当前位置:网站首页>仿牛客技术博客项目常见问题及解答(三)
仿牛客技术博客项目常见问题及解答(三)
2022-07-06 09:20:00 【李孛欢】
书接上回:仿牛客技术博客项目常见问题及解答(二)_李孛欢的博客-CSDN博客
13 项目中的kafka是怎么用的?
kafka入门
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力:
- 发布和订阅流数据流,类似于消息队列或者是企业消息传递系统
- 以容错的持久化方式存储数据流
- 处理数据流
-应用:消息系统、日志收集、用户行为跟踪、流式处理
·kafka特点
-高吞吐量:处理TB级的海量数据
-消息持久化:持久化,将数据存储到硬盘上,而不仅仅存储在内存中,长久保存消息,存到硬盘中的读取速度远远小于内存,读写硬盘的效率高低取决于读取硬盘的方式,硬盘的顺序读写的效率是很高的,kafka保证对硬盘消息的读写都是顺序的;
-高可靠性:kafka是分布式部署,一台服务器挂了,还有别的,有容错机制
-高拓展性:集群的服务器不够时,可以扩展服务器,只需简单的配置
·kafka术语
-Broker:卡夫卡的服务器,卡夫卡集群中的每一台服务器称为一个Broker
-Zookeeper:管理集群的软件,在使用卡夫卡时可以单独安装zookeeper或是内置zookeeper
消息队列的实现方式:
点对点的实现方式:BlockingQueue,生产者将消息放入队列中,消费者从队列中取出数据,每个消息只会被一个消费者消费;
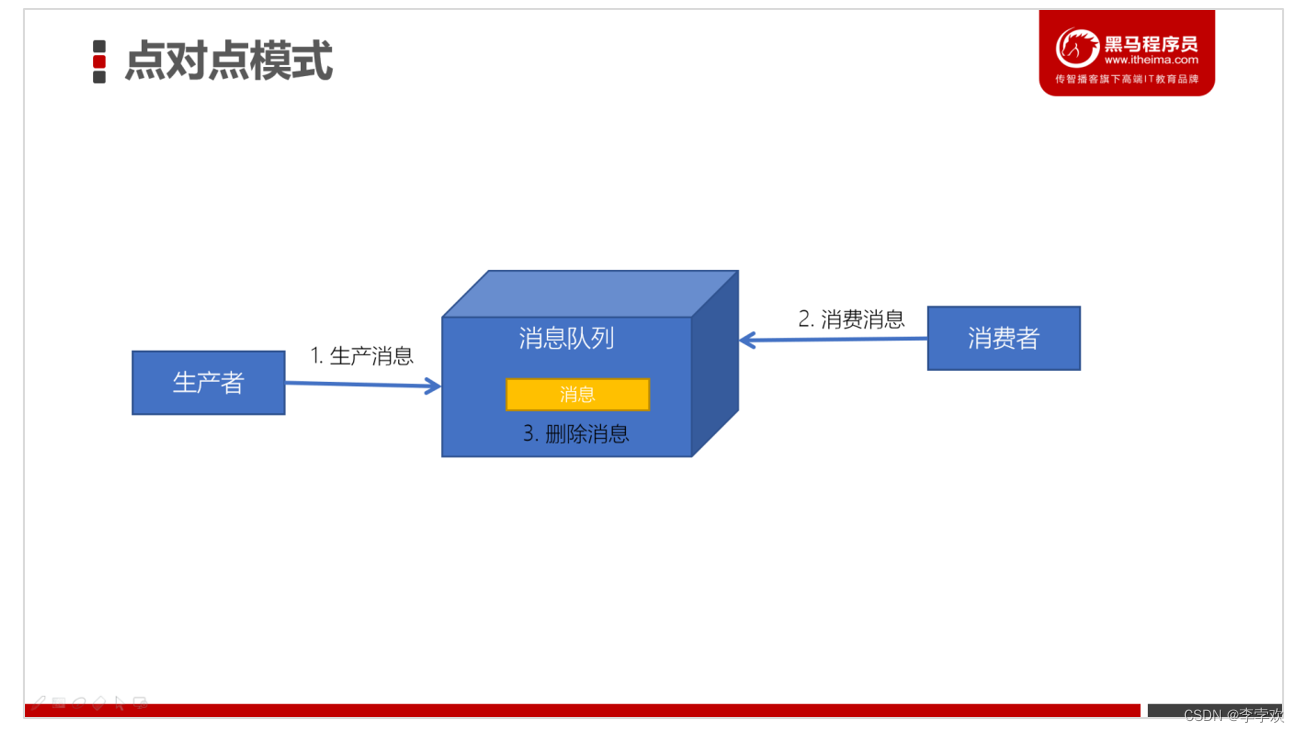
消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。

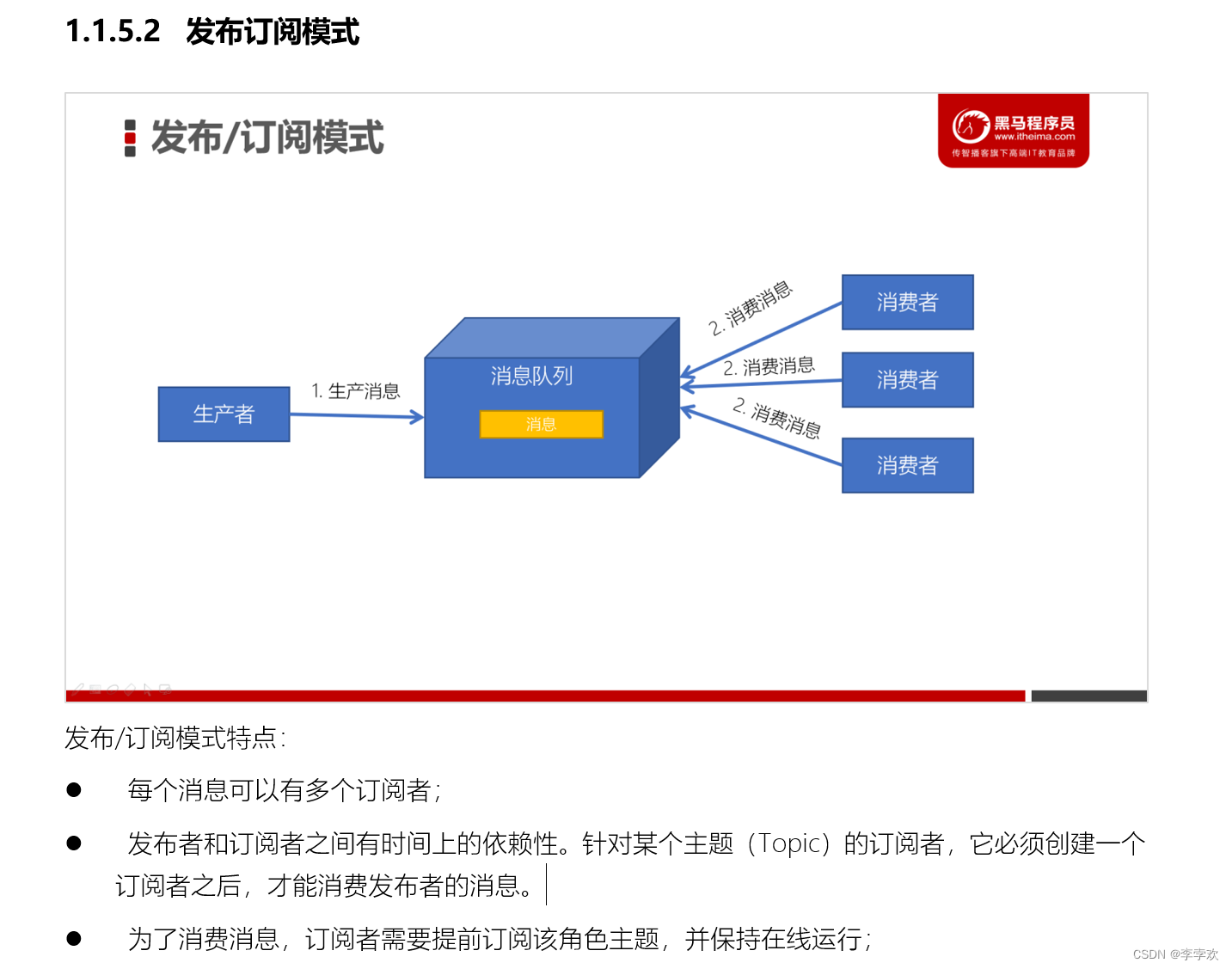
发布订阅模式:生产者将消息发布到某个位置,多个消费者可以同时订阅这个位置,该消息可以被多个消费者读取,
卡夫卡使用的就是发布订阅模式:生产者将消息发布到的区域就叫做topic,可以理解为一个文件夹
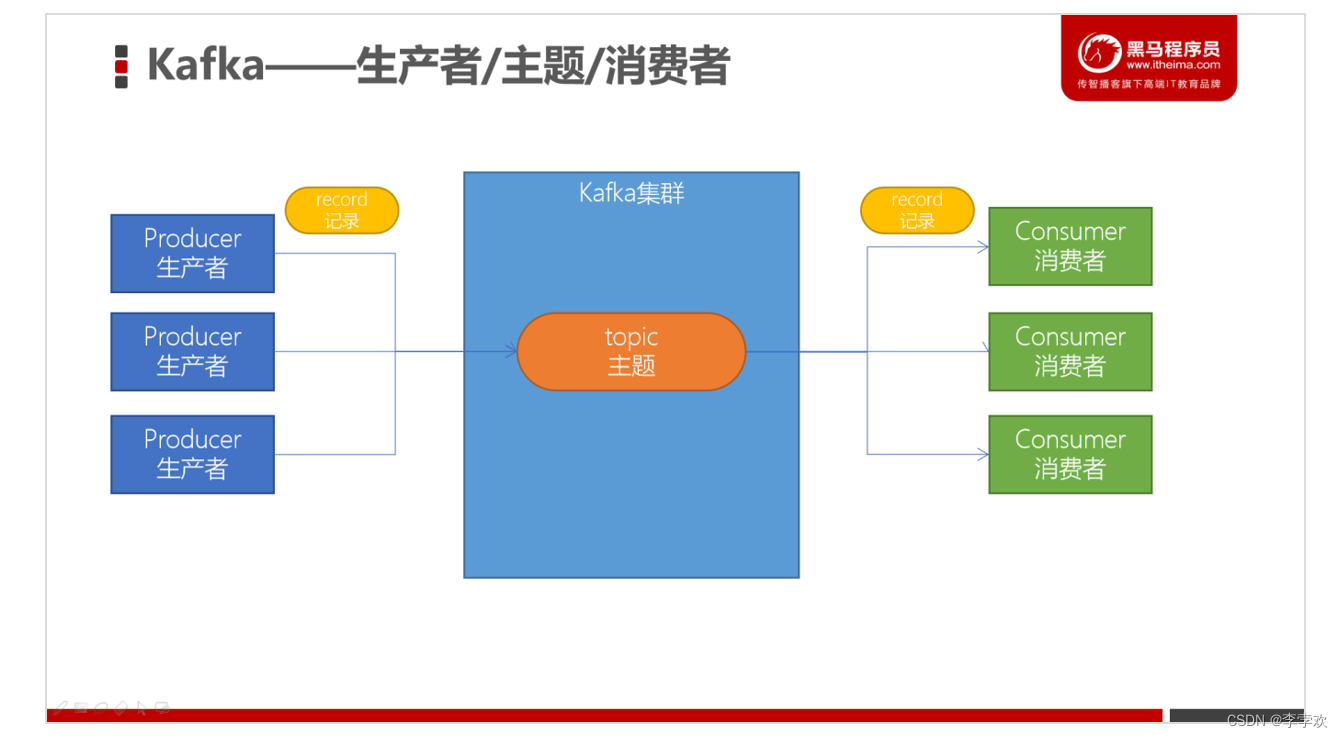
-Partition:对主题的分区
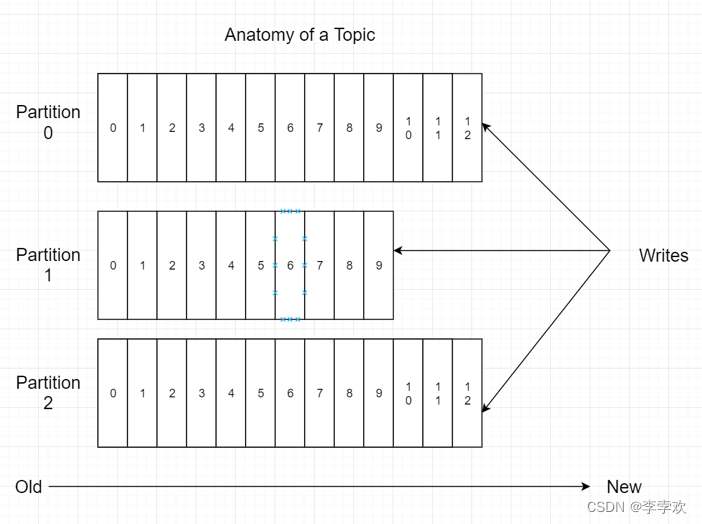
-Offset:消息在分区内存放的索引
-Leader Replica:副本,卡夫卡是分布式的,所以会对分区进行多个副本的重复
主副本:可以处理获取消息的请求
-Follower Replica:从副本只是备份数据,不会产生响应,当主副本挂了时,分布式会在所有的从副本中选择一个作为新的主副本
发送系统通知: ---操作非常频繁,用户群体很多,需要考虑性能问题
·触发事件
定义三种不同的主题,将不同的触发事件包装成不同的消息,发布到对应的主题中,这样生产者线程可以继续发布消息,
此时消费者线程可以并发的读取消息,进行存储
-评论后,发布通知
-点赞后,发布通知
-关注后,发布通知
·处理事件
-封装事件对象
-开发事件的生产者
-开发事件的消费者
生产者:触发Event,封装了Topic以及userId、Entity等信息,调用sendMsg时,提取出event.Topic和JSONObject.toJSONString(Event)以content形式发送,进行调用即可; (主动触发,在添加评论、关注和点赞时触发)
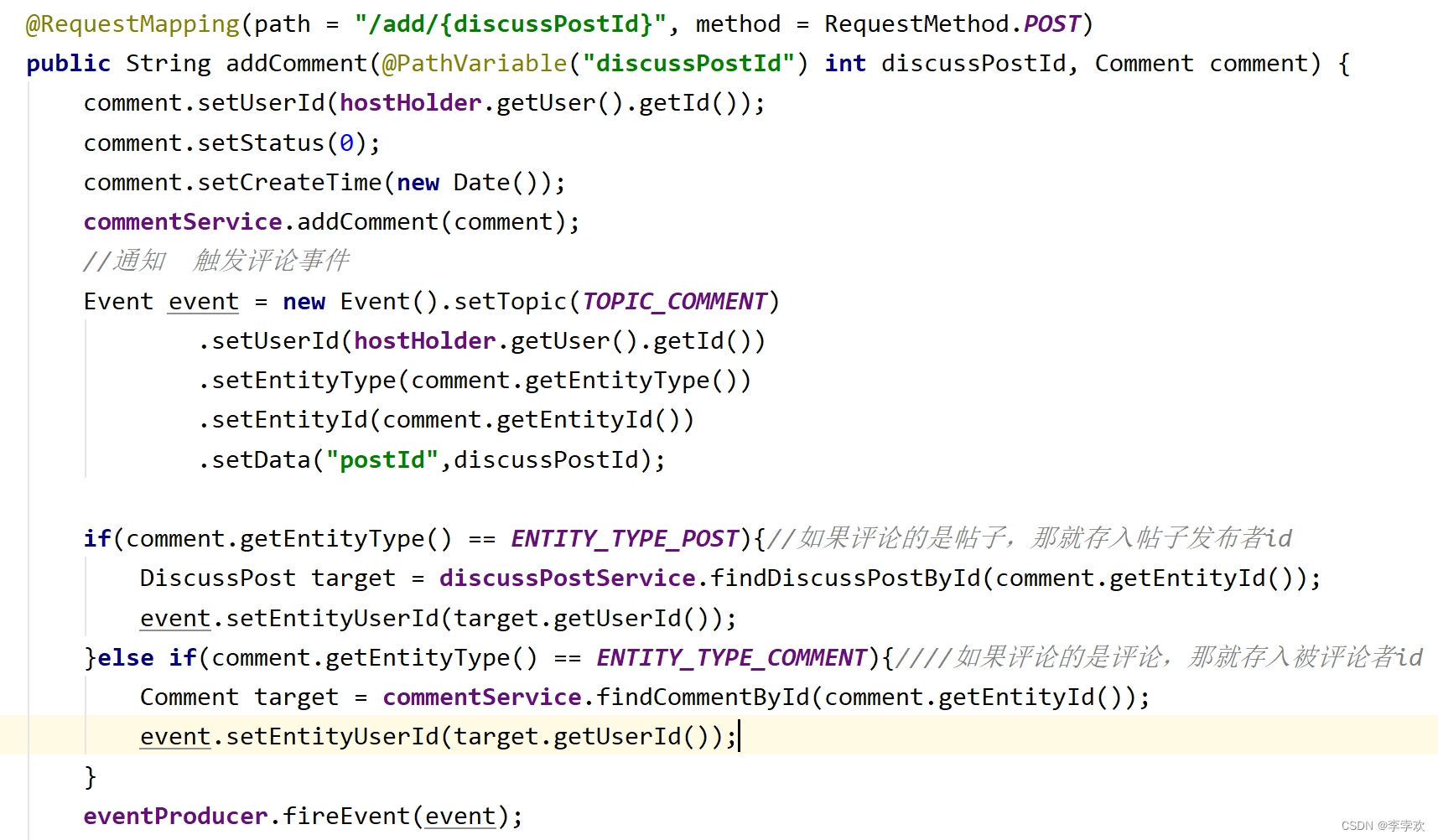
消费者:监听Topic,如果有新消息,就读取,record中获得到的是event里的json串,再恢复成event即可JSONObject.paresObject(record.value().toString,Event.class);然后将相关属性,封装成message私信的形式,保存到数据库中,供给前端页面调用并显示。(这里的消费就是将数据从消息队列存入数据库,被动触发,kafka监听主题,有消息就自动消费)
14 消息队列放到内存还是磁盘?放磁盘为什么还这么快?
Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率。
从数据写入和读取两方面分析,为什么Kafka速度这么快
写入数据:磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。在顺序读写的情况下,磁盘的顺序读写速度和内存持平。因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘 ,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
读取数据:实现了零拷贝
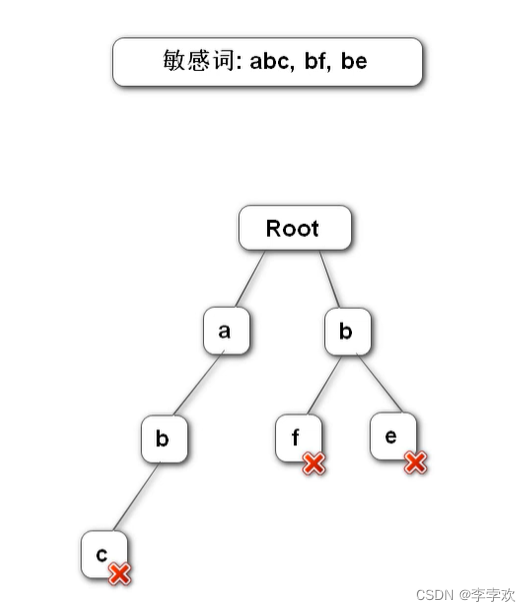
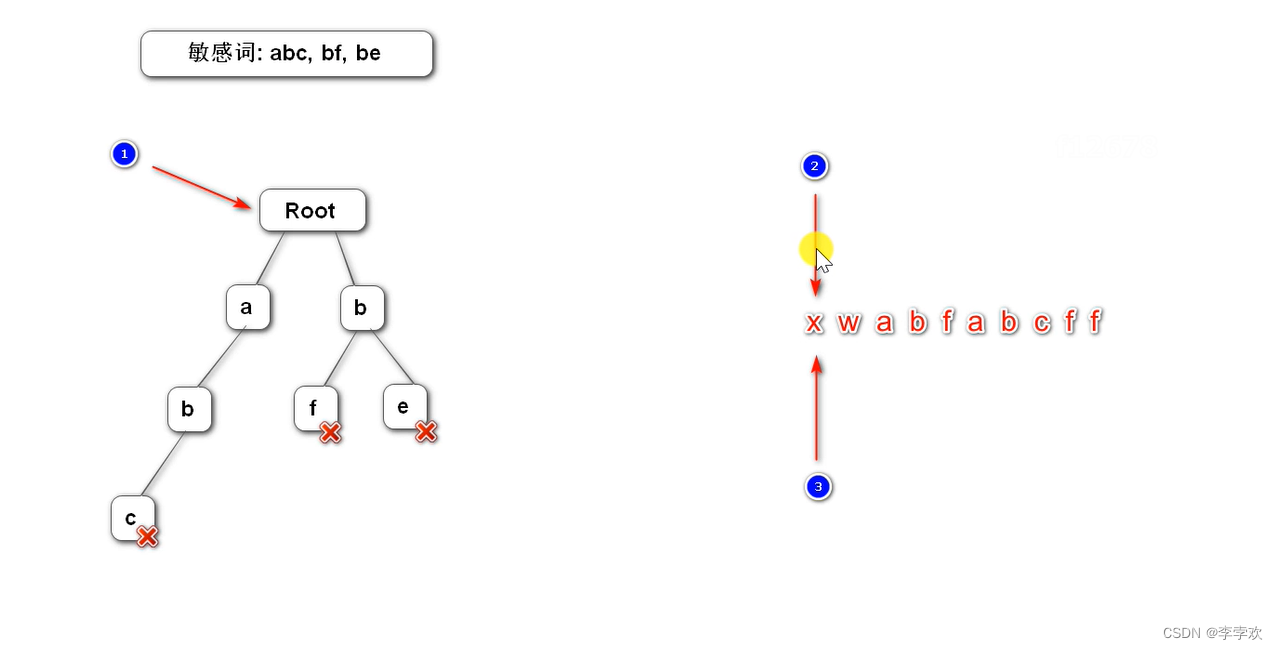
15 TrieTree前缀树介绍一下
前缀树 是一种多叉树的树形数据结构,在项目中用于对敏感词进行过滤。
构造前缀树:第一层就存所有敏感词的第一个字符
前缀树特点是:1.根节点不包含任何信息 除了根节点的每个节点只包含一个字符,2.从根节点到某一个节点经过的路径,字符所连接的字符串就是这个节点所对应的字符串 3.每个节点的所有子节点包含的字符不同
如下图:

过滤敏感词算法:
三个指针,一个指向树根(node),另两个指针(begin和position),都指向文本首,其中一个一直向后移动(begin),另一个跟着动,发现不是敏感词,就说明以begin开头的字符不可能组成敏感词,将其存入StringBuilder,begin后移,然后再返回至begin。若是敏感词,则替换,并另两个指针都后移,树指针指向根节点。
public String filter(String text) {
if (StringUtils.isBlank(text)) {
return null;
}
// 指针1
TrieNode tempNode = rootNode;
// 指针2
int begin = 0;
// 指针3
int position = 0;
// 结果
StringBuilder sb = new StringBuilder();
while (position < text.length()) {
char c = text.charAt(position);
// 跳过符号
if (isSymbol(c)) {
// 若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode == rootNode) {
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词,将begin~position字符串替换掉
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
} else {
// 检查下一个字符
position++;
}
}
// 将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
边栏推荐
- hashCode()与equals()之间的关系
- 【九阳神功】2021复旦大学应用统计真题+解析
- 2.C语言初阶练习题(2)
- JS interview questions (I)
- 167. Sum of two numbers II - input ordered array - Double pointers
- View UI Plus 发布 1.3.0 版本,新增 Space、$ImagePreview 组件
- MPLS experiment
- Branch and loop statements
- 1.C语言矩阵加减法
- Conceptual model design of the 2022 database of tyut Taiyuan University of Technology
猜你喜欢

Tyut Taiyuan University of technology 2022 introduction to software engineering summary
最新坦克大战2022-全程开发笔记-2

5. Download and use of MSDN

6. Function recursion
6.函数的递归
Inheritance and polymorphism (I)
4. Binary search

There is always one of the eight computer operations that you can't learn programming
arduino+DS18B20温度传感器(蜂鸣器报警)+LCD1602显示(IIC驱动)
Inheritance and polymorphism (Part 2)
随机推荐
9.指针(上)
Data manipulation language (DML)
3. Number guessing game
Mortal immortal cultivation pointer-1
【九阳神功】2021复旦大学应用统计真题+解析
Alibaba cloud microservices (I) service registry Nacos, rest template and feign client
Network layer 7 protocol
Counter attack of flour dregs: redis series 52 questions, 30000 words + 80 pictures in detail.
Comparison between FileInputStream and bufferedinputstream
西安电子科技大学22学年上学期《基础实验》试题及答案
[中国近代史] 第六章测验
Common method signatures and meanings of Iterable, collection and list
Alibaba cloud microservices (III) sentinel open source flow control fuse degradation component
hashCode()与equals()之间的关系
【快趁你舍友打游戏,来看道题吧】
Tyut Taiyuan University of technology 2022 introduction to software engineering examination question outline
凡人修仙学指针-1
Floating point comparison, CMP, tabulation ideas
C语言入门指南
First acquaintance with C language (Part 1)