当前位置:网站首页>Institute of automation, Chinese Academy of Sciences: a review of the latest visual language pre training
Institute of automation, Chinese Academy of Sciences: a review of the latest visual language pre training
2022-06-10 16:48:00 【PaperWeekly】


Paper title :
VLP: A Survey on Vision-Language Pre-training
Thesis link :
https://arxiv.org/abs/2202.09061

Abstract
In the last few years , The emergence of pre training model will lead to computer vision (CV) And natural language processing (NLP) And other single-mode fields have entered a new era . A lot of work has shown that they are beneficial to downstream single-mode tasks , And avoid training new models from scratch . So can such a pre training model be applied to multimodal tasks ? Researchers have explored this problem and made great progress .
This paper investigates visual - Language pre training (VLP) The latest progress and new frontier of , Include images - Text and video - Text pre training . In order to make readers better grasp VLP, We start with feature extraction 、 Model architecture 、 Pre training objectives 、 The recent progress of pre training data set and downstream task is reviewed in five aspects . then , We summarized the specific VLP Model . Last , We talked about VLP New areas of . As far as we know , This is a VLP First overview of the field . We hope that this review will serve VLP Implications for future research in the field .

Introduce
It has always been the unremitting goal of artificial intelligence researchers to make machines react in a way similar to human beings . In order for the machine to perceive and think , The researchers proposed a series of related tasks , For example, face recognition 、 Reading comprehension and man-machine dialogue , To train and evaluate the intelligence of the machine in specific aspects . say concretely , Domain experts manually build standard data sets , Then train and evaluate the relevant models on it .
However , Due to the limitation of related technology , It is often necessary to train on a large number of labeled data , To get better 、 A more capable model . The recent emergence is based on Transformer The pre training model of the structure alleviates this problem . They first pre train through self supervised learning , It usually uses auxiliary tasks ( Pre training objectives ) Automatically mining supervision signals from large-scale unlabeled data to train models , So as to learn the general representation .
then , They can achieve amazing results by fine tuning with only a small amount of manually tagged data on downstream tasks . since BERT In natural language processing (NLP) Since the emergence of , Various pre training models have sprung up in the single-mode field , For example, computer vision (CV) In the field of Vision Transformer(ViT) And voice Wave2Vec. A lot of work has shown that they are beneficial to downstream single-mode tasks , And avoid training new models from scratch .
Similar to the single-mode domain , There is also a problem of less high-quality annotation data in the multimodal field . A natural question is whether the above pre training method can be applied to multimodal tasks ? Researchers have explored this problem and made great progress . In this paper , We focus on the mainstream vision - Language pre training (VLP), Include images - Text and video - Text pre training .
VLP Mainly through pre training based on large-scale data to learn the semantic correspondence between different modes . for example , In the image - Text pre training , We expect the model to include in the text “ Dog ” And in the image “ Dog ” Related to . In the video - Text pre training , We expect the model to include objects in the text / Actions are mapped to objects in the video / action . In order to achieve this goal , Need clever design VLP Goals and model architecture , To allow the model to mine the association between different modes .
In order to make readers better understand VLP, We start with 5 A comprehensive review of its latest progress in three important aspects :
1) feature extraction : This section includes VLP Image in model 、 Preprocessing and representation of video and text ( See also 3 section );
2) Model architecture : We introduce... From two different perspectives VLP The architecture of the model : From the perspective of multimodal fusion, it can be divided into single flow and double flow , From the perspective of overall architecture design, it is divided into Encoder-only And Encoder-decoder ( See also 4 section );
3) Pre training objectives : The goal of pre training is VLP At the heart of , It is mainly used to guide the model to learn the information related to visual language . We summed up our special training goals , Divided into complement 、 matching 、 Timing and special types ( See also 5 section );
4) Pre training dataset : Data for VLP crucial . We briefly introduced VLP The mainstream corpus and its specific size ( See also 6 section );
5) Downstream tasks : Multiple tasks require cooperative knowledge of vision and language . We divide them into five categories : classification 、 Return to 、 retrieval 、 Build and other tasks . We also discussed the basic details and objectives of these tasks ( See also 7 section ).
Then we summarize the specific state-of-the-art (SOTA)VLP Model ( See also 8 section ). Last , We summarize the paper and comment on VLP The new frontier of ( See also 9 section ).
As far as we know , This is a VLP The first overview of the field . We hope that our review will help researchers better understand this field , And inspire them to design better models .

feature extraction
This section describes VLP How the model preprocesses and represents images 、 Video and text to get corresponding features .
3.1 Feature preprocessing
Image feature preprocessing mainly includes three methods : Regional features based on target detection , be based on CNN Grid features and based on ViT Of patch features .
Video feature preprocessing : First, the video is divided into frames , Get the image sequence , Then, the image is processed according to the above image feature preprocessing method .
Text feature preprocessing : Mainly follow BERT Pretreatment method of , Segment the input sentence into sub word sequences , Then close and add [CLS] and [SEP], The last input is expressed as the word embedding + Location embedding + segment embedding.
3.2 Characteristic means
In order to make full use of the single-mode pre training model ,VLP The model can input visual or text features into Transformer Encoder . say concretely ,VLP The model utilizes criteria with random initialization Transformer Encoders to generate visual or textual representations . Besides ,VLP The model can take advantage of the pre trained vision Transformer Yes, based on ViT Of patch Feature coding , for example ViT and DeiT.VLP The model can also use pre trained text Transformer Encode text features , for example BERT. For the sake of simplicity , We put these Transformer Name it Xformer.
See the paper for more details Section 2.

Model structure
In this section , We introduce... From two different perspectives VLP The architecture of the model :(1) From the perspective of multimodal fusion, it can be divided into single flow and double flow , as well as (2) From the perspective of overall architecture design, it can be divided into only-encoder And encoder-decoder.

4.1 Single-stream versus Dual-strea
Single stream architecture refers to the connection of text and visual features , Then enter a single Transformer modular , Such as Firgue 1(a) Shown .
Dual flow architecture means that text and visual features are not connected , It's sent independently to two different Transformer block , Such as Firgue 1(b) Shown .
4.2 Encoder-only versus Encoder-decoder
many VLP The model adopts encoder only architecture , The output mode is generated directly across the feed layer . by comparison , other VLP The model advocates the use of converter encoders - Decoder architecture , Where the cross modal representation is first fed into the decoder , Then feed into the output layer .
See the paper for more details Section 3.

Pre training objectives
This section describes how we pre train by using different pre training objectives VLP Model , This is important for learning vision - A universal representation of language is essential . We summarize the pre training objectives into four categories : completion 、 matching 、 Timing and specific types .
The completion type is to understand the mode by reconstructing the masked element with the remainder of the unmasked part , Include Masked Language Modeling,Prefix Language Modeling,Masked Vision Modeling etc. ;
Matching type is to unify vision and language into a shared hidden space , To generate a general visual - Language means , Include Vision-Language Matching,Vision-Language Contrastive Learning,Word-Region Alignment etc. ;
Timing types learn good representation by reordering the input sequence of interrupts , Mainly for video related pre training , Such as Frame Order Modeling etc. ;
Special types consist of other pre training objectives , Such as visual Q & A and visual description .
See the paper for more details Section 4.

Pre training dataset
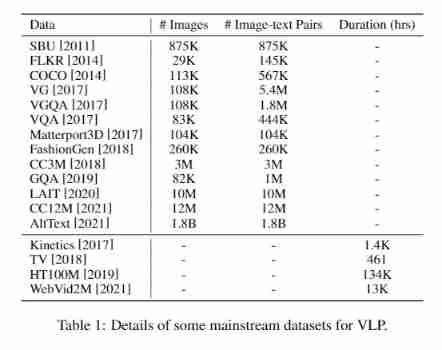
majority VLP Datasets are built by combining common datasets across different multimodal tasks . However , Some of the previous work , for example VideoBERT、ImageBERT、ALIGN and CLIP, Deal with large amounts of data collected from the Internet and train with their own data sets . ad locum , Some mainstream corpora and their scale information are shown in table 1 Shown .

Downstream tasks
Various tasks require collaborative knowledge of vision and language . In this section , We will introduce the basic details and objectives of such tasks , And divide them into five categories : classification 、 Return to 、 retrieval 、 Build and other tasks , Among them, classification 、 Regression and retrieval tasks are also called comprehension tasks .
Classification tasks mainly include :Visual Question Answering(VQA)、Visual Question Answering(VQA)、Natural Language for Visual Reasoning(NLVR).、Visual Commonsense Reasoning(VCR) etc. ;
Regression tasks include Multi-modal Sentiment Analysis(MSA);
The retrieval task mainly refers to some visual tasks - Language retrieval task ;
Generation tasks include :Visual Dialogue(VD)、Visual Captioning(VC) etc. ;
Other tasks include :Multi-modal Machine Translation(MMT)、Vision-Language Navigation(VLN). etc. .
See the paper for more details Section 6.

SOTA VLP models
Based on the above VLP Model 5 Big picture , We are concerned about the VLP The models are summarized :

See the paper for more details Section 7.

Summary and new frontiers
In this paper , We offer the first VLP review . We extract from features 、 Model architecture 、 Pre training objectives 、 The latest progress of pre training data set and downstream task is reviewed , And a detailed summary of the specific SOTA VLP Model . We hope that our review will help researchers better understand VLP, And stimulate new work to promote the development of this field . future , On the basis of existing work ,VLP It can be further developed from the following aspects :
1)Incorporating Acoustic Information. Most previous work on multimodal pre training has emphasized the joint modeling of language and vision , But it ignores the information hidden in the audio . Although the semantic information in audio may overlap with language , But audio can provide additional emotional information 、 Acoustic boundary information, etc . Besides , Pre training with audio enables the model to handle downstream tasks with acoustic input .
up to now , Cross text 、 The joint modeling and representation of vision and audio is still an open issue to be further studied . Some frontier work has clarified the future of this research field . And previous VLP Different models ,VATT Take the original audio as input , And estimate through noise comparison (NCE) Learn multimodal representation .
And VATT Different ,OPT Combine various multi-level masking strategies to learn cross text 、 Cross modal representation of images and audio , And it can also generate text and images . Some other work , for example AudioCLIP and MERLOT Reserve, It also shows their unique method of learning cross modal representation on three modes ;
2)Knowledgeable Learning and Cognitive. Although the existing VLP The model has achieved significant performance , But their essence is to fit large-scale multimodal data sets . send VLP The model is more knowledgeable for the future VLP Very important . For input visual and text , Rich knowledge of relevant external common sense world and illustrative scenarios , Can be used to enhance input , Accelerate model training and reasoning . Solving this problem requires a unified cognitive model architecture 、 Pre training objectives of knowledge guidance and support for interaction with new knowledge ;
3)Prompt Tuning. at present , Fine tuning will VLP The main method of transferring knowledge to downstream tasks . However , With the increase of model scale , Each downstream task has its fine tuning parameters , Resulting in inefficient parameters . Besides , Diversified downstream tasks also make the design of pre training and fine-tuning stages cumbersome , Cause them to exist gap.
lately ,Prompt Tuning stay NLP More and more attention has been paid to . Discrete or continuous by design Prompt And will MLM For specific downstream tasks , These models can a. Reduce the computational cost of fine tuning a large number of parameters ;b. Bridge the gap between pre training and fine tuning .Prompt Tuning Yes, excitation PLM A promising approach to the distribution of language and world knowledge in . The next step is to improve and migrate to multimodal scenes , Break the traditional paradigm , solve VLP The pain point of .
Thank you very much
thank TCCI Tianqiao Academy of brain sciences for PaperWeekly Support for .TCCI Focus on the brain to find out 、 Brain function and brain health .
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- Duyuan outdoor sprint to Shenzhen Stock Exchange: the annual revenue is 350million, and the color of Lin Xizhen family is obvious
- Fiddler模拟低速网络环境
- PV operation daily question - Restaurant Service
- Fortex Fangda releases the electronic trading ecosystem to share and win-win with customers
- Learn actionchains through jianshu.com and Chapter 3 of selenium webdriver
- Zhangxiaobai teaches you how to use Ogg to synchronize Oracle 19C data with MySQL 5.7 (2)
- STM32 printf garbled
- 提高效率的 5 个 GoLand 快捷键,你都知道吗?
- Is it safe to open an account in qiniu? How to open an account online when buying stocks
- Quickly understand the commonly used symmetric encryption algorithm, and no longer have to worry about the interviewer's thorough inquiry
猜你喜欢

Nerf: the popularity of using deep learning to complete 3D rendering tasks
![[web security self-study] section 1 building of basic Web Environment](/img/f8/f2d13c2879cdbc03ad261c6569bc1d.jpg)
[web security self-study] section 1 building of basic Web Environment

数字图像处理:灰度化

Software College of Shandong University Project Training - Innovation Training - network security range experimental platform (XVII)

China coal machinery industry development research and investment prospect analysis report 2022-2028 Edition
![ASP. Net core 6 framework unveiling example demonstration [12]: advanced usage of diagnostic trace](/img/29/72c04d86e48f9fa34e5e17c44b6bd9.jpg)
ASP. Net core 6 framework unveiling example demonstration [12]: advanced usage of diagnostic trace
![[quick code] define the new speed of intelligent transportation with low code](/img/cd/da8cf959200dba8eeab6c8eccc5635.jpg)
[quick code] define the new speed of intelligent transportation with low code

What open source tools are actually used in the black cool monitoring interface?

Fiddler过滤会话

Shit, jialichuang's price is reduced again
随机推荐
再联合 冲量在线与飞腾完成合作伙伴认证,携手打造信创隐私计算生态圈
靠,嘉立创打板又降价
Zhangxiaobai teaches you how to use Ogg to synchronize Oracle 19C data with MySQL 5.7 (3)
Learn actionchains through jianshu.com and Chapter 3 of selenium webdriver
Bluetooth - Bluetooth SIG
leetcode:730. Statistics of different palindrome subsequences [traversed by point and surface interval DP + 3D DP + diagonal]
STOP在屏幕程序的应用_SAP刘梦_
What are the pitfalls of redis's current network: using a cache and paying for disk failures?
Postman switching topics
Thinking and precipitation after docking with hundreds of third-party APIs
Research Report on the development scale of Chinese sanatorium industry and the 14th five year plan (2022-2028)
Jerry's ble transmission rate [chapter]
从零开始,如何拥有自己的博客网站【华为云至简致远】
oss存储引出的相关内容
Software College of Shandong University Project Training - Innovation Training - network security range experimental platform (16)
Mm main tables and main fields_ SAP LIUMENG_
Detailed explanation of RGB color space, hue, saturation, brightness and HSV color space
Palm detection and finger counting based on OpenCV
Tactile intelligent sharing-a133 application in laryngoscope
PV operation daily question - black and white chess question (variant)