当前位置:网站首页>Reids之缓存预热、雪崩、穿透
Reids之缓存预热、雪崩、穿透
2022-07-06 08:59:00 【~庞贝】
目录
Reids之缓存预热
1.问题
数据库启动后迅速宕机
2.问题排查
1.请求数量较高
2.主从之间数据吞吐量较大,数据同步操作频度较高
通俗解释 :即数据库启动后,缓存里面没有数据,数据库服启动的一瞬间请求又非常多,自然为服务器带来压力,于是就会宕机
3.缓存预热介绍
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
4.解决方案
前置准备工作:
1.日常例行统计数据访问记录,统计访问频度较高的热点数据(手工方式)
2.利用LRU数据删除策略,构建数据留存队列,例如:storm与kafka配合(自动方式)
准备工作:
1.将统计结果中的数据分类,根据级别,redis优先加载级别较高的热点数据
2.利用分布式多服务器同时进行数据读取,提速数据加载过程
3.热点数据主从同时预热
实施:
1.手工方式不太现实,可以使用脚本程序固定触发数据预热过程
2.如果条件允许,使用了CDN(内容分发网络),效果会更好
Redis之缓存雪崩
1.数据库服务器崩溃问题
1.系统平稳运行过程中,忽然数据库连接量激增
2.应用服务器无法及时处理请求
3.大量408,500错误页面出现
4.客户反复刷新页面获取数据
5.数据库崩溃
6.应用服务器崩溃
7.重启应用服务器无效
8.Redis服务器崩溃(一台一台的紧接着崩溃)
9.Redis集群崩溃
10.重启数据库后再次被瞬间流量放倒
注:以上的问题按着时间顺序依次发生
2.问题排查
1.在一个较短的时间内,缓存中较多的key集中过期(在实际开发当中,是有很多定时key的,因为内存大小有限)
2.此周期内请求访问过期的数据,redis未命中,redis向数据库获取数据
3.数据库同时接收到大量的请求无法及时处理
4.Redis大量请求被积压,开始出现超时现象
5.数据库流量激增,数据库崩溃
6.重启后仍然面对缓存中无数据可用
7.Redis服务器资源被严重占用,Redis服务器崩溃
8.Redis集群呈现崩塌,集群瓦解
9.应用服务器无法及时得到数据响应请求,来自客户端的请求数量越来越多,应用服务器崩溃
10.应用服务器,redis,数据库全部重启,效果不理想,因为仍然没有缓存,即使rdb恢复也不行,因为key是过期的
3.问题分析
1.短时间范围内
2.大量key集中过期
4.解决方案(道)
1.更多的页面静态化处理
2.构建多级缓存架构
Nginx缓存+redis缓存+ehcache缓存
3.检测Mysql严重耗时业务进行优化
对数据库的瓶颈排查:例如超时查询、耗时较高事务等
4.灾难预警机制
监控redis服务器性能指标
1)CPU占用、CPU使用率
2)内存容量
3)查询平均响应时间
4)线程数
5.限流、降级
短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问
5.解决方案(术)
1.LRU与LFU切换
2.数据有效期策略调整
1)根据业务数据有效期进行分类错峰,A类90分钟,B类80分钟,C类70分钟
2)过期时间使用固定时间+随机值的形式,稀释集中到期的key的数量
3.超热数据使用永久key
4.定期维护(自动+人工)
用自动脚本的方式及维护,或者人工的方式维护,对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据的延时
5.加锁(慎用!):
拿到锁的可以干活,拿不到的不能干活
6.缓存雪崩介绍
缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如能够有效避免过期时间集中,可以有效解决雪崩现象的出现(约40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t2vX4JcV-1656728445660)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220701211016177.png)]](/img/54/48536b7f3465a28c4479e01b8a3547.png)
Redis之缓存穿透
1.数据库服务器崩溃问题
1.系统平稳运行过程中
2.应用服务器流量随时间增量较大
3.Redis服务器命中率随时间逐步降低
4.Redis内存平稳,内存无压力
5.Redis服务器CPU占用激增
6.数据库服务器压力激增
7.数据库崩溃
2.问题排查
1.Redis中大面积出现未命中
2.出现非正常URL访问
3.问题分析
1.获取的数据在数据库中也不存在,数据库查询未得到对应数据
2.Redis获取到null数据未进行持久化,直接返回
3.下次此类数据到达重复上述过程
4.出现黑客攻击服务器
4.解决方案(术)
1.缓存null
对查询结果为null的数据进行缓存(长期使用,定期清理),设定短时限,例如30-60秒,最高5分钟(不能设置时间太长,否则redis内存太满)
2.白名单策略
1)提前预热各种分类数据id对应的bitmaps,id作为bitmaps的offset,相当于设置了数据白名单。当加载正常数据时,放行,加载异常数据时直接拦截(效率偏低)
2)使用布隆过滤器(布隆过滤器不一定全部命中,有关布隆过滤器的命中问题对当前状况的来说可以忽略)
3.实施监控
实时监控redis命中率(业务正常范围时,通常会有一个波动值)与null数据的占比
1)非活动时段波动:通常检测3-5倍,超过5倍纳入重点排查对象(无节日)
2)活动时段波动:通常检测10-50倍,超过50倍纳入重点排查对象(双十一)
根据倍数不同,启动不同的排查流程。然后使用黑名单进行防控(运营)
4.key加密
问题出现后,临时启动防灾业务key,对key进行业务层传输加密服务,设定校验程序,过来的key校验
例如每天随机分配60个加密串,挑选2到3个,混淆到页面数据id中,发现访问key不满足规则,驳回数据访问
5.缓存穿透介绍
缓存击穿访问了不存在的数据,跳过了合法数据的redis数据缓存阶段,每次访问数据库,导致对数据库服务器造成压力。通常此类数据的出现量是一个较低的值,当出现此类情况以毒攻毒,并及时报警。应对策略应该在临时预案防范方面多做文章。
无论是黑名单还是白名单,都是对整体系统的压力,警报解除后尽快移除
边栏推荐
- CUDA implementation of self defined convolution attention operator
- 力扣每日一题(二)
- Selenium+pytest automated test framework practice
- 不同的数据驱动代码执行相同的测试场景
- Intel Distiller工具包-量化实现2
- 甘肃旅游产品预订增四倍:“绿马”走红,甘肃博物馆周边民宿一房难求
- Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges
- LeetCode:498. Diagonal traversal
- Redis之Bitmap
- ant-design的走马灯(Carousel)组件在TS(typescript)环境中调用prev以及next方法
猜你喜欢

Once you change the test steps, write all the code. Why not try yaml to realize data-driven?
Advanced Computer Network Review(3)——BBR

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
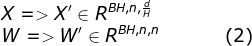
CUDA implementation of self defined convolution attention operator

Redis之Bitmap

不同的数据驱动代码执行相同的测试场景
Alibaba cloud server mining virus solution (practiced)
LeetCode:498. Diagonal traversal

Post training quantification of bminf
随机推荐
[OC]-<UI入门>--常用控件-提示对话框 And 等待提示器(圈)
UML图记忆技巧
LeetCode41——First Missing Positive——hashing in place & swap
Cesium draw points, lines, and faces
MYSQL卸载方法与安装方法
Selenium+Pytest自动化测试框架实战
UML圖記憶技巧
[Hacker News Weekly] data visualization artifact; Top 10 Web hacker technologies; Postman supports grpc
Nacos installation and service registration
【shell脚本】使用菜单命令构建在集群内创建文件夹的脚本
CUDA实现focal_loss
[MySQL] multi table query
Pytest之收集用例规则与运行指定用例
After reading the programmer's story, I can't help covering my chest...
【剑指offer】序列化二叉树
ant-design的走马灯(Carousel)组件在TS(typescript)环境中调用prev以及next方法
Redis之性能指标、监控方式
Leetcode: Sword Finger offer 42. Somme maximale des sous - tableaux consécutifs
Problems encountered in connecting the database of the project and their solutions
What is an R-value reference and what is the difference between it and an l-value?