当前位置:网站首页>Intel distiller Toolkit - Quantitative implementation 2
Intel distiller Toolkit - Quantitative implementation 2
2022-07-06 08:57:00 【cyz0202】
This series of articles
Intel Distiller tool kit - Quantitative realization 1
Intel Distiller tool kit - Quantitative realization 2
review
- Last article This paper introduces the in Distiller And Quantizer Base class , Base classes define important variables , Such as replacement_factory(dict, Used to record to be quantified module Corresponding wrapper); In addition, the quantitative process is defined , Include Preprocessing (BN Fold , Activate optimization, etc )、 Quantization module replacement 、 post-processing And other main steps ;
- This article introduces inheritance from Quantizer Subclass quantizer of , Include
- PostTrainLinearQuantizer( this paper )
- QuantAwareTrainRangeLinearQuantizer( follow-up )
- PACTQuantizer( follow-up )
- NCFQuantAwareTrainQuantizer( follow-up )
- There are many codes in this article , Because I can't post them all , Some places are not clear , Please also refer to the source code ;
PostTrainLinearQuantizer
- Post training quantizer ; Quantify the trained model , You need to use a small amount of input to collect the internal input of the model 、 Output 、 Weight statistics ;
- PostTrainLinearQuantizer The class definition of is as follows : The main content is in the constructor , Let's introduce ; The other is to add pretreatment (BN Fold 、 Activate layer optimization ) etc. ;

- Constructors : The point is

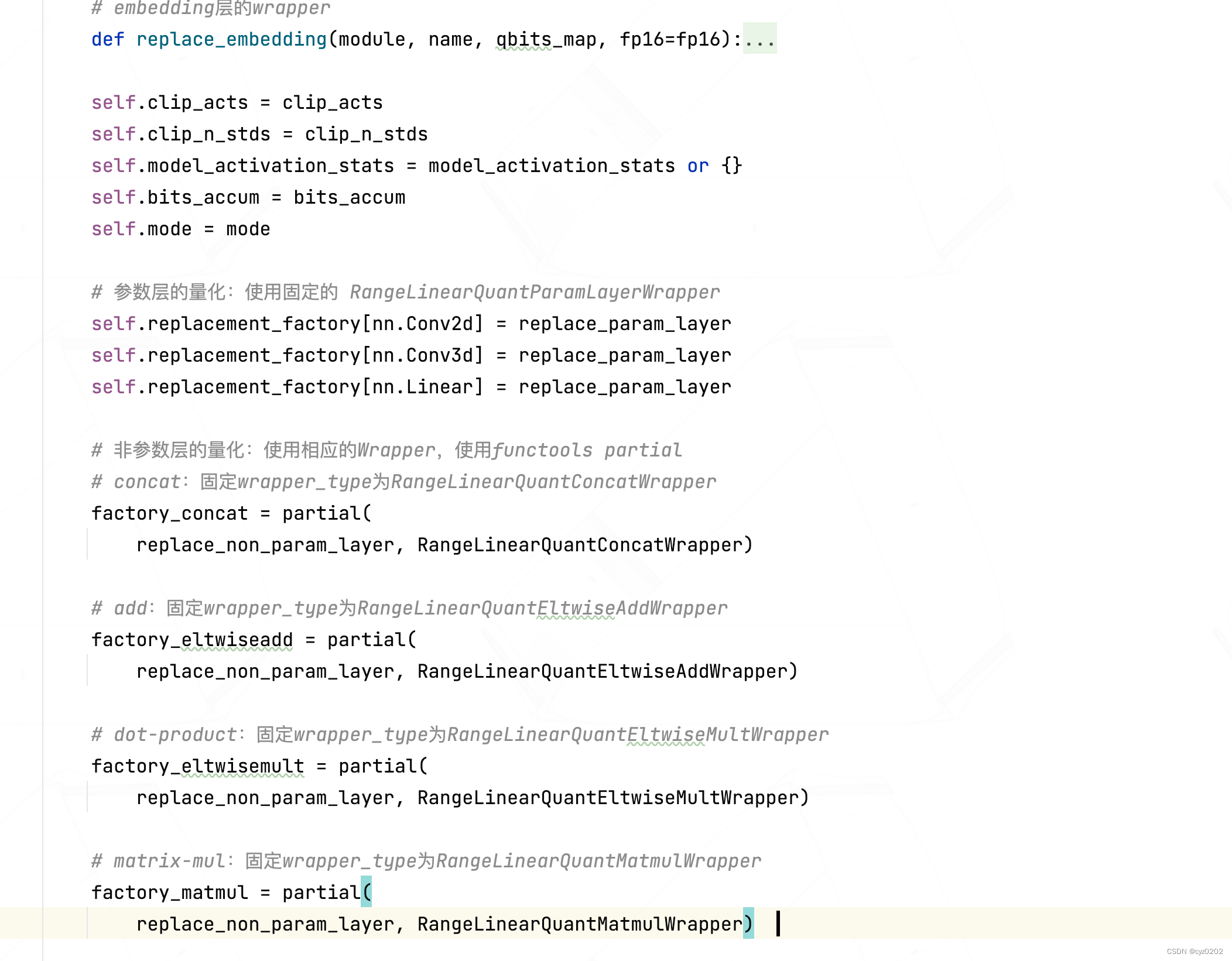
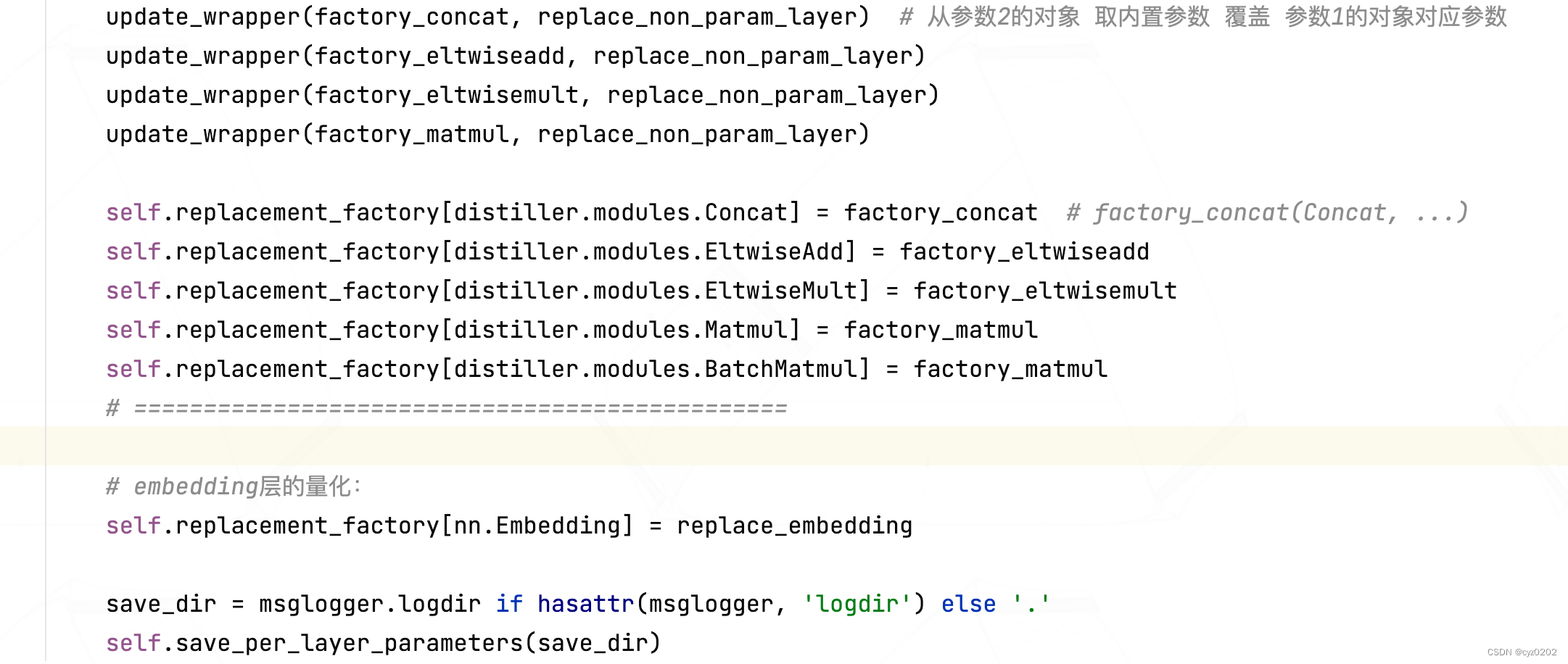
- In the constructor , Check and default settings are all in the front ( Such as quantitative mode check 、clip Model checking 、 Is there any statistical data 、 Default quantization settings, etc ); Until the following code , It's just PostTrainLinearQuantizer The core
#### PART1- Quantification of parameter layer : Use fixed RangeLinearQuantParamLayerWrapper #### self.replacement_factory[nn.Conv2d] = replace_param_layer self.replacement_factory[nn.Conv3d] = replace_param_layer self.replacement_factory[nn.Linear] = replace_param_layer #### PART2- Quantification of nonparametric layer : Use corresponding Wrapper, Use functools partial #### # concat: Fix wrapper_type by RangeLinearQuantConcatWrapper factory_concat = partial( replace_non_param_layer, RangeLinearQuantConcatWrapper) # add: Fix wrapper_type by RangeLinearQuantEltwiseAddWrapper factory_eltwiseadd = partial( replace_non_param_layer, RangeLinearQuantEltwiseAddWrapper) # dot-product: Fix wrapper_type by RangeLinearQuantEltwiseMultWrapper factory_eltwisemult = partial( replace_non_param_layer, RangeLinearQuantEltwiseMultWrapper) # matrix-mul: Fix wrapper_type by RangeLinearQuantMatmulWrapper factory_matmul = partial( replace_non_param_layer, RangeLinearQuantMatmulWrapper) update_wrapper(factory_concat, replace_non_param_layer) # From parameter 2 The object of Take the built-in parameters Cover Parameters 1 Corresponding parameters of the object update_wrapper(factory_eltwiseadd, replace_non_param_layer) update_wrapper(factory_eltwisemult, replace_non_param_layer) update_wrapper(factory_matmul, replace_non_param_layer) self.replacement_factory[distiller.modules.Concat] = factory_concat # factory_concat(Concat, ...) self.replacement_factory[distiller.modules.EltwiseAdd] = factory_eltwiseadd self.replacement_factory[distiller.modules.EltwiseMult] = factory_eltwisemult self.replacement_factory[distiller.modules.Matmul] = factory_matmul self.replacement_factory[distiller.modules.BatchMatmul] = factory_matmul # =============================================== #### PART3-embedding Quantification of layers :#### self.replacement_factory[nn.Embedding] = replace_embedding - As the code Notes say , The code is respectively right Quantifiable parameter layer 、 Nonparametric layer 、embedding Layer for quantitative settings
- Parameter layer :
- With nn.Conv2d For example :self.replacement_factory[nn.Conv2d] = replace_param_layer
- Express nn.Conv2d This module Will be replace_param_layer Generated quantitative version module Replace
- Let's see replace_param_layer What does it look like ?
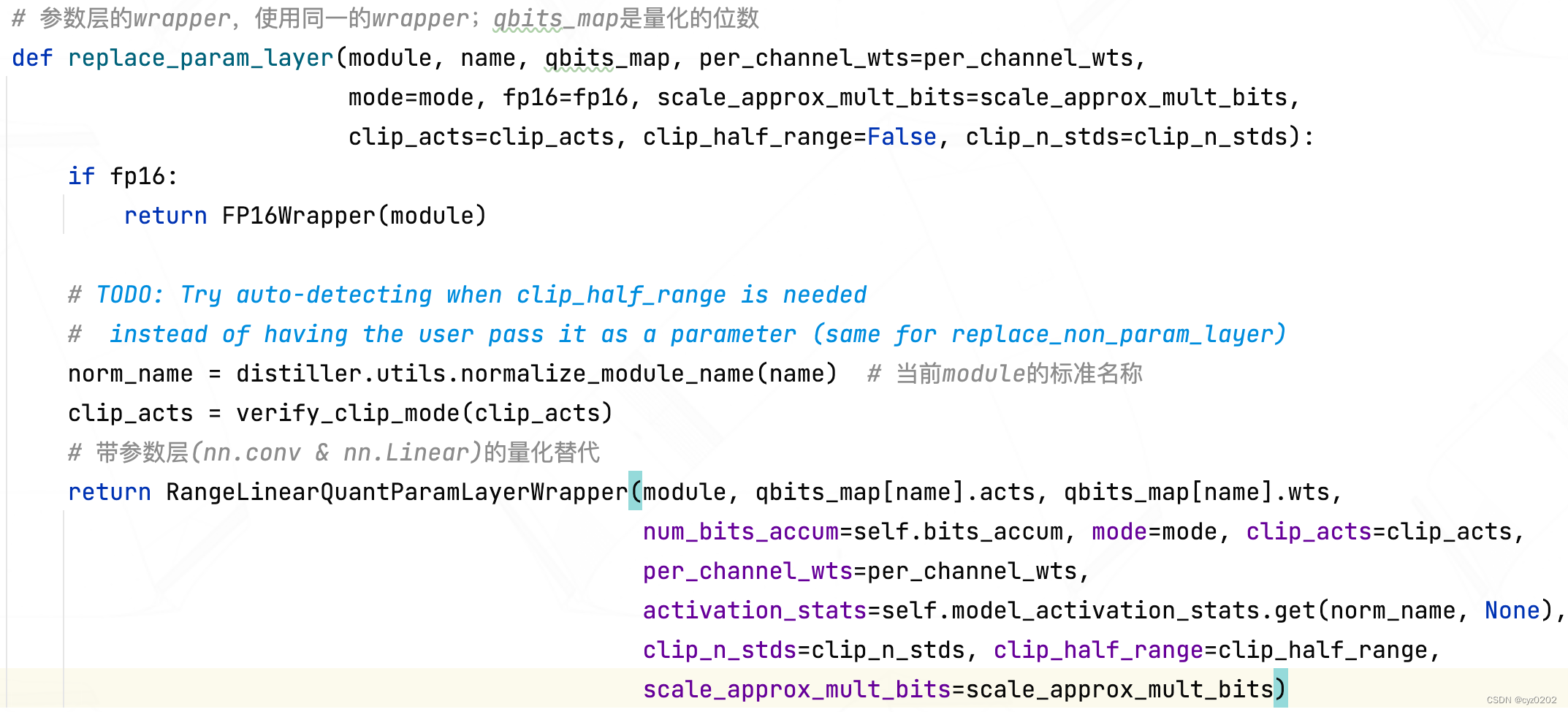
- You can see replace_param_layer In the face of module( Here it means nn.Conv2d) When packaging , In fact, the return is RangeLinearQuantParamLayerWrapper object ( It's a nn.Module, New module Replace the old module); So let's take a look at this wrapper How objects are implemented ;
- RangeLinearQuantParamLayerWrapper Inherited from RangeLinearQuantWrapper, You need to look at the base class first RangeLinearQuantWrapper The definition of :

- Let's focus on forward function :

- RangeLinearQuantParamLayerWrapper According to the base class RangeLinearQuantWrapper The definition of and their own needs to achieve related functions , Mainly quantized_forward and get_accum_to_output_re_quantization_params; The specific definitions are as follows
# The method of parameter layer quantification is defined class RangeLinearQuantParamLayerWrapper(RangeLinearQuantWrapper): """ Linear range-based quantization wrappers for layers with weights and bias (namely torch.nn.ConvNd and torch.nn.Linear) Assume: x_q = round(scale_x * x_f) - zero_point_x Hence: x_f = 1/scale_x * x_q + zero_point_x # Write according to the following , Should be 1/scale_x * (x_q + zero_point_x) (And the same for y_q, w_q and b_q) So, we get: (use "zp" as abbreviation for zero_point) y_f = x_f * w_f + b_f # The following is omitted except the first step round, Notice in brackets ,bias As a re-quant-bias There is , That is, when it is implemented round()-0 y_q = round(scale_y * y_f) - zp_y = scale_y * (x_f * w_f + b_f) - zp_y = scale_y scale_x * scale_w = ------------------- * [(x_q + zp_x) * (w_q + zp_w) + ------------------- * (b_q + zp_b)] - zp_y scale_x * scale_w scale_b Args: wrapped_module (torch.nn.Module): Module to be wrapped num_bits_acts (int): Number of bits used for inputs and output quantization num_bits_params (int): Number of bits used for parameters (weights and bias) quantization num_bits_accum (int): Number of bits allocated for the accumulator of intermediate integer results mode (LinearQuantMode): Quantization mode to use (symmetric / asymmetric-signed/unsigned) clip_acts (ClipNode): See RangeLinearQuantWrapper per_channel_wts (bool): Enable quantization of weights using separate quantization parameters per output channel activation_stats (dict): See RangeLinearQuantWrapper clip_n_stds (int): See RangeLinearQuantWrapper clip_half_range (bool) : See RangeLinearQuantWrapper scale_approx_mult_bits (int): See RangeLinearQuantWrapper( Whether to use integer processing scale) """ def __init__(self, wrapped_module, num_bits_acts, num_bits_params, num_bits_accum=32, mode=LinearQuantMode.SYMMETRIC, clip_acts=ClipMode.NONE, per_channel_wts=False, activation_stats=None, clip_n_stds=None, clip_half_range=False, scale_approx_mult_bits=None): super(RangeLinearQuantParamLayerWrapper, self).__init__(wrapped_module, num_bits_acts, num_bits_accum, mode, clip_acts, activation_stats, clip_n_stds, clip_half_range, scale_approx_mult_bits) if not isinstance(wrapped_module, (nn.Conv2d, nn.Conv3d, nn.Linear)): raise ValueError(self.__class__.__name__ + ' can wrap only Conv2D, Conv3D and Linear modules') self.num_bits_params = num_bits_params # Parameter quantification bits self.per_channel_wts = per_channel_wts # Whether the weight is quantized channel by channel # Get the quantitative range ( According to the quantification mode )sign: [-128,127] unsign: [0, 255] self.params_min_q_val, self.params_max_q_val = get_quantized_range( num_bits_params, signed=mode != LinearQuantMode.ASYMMETRIC_UNSIGNED) # Quantize weights - overwrite FP32 weights( Get current op The weight weights The quantization parameters of ) w_scale, w_zero_point = _get_quant_params_from_tensor(wrapped_module.weight, num_bits_params, self.mode, per_channel=per_channel_wts) # Add a pseudo attribute fake-attr, Can save but not participate in parameter update self.register_buffer('w_scale', w_scale) self.register_buffer('w_zero_point', w_zero_point) # Quantitative weight (weight.data) And replace (inplace=True), Pay attention to clamp( Another way is to send x、w all clamp To the specified range ) linear_quantize_clamp(wrapped_module.weight.data, self.w_scale, self.w_zero_point, self.params_min_q_val, self.params_max_q_val, inplace=True) self.has_bias = hasattr(wrapped_module, 'bias') and wrapped_module.bias is not None device = self.w_scale.device # At present module Is there statistical data and input if self.preset_act_stats: self.in_0_scale = self.in_0_scale.to(device) # Use only the first input Of scale self.register_buffer('accum_scale', self.in_0_scale * self.w_scale) if self.per_channel_wts: # TODO how? self.accum_scale = self.accum_scale.squeeze(dim=-1) else: self.accum_scale = 1 # Quantize bias self.has_bias = hasattr(wrapped_module, 'bias') and wrapped_module.bias is not None if self.has_bias: if self.preset_act_stats: # If accu_scale According to the statistical data , Then order bias_scale==accu_scale,bias_zp==0, The quantitative range also comes from accu # Notice the quantification here , It's based on doc Designed by the formula in ; Besides ,bias according to accum The quantitative range of clamp linear_quantize_clamp(wrapped_module.bias.data, self.accum_scale.squeeze(), 0, self.accum_min_q_val, self.accum_max_q_val, inplace=True) else: # Otherwise use bias Their own scale and zp And general quantification range b_scale, b_zero_point = _get_quant_params_from_tensor(wrapped_module.bias, num_bits_params, self.mode) self.register_buffer('b_scale', b_scale) self.register_buffer('b_zero_point', b_zero_point) # TODO Be careful inplace=False,dynamic requantize,why? base_b_q = linear_quantize_clamp(wrapped_module.bias.data, self.b_scale, self.b_zero_point, self.params_min_q_val, self.params_max_q_val) # Dynamic ranges - save in auxiliary buffer, requantize each time based on dynamic input scale factor self.register_buffer('base_b_q', base_b_q) # A flag indicating that the simulated quantized weights are pre-shifted. for faster performance. # In the first forward pass - `w_zero_point` is added into the weights, to allow faster inference, # and all subsequent calls are done with these shifted weights. # Upon calling `self.state_dict()` - we restore the actual quantized weights. # i.e. is_simulated_quant_weight_shifted = False self.register_buffer('is_simulated_quant_weight_shifted', torch.tensor(0, dtype=torch.uint8, device=device)) def state_dict(self, destination=None, prefix='', keep_vars=False): if self.is_simulated_quant_weight_shifted: # We want to return the weights to their integer representation: # according to doc,weight To add w_zp, utilize is_simulated_quant_weight_shifted Mark ; Restore to the real one when saving weight self.wrapped_module.weight.data -= self.w_zero_point self.is_simulated_quant_weight_shifted.sub_(1) # i.e. is_simulated_quant_weight_shifted = False return super(RangeLinearQuantParamLayerWrapper, self).state_dict(destination, prefix, keep_vars) def get_inputs_quantization_params(self, input): if not self.preset_act_stats: # If there is no statistical data to support , You need to dynamic Calculation self.in_0_scale, self.in_0_zero_point = _get_quant_params_from_tensor( input, self.num_bits_acts, self.mode, clip=self.clip_acts, num_stds=self.clip_n_stds, scale_approx_mult_bits=self.scale_approx_mult_bits) return [self.in_0_scale], [self.in_0_zero_point] def quantized_forward(self, input_q): # See class documentation for quantized calculation details. if not self.preset_act_stats: # There are no statistics # In base class self.accum_scale = 1, Reset here self.accum_scale = self.in_0_scale * self.w_scale # in_0_scale stay get_inputs_quantization_params It completes the definition if self.per_channel_wts: self.accum_scale = self.accum_scale.squeeze(dim=-1) if self.has_bias: # Re-quantize bias to match x * w scale: # b_q' = (in_scale * w_scale / b_scale) * (b_q + b_zero_point) bias_requant_scale = self.accum_scale.squeeze() / self.b_scale if self.scale_approx_mult_bits is not None: bias_requant_scale = approx_scale_as_mult_and_shift(bias_requant_scale, self.scale_approx_mult_bits) # Without statistics , Yes bias according to accum scale Conduct * again * quantitative ( according to doc The formula in , But there was no round Of ) # b_q' = round[(in_scale * w_scale / b_scale) * (base_b_q + b_zero_point)] - 0 self.wrapped_module.bias.data = linear_quantize_clamp(self.base_b_q + self.b_zero_point, bias_requant_scale, 0, self.accum_min_q_val, self.accum_max_q_val) # Note the main terms within the summation is: # (x_q + zp_x) * (w_q + zp_w) # In a performance-optimized solution, we would expand the parentheses and perform the computation similar # to what is described here: # https://github.com/google/gemmlowp/blob/master/doc/low-precision.md#efficient-handling-of-offsets # However, for now we're more concerned with simplicity rather than speed. So we'll just add the zero points # to the input and weights and pass those to the wrapped model. Functionally, since at this point we're # dealing solely with integer values, the results are the same either way. if self.mode != LinearQuantMode.SYMMETRIC and not self.is_simulated_quant_weight_shifted: # We "store" the w_zero_point inside our wrapped module's weights to # improve performance on inference. self.wrapped_module.weight.data += self.w_zero_point # Symmetry mode w_zp=0 self.is_simulated_quant_weight_shifted.add_(1) # i.e. is_simulated_quant_weight_shifted = True input_q += self.in_0_zero_point # perform doc Medium (x_q + zp_x) * (w_q + zp_w) + # round[ (in_scale * w_scale / b_scale) * (b_q + b_zero_point) - 0 ] # get accum, Note that it is only an intermediate quantized value , No practical significance accum = self.wrapped_module.forward(input_q) # accum The quantitative range of is 32bits clamp(accum.data, self.accum_min_q_val, self.accum_max_q_val, inplace=True) return accum def get_output_quantization_params(self, accumulator): if self.preset_act_stats: return self.output_scale, self.output_zero_point # TODO why? Without historical statistics ,scale_y and zp_y There is no way to get ? y_f = accumulator / self.accum_scale return _get_quant_params_from_tensor(y_f, self.num_bits_acts, self.mode, clip=self.clip_acts, num_stds=self.clip_n_stds, scale_approx_mult_bits=self.scale_approx_mult_bits) def get_accum_to_output_re_quantization_params(self, output_scale, output_zero_point): requant_scale = output_scale / self.accum_scale if self.scale_approx_mult_bits is not None: requant_scale = approx_scale_as_mult_and_shift(requant_scale, self.scale_approx_mult_bits) return requant_scale, output_zero_point - The whole idea is :
- stay doc in , Explained distiller How to convert the original calculation into float -> int -> float Formal , And let the original module perform int Part of the calculation , The core calculation is achieved by int The purpose of execution is ( That is to realize quantitative calculation )
- __init__ in , Calculate in advance weight、bias( If there is ) Quantized value of ; There will be some processing differences here according to whether there are statistical data ;
- quantized_forward function : Receive quantized input , Then let yuan module Perform quantitative calculations , The intermediate quantized value is returned ( No y_f Corresponding y_q)

get_accum_to_output_re_quantization_params function : according to doc explain , To get the final quantitative output y_q, Also need to quantized_forward Output value (accum) To transform ; Observe doc explain , This transformation can be regarded as a kind of quantization , Therefore, the function is based on doc Output Quantized twice scale and zp;
Summary :
Through the above module Replace ( encapsulation ), treat as inference when , although nn.Conv2d unchanged , But when calculating, it becomes int Type calculation ;
It is worth mentioning that ,distiller The toolkit does not implement integer gemm( Matrix multiplication /igemm), Therefore, it is necessary to introduce igemm package ;
- Nonparametric layer
- The nonparametric layer and the parametric layer are generally similar , Just because there are no parameters , So it's a little different
- Illustrate with examples : This is an addition operation (distiller Now it is encapsulated as module) Quantification
# add: Fix wrapper_type by RangeLinearQuantEltwiseAddWrapper factory_eltwiseadd = partial(replace_non_param_layer, RangeLinearQuantEltwiseAddWrapper) - replace_non_param_layer similar replace_param_layer, But one more parameter wrapper_type, Express wrapper type ; This parameter is set for the purpose of reusing functions , Because non participation module More ( Such as addition 、 Multiplication by element / Dot product 、 Batch multiplication, etc ), each module Need to use different wrapper; The definition is as follows :

- to glance at eltwiseadd Of wrapper, Implementation ideas and the above reference wrapper It's the same , The difference is quantized_forward Represents the quantitative implementation process
class RangeLinearQuantEltwiseAddWrapper(RangeLinearQuantWrapper): """ add-0107-zyc y_f = in0_f + in1_f in0_q = round(in0_f * scale_in0) - zp_in0 in1_q = round(in1_f * scale_in1) - zp_in1 y_q = round(y_f * scale_y) - zp_y => Omitted below round = scale_y * ( in0_f + in1_f ) - zp_y scale_y = ------------------- * [ scale_in1*(in0_q + zp_in0) + (in1_q + zp_in1)*scale_in0 ] - zp_y scale_in0*scale_in1 => It can be found that the above formula cannot be carried out int Calculation , So it needs further treatment : Yes in0_q and in1_q Re quantify ,scale Unified as this node output/accum Of scale in0_re_q = scale_accum * [( in0_q + zp_in0 ) / scale_in0] - 0 # Now the new scale by scale_accum,zp by 0 in1_re_q = scale_accum * [( in0_q + zp_in1 ) / scale_in1] - 0 => be y_q = round(y_f * scale_y) - zp_y => Omitted below round = scale_y * ( in0_f + in1_f ) - zp_y scale_y = ------------------------- * [scale_re_in1*(in0_re_q+zp_re_in0)+(in1_re_q+zp_re_in1)*scale_re_in0] - zp_y scale_re_in0*scale_re_in1 = 1 * [ (in0_re_q + zp_re_in0) + (in1_re_q + zp_re_in1) ] - zp_y = 1 * (in0_re_q + in1_re_q) - zp_y note: From the perspective of derivation , There is no problem with the above weighing method """ def __init__(self, wrapped_module, num_bits_acts, mode=LinearQuantMode.SYMMETRIC, clip_acts=ClipMode.NONE, activation_stats=None, clip_n_stds=None, clip_half_range=False, scale_approx_mult_bits=None): if not isinstance(wrapped_module, distiller.modules.EltwiseAdd): raise ValueError(self.__class__.__name__ + ' can only wrap distiller.modules.EltwiseAdd modules') if not activation_stats: raise NoStatsError(self.__class__.__name__ + ' must get activation stats, dynamic quantization not supported') super(RangeLinearQuantEltwiseAddWrapper, self).__init__(wrapped_module, num_bits_acts, mode=mode, clip_acts=clip_acts, activation_stats=activation_stats, clip_n_stds=clip_n_stds, clip_half_range=clip_half_range, scale_approx_mult_bits=scale_approx_mult_bits) if self.preset_act_stats: # For addition to make sense, all input scales must match. So we set a re-scale factor according # to the preset output scale requant_scales = [self.output_scale / in_scale for in_scale in self.inputs_scales()] if scale_approx_mult_bits is not None: requant_scales = [approx_scale_as_mult_and_shift(requant_scale, scale_approx_mult_bits) for requant_scale in requant_scales] for idx, requant_scale in enumerate(requant_scales): self.register_buffer('in_{0}_requant_scale'.format(idx), requant_scale) def inputs_requant_scales(self): if not self.preset_act_stats: raise RuntimeError('Input quantization parameter iterators only available when activation stats were given') for idx in range(self.num_inputs): name = 'in_{0}_requant_scale'.format(idx) yield getattr(self, name) def get_inputs_quantization_params(self, *inputs): return self.inputs_scales(), self.inputs_zero_points() def quantized_forward(self, *inputs_q): # Re-scale inputs to the accumulator range # Re quantify the quantized input ,scale Turn into accum Of (self.output_scale), So unified scale_in inputs_re_q = [linear_quantize_clamp(input_q + zp, requant_scale, 0, self.accum_min_q_val, self.accum_max_q_val, inplace=False) for input_q, requant_scale, zp in zip(inputs_q, self.inputs_requant_scales(), self.inputs_zero_points())] accum = self.wrapped_module(*inputs_re_q) clamp(accum.data, self.accum_min_q_val, self.accum_max_q_val, inplace=True) return accum def get_output_quantization_params(self, accumulator): return self.output_scale, self.output_zero_point def get_accum_to_output_re_quantization_params(self, output_scale, output_zero_point): return 1., self.output_zero_point
- Embedding layer
- The quantitative calculation of this layer is relatively simple ( In fact, it's OK not to quantify , Unless in order to reduce the size of the model ), The following is the definition :

- You can see , uncomplicated quantized_forward And second quantization ;
- The quantitative calculation of this layer is relatively simple ( In fact, it's OK not to quantify , Unless in order to reduce the size of the model ), The following is the definition :
- Summary : The above describes how the post training quantizer is implemented , The core part is Various types wrapper Original module Packaging replacement ;
- Add :scale( It's usually float) Integer calculation method of
- Go straight to the code ; The basic idea is floor(scale*2^N) / (2^N),N In fact, if you can be big, you can be big

- Go straight to the code ; The basic idea is floor(scale*2^N) / (2^N),N In fact, if you can be big, you can be big
- Parameter layer :
- BN Folding implementation
- see BN Fold
- Activate layer optimization
- To be added
summary
- This paper introduces distiller Quantizer base class Quantizer A subclass of :PostTrainLinearQuantizer;
- The core part is Various types wrapper Original module Packaging replacement ; And some optimization , Such as BN Fold 、 Activate layer optimization 、scale Integer calculation, etc ;
边栏推荐
- LeetCode:236. The nearest common ancestor of binary tree
- Advanced Computer Network Review(5)——COPE
- Tcp/ip protocol
- 有效提高软件产品质量,就找第三方软件测评机构
- 【嵌入式】使用JLINK RTT打印log
- JVM quick start
- LeetCode:39. Combined sum
- Current situation and trend of character animation
- Problems encountered in connecting the database of the project and their solutions
- LeetCode:498. Diagonal traversal
猜你喜欢
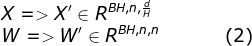
自定义卷积注意力算子的CUDA实现

Light of domestic games destroyed by cracking

数字人主播618手语带货,便捷2780万名听障人士
ant-design的走马灯(Carousel)组件在TS(typescript)环境中调用prev以及next方法

Using pkgbuild:: find in R language_ Rtools check whether rtools is available and use sys The which function checks whether make exists, installs it if not, and binds R and rtools with the writelines
Variable length parameter
BN折叠及其量化
CUDA implementation of self defined convolution attention operator
Digital people anchor 618 sign language with goods, convenient for 27.8 million people with hearing impairment
Navicat Premium 创建MySql 创建存储过程
随机推荐
有效提高软件产品质量,就找第三方软件测评机构
Cesium draw points, lines, and faces
如何正确截取字符串(例:应用报错信息截取入库操作)
LeetCode:221. Largest Square
[MySQL] limit implements paging
How to effectively conduct automated testing?
Implement window blocking on QWidget
Leetcode刷题题解2.1.1
LeetCode:162. Looking for peak
LeetCode:236. 二叉树的最近公共祖先
SimCLR:NLP中的对比学习
Notes 01
LeetCode:剑指 Offer 42. 连续子数组的最大和
使用latex导出IEEE文献格式
Leetcode: Sword finger offer 48 The longest substring without repeated characters
Shift Operators
Warning in install. packages : package ‘RGtk2’ is not available for this version of R
vb.net 随窗口改变,缩放控件大小以及保持相对位置
Using pkgbuild:: find in R language_ Rtools check whether rtools is available and use sys The which function checks whether make exists, installs it if not, and binds R and rtools with the writelines
Pytorch view tensor memory size