当前位置:网站首页>Cs231n notes (medium) -- applicable to 0 Foundation
Cs231n notes (medium) -- applicable to 0 Foundation
2022-07-05 15:55:00 【Small margin, rush】
Catalog
Pooling layer - Pooling layer - Convergence layer
Convolutional neural networks
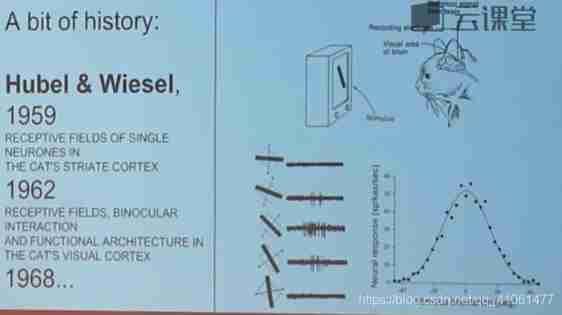
Conventional neural networks : The input of neural network is a vector , Then in a series of Cryptic layer Change it in . Each hidden layer is composed of several neurons , Are connected to all neurons in the previous layer . In a hidden layer , Neurons are independent of each other and do not make any connections . The last full connection layer is called “ Output layer ”, In the classification problem , Its output value is regarded as the rating value of different categories .
Convolutional neural network aims at the situation that the input is all images , Adjust the structure more reasonably , Its Neurons are 3 Dimensional arrangement : Width 、 Height and depth , Neurons in the layer will only connect to a small area in the previous layer , Instead of a full connection .
Network structure
Convolution layer
With parameters , There are some learnable filter sets , Each filter is in space ( Width and height ) They are all relatively small , But the depth is the same as the input data .
When it comes to forward propagation , Each filter slides across the width and height of the input data ( More precisely, convolution ), Then calculate the inner product of the whole filter and any part of the input data , Generate a 2 Activation diagram of dimension (activation map), The activation diagram shows the response of the filter at each spatial location .
Feel the field : The neurons in the latter layer are in the sensory space of the neurons in the former layer It can also be defined as the area size mapped by the pixel points on the feature map of each layer in the convolutional neural network in the original image

Hyperparameters :
depth , step ( When sliding the filter , Moving pixel bits ), Zero fill ( use 0 Fill at the edge )
The spatial size of the output data body can be obtained by inputting the size of the data body (W), The size of receptive field of neurons in convolution layer (F), step (S) And the number of zero fills (P) To calculate .
(W-F +2P)/S+1
Parameters of the Shared : Used to control the number of parameters . If a feature is useful , You can share it
demonstration
- The size of the input data body is

- 4 A super parameter : The number of filters K, Space size of filter F, step S. Zero fill quantity P
- Width and height of output dimension :
 , among W and H by (W-F +2P)/S+1,D2=k
, among W and H by (W-F +2P)/S+1,D2=k

 , among W and H by
, among W and H by Convolution is essentially a dot product between the filter and the local area of the input data .
1x1 Convolution : The depth of the filter and the input data body is the same , For input yes [32x32x3], that 1x1 Convolution is efficient 3 Dimensional point product
Expansion convolution : There are some element gaps in the filter , The receptive field increases
Pooling layer - Pooling layer - Convergence layer
A convergence layer is periodically inserted between successive convolution layers , Gradually reduce the spatial size of the data body .
- There are two super parameters : The size F, step S, The size calculation of output data is the same as that of convolution layer
- Zero padding is rarely used in the convergence layer
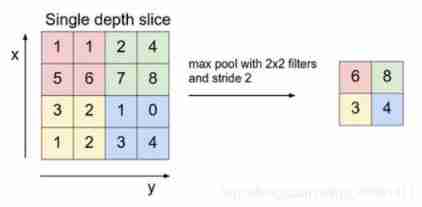
Maximum convergence
Fully connected layer
In the full connection layer , Neurons are fully connected to all activation data in the previous layer , Refer to the conventional neural network
The only difference between the full connection layer and the convolution layer is that the neurons in the convolution layer are only connected to a local area in the input data , And the neurons in the convolution column share parameters . The full connection layer can be transformed into a convolution layer
The arrangement of layers
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
The combination of several small filter convolution layers is better than one large filter convolution layer
A structure in which multiple convolution layers alternate with nonlinear activation layers , It can extract deeper and better features than the structure of a single convolution layer . The disadvantage is , In back propagation , The convolution layer in the middle may lead to more memory consumption .
Q&A:
- Why use zero padding ? Using zero padding can keep the output data of the convolution layer and the input data unchanged in the spatial dimension in addition to the above mentioned
- Why use in convolution layer 1 Step size of ? Smaller step size is better , In steps of 1 It can let the spatial dimension downsampling be all in the charge of the convergence layer , The convolution layer is only responsible for transforming the depth of the input data volume .
common CNN
LeNet: The first convolutional neural network
AlexNet:ImageNet2012 champion , Network structure and LeNet similar , Use the convolution layer to obtain features
ZF Net:2013 Champion can modify the super parameters in the structure to realize AlexNet Improvement of , Specifically, the size of the intermediate convolution layer is increased , Make the step size and filter size of the first layer smaller
GoogLeNet: Significantly reduce the number of parameters in the network ,Inception.
VGGNet:2014 runner-up , It shows that the depth of the network is the key part of the excellent performance of the algorithm . Consume more computing resources , And more parameters are used , Cause more memory usage
ResNet:2015 champion , Used a lot Batch normalization
边栏推荐
- lv_ font_ Conv offline conversion
- JS knowledge points-01
- Lesson 4 knowledge summary
- Linear DP (basic questions have been updated)
- Nine hours, nine people, nine doors problem solving Report
- queryRunner. Query method
- Bugku's eyes are not real
- Data communication foundation - route republication
- wxml2canvas
- verilog实现计算最大公约数和最小公倍数
猜你喜欢

vulnhub-Root_ this_ box
SQL injection sqllabs (basic challenges) 1-10
【简记】解决IDE golang 代码飘红报错

Object. defineProperty() - VS - new Proxy()
Appium automation test foundation - appium basic operation API (II)

我们为什么要学习数学建模?
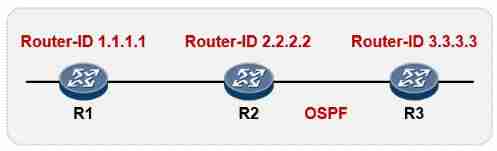
Data communication foundation OSPF Foundation

Optional parameters in the for loop

力扣今日题-729. 我的日程安排表 I
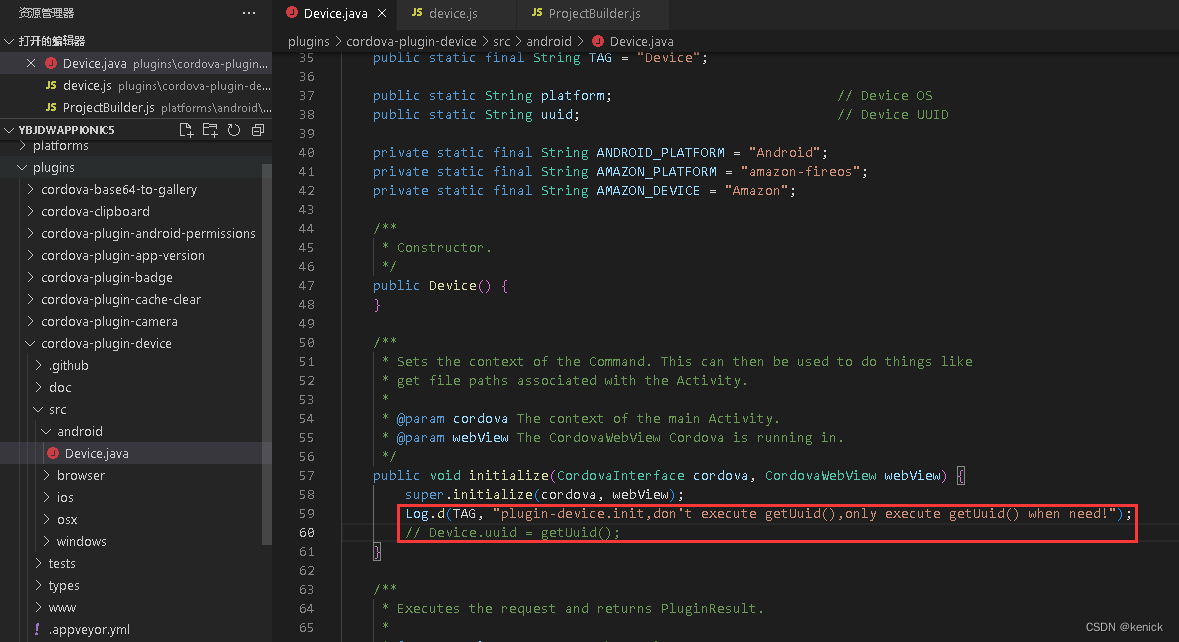
Ionic Cordova project modification plug-in
随机推荐
Modify PyUnit_ Time makes it support the time text of 'xx~xx months'
I'm fat, huh
19.[STM32]HC_ SR04 ultrasonic ranging_ Timer mode (OLED display)
Definition of episodic and batch
ICML 2022 | explore the best architecture and training method of language model
通过的英特尔Evo 3.0整机认证到底有多难?忆联科技告诉你
【简记】解决IDE golang 代码飘红报错
I include of spring and Autumn
Number protection AXB function! (essence)
开发中Boolean类型使用遇到的坑
MySQL overview
Array sorting num ranking merge in ascending order
Virtual base class (a little difficult)
后台系统发送验证码功能
复现Thinkphp 2.x 任意代码执行漏洞
把 ”中台“ 的思想迁移到代码中去
基于OpenHarmony的智能金属探测器
20. [stm32] realize the function of intelligent garbage can by using ultrasonic module and steering gear
mapper. Comments in XML files
vlunhub- BoredHackerBlog Social Network