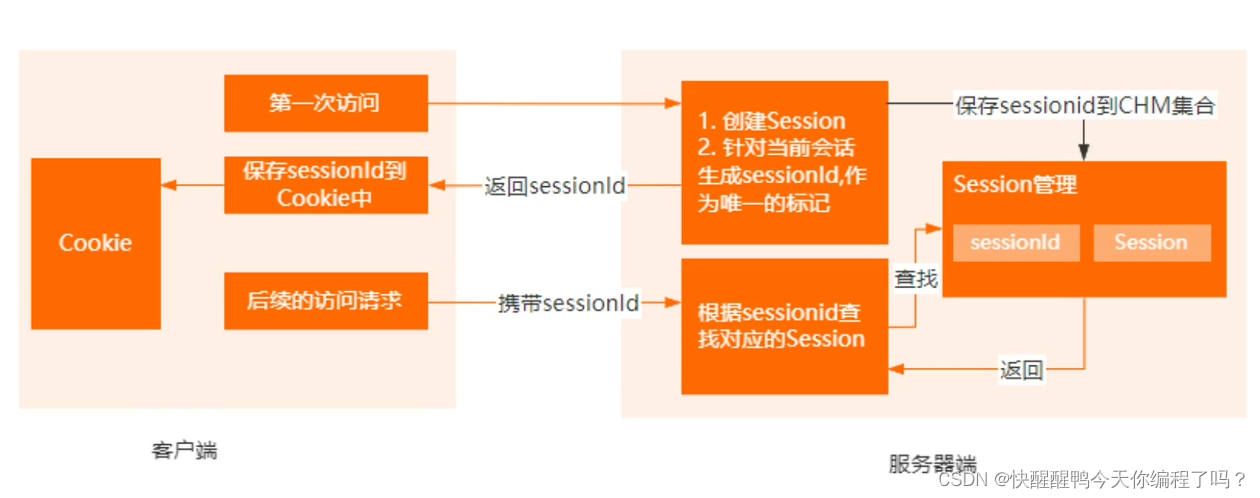
Cookie和Session的区别
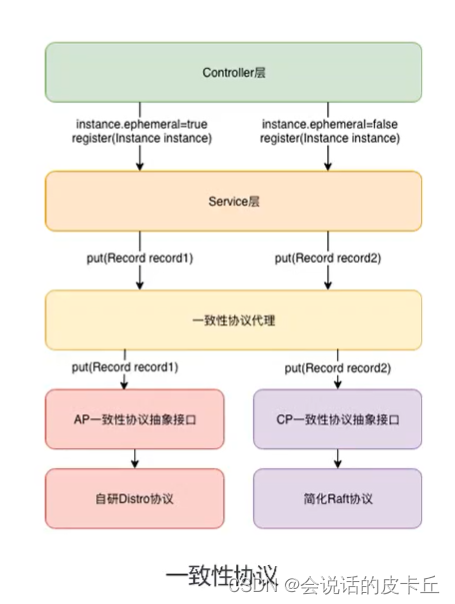
Alibaba cloud microservices (II) distributed service configuration center and Nacos usage scenarios and implementation introduction
随机推荐
string
更改VS主题及设置背景图片
7.数组、指针和数组的关系
杂谈0516
fianl、finally、finalize三者的区别
TYUT太原理工大学2022数据库之关系代数小题
【九阳神功】2017复旦大学应用统计真题+解析
The latest tank battle 2022 full development notes-1
CorelDRAW plug-in -- GMS plug-in development -- Introduction to VBA -- GMS plug-in installation -- Security -- macro Manager -- CDR plug-in (I)
System design learning (I) design pastebin com (or Bit.ly)
(ultra detailed onenet TCP protocol access) arduino+esp8266-01s access to the Internet of things platform, upload real-time data collection /tcp transparent transmission (and how to obtain and write L
TYUT太原理工大学2022数据库大题之E-R图转关系模式
【话题终结者】
关于双亲委派机制和类加载的过程
凡人修仙学指针-1
String abc = new String(“abc“),到底创建了几个对象
[the Nine Yang Manual] 2017 Fudan University Applied Statistics real problem + analysis
TYUT太原理工大学2022数据库大题之数据库操作
vector
重载和重写的区别