当前位置:网站首页>MapReduce instance (VI): inverted index
MapReduce instance (VI): inverted index
2022-07-06 09:33:00 【Laugh at Fengyun Road】
MR Realization Inverted index
Hello everyone , I am Fengyun , Welcome to my blog perhaps WeChat official account 【 Laugh at Fengyun Road 】, In the days to come, let's learn about big data related technologies , Work hard together , Meet a better self !
The principle of inverted index
- " Inverted index " It is the most commonly used data structure in document retrieval system , It is widely used in full text search engine .
- It's mainly used to store a word ( Or phrases ) Mapping of storage locations in a document or group of documents , That is, it provides a basis " Content to find documents " The way . Because it is not based on " Document to determine what the document contains " The content of , Instead, do the opposite , So it's called inverted index (Inverted Index)
- Realization " Inverted index " The main information of concern is : word 、 file URL And word frequency
Inverted index is mainly used to store a word ( Or phrases ) Mapping of storage locations in a document or group of documents , That is, it provides a basis " Content to find documents " The way .
Realize the idea
according to MapReduce The design idea of inverted index is given :
(1)Map The process
First, use the default TextInputFormat Class to process the input file , Get the offset of each line in the text and its content . obviously ,Map The process must first analyze the input <key,value> Yes , Get the three information needed in the inverted index : word 、 file URL And word frequency , Then we use the read data Map Operation for pretreatment , As shown in the figure below :
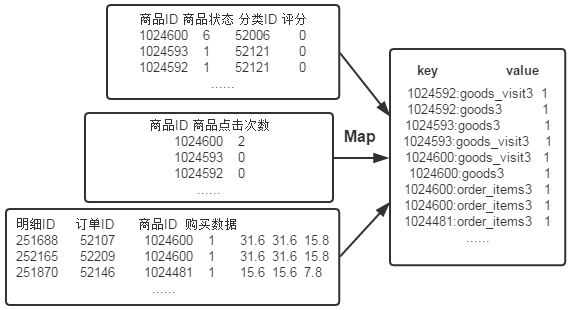
There are two problems :
First of all ,<key,value> Yes, there can only be two values , Without using Hadoop In the case of custom data types , Two of these values need to be combined into one value according to the situation , As key or value value .
second , Through one Reduce The process cannot complete word frequency statistics and generate document list at the same time , So we must add one Combine Process complete word frequency statistics .
Here's the product ID and URL form key value ( Such as "1024600:goods3"), Will word frequency ( goods ID Number of occurrences ) As value, The advantage of this is that you can take advantage of MapReduce The frame comes with Map End sort , Make a list of the word frequencies of the same words in the same document , Pass to Combine The process , The implementation is similar to WordCount The function of .
(2)Combine The process
after map Method after treatment ,Combine The process will key Same value value Value accumulation , Get the word frequency of a word in the document , As shown in the figure below . If you directly use the output shown in the following figure as Reduce Input to the process , stay Shuffle The process will face a problem : All records with the same word ( By word 、URL And word frequency ) It should be handed over to the same Reducer Handle , But the current key Value does not guarantee this , So we have to modify key Values and value value . This time, put the word ( goods ID) As key value ,URL And word frequency value value ( Such as "goods3:1"). The advantage of this is that you can take advantage of MapReduce Frame default HashPartitioner Class completion Shuffle The process , Send all records of the same word to the same Reducer To deal with .
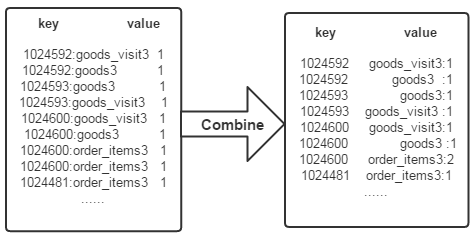
(3)Reduce The process
After the above two processes ,Reduce The process only needs to be the same key All that's worth value The values are combined into the format required by the inverted index file , The rest can be handed over directly to MapReduce The framework deals with . As shown in the figure below
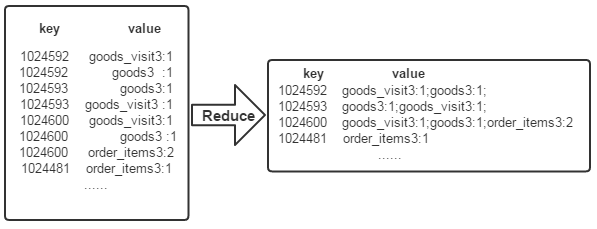
Code writing
Map Code
First, use the default TextInputFormat Class to process the input file , Get the offset of each line in the text and its content . obviously ,Map The process must first analyze the input <key,value> Yes , Get the three information needed in the inverted index : word 、 file URL And word frequency , There are two problems : First of all ,<key,value> Yes, there can only be two values , Without using Hadoop In the case of custom data types , Two of these values need to be combined into one value according to the situation , As key or value value . second , Through one Reduce The process cannot complete word frequency statistics and generate document list at the same time , So we must add one Combine Process complete word frequency statistics .
public static class doMapper extends Mapper<Object, Text, Text, Text>{
public static Text myKey = new Text(); // Store words and URL Combine
public static Text myValue = new Text(); // Stored word frequency
//private FileSplit filePath; // Storage Split object
@Override // Realization map function
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String filePath=((FileSplit)context.getInputSplit()).getPath().toString();
if(filePath.contains("goods")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("goods");
myKey.set(val[0] + ":" + filePath.substring(splitIndex));
}else if(filePath.contains("order")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("order");
myKey.set(val[2] + ":" + filePath.substring(splitIndex));
}
myValue.set("1");
context.write(myKey, myValue);
}
}
Combiner Code
after map Method after treatment ,Combine The process will key Same value value Value accumulation , Get the word frequency of a word in the document . If the output is directly used as Reduce Input to the process , stay Shuffle The process will face a problem : All records with the same word ( By word 、URL And word frequency ) It should be handed over to the same Reducer Handle , But the current key Value does not guarantee this , So we have to modify key Values and value value . This time use the word as key value ,URL And word frequency value value . The advantage of this is that you can take advantage of MapReduce Frame default HashPartitioner Class completion Shuffle The process , Send all records of the same word to the same Reducer To deal with .
public static class doCombiner extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override // Realization reduce function
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// Count the frequency of words
int sum = 0 ;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int mysplit = key.toString().indexOf(":");
// To reset value Values are determined by URL And word frequency
myK.set(key.toString().substring(0, mysplit));
myV.set(key.toString().substring(mysplit + 1) + ":" + sum);
context.write(myK, myV);
}
}
Reduce Code
After the above two processes ,Reduce The process only needs to be the same key It's worth it value The values are combined into the format required by the inverted index file , The rest can be handed over directly to MapReduce The framework deals with .
public static class doReducer extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override // Realization reduce function
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// Generate document list
String myList = new String();
for (Text value : values) {
myList += value.toString() + ";";
}
myK.set(key);
myV.set(myList);
context.write(myK, myV);
}
}
Complete code
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyIndex {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("InversedIndexTest");
job.setJarByClass(MyIndex.class);
job.setMapperClass(doMapper.class);
job.setCombinerClass(doCombiner.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in1 = new Path("hdfs://localhost:9000/mymapreduce9/in/goods3");
Path in2 = new Path("hdfs://localhost:9000/mymapreduce9/in/goods_visit3");
Path in3 = new Path("hdfs://localhost:9000/mymapreduce9/in/order_items3");
Path out = new Path("hdfs://localhost:9000/mymapreduce9/out");
FileInputFormat.addInputPath(job, in1);
FileInputFormat.addInputPath(job, in2);
FileInputFormat.addInputPath(job, in3);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, Text>{
public static Text myKey = new Text();
public static Text myValue = new Text();
//private FileSplit filePath;
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String filePath=((FileSplit)context.getInputSplit()).getPath().toString();
if(filePath.contains("goods")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("goods");
myKey.set(val[0] + ":" + filePath.substring(splitIndex));
}else if(filePath.contains("order")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("order");
myKey.set(val[2] + ":" + filePath.substring(splitIndex));
}
myValue.set("1");
context.write(myKey, myValue);
}
}
public static class doCombiner extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int sum = 0 ;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int mysplit = key.toString().indexOf(":");
myK.set(key.toString().substring(0, mysplit));
myV.set(key.toString().substring(mysplit + 1) + ":" + sum);
context.write(myK, myV);
}
}
public static class doReducer extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String myList = new String();
for (Text value : values) {
myList += value.toString() + ";";
}
myK.set(key);
myV.set(myList);
context.write(myK, myV);
}
}
}
-------------- end ----------------
WeChat official account : Below scan QR code or Search for Laugh at Fengyun Road Focus on 
边栏推荐
- 有软件负载均衡,也有硬件负载均衡,选择哪个?
- Mapreduce实例(十):ChainMapReduce
- 【深度学习】语义分割-源代码汇总
- Appears when importing MySQL
- Servlet learning diary 8 - servlet life cycle and thread safety
- Meituan Er Mian: why does redis have sentinels?
- Global and Chinese market of electronic tubes 2022-2028: Research Report on technology, participants, trends, market size and share
- 为什么要数据分层
- [Chongqing Guangdong education] reference materials for nine lectures on the essence of Marxist Philosophy in Wuhan University
- Redis' performance indicators and monitoring methods
猜你喜欢
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges
Design and implementation of online shopping system based on Web (attached: source code paper SQL file)

Selenium+Pytest自动化测试框架实战(下)
Mapreduce实例(九):Reduce端join
Sentinel mode of redis
Selenium+pytest automated test framework practice
![[three storage methods of graph] just use adjacency matrix to go out](/img/79/337ee452d12ad477e6b7cb6b359027.png)
[three storage methods of graph] just use adjacency matrix to go out
Publish and subscribe to redis

Advance Computer Network Review(1)——FatTree
随机推荐
Global and Chinese market of bank smart cards 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese market of cup masks 2022-2028: Research Report on technology, participants, trends, market size and share
Meituan Er Mian: why does redis have sentinels?
One article read, DDD landing database design practice
[daily question] Porter (DFS / DP)
Nacos installation and service registration
Servlet learning diary 7 -- servlet forwarding and redirection
Publish and subscribe to redis
O & M, let go of monitoring - let go of yourself
Different data-driven code executes the same test scenario
Redis之Bitmap
QDialog
Sentinel mode of redis
The five basic data structures of redis are in-depth and application scenarios
Le modèle sentinelle de redis
Advanced Computer Network Review(3)——BBR
[oc foundation framework] - < copy object copy >
Design and implementation of online snack sales system based on b/s (attached: source code paper SQL file)
Global and Chinese market of linear regulators 2022-2028: Research Report on technology, participants, trends, market size and share
Webrtc blog reference: