当前位置:网站首页>漫画:什么是MapReduce?
漫画:什么是MapReduce?
2022-07-05 15:35:00 【小灰】
————— 第二天 —————
————————————
什么是MapReduce?
MapReduce是一种编程模型,其理论来自Google公司发表的三篇论文(MapReduce,BigTable,GFS)之一,主要应用于海量数据的并行计算。
MapReduce可以分成Map和Reduce两部分理解。
1.Map:映射过程,把一组数据按照某种Map函数映射成新的数据。
2.Reduce:归约过程,把若干组映射结果进行汇总并输出。
让我们来看一个实际应用的栗子,如何高效地统计出全国所有姓氏的人数?
我们可以利用MapReduce的思想,针对每个省的人口做并行映射,统计出若干个局部结果,再把这些局部结果进行整理和汇总:
这张图是什么意思呢?我们来分别解释一下步骤:
1.Map:
以各个省为单位,多个线程并行读取不同省的人口数据,每一条记录生成一个Key-Value键值对。图中仅仅是简化了的数据。
2.Shuffle
Shuffle这个概念在前文并未提及,它的中文意思是“洗牌”。Shuffle的过程是对数据映射的排序、分组、拷贝。
3.Reduce
执行之前分组的结果,并进行汇总和输出。
需要注意的是,这里描述的Shuffle只是抽象的概念,在实际执行过程中Shuffle被分成了两部分,一部分在Map任务中完成,一部分在Reduce任务中完成。
Hadoop如何实现MapReduce?
Hadoop是Apache基金会开发的一套分布式系统框架,包含多个组件,其核心就是HDFS和MapReduce。
由于篇幅原因,文本不会对Hadoop做完整的介绍,只是简单介绍一下Haddoop框架当中如何实现MapReduce。
下面这张图是Hadoop框架执行一个MapReduce Job的全过程:
这里需要对几种实体进行解释:
HDFS:
Hadoop的分布式文件系统,为MapReduce提供数据源和Job信息存储。
Client Node:
执行MapReduce程序的进程,用来提交MapReduce Job。
JobTracker Node:
把完整的Job拆分成若干Task,负责调度协调所有Task,相当于Master的角色。
TaskTracker Node:
负责执行由JobTracker指派的Task,相当于Worker的角色。这其中的Task分为MapTask和ReduceTask。
最后,祝愿有志向成为大数据工程师的小伙伴们,以及小灰的所有读者们,在新的一年顺利达成梦想!
—————END—————
边栏推荐
- 【网易云信】超分辨率技术在实时音视频领域的研究与实践
- This article takes you through the addition, deletion, modification and query of JS processing tree structure data
- Intelligent metal detector based on openharmony
- The list set is summed up according to a certain attribute of the object, the maximum value, etc
- Use of RLOCK lock
- 一键安装脚本实现快速部署GrayLog Server 4.2.10单机版
- Reproduce ThinkPHP 2 X Arbitrary Code Execution Vulnerability
- vant popup+其他组件的组合使用,及避坑指南
- Codasip adds verify safe startup function to risc-v processor series
- list去重并统计个数
猜你喜欢
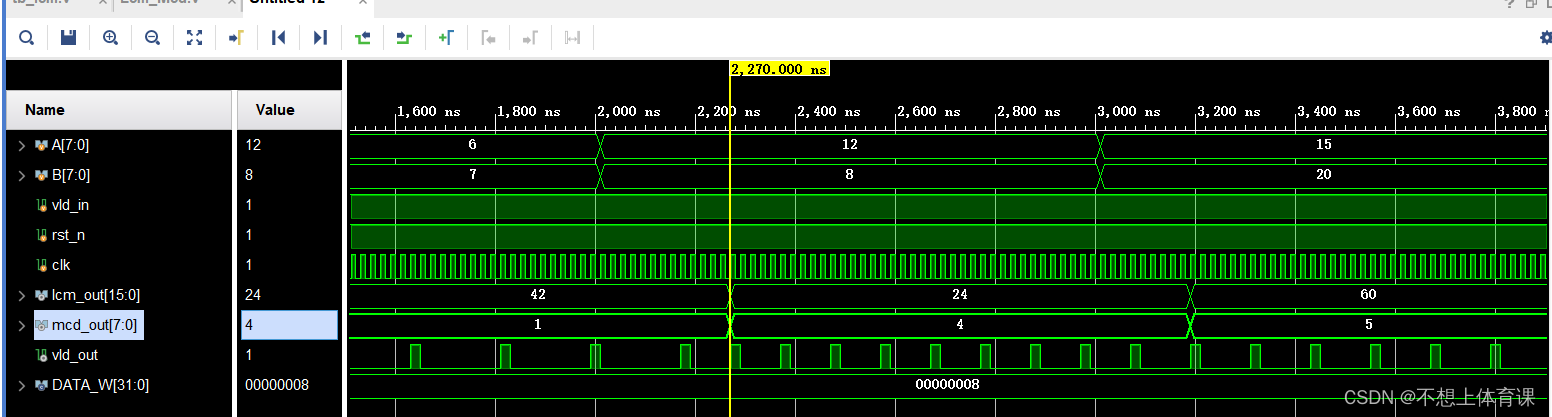
Verilog realizes the calculation of the maximum common divisor and the minimum common multiple
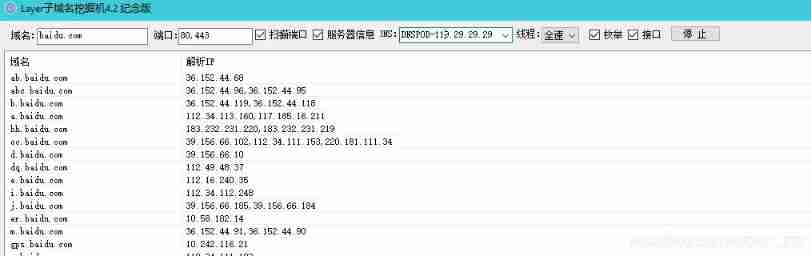
Information collection of penetration test

Li Kou today's question -729 My schedule I

Codasip为RISC-V处理器系列增加Veridify安全启动功能
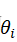
机械臂速成小指南(九):正运动学分析

CODING DevSecOps 助力金融企业跑出数字加速度
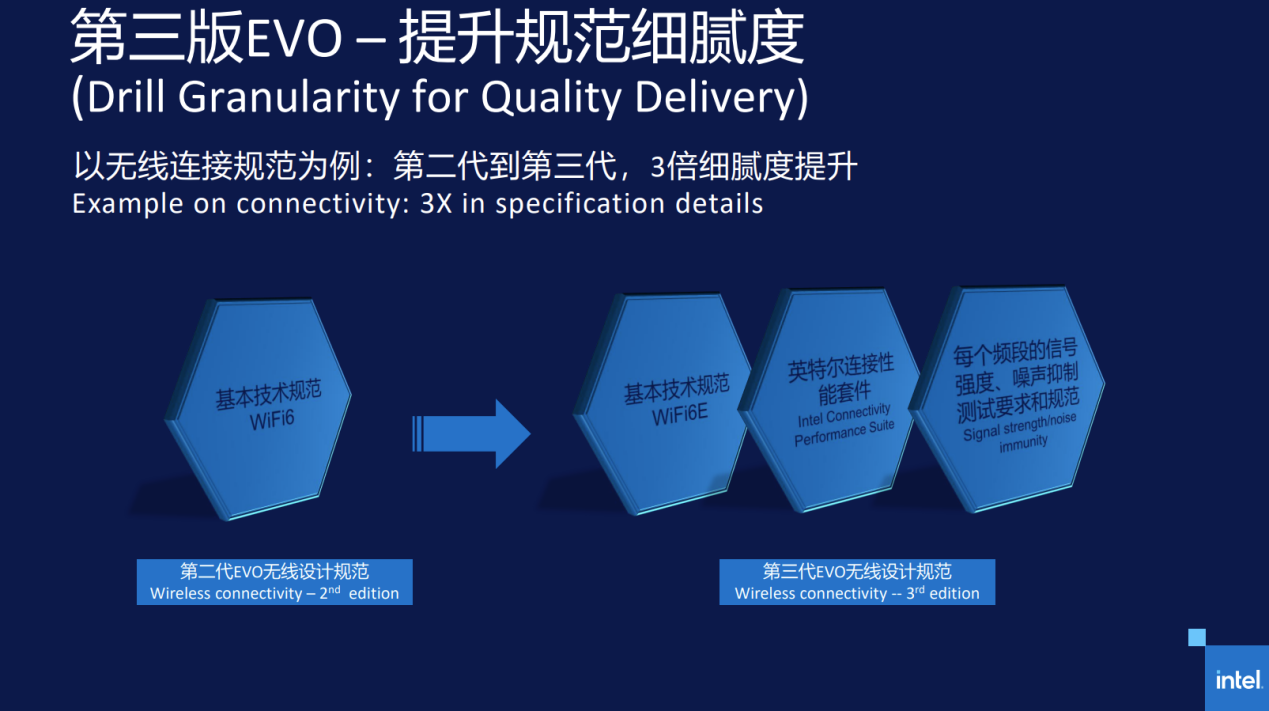
Defining strict standards, Intel Evo 3.0 is accelerating the upgrading of the PC industry
![18.[STM32]读取DS18B20温度传感器的ROM并实现多点测量温度](/img/e7/4f682814ae899917c8ee981c05edb8.jpg)
18.[STM32]读取DS18B20温度传感器的ROM并实现多点测量温度
![21. [STM32] I don't understand the I2C protocol. Dig deep into the sequence diagram to help you write the underlying driver](/img/f4/2c935dd9933f5cd4324c29c41ab221.png)
21. [STM32] I don't understand the I2C protocol. Dig deep into the sequence diagram to help you write the underlying driver
Data communication foundation - routing communication between VLANs
随机推荐
六种常用事务解决方案,你方唱罢,我登场(没有最好只有更好)
Background system sending verification code function
16.[STM32]从原理开始带你了解DS18B20温度传感器-四位数码管显示温度
Data communication foundation - Ethernet port mirroring and link aggregation
Data communication foundation - dynamic routing protocol rip
我们为什么要学习数学建模?
sql中查询最近一条记录
Write a go program with vscode in one article
【 note 】 résoudre l'erreur de code IDE golang
Xiao Sha's arithmetic problem solving Report
RLock锁的使用
Definition of episodic and batch
17.[STM32]仅用三根线带你驱动LCD1602液晶
Example project: simple hexapod Walker
Use of RLOCK lock
一文带你吃透js处理树状结构数据的增删改查
Appium自动化测试基础 — APPium基础操作API(一)
Codasip adds verify safe startup function to risc-v processor series
abstract关键字和哪些关键字会发生冲突呢
How difficult is it to pass the certification of Intel Evo 3.0? Yilian technology tells you