当前位置:网站首页>Mapreduce实例(八):Map端join
Mapreduce实例(八):Map端join
2022-07-06 09:01:00 【笑看风云路】
大家好,我是风云,欢迎大家关注我的博客 或者 微信公众号【笑看风云路】,在未来的日子里我们一起来学习大数据相关的技术,一起努力奋斗,遇见更好的自己!
使用场景和原理
Map端join是指数据达到map处理函数之前进行合并的,效率要远远高于Reduce端join,因为Reduce端join是把所有的数据都经过Shuffle,非常消耗资源。
- Map端join的使用场景:
- 一张表数据十分小、一张表数据很大
- 原理:
- Map端join是针对以上场景进行的优化:将小表中的数据全部加载到内存,按关键字建立索引。大表中的数据作为map的输入,对map()函数每一对<key,value>输入,就能够方便地和已加载到内存的小数据进行连接。把连接结果按key输出,经过shuffle阶段,到reduce端的就是已经按key分组并且连接好了的数据。
实现思路
- 首先在提交作业的时候将小表文件放到该作业的DistributedCache中,然后从DistributedCache中取出该小表进行join连接的<key,value>键值对,将其分割放到内存中(可以放到HashMap等容器中)
- 要重写MyMapper类下面的setup()方法,因为这个方法是先于map方法执行的,将较小表先读入到一个HashMap中。
- 重写map函数,一行行读入大表的内容,逐一与HashMap中的内容进行比较,若Key相同,则对数据进行格式化处理,然后直接输出。
- map函数输出的<key,value>键值对首先经过shuffle把key值相同的所有value放到一个迭代器中形成values,然后将<key,values>键值对传递给reduce函数,reduce函数输入的key直接复制给输出的key,输入的values通过增强版for循环遍历逐一输出,循环的次数决定了<key,value>输出的次数。
代码编写
Mapper代码
public static class MyMapper extends Mapper<Object, Text, Text, Text>{
private Map<String, String> dict = new HashMap<>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
String fileName = context.getLocalCacheFiles()[0].getName();
System.out.println(fileName);
BufferedReader reader = new BufferedReader(new FileReader(fileName));
String codeandname = null;
while (null != ( codeandname = reader.readLine() ) ) {
String str[]=codeandname.split("\t");
dict.put(str[0], str[2]+"\t"+str[3]);
}
reader.close();
}
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] kv = value.toString().split("\t");
if (dict.containsKey(kv[1])) {
context.write(new Text(kv[1]), new Text(dict.get(kv[1])+"\t"+kv[2]));
}
}
}
该部分分为setup方法与map方法。在setup方法中首先用getName()获取当前文件名为orders1的文件并赋值给fileName,然后用bufferedReader读取内存中缓存文件。在读文件时用readLine()方法读取每行记录,把该记录用split(“\t”)方法截取,与order_items文件中相同的字段str[0]作为key值放到map集合dict中,选取所要展现的字段作为value。map函数接收order_items文件数据,并用split(“\t”)截取数据存放到数组kv[]中(其中kv[1]与str[0]代表的字段相同),用if判断,如果内存中dict集合的key值包含kv[1],则用context的write()方法输出key2/value2值,其中kv[1]作为key2,其他dict.get(kv[1])+“\t”+kv[2]作为value2。
Reduce代码
public static class MyReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text text : values) {
context.write(key, text);
}
}
}
map函数输出的<key,value >键值对首先经过一个suffle把key值相同的所有value放到一个迭代器中形成values,然后将<key,values>键值对传递给reduce函数,reduce函数输入的key直接复制给输出的key,输入的values通过增强版for循环遍历逐一输出。
完整代码
package mapreduce;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MapJoin {
public static class MyMapper extends Mapper<Object, Text, Text, Text>{
private Map<String, String> dict = new HashMap<>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
String fileName = context.getLocalCacheFiles()[0].getName();
//System.out.println(fileName);
BufferedReader reader = new BufferedReader(new FileReader(fileName));
String codeandname = null;
while (null != ( codeandname = reader.readLine() ) ) {
String str[]=codeandname.split("\t");
dict.put(str[0], str[2]+"\t"+str[3]);
}
reader.close();
}
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] kv = value.toString().split("\t");
if (dict.containsKey(kv[1])) {
context.write(new Text(kv[1]), new Text(dict.get(kv[1])+"\t"+kv[2]));
}
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text text : values) {
context.write(key, text);
}
}
}
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException, URISyntaxException {
Job job = Job.getInstance();
job.setJobName("mapjoin");
job.setJarByClass(MapJoin.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in = new Path("hdfs://localhost:9000/mymapreduce5/in/order_items1");
Path out = new Path("hdfs://localhost:9000/mymapreduce5/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
URI uri = new URI("hdfs://localhost:9000/mymapreduce5/in/orders1");
job.addCacheFile(uri);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
-------------- end ----------------
微信公众号:扫描下方二维码或 搜索 笑看风云路 关注
边栏推荐
- Booking of tourism products in Gansu quadrupled: "green horse" became popular, and one room of B & B around Gansu museum was hard to find
- In depth analysis and encapsulation call of requests
- Simclr: comparative learning in NLP
- 美团二面:为什么 Redis 会有哨兵?
- How to intercept the string correctly (for example, intercepting the stock in operation by applying the error information)
- Servlet learning diary 8 - servlet life cycle and thread safety
- 【shell脚本】——归档文件脚本
- Global and Chinese market of electronic tubes 2022-2028: Research Report on technology, participants, trends, market size and share
- 一篇文章带你了解-selenium工作原理详解
- Post training quantification of bminf
猜你喜欢
基于WEB的网上购物系统的设计与实现(附:源码 论文 sql文件)
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
Kratos ares microservice framework (II)

Redis connection redis service command
Redis' performance indicators and monitoring methods
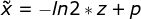
I-BERT
Servlet learning diary 7 -- servlet forwarding and redirection

一篇文章带你了解-selenium工作原理详解
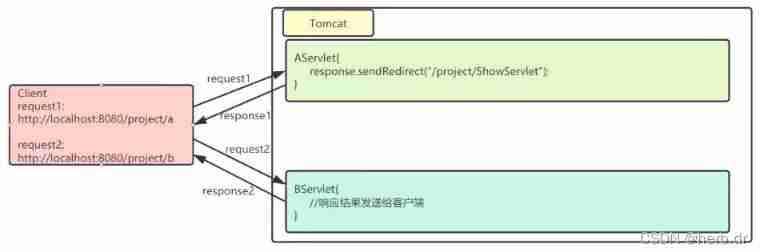
Sentinel mode of redis
Servlet learning diary 8 - servlet life cycle and thread safety
随机推荐
在QWidget上实现窗口阻塞
Selenium+pytest automated test framework practice (Part 2)
数据建模有哪些模型
Redis之核心配置
AcWing 2456. 记事本
IDS cache preheating, avalanche, penetration
An article takes you to understand the working principle of selenium in detail
Activiti7工作流的使用
Different data-driven code executes the same test scenario
[oc foundation framework] - < copy object copy >
Redis之主从复制
Using label template to solve the problem of malicious input by users
Connexion d'initialisation pour go redis
Advance Computer Network Review(1)——FatTree
基于B/S的影视创作论坛的设计与实现(附:源码 论文 sql文件 项目部署教程)
Redis之持久化实操(Linux版)
Servlet learning diary 8 - servlet life cycle and thread safety
LeetCode41——First Missing Positive——hashing in place & swap
Reids之删除策略
Intel distiller Toolkit - Quantitative implementation 1