当前位置:网站首页>How was the middle table destroyed?
How was the middle table destroyed?
2022-07-05 16:31:00 【CSDN cloud computing】

author | Don't eat tomatoes
source | CSDN Blog

Generation of intermediate table
The intermediate table is a data table in the database that stores intermediate calculation results , It is often a summary table established in the database for faster or more convenient front-end query and statistics , Because it is an intermediate result processed from raw data , Therefore, it is called intermediate table .
In some large institutions , The number of intermediate watches accumulated over the years is as high as tens of thousands , It causes a lot of trouble to the system and use .
Intermediate tables will occupy a lot of database storage space, resulting in insufficient database capacity , Facing expansion pressure . Database space is often expensive , The cost of expansion is very high , And database expansion is often limited , It is not a good way to store intermediate tables at high cost . meanwhile , Too many intermediate tables will also cause database performance problems , Intermediate tables do not exist in isolation , From the original data to the intermediate table, it needs a series of operations, which consumes database computing resources , And the frequency of processing intermediate tables is sometimes very high , A lot of resources of the database are consumed in the generation of intermediate tables , Serious cases will cause slow database queries 、 Slow trading and other issues .
Why are there so many intermediate tables ? The main reasons are as follows .
1、 One step cannot be calculated
The original data table in the database needs complex calculation , Can be shown on the report . One SQL It is difficult to achieve such complex calculations . There should be multiple consecutive SQL Realization , The former generates an intermediate table for the latter SQL Use .
2、 The waiting time for real-time calculation is too long
Because of the large amount of data or complex calculation , Report users wait too long . So run batch tasks every night , Calculate the data and store it in the intermediate table . Report users will query much faster based on the intermediate table .
3、 Diverse data sources participate in the calculation
From file 、NOSQL、Web service And other external data , It doesn't have much computing power , Need to use the computing power of the database , Especially when you want to perform mixed calculation with the data in the database , The traditional method can only import the database to form an intermediate table .
4、 The middle table is difficult to delete
Because the database usually adopts a flat structure that lacks hierarchy , Once created, the intermediate table may be used by multiple queries , Deleting may affect other queries . It's even hard to figure out which programs use an intermediate table , Not to mention deleting , It's not that I don't want to delete , But dare not delete . Accumulate over a long period , It's not surprising that there are tens of thousands of middle watches .
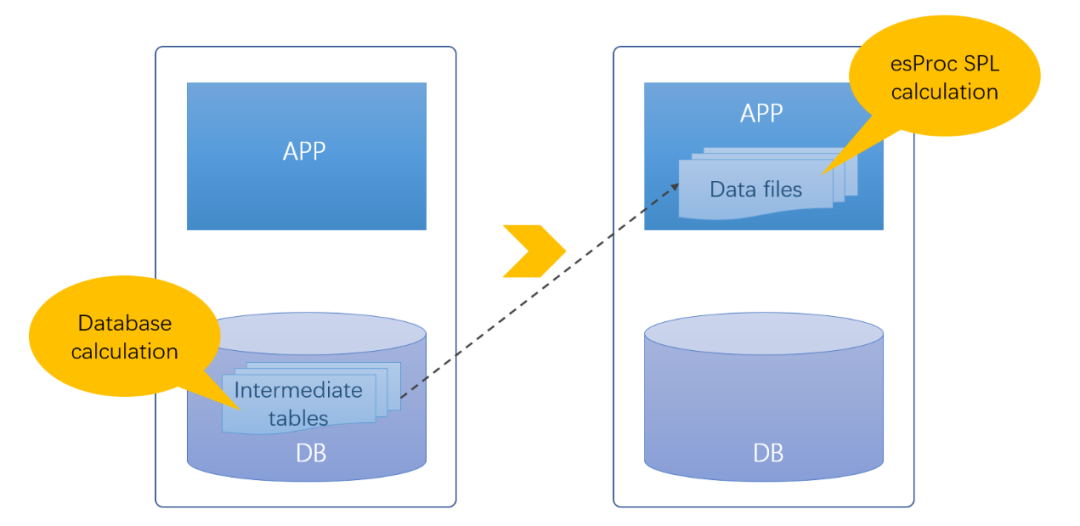
that , Why save intermediate data into the database to form an intermediate table ? Careful observation of the direct cause of the middle table can be seen , The main purpose of saving to the database is to continue to rely on the computing power of the database . Intermediate data will be further calculated when used , Sometimes the calculation is complicated , At present, there are only databases (SQL) Have more convenient computing ability . Although data storage forms such as files also have advantages ( Such as IO High performance 、 Compressible 、 Easy to parallel ), But the document has no computing power , If the calculation is hard coded in the application based on the file , Far from it SQL convenient . In order to make further use of the computing power of the database is the fundamental reason for the generation of intermediate tables .
Intermediate data is necessary in a sense , But just to obtain further computing power, it will occupy a lot of database resources , Obviously, it is not an ideal solution . If the file has the same ability as the database , Storing the intermediate table in the file system outside the database can solve various problems of the intermediate table in the database , The database can also be freed ( alleviate excessive burden ).
Open source SPL It can be achieved .
SPL Is an open source structured data computing engine , Data processing can be directly based on files , Make the file also have computing power .SPL Database independent , It provides professional structured data objects and rich operation class libraries on them , Have complete computing power , At the same time, it supports process control , It is also convenient to realize complex calculation , It can completely replace the database to complete the intermediate table generation and subsequent data processing tasks .

Document calculation
SPL Can be based on Csv、Excel Wait for documents to calculate , You can also calculate JSON/XML And so on , Easy to read and use . such , You can store intermediate table data into such files , Reuse SPL Processing . Here are some general operations :
| A | B | |
1 | =T("/data/scores.txt") | |
| 2 | =A1.select(CLASS==10) | Filter |
| 3 | =A1.groups(CLASS;min(English),max(Chinese),sum(Math)) | Group summary |
| 4 | =A1.sort(CLASS:-1) | Sort |
| 5 | =T("/data/students.txt").keys(SID) | |
| 6 | =A1.join(STUID,A5,SNAME) | relation |
| 7 | =A6.derive(English+ Chinese+ Math:TOTLE) | Append column |
In addition to the original SPL grammar ,SPL It also provides quite SQL92 The standard SQL Support , For familiar with using SQL People can use it directly SQL Query file .
$select * from d:/Orders.csv where Client in ('TAS','KBRO','PNS')More complicated with All support :
$select t.Client, t.s, ct.Name, ct.address from
(select Client ,sum(amount) s from d:/Orders.csv group by Client) t
left join ClientTable ct on t.Client=ct.ClientSPL Processing JSON/XML And so on ( file ) It also has advantages , Such as : According to the employee order information (json) Complete the calculation .
| A | ||
| 1 | =json(file("/data/EO.json").read()) | |
| 2 | =A1.conj(Orders) | |
| 3 | =A2.select(Amount>1000 && Amount<=3000 && [email protected](Client,"*s*")) | filter |
| 4 | =A2.groups(year(OrderDate);sum(Amount)) | Group summary |
| 5 | =A1.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) | Associated calculation |
You can see , Relative to others JSON library ( Such as JsonPath)SPL The implementation of is simpler .
Again , Use SQL You can also check JSON data :
$select * from {json(file("/data/EO.json").read())}
where Amount>=100 and Client like 'bro' or OrderDate is nullSPL Agile syntax and process computing are also very suitable for complex computing , For example, based on stock records (txt) Calculate the longest consecutive days of a stock It can be written like this :
| A | |
| 1 | =T("/data/stock.txt") |
| 2 | [email protected](price<price[-1]).max(~.len())-1 |
Another example , According to the user login record (csv) List the last login interval of each user :
| A | ||
| 1 | =T(“/data/ulogin.csv”) | |
| 2 | =A1.groups(uid;top(2,-logtime)) | Last 2 Login records |
| 3 | =A2.new(uid,#2(1).logtime-#2(2).logtime:interval) | Calculation interval |
Such calculations are even based on database usage SQL It's also hard to write ,SPL It is very convenient to realize .
With SPL Out of Library computing support , Originally, various problems caused by the intermediate table of the database can be effectively solved . File storage no longer takes up database storage space , The pressure of database expansion decreases , The database is more convenient to manage ; Out of Library computing no longer occupies database computing resources , Database load reduction can better serve other businesses .

High performance file format
Although text is a very common form of data storage , It has the advantages of versatility and readability , however , The performance of text is very poor ! It is difficult to achieve high performance based on text .
Text characters cannot be calculated directly , Need to convert to an integer 、 The set of real Numbers 、 date 、 String and other memory data types can be further processed , Text parsing is a very complex task ,CPU Time consuming . In general , The main time of external memory data access is the reading of the hard disk itself , However, the performance bottleneck of text files often occurs in CPU link . Because of the complexity of parsing ,CPU It is likely to take more time than the hard disk ( Especially when using high-performance solid-state drives ). Text is usually not used when high-performance processing of large amounts of data is required .
SPL Provides two high-performance data storage formats , Set files and group tables . The set file is SPL Binary data format provided , Compression technology is adopted ( Smaller footprint and faster reading ), Stored data type ( There is no need to parse the data type, and reading is faster ), It also supports the multiplication and segmentation mechanism of appendable data , It is easy to realize parallel computing by using segmentation strategy , Further improve computing performance .
Group table is SPL Provide inventory 、 File storage format of indexing mechanism , The number of columns involved in the calculation ( Field ) When there is less inventory, it will have great advantages . The group table supports column storage , Realized minmax Index outside , It also supports the multiplication and segmentation mechanism , In this way, we can not only enjoy the advantages of inventory , It is also easier to improve parallel computing performance .
SPL Storage is very convenient , Basically consistent with the use of text , For example, read the set file and calculate :
| A | B | |
| 1 | =T("/data/scores.btx") | Read in set file |
| 2 | =A1.select(CLASS==10) | Filter |
| 3 | =A1.groups(CLASS;min(English),max(Chinese),sum(Math)) | Group summary |
If the amount of data is large , It also supports cursor batch reading and multiple CPU Parallel computing :
=file("/data/scores.btx")[email protected]()When using files as data storage , No matter what format the original data is , Finally, they must at least be converted into binary ( Such as set file ) Format , In this way, it will have more advantages in terms of space occupation and computing performance .

Manageability
After the intermediate table is transferred outside the library and stored by file , In addition to reducing the burden on the database , The intermediate table outside the library itself also has strong manageability . Files can be stored through the tree directory of the system , Easy to use and manage . Different systems 、 The intermediate tables used by different modules are stored in different directories very clearly , There will be no cross references , In this way, there will be no tight coupling problem before each system or module caused by the previous confusion of the use of intermediate tables in the database . If the corresponding function module is offline, you can safely delete the corresponding intermediate table data without worrying about the impact on other programs .

Multi data source support
In addition to file data sources ,SPL It also supports dozens of other data sources , You can not only connect and access , It can also complete mixed calculation .

After the intermediate table is stored in files, cross source calculation is involved in the full query with the real-time data in the database , Use SPL Complete such T+0 Inquiry is very convenient .
| A | ||
| 1 | =cold=file(“/data/orders.ctx”).open().cursor(area,customer,amount) | / Cold data from file system (SPL High performance storage ) To take , Yesterday's and previous data |
| 2 | =hot=db.cursor(“select area,customer,amount from orders where odate>=?”,date(now())) | |
| 3 | =[cold,hot].conjx() | / Heat data is taken from the production Library , Today's data |
| 4 | =A3.groups(area,customer;sum(amout):amout) | / Hybrid computing implementation T+0 |

Integration
SPL Provides standards JDBC and ODBC Call for interface supply . Specially , about Java Applications can put SPL Integrated into the application as an embedded engine , Make the application itself have intermediate ( data ) Table processing capacity .
JDBC call SPL Code example :
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement st = connection.();
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…SPL It's the interpretation of execution , Natural support for hot switching . be based on SPL Data calculation logic writing 、 There is no need to restart for modification and operation and maintenance , In real time , Development, operation and maintenance are also more convenient .
With the ability to calculate outside the Library SPL, Move the intermediate table to the file system , It can help the database eliminate tens of thousands of intermediate tables , While reducing the burden on the database , Get more flexibility 、 Faster performance and stronger scalability .

Previous recommendation
read How much disk does a byte of file actually take place on IO?
Docker Why is the container proud ? All supported by mirror image !
Redis What to do when the memory is full ? This is the correct setting !
The original hand of cloud 、 Good hands and bad hands

Share

Point collection

A little bit of praise

Click to see
边栏推荐
- list使用Stream流进行根据元素某属性数量相加
- Data Lake (XIV): spark and iceberg integrated query operation
- 10分钟帮你搞定Zabbix监控平台告警推送到钉钉群
- Reduce the cost by 40%! Container practice of redis multi tenant cluster
- ES6 drill down - Async functions and symbol types
- Quelques réflexions cognitives
- Some cognitive thinking
- 面对新的挑战,成为更好的自己--进击的技术er
- Solve the Hanoi Tower problem [modified version]
- 漫画:什么是蓝绿部署?
猜你喜欢
CISP-PTE之SQL注入(二次注入的应用)

抽象类中子类与父类

Cs231n notes (top) - applicable to 0 Foundation
![[deep learning] how does deep learning affect operations research?](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[deep learning] how does deep learning affect operations research?
Pits encountered in the use of boolean type in development
Starkware: to build ZK "universe"
Single merchant v4.4 has the same original intention and strength!
ES6 deep - ES6 class class
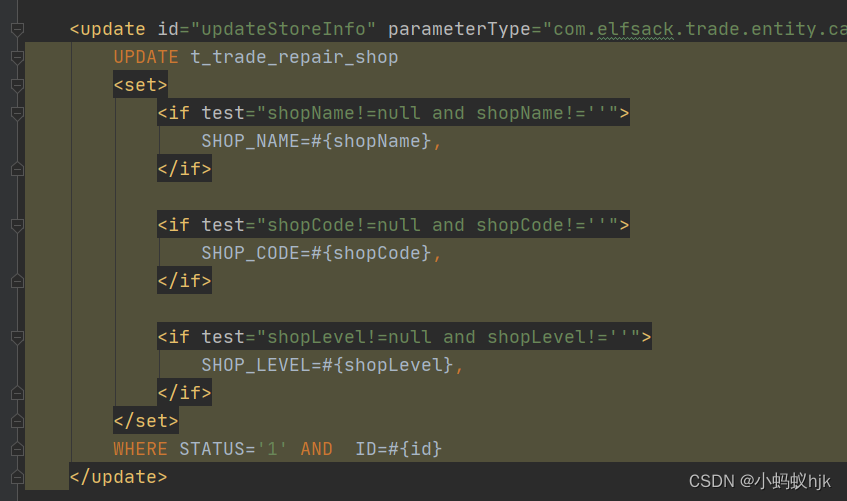
sql中set标签的使用

abstract关键字和哪些关键字会发生冲突呢
随机推荐
单商户 V4.4,初心未变,实力依旧!
国泰君安网上开户安全吗
Single merchant v4.4 has the same original intention and strength!
抽象类和接口的区别
有序链表集合求交集 方法 总结
What is the difference between EDI license and ICP business license
践行自主可控3.0,真正开创中国人自己的开源事业
Batch update in the project
给自己打打气
Exception com alibaba. fastjson. JSONException: not match : - =
Cartoon: what is blue-green deployment?
[深度学习][原创]让yolov6-0.1.0支持yolov5的txt读取数据集模式
yarn 常用命令
抽象类中子类与父类
RLock锁的使用
OneForAll安装使用
漫画:什么是分布式事务?
sql中set标签的使用
数据访问 - EntityFramework集成
Relationship between objects and classes