当前位置:网站首页>【深度学习】语义分割:论文阅读:(2021-12)Mask2Former
【深度学习】语义分割:论文阅读:(2021-12)Mask2Former
2022-07-06 09:02:00 【sky_柘】
详情
论文:Masked-attention Mask Transformer for Universal Image Segmentation
代码:
官方-代码
代码
视频:
b站论文讲解
笔记参考:
翻译版
摘要
Mask2Former在MaskFormer的基础上,
- 增加了masked attention机制,
- 另外还调整了decoder部分的self-attention和cross-attention的顺序,
- 还提出了使用importance sampling来加快训练速度。
本文的改进呢**主要是mask attention还有high-resolution features,**本质上是一个金字塔,剩下的一些关于训练上的还有optimization上改进呢,能够提高训练速度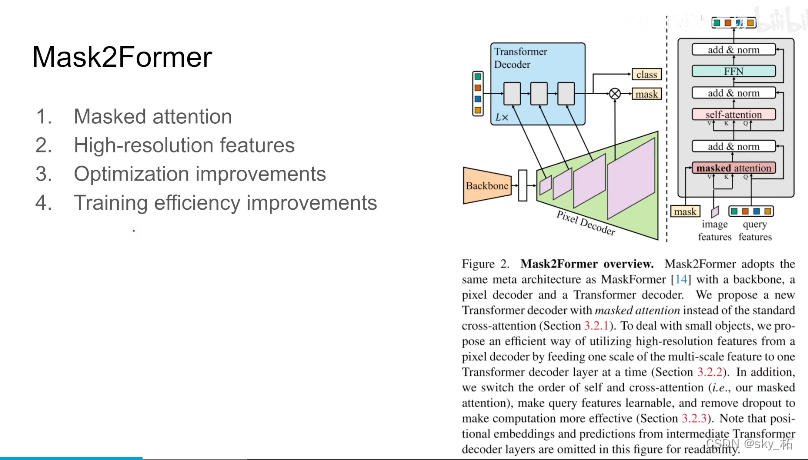
masked attention
我们知道decode里边有个masked attention的,就是控制哪两个token能产生attention。
这里作者使用一个大胆的假设,就是我们在做embeding的时候,我们只需要foreground这些区域,他们之间做attention就可以了,也就是原来在maskformer里边,每个像素和整张图像做attention,那么现在这个像素,只和自己同一个类别的,都是同一个qurey的像素,他们之间做attention。
这个是本文相对maskformer最主要的区别,最核心的贡献。
具体来看,maskformer里边q,k进来,这里的k,value呢,都是从图像的feature里边来,q呢是从之前query feature里边过来的,那在本作中呢,引入了mask,其实这个mask也就是标注了每个q,这里一个q代表一个类别,每个q对应的mask,在mask里边的这些像素,他们相互做attention,超过的,也就是说我们认为不是这一类的像素,不和它做attention。
在decoder结构里,image features是从pixel decoder里边来的,根据它呢对每个像素提取value,k。那query feature区别于前作,maskformer里边是0,这里是可学习的vector。它们先做mask attention。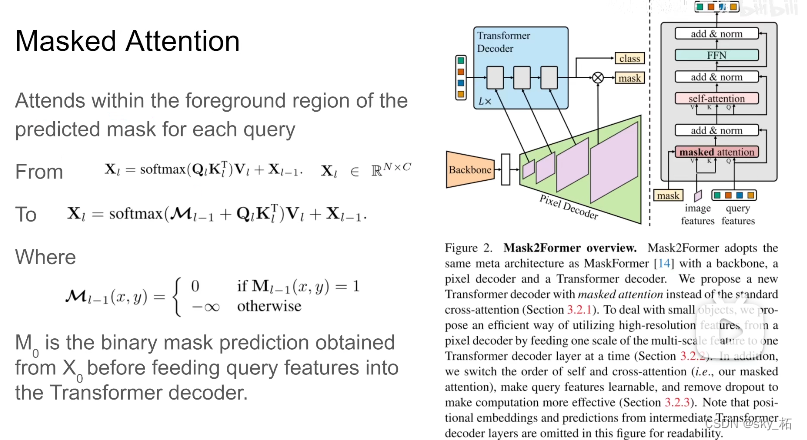
这个mask怎么产生呢,回顾于一下,在maskformer里边,每个q出来。通过mlp产生一个embeding,根据这个embeding再和pixel embeding结合,就得到关于mask 的prediction ,那么这个mask就是mask2former decoder里输入的mask,也就是对于第0层的decoder来说,我们还没有经过transformer decoder,首先呢把这些qurey 送到 mlp里边,然后预测出这个mask出来,然后我们在做decoder,一层一层往下做就可以了,比如说过完一层,我们有新的query,那么同样的,新的query送到mlp里边。做一个mask出来,然后加上新的image feature,为什么新的呢,下面再讲,然后再重复decoder过程就可以了,那么这个就是核心的mask attention原理。
为什么query feature 不再是zero 而是一个learning frature,因为在过decoder之前,要根据这些feature预测一个mask,那么这是一个必要的更改、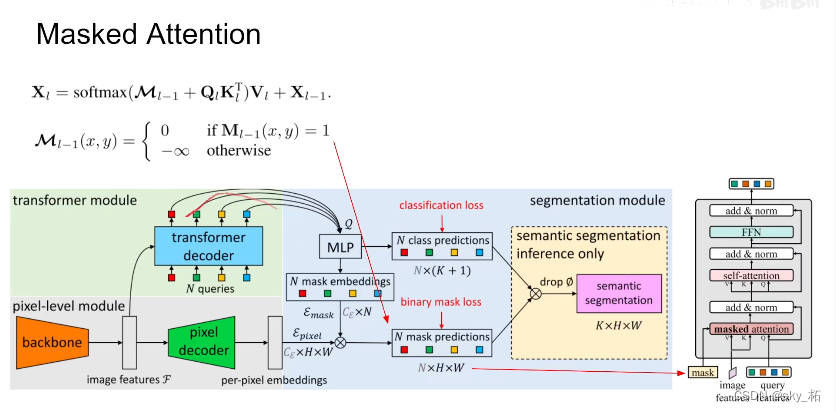
High-resolution features
本质就是图像金字塔,这里作者选用了原始图像的32分之一,16分之一,8分之一的三个尺度的图像的feature呢,送到decoder,也就是第一层32分之一尺度的,做完一层decoder得到query,然后第二层呢,16分之一尺度的,再做同样的decoder,然后不断重复三层的结构,重复L次,比如L是3,那么decoder里边有9层这样的结构。
而对于每个resolution来说呢,首先是一个正弦的position embeding,同时还引入了1 x C的可学习的scale-level embeding,来控制每个chanel 的scale,那这个呢,就是作者应对如何high-resolution feature
那么金字塔之后呢,再来关注一下,在原来的maskformer之上d做了哪些细节的调整。
经典的decoder,一上来先做token之间的self-attention ,然后在做这个 以image feature 引入的k,vaiue的mask attention。
作者这里把顺序更改了一下,因为假如你一上来先对query之间做self attention,它本来就没有任何图像的信息,这样做出了也没有什么意义,所以这里作者把顺序更改了一下第二个改动。query feature是可学习的,因为一上来要用query feature来预测mask,所以现在query feature是可学习的
第三个是dropout会影响模型的性能,同时让训练速度减慢,所以直接把dropout去掉
此外那,作者为了增加训练的效率,利用采样点来替代整个mask。简单来说就是原来计算loss,都是一整张图,每个像素,他的maks形状对不对,他的分类的对不对,一整张图,非常占内存,而且效率很低。
这里呢作者随机采样几个点,用采样的方法,相当于用像素更少的像素点,来去形成loss,这样能大幅节约我们训练每张图时使用的内存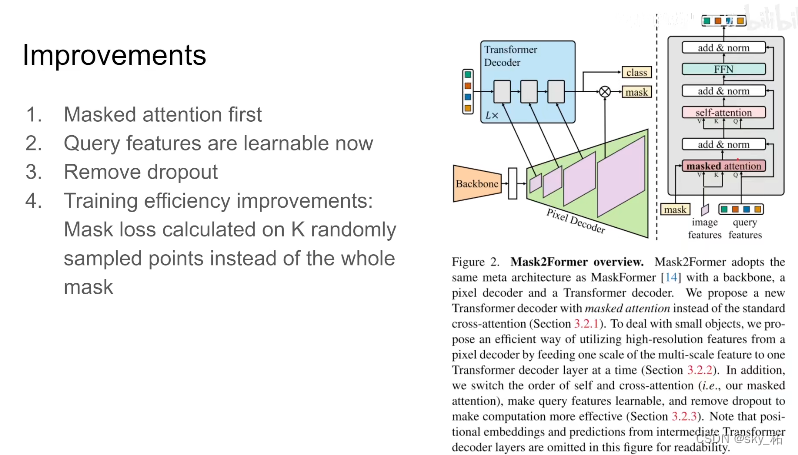
详细介绍
笔记参考:
详细笔记
知乎提问-如何评价FAIR提出的图像分割方法Mask2Former,效果超过MaskFormer和K-Net?
作者:大大拉头
链接:https://www.zhihu.com/question/503340099/answer/2256299264
来源:知乎
1, 首先看标题,这个是叫做Universal Image Segmentation,应该是说想用一个model去建模所有的分割任务:语义分割,实例分割和以及全景分割。不同之前的一些Unified Segmentation(Max-Deeplab, K-Net, Maskformer),作者想表达的意思是他们model可以beat COCO上的各个分割任务上的最新的STOA,这个就是他们teaser的观点。
2, 接下来是模型本身,Mask2Former是基于MaskFormer的。
回顾下MaskFormer, 以全景分割为例,MaskFormer基于DETR的setting,
- 去掉了DETR里面的Heavy Segmentation Head 和 box prediction,额外增加一个pixel decoder出segmentation feature,
- 然后用DETR中的输出的object query和segmentation feature直接出mask的分类和分割,
主要的insight是MaskFormer证明了只用mask classification就够了,给出了一个简洁的solid的baseline。
但是MaskFormer里面的两个问题没有解决,
- 一个是300 epoch的训练效率,
- 一个是大的显存和计算的开销。
因此,作者**基于上述的问题和最初的motivation(**一个模型取得三个不同分割任务STOA),提出了几个改进,在节省训练的时间和cost的同时能够提升性能。
第一个是masked attention,相比于之前的cross attention,这个里面的attention affinity是一种稀疏的attention,大致思想有点类似于Sparse-RCNN中 对 Query Feature的ROI align 和 K-Net中的MaskGrouping等操作,只对有object的region做attention。
看代码,这里的Mask0是由一个额外的Learnable query features 产生的第二个改进是用了multi scale的特征,作者使用了类似于Deformable DETR decoder端的设置,在decoder端采用了multi scale的特征输入做attention。这个步骤对于提升small object的segmentation帮助很大。1/8 特征虽然最好,但是还是不够efficient。
第三个改进是一些简单有效的设计:
第一个是使用类似于PointRend中点监督的方法来降低显存开销,这个的好处还有一点是可以训练更大的model,因此看作者的代码,他们使用了更多的decoder(9个>6个)来进行迭代更多的scale(3个scale)。
第二个是更换cross attention和 self attention的位置以及去掉dropout等等。
此外相比之前MaskFormer,这里的pixel decoder用的是 Deformable DETR的形式去融合不同层的特征。pixel decoder 的增强可以看到对AP的影响更大,个人猜测还是small object的seg提升。
边栏推荐
- xargs命令的基本用法
- 软件负载均衡和硬件负载均衡的选择
- Design and implementation of online shopping system based on Web (attached: source code paper SQL file)
- Five layer network architecture
- [OC foundation framework] - [set array]
- Detailed explanation of cookies and sessions
- Persistence practice of redis (Linux version)
- CAP理论
- Redis' performance indicators and monitoring methods
- Global and Chinese market of AVR series microcontrollers 2022-2028: Research Report on technology, participants, trends, market size and share
猜你喜欢

CUDA realizes focal_ loss
Redis之持久化实操(Linux版)
BN folding and its quantification
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"

An article takes you to understand the working principle of selenium in detail

运维,放过监控-也放过自己吧
Le modèle sentinelle de redis
Redis cluster
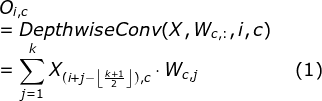
A convolution substitution of attention mechanism
Selenium+Pytest自动化测试框架实战
随机推荐
AcWing 2456. Notepad
Go redis initialization connection
[Yu Yue education] reference materials of complex variable function and integral transformation of Shenyang University of Technology
Use of activiti7 workflow
The carousel component of ant design calls prev and next methods in TS (typescript) environment
Redis分布式锁实现Redisson 15问
What is MySQL? What is the learning path of MySQL
YARN组织架构
工作流—activiti7环境搭建
Seven layer network architecture
基于B/S的网上零食销售系统的设计与实现(附:源码 论文 Sql文件)
不同的数据驱动代码执行相同的测试场景
Different data-driven code executes the same test scenario
Redis core configuration
为什么要数据分层
有软件负载均衡,也有硬件负载均衡,选择哪个?
Redis connection redis service command
Global and Chinese market of linear regulators 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese markets for small seed seeders 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese market of electric pruners 2022-2028: Research Report on technology, participants, trends, market size and share