当前位置:网站首页>A deep long article on the simplification and acceleration of join operation
A deep long article on the simplification and acceleration of join operation
2022-07-05 12:51:00 【Shizhenzhen's grocery store】
author : Shi Zhenzhen , CSDN Blog star Top5、Kafka Contributor 、nacos Contributor、 Hua Wei Yun MVP , Tencent cloud TVP, sound of dripping water Kafka technician 、LogiKM PMC( Change of name KnowStream).
List of articles
- One . SQL Medium JOIN
- Two . equivalence JOIN Analysis of
- 3、 ... and . JOIN Syntax simplification of
- Four . Dimension alignment Syntax
- 5、 ... and . Solve associated queries
- 6、 ... and 、 Foreign key preassociation
- 7、 ... and 、 Further foreign key associations
- 8、 ... and 、 Orderly merge
- Conclusion
- SPL Information
Join operation (JOIN) Has always been a SQL A long-standing problem in . When there are a little more associated tables , Code writing becomes very error prone . And because JOIN The complexity of the statement , It always leads to association queries BI Software weakness , Hardly any BI The software enables business users to smoothly complete multi table Association queries . The same goes for performance optimization , When there are many associated tables or a large amount of data ,JOIN It is also difficult to improve the performance of .
This article will JOIN Operations for further discussion , The methods of syntax simplification and performance optimization are proposed .
One . SQL Medium JOIN
Let's see first SQL How to understand JOIN Operational .
SQL Yes JOIN The definition of is very simple , Just two sets ( surface ) Do the Cartesian product and then filter according to certain conditions , The grammar written is A JOIN B ON …. Theoretically speaking , The result set of Cartesian product should be a two tuple composed of two set members , But due to the SQL A set in is a table , Its members always have records of fields , Nor does it support generic data types to describe binary members of records , Therefore, the result set is simply processed into a set of new records formed by merging the fields of two table records . This is also JOIN The original meaning of the word in English ( That is, connect the fields of two records ), There is no multiplication ( The cartesian product ) It means . however , Understanding Cartesian product members as two tuples or merging field records , It does not affect our subsequent discussion .
JOIN There is no agreement on the form of filter conditions in the definition of , Theoretically , As long as the result set is a subset of the Cartesian product of two source sets , It's all reasonable JOIN operation . For example, suppose a set A={1,2},B={1,2,3},A JOIN B ON A<B The result is that {(1,2),(1,3),(2,3)};A JOIN B ON A=B The result is {(1,1),(2,2)}. We call the filter condition as an equation equivalence JOIN, Instead of equivalent connection, it is called non-equivalence JOIN. In these two examples , The former is non equivalent JOIN, The latter is equivalent JOIN.
For equivalence between data tables JOIN, A condition may consist of more than one AND The equation of the relationship constitutes , Grammatical form A JOIN B ON A.ai=B.bi AND …, among ai and bi Namely A and B Field of . Experienced programmers know that , In reality, the vast majority JOIN It's all equivalent JOIN, non-equivalence JOIN Much less common , And in most cases it can be converted to equivalent JOIN To deal with it , So here we focus on equivalence JOIN, In the following discussion, tables and records are mainly used instead of sets and members .
According to the processing rules for null values , Strict equivalence JOIN Also known as INNER JOIN, You can also derive LEFT JOIN and FULL JOIN, There are three situations (RIGHT JOIN It can be understood as LEFT JOIN The reverse association of , No longer a separate type ). talk about JOIN Generally, it is based on the associated records in the two tables ( That is, the two tuples that meet the filter conditions ) The quantity of is divided into one-on-one 、 One to many 、 For one more as well as Many to many In these cases , These conventional terms are used in SQL And database materials , I won't go into that here .
Let's see JOIN The implementation of the .
The easiest way to think of is to do hard traversal by definition , Do not distinguish equivalence JOIN And non equivalent JOIN. Set table A Yes n Bar record ,B Yes m Bar record , To calculate A JOIN B ON A.a=B.b when , The complexity of hard traversal would be nm, That is to do nm Calculation of secondary filter conditions .
Obviously, this algorithm will be slow . however , Sometimes, this slow method is used in report tools that support multiple data sources , Because of the association of data sets in the report ( That is to say JOIN Filter conditions in ) Will break up the expressions defined in the cells , It can no longer be seen that it is between multiple data sets JOIN operation , So we can only use the traversal method to calculate these correlation expressions .
Mature databases are certainly not so stupid , For equivalence JOIN, Databases generally use HASH JOIN Algorithm . That is, the records of the associated table are divided into Association key ( The corresponding equivalent fields in the filter conditions , namely A.a and B.b) Of HASH Values are divided into groups , Will be the same HASH The records of values are grouped . Such as HASH The value range is 1…k, Will A and B The tables are divided into k A subset of A1,…,Ak and B1,…,Bk.Ai Association key recorded in a Of HASH The value is i,Bi Association key recorded in b Of HASH So is the value i, then , As long as they are in Ai and Bi It is OK to make traversal connection between . because HASH The field values must be different at different times ,i!=j when ,Ai Impossible and Bj Is associated with records in . If Ai The number of records is ni,Bi The number of records is mi, Then the calculation times of filter conditions are SUM(ni*mi), In the most average case ,ni=n/k,mi=m/k, The total complexity is only that of the original hard traversal method 1/k, It can effectively improve the operation performance !
therefore , If you want to speed up the multi data source associated report , You also need to do a good job of correlation in the data preparation stage , Otherwise, the performance will drop sharply when the data volume is a little large .
however ,HASH Functions do not always guarantee average splitting , A certain group of particularly large situations may occur during bad luck , The performance improvement effect will be much worse . And you can't use too complicated HASH function , Otherwise, calculate HASH Time has changed again .
When the amount of data is large enough to exceed the memory , The database will use HASH The method of stacking , Count as HASH JOIN Generalization of the algorithm . Traverse A Table and B surface , Press the associated key to record HASH Value is split into several subsets and cached in external memory , be called Stacking . Then do memory between the corresponding heaps JOIN operation . Same thing ,HASH When the value is different, the key value must be different , The association must occur between the corresponding heaps . In this way, the JOIN Converted into several small data JOIN 了 .
But similarly ,HASH The function has a luck problem , It is possible that a certain heap is too large to be loaded into memory , At this time, it may be necessary to conduct a second HASH Stacking , That is, change one HASH Function to do this again for this group of too large heap partitions HASH Heap splitting algorithm . therefore , External storage JOIN The operation may be cached many times , Its operation performance is uncontrollable .
Under the distributed system JOIN It's the same thing , According to the associated key HASH Value to distribute the records to each node machine , be called Shuffle action , And then do the single machine JOIN. When there are many nodes , The delay caused by the network traffic will offset the benefits of multi machine task allocation , So the distributed database system usually has a limit of nodes , After reaching the limit , More nodes do not get better performance .
Two . equivalence JOIN Analysis of
Let's examine the following three equivalents JOIN:
1. Foreign key link
surface A A field and table of B The primary key field of ( The so-called Field Association , As mentioned in the previous section, in equivalence JOIN Corresponding fields in the filter conditions of ).A The table is called Fact table ,B The table is called Dimension table .A In the table and B The fields associated with the table primary key are called A Point to B Of Foreign keys ,B Also known as A Foreign key list of .
The primary key here refers to the logical primary key , That is, the value in the table is unique 、 A field that can be used to uniquely identify a record ( Group ), You may not have established a primary key on the database table .
Foreign key tables are many to one relationships , And only JOIN and LEFT JOIN, and FULL JOIN Very rare .
A typical example : Commodity transaction table and commodity information table .
obviously , Foreign key associations are asymmetric . The positions of fact table and dimension table cannot be interchanged .
2. Isometric table
surface A Primary keys and tables of B Primary key Association of ,A and B Call each other Isometric table . The same dimension table is a one-to-one relationship ,JOIN、LEFT JOIN and FULL JOIN There will be , But in most data structure designs ,FULL JOIN It is also relatively rare .
A typical example : Employee table and manager table .
The same dimension tables are symmetric , The two tables have the same status . The same dimension table also constitutes an equivalence relation ,A and B Is the same dimension table ,B and C Is the same dimension table , be A and C It is also the same dimension table .
3. Master sub table
surface A Primary keys and tables of B Partial primary key Association of ,A be called Main table ,B be called Sub table . The primary sub table is a one to many relationship , Only JOIN and LEFT JOIN, There will be no FULL JOIN.
A typical example : Orders and order details .
The primary and child tables are also asymmetric , There is a clear direction .
stay SQL There is no distinction between foreign key tables and primary sub tables in the concept system of , Many to one and one to many SQL It seems that the relationship direction is different , It's one thing in essence . exactly , An order can also be understood as a foreign key table of order details . however , We have to distinguish them here , In the future, different approaches will be used to simplify syntax and optimize performance .
We said , These three JOIN The vast majority of equivalents have been covered JOIN The situation of , It can even be said that almost all of them have business significance JOIN All belong to these three categories , Equate JOIN Limited to these three cases , It hardly reduces its scope of adaptation .
Examine these three carefully JOIN, We found that all associations involve primary keys , There is no many to many situation , Is it possible not to consider this situation ?
Yes ! Many to many equivalence JOIN Little business sense .
If two tables JOIN The associated field of does not involve any primary key , Then a many to many situation will occur , In this case, there will almost certainly be a larger table to associate the two tables as dimension tables . For example, the student chart and the chart of subjects are in JOIN when , There will be a grade sheet that takes the student chart and the subject chart as the dimension table , There are only student charts and subject charts JOIN No business sense .
When writing SQL Statement found many to many , There is a high probability that this statement is misspelled ! Or there is a problem with the data ! This rule is used to exclude JOIN Mistakes are very effective .
however , We've been saying “ almost ”, There is no definite statement , in other words , Many to many also makes business sense in very rare cases . For example , use SQL Many to many equivalence occurs when matrix multiplication is implemented JOIN, The specific writing method can be supplemented by the reader .
The Cartesian product then filters this JOIN Definition , It's very simple , And the simple connotation will get greater extension , You can equate many to many JOIN Even non equivalent JOIN And so on . however , Too simple connotation can not fully reflect the most common equivalence JOIN Operational characteristics of . This leads to the inability to take advantage of these features when writing code and implementing operations , When the operation is complex ( It involves many associated tables and nesting ), It is very difficult to write or optimize . And after making full use of these features , We can create simpler forms of writing and achieve more efficient computing performance , The following contents will be explained step by step .
Instead of defining operations in a more general form in order to include rare cases , It is more reasonable to define these cases as another kind of operation .
3、 ... and . JOIN Syntax simplification of
Let's first look at how to use the feature that associations all involve primary keys to simplify JOIN Code writing for , Discuss these three situations separately .
1. Foreign key attributions
Let's take an example , There are two tables as follows :
employee The employee table
id Employee number
name full name
nationality nationality
department Department
department Departmental table
id Department number
name Department name
manager division manager
employee Table and department The primary keys of tables are all of them id Field ,employee Tabular department The field points to department Table foreign key ,department Tabular manager The field points to employee Table foreign key ( Because the manager is also an employee ). This is a very common table structure design .
Now we want to ask : Which American employees have a Chinese manager ?
use SQL It's a three table JOIN The sentence of :
SELECT A.*
FROM employee A
JOIN department B ON A.department=B.id
JOIN employee C ON B.manager=C.id
WHERE A.nationality='USA' AND C.nationality='CHN'
First of all FROM employee Used to obtain employee information , And then this employee Table and department do JOIN Get the employee's department information , And then this department The watch has to be combined with employee surface JOIN To get manager information , such employee Table requires two participation JOIN, stay SQL It should be distinguished by an alias in the statement , The whole sentence is very complicated .
If we directly understand the foreign key field as its associated dimension table record , It can be written in a different way :
SELECT * FROM employee
WHERE nationality='USA' AND department.manager.nationality='CHN'
Of course , This is not standard SQL Statement .
The bold part in the second sentence indicates the current employee's “ The nationality of the manager of the Department ”. After we understand the foreign key field as the record of the dimension table , The fields of the dimension table are understood as the attributes of the foreign key ,department.manager That is “ The manager of the Department ”, And this field is in department Is still a foreign key , The corresponding dimension table record field can continue to be understood as its attribute , There will be department.manager.nationality, namely “ The nationality of the manager of the Department ”.
This kind of object-oriented understanding is called Foreign key attributions , Obviously, it is much more natural and intuitive than Cartesian product filtering . Foreign key table JOIN It does not involve the multiplication of two tables , The foreign key field is only used to find the corresponding record in the dimension key table , It will not involve Cartesian product, which is a multiplication operation .
We agreed earlier , When a foreign key is associated with a dimension table, the associated key must be a primary key , such , The dimension table record associated with the foreign key field of each record in the fact table is unique , in other words employee Of each record in the table department The field is uniquely associated with one department The records in the table , and department Of each record in the table manager The field is also uniquely associated with one employee The records in the table . This ensures that for employee Every record in the table ,department.manager.nationality All have unique values , Can be clearly defined .
however ,SQL Yes JOIN There is no primary key convention in the definition of , If based on SQL The rules of , You cannot assume that the dimension table records associated with foreign keys in the fact table are unique , It is possible to associate with multiple records , about employee In terms of the records of the table ,department.manager.nationality There is no clear definition , You can't use it .
in fact , This object-oriented approach is used in high-level languages ( Such as C,Java) Very common in , In this kind of language , Data is stored as objects .employee In the table department Field value is simply an object , Not the number . In fact, the primary key values of many tables have no business significance , Just to distinguish records , The foreign key field is only used to find the corresponding records in the dimension table , If the foreign key field is directly an object , There is no need to identify by number . however ,SQL This storage mechanism is not supported , And with the help of numbers .
We said that foreign key associations are asymmetric , That is, the fact table and dimension table are not equal , You can only find dimension table fields based on the fact table , There will be no reverse .
2. Isometric table assimilation
The case of the same dimension table is relatively simple , Let's start with an example , There are two tables :
employee The employee table
id Employee number
name full name
salary Wages
...
manager Manager table
id Employee number
allowance Job allowance
....
The primary keys of both tables are id, Managers are also employees , The two tables share the same employee number , Managers have more attributes than ordinary employees , Use another manager table to save .
Now we have to count all employees ( Including the manager ) The total income of ( Plus allowances ).
use SQL It will still be used in writing JOIN:
SELECT employee.id, employee.name, employy.salary+manager.allowance
FROM employee
LEFT JOIN manager ON employee.id=manager.id
And for two one-to-one tables , We can simply think of them as a table :
SELECT id,name,salary+allowance
FROM employee
Similarly , According to our agreement , Isometric table JOIN Both tables are associated by primary key , The corresponding record is unique ,salary+allowance Yes employee Each record in the table is uniquely calculable , There will be no ambiguity . This simplification is called Isometric table assimilation .
The relationship between the same dimension tables is equivalent , From any table, you can reference the fields of other tables with the same dimension .
3. Sub table aggregation
Orders and order details are typical primary sub tables :
Orders The order sheet
id The order no.
customer Customer
date date
...
OrderDetail The order details
id The order no.
no Serial number
product Order product
price Price
...
Orders The primary key of the table is id,OrderDetail The primary key in the table is (id,no), The primary key of the former is part of the latter .
Now we want to calculate the total amount of each order .
use SQL It would be like this :
SELECT Orders.id, Orders.customer, SUM(OrderDetail.price)
FROM Orders
JOIN OrderDetail ON Orders.id=OrderDetail.id
GROUP BY Orders.id, Orders.customer
To complete this operation , Not only JOIN, It needs to be done once more GROUP BY, Otherwise, too many records will be selected .
If we regard the records related to the main table in the sub table as a field of the main table , Then this problem can no longer be used JOIN as well as GROUP BY:
SELECT id, customer, OrderDetail.SUM(price)
FROM Orders
Different from normal fields ,OrderDetail Be regarded as Orders Table fields , Its value will be a set , Because the two tables are one to many . So we need to use the aggregation operation here to calculate the set value into a single value . This simplification is called Sub table aggregation .
Look at the primary sub table Association in this way , Not only understanding writing is easier , And it's not easy to make mistakes .
If Orders Table also has a sub table for recording payment collection :
OrderPayment Order collection form
id The order no.
date Date of collection
amount The amount of money received
....
We now want to know that those orders are still in arrears , That is, orders whose cumulative collection amount is less than the total order amount .
Simply put these three tables JOIN It's wrong to get up ,OrderDetail and OrderPayment Many to many relationships will occur , This is wrong ( Recall the previous statement of "many to many probability errors" ). These two sub tables should be made separately GROUP, Together with Orders surface JOIN Get up to get the right result , Will be written in the form of subqueries :
SELECT Orders.id, Orders.customer,A.x,B.y
FROM Orders
LEFT JOIN ( SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN ( SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x>B.y
If we continue to treat the sub table as a set field of the main table , That's easy :
SELECT id,customer,OrderDetail.SUM(price) x,OrderPayment.SUM(amount) y
FROM Orders WHERE x>y
This way of writing is not prone to many to many errors .
The relationship between master and child tables is not equal , But references in both directions make sense , The above describes the reference of sub tables from the main table , Referencing a primary table from a child table is similar to a foreign key table .
We change our view on JOIN An operational view , Abandon the idea of Cartesian product , Regard the multi table association operation as a slightly more complex single table operation . such , Equivalent to the most common equivalent JOIN The association of operations eliminates , Even in grammar JOIN keyword , Writing and understanding are much simpler .
Four . Dimension alignment Syntax
Let's review the previous example of the Gemini table SQL:
SELECT Orders.id, Orders.customer, A.x, B.y
FROM Orders
LEFT JOIN (SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN (SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x > B.y
So here comes the question , This is obviously a business sense JOIN, Which kind is it ?
This JOIN Involving tables Orders And subquery A And B, A close look will reveal , Subquery with GROUP BY id Clause of , obviously , The result set will be in the form of id Primary key . such ,JOIN Three tables involved ( The subquery is also considered a temporary table ) The primary key of is the same , They are one-to-one isometric tables , Still within the scope of the foregoing .
however , This isometric table JOIN But it can't be simplified with the above-mentioned writing method , Subquery A,B Can not omit not to write .
The reason why writing can be simplified is : We assume that we know the relationship between these tables in the data structure in advance . In technical terms , Know the metadata of the database (metadata). For the temporarily generated sub query , Obviously, it is impossible to define it in metadata in advance , In this case, it must be clearly specified that JOIN Table of ( Subquery ).
however , although JOIN Table of ( Subquery ) Don't omit , But associated fields are always primary keys . The primary key of a subquery always consists of GROUP BY produce , and GROUP BY The field of must be selected for the outer layer JOIN; And the sub tables involved in these sub queries are independent of each other , There will be no correlation between them , We can GROUP Put actions and aggregations directly into the main sentence , Thus eliminating a layer of subqueries :
SELECT Orders.id, Orders.customer, OrderDetail.SUM(price) x, OrderParyment.SUM(amount) y
FROM Orders
LEFT JOIN OrderDetail GROUP BY id
LEFT JOIN OrderPayment GROUP BY id
WHERE A.x > B.y
there JOIN and SQL Defined JOIN The operation has been very different , There is no Cartesian product at all . and , Also different from SQL Of JOIN The operation will be defined between any two tables , there JOIN,OrderDetail and OrderPayment as well as Orders All are linked to a common primary key id alignment , That is, all tables are aligned to a set of benchmark dimensions . Because of the dimension of each table ( Primary key ) Different , There may be... When aligning GROUP BY, When the table field is referenced, the aggregation operation will occur accordingly .OrderDetail and OrderPayment even to the extent that Orders Are not directly related to each other , Of course, you don't have to care about the relationship between them when writing operations , Don't even care if another table exists . and SQL The Cartesian product JOIN You always need to find one or more tables to define associations , Once you reduce or modify a table, you should also consider the associated table , Make it more difficult to understand .
We call this JOIN be called Dimension alignment , It doesn't go beyond the three we mentioned above JOIN Range , But there are differences in the grammatical description , there JOIN Don't like SQL Middle is a verb , But more like a conjunction . and , And the first three basic JOIN Does not or rarely occur FULL JOIN The situation is different , In the scenario of dimension alignment FULL JOIN It's not very rare .
Although we abstract the dimension alignment from the example of the primary sub table , But this JOIN There is no demand for JOIN The table of is the primary sub table ( As a matter of fact, we can see from the previous grammar , There is no need to write so much trouble for the operation of primary and secondary tables ), Any number of tables can be related in this way , Moreover, the associated field does not need to be a primary key or part of a primary key .
There is a contract form , Collection form and invoice form :
Contract Contract form
id Contract No
date Date of signing
customer Customer
price The contract amount
...
Payment Payment collection form
seq Collection No
date Date of collection
source Source of payment collection
amount amount of money
...
Invoice Invoice form
code Invoice number
date Invoice date
customer Customer
amount Invoice amount
...
Now I want to count the contract amount every day 、 Return amount and invoice amount , I can write this as :
SELECT Contract.SUM(price), Payment.SUM(amount), Invoice.SUM(amount) ON date
FROM Contract GROUP BY date
FULL JOIN Payment GROUP BY date
FULL JOIN Invoice GROUP BY date
Here we need to put date stay SELECT The result set is aligned by date .
This kind of writing , Don't worry about the relationship between the three tables , Just write the relevant parts , It seems that these tables are not related , What connects them together is the dimension to be aligned together ( Here is date).
These kinds of JOIN The situation may also be mixed .
Continue to give examples , Continue to use the contract form above , Then there is the customer table and the salesperson table
Customer Customer list
id Customer number
name Customer name
area The region
...
Sales Salesman list
id Employee number
name full name
area Responsible area
...
among Contract In the table customer The field points to Customer Table foreign key .
Now we want to count the number of salespeople and contract amount in each region :
SELECT Sales.COUNT(1), Contract.SUM(price) ON area
FROM Sales GROUP BY area
FULL JOIN Contract GROUP BY customer.area
Dimension alignment can cooperate with the writing of foreign key attributes .
In these examples , The final JOIN They are all the same dimension tables . in fact , Dimension alignment and primary sub table alignment , But relatively rare , We won't discuss it in depth here .
in addition , At present, these simplified grammars are still schematic , You need to define the concept of dimension strictly before you can formalize it , Become a sentence that can be interpreted and executed .
We call this simplified grammar DQL(Dimensional Query Languange),DQL It is a dimension oriented query language . We have already DQL It has been realized in the project , And serve as a reference for the moistening report DQL The server releases , It can DQL Sentences translated into SQL Statement execution , That is, it can run on any relational database .
Yes DQL Readers who are interested in theory and application can pay attention to the papers and related articles published in Qian college .
5、 ... and . Solve associated queries
We re-examine and define equivalence JOIN operation , And simplified the grammar . A direct effect is obviously to make the statement It is easier to write and understand . Foreign key attributions 、 The assimilation of the same dimension table and the aggregation of sub tables directly eliminate the explicit association operation , It is also more in line with natural thinking ; Dimension alignment can make programmers no longer care about the relationship between tables , Reduce the complexity of statements .
simplify JOIN The benefit of grammar is not just that , Can also be Reduce the error rate .
We know ,SQL Allowed WHERE To write JOIN Filter condition of operation ( Review the original definition of Cartesian product ), Many programmers are used to writing this . When JOIN When there are only twoorthree watches , That's not a big problem , But if JOIN There are sevenoreight or even a dozen watches , Omit one JOIN The condition is very likely . And omitted JOIN Condition means that many to many complete cross product will occur , And this SQL But it can be executed normally , On the one hand, the calculation results will be wrong ( Recall what I said before , Many to many JOIN when , The probability is that the sentence is misspelled ), On the other hand , If the list of missing conditions is large , The scale of the Cartesian product will be square , This is very likely to put the database directly “ Run to death ”!
The simplified JOIN grammar , It is impossible to miss writing JOIN Condition of the situation . Because of JOIN Is no longer based on Cartesian product , And these grammars have been designed assuming that many to many associations have no business meaning , There is no complete cross product operation under this rule .
For operations aligned with the main table after grouping multiple sub tables , stay SQL To be written in the form of multiple subqueries . But if there is only one child table , You can start with JOIN Again GROUP, There is no need to subquery . Some programmers don't analyze it carefully , This method will be extended to the case of multiple sub tables , Also first JOIN Again GROUP, You can avoid using subqueries , But the result is wrong .
This kind of error is not easy to occur when using dimension alignment , No matter how many sub tables , No subquery is required , A sub table and multiple sub tables are written in exactly the same way .
Take a fresh look at JOIN operation , The key role is Implementation of associated query .
At present BI The product is a hot , Each product claims that it can allow business personnel to drag and drop to complete the desired query report . But the actual application effect will be far from satisfactory , Business people still have to turn to IT department . The main reason for this phenomenon is that most business queries are process based calculations , It would have been impossible to drag and drop . however , Some business queries do not involve multi-step processes , And business people are still hard to complete .
This is called Association query , And most of them BI The weakness of the product . In the previous article, we have talked about why it is difficult to do association queries , The root cause is SQL Yes JOIN The definition of is too simple .
result ,BI The working mode of the product becomes that the technician builds the model first , Then the business personnel will query based on the model . The so-called modeling , Is to generate a logical or physical wide table . in other words , Modeling should be implemented separately for different associated requirements , We call it On demand modeling , By this time BI You lose agility .
however , If we change the right JOIN An operational view , Association query can be fundamentally solved . Recall the three mentioned above JOIN And its simplified means , In fact, we have transformed the multi table Association in these cases into a single table query , Business users have no obstacles to understand single table queries . Nothing more than the attributes of the table ( Field ) A little more complicated : There may be sub attributes ( The dimension table that the foreign key field points to and references its fields ), Sub attributes may also have sub attributes ( Multi tier dimension tables ), Some field values are collections rather than single values ( The sub table is regarded as the field of the main table ). The occurrence of correlation or even self correlation does not affect understanding ( The previous example of American employees of Chinese managers is related to each other ), Of course, having the same dimension as a table is not an obstacle ( Each has its own sub attributes ).
Under this correlation mechanism , Technical personnel only need to put the data structure ( Metadata ) Well defined , In the right interface ( List the fields of the table in a hierarchical tree rather than a regular line ), It can be realized by the business personnel themselves JOIN operation , There is no need for technical personnel to participate . Data modeling only occurs when the data structure changes , There is no need to model new associated requirements , This is the same. Non on demand modeling , Supported by this mechanism BI To have enough agility .
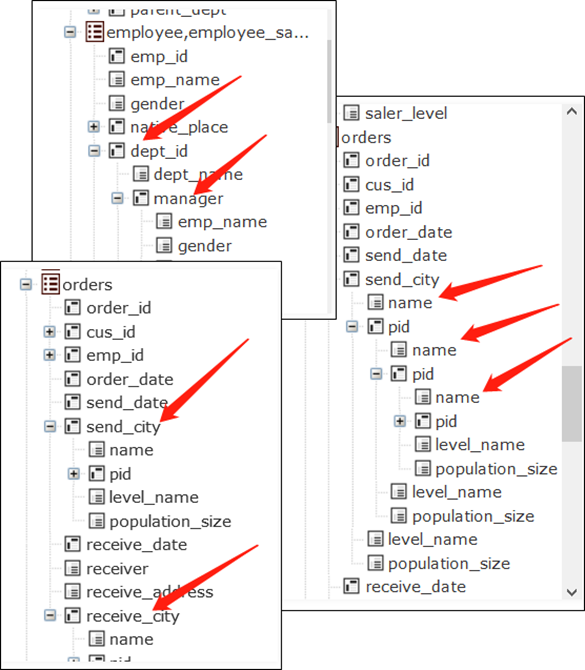
6、 ... and 、 Foreign key preassociation
Let's study how to use JOIN Features to optimize performance , There are many details of these contents , Let's pick some examples that are easy to understand , For a more perfect connection acceleration algorithm, please refer to the 《 performance optimization 》 Books and SPL The performance optimization feature article in the learning materials .
Let's first look at the foreign key Association in full memory .
There are two tables :
customer Customer information sheet
key Number
name name
city City
...
orders The order sheet
seq Serial number
date date
custkey Customer number
amount amount of money
...
among orders In the table custkey It's pointing customer In the table key The foreign key of the field ,key yes customer Primary Key .
Now the total amount of orders in our cities ( To simplify the discussion , No longer set conditions ), use SQL Write out :
SELECT customer.city, SUM(orders.amount)
FROM orders
JOIN customer ON orders.custkey=customer.key
GROUP BY customer.city
Databases generally use HASH JOIN Algorithm , The associated keys in the two tables are required HASH Value and compare .
We use the simplified JOIN grammar (DQL) Write this operation :
SELECT custkey.city, SUM(amount)
FROM orders
GROUP BY custkey.city
This way of writing actually indicates that it can have better optimization schemes , Let's see how to implement .
If all the data can be loaded into memory , We can do that Foreign key addressing .
List the facts orders Foreign key fields in custkey, Convert to dimension table customer Address of the associated record in , namely orders Tabular custkey The value of is already a customer The records in the table , Then you can directly reference the fields of records for calculation .
use SQL It is impossible to describe the detailed process of this operation , We use SPL To describe 、 And use the file as the data source to explain the calculation process :
| A | |
|---|---|
| 1 | =file(“customer.btx”)[email protected]() |
| 2 | >[email protected](key) |
| 3 | =file(“orders.btx”)[email protected]() |
| 4 | >A3.switch(custkey,A1) |
| 5 | =A3.groups(custkey.city;sum(amount)) |
A1 Read the customer table ,A2 Set the primary key and index for the customer table .
A3 Read the order form ,A4 The action of is to A3 Foreign key fields of custkey Convert to corresponding A1 The record of , After the execution , Order table fields custkey Will become a record of the customer table .A2 Building an index can make switch faster , Because the fact table is usually much larger than the dimension table , This index can be reused many times .
A5 You can perform group summary , When traversing the order table , because custkey The field value is now a record , Then it can be used directly . The operator references its field ,custkey.city It can be executed normally .
complete A4 Medium switch After the action , In memory fact table A3 Of custkey The field storage content is already a dimension table A1 The address of a record of , This action is called foreign key addressing . When referring to dimension table fields , It can be taken out directly , There is no need to use foreign key values in A1 Search for , It is equivalent to getting the fields of the dimension table in a constant time , Avoided HASH Value calculation and comparison .
however ,A2 Building a primary key index generally uses HASH Way , Yes key Calculation HASH value ,A4 Address translation is also a calculation custkey Of HASH Value and A2 Of HASH Index table comparison . If you only do one association operation , Addressing schemes and traditions HASH The calculation amount of the subsection scheme is basically the same , There is no fundamental advantage .
But the difference is , If the data can be put in memory , This address can be reused once converted , in other words A1 To A4 Just do it once , The next time you do the correlation operation on these two fields, you don't have to calculate HASH Value and compare , Performance can be greatly improved .
To be able to do this , It makes use of the uniqueness of the foreign key Association in the dimension table , A foreign key field value only corresponds to one dimension table record , You can put each custkey Convert to its only corresponding one A1 The record of . And continue to use SQL Chinese vs JOIN The definition of , You cannot assume that the foreign key points to the uniqueness of the record , This notation cannot be used . and SQL There is no record of address data type , The result is that each association is calculated HASH Value and compare .
and , If there are multiple foreign keys in the fact table pointing to multiple dimension tables , Conventional HASH piecewise JOIN The scheme can only resolve one at a time , There are many. JOIN To perform the action many times , After each association, you need to keep the intermediate results for the next round , The calculation process is much more complicated , The data will also be traversed many times . The foreign key addressing scheme is used to address multiple foreign keys , Just traverse the fact table once , No intermediate results , The calculation process should be much clearer .
And a little bit more , Memory is very suitable for parallel computing , but HASH piecewise JOIN The algorithm is not easy to parallel . Even if the data is segmented in parallel HASH value , But the same HASH The records of values are gathered together for the next round of comparison , There will also be shared resources preemption , This will sacrifice many of the advantages of Parallel Computing . And the outer key type JOIN Under the model , The status of the associated two tables is not equal , After clearly distinguishing the dimension table from the fact table , As long as the fact table is simply segmented, it can be calculated in parallel .
take HASH The segmentation technology is transformed by referring to the foreign key attribute scheme , It can also improve the one-time parsing and parallelism of multiple foreign keys to a certain extent , Some databases can implement this optimization at the engineering level . however , This optimization occurs when there are only two tables JOIN It's not a big problem , There are many watches and all kinds of JOIN When mixed , It is not easy for the database to identify which table should be traversed in parallel as a fact table 、 Other tables are created as dimension tables HASH Indexes , Optimization is not always effective . So we often find that when JOIN The phenomenon that the performance will drop sharply when the number of tables becomes large ( It often happens when there are fourorfive tables , The result set did not increase significantly ). And from JOIN After introducing the concept of foreign key into the model , Put this JOIN For special treatment , You can always tell the fact table from the dimension table , added JOIN Tables only lead to linear degradation of performance .
Memory database is a hot technology at present , But the above analysis shows that , use SQL The model's in memory database is JOIN It is difficult to get up quickly in operation !
7、 ... and 、 Further foreign key associations
Let's move on to foreign keys JOIN, And continue with the example in the previous section .
When the amount of data is too large to be put into memory , The aforementioned addressing method is no longer effective , Because the address calculated in advance cannot be saved in external memory .
In general , The size of the dimension table pointed to by the foreign key is small , And the growing list of facts is much larger . If the memory can put down the dimension table , We can use temporary pointing to handle foreign keys .
| A | |
|---|---|
| 1 | =file(“customer.btx”)[email protected]() |
| 2 | >[email protected](key) |
| 3 | =file(“orders.btx”)[email protected]() |
| 4 | >A3.switch(custkey,A1) |
| 5 | =A3.groups(custkey.city;sum(amount)) |
The first two steps are the same as for full memory , The first 4 Step address translation is performed while reading , And the conversion result cannot be retained for reuse , The next time you do the correlation, you have to calculate again HASH And comparison , The performance is worse than that of the full memory solution . In terms of calculation amount , Than HASH JOIN The algorithm has lost one dimension table HASH Value calculation , This dimension table will take advantage if it is often reused , But because the dimension table is relatively small , The overall advantage is not big . however , This algorithm also has the characteristics that the full memory algorithm can resolve all foreign keys at one time and is easy to be parallel , In the actual scene HASH JOIN The algorithm still has great performance advantages .
Based on this algorithm , We can also make a variant : Foreign key serialization .
If we can convert the primary keys of the dimension table to 1 The natural number of the beginning , Then we can directly locate the dimension table records with serial numbers , There is no need to calculate and compare HASH value , In this way, you can obtain the performance similar to that of addressing in full memory .
| A | |
|---|---|
| 1 | =file(“customer.btx”)[email protected]() |
| 2 | =file(“orders.btx”)[email protected]() |
| 3 | >A2.switch(custkey,A1:#) |
| 4 | =A2.groups(custkey.city;sum(amount)) |
When the primary key of a dimension table is a serial number, the original creation is not required HASH Index number 2 Step .
Serialization of foreign keys is essentially equivalent to addressing in external memory . This scheme needs to convert the foreign key fields in the fact table into sequence numbers , This is similar to addressing in full memory operations , This precomputation can also be reused . It should be noted that , When the dimension table changes significantly , You need to synchronize the foreign key fields of the fact table , Otherwise, it may correspond to dislocation . However, the change frequency of dimension table is generally low , And most actions are additions and modifications, not deletions , There are not many cases where the fact table needs to be reorganized . For the details of the project, you can also refer to the materials in Qian college .
SQL The concept of unordered sets is used , Even if we serialize the foreign keys in advance , Databases can't take advantage of this feature , The mechanism of rapid sequence number positioning cannot be used on unordered sets , Only the index can be used to find , And the database doesn't know that foreign keys are serialized , Still calculate HASH Value and comparison .
If the dimension table is too large to fit in memory ?
When we analyze the above algorithm carefully, we will find that , The access to the fact table in the process is continuous , But the access to dimension tables is random . We talked about the performance characteristics of hard drives before , External memory is not suitable for random access , Therefore, the dimension table in external memory can no longer use the above algorithm .
Dimension tables in external storage can be sorted and stored by primary key in advance , In this way, we can continue to use the feature that the dimension table association key is the primary key to optimize performance .
If the fact sheet is small , It can be installed in the memory , Then associating dimension table records with foreign keys will actually become a ( Batch ) External memory search action . As long as the dimension table has an index for the primary key , You can also quickly find , This avoids traversing large dimension tables , Get better performance . This algorithm can also resolve multiple foreign keys at the same time .SQL Do not distinguish between dimension tables and fact tables , When facing two tables, one large and one small , Optimized HASH JOIN No more heap splitting caching , Usually, small tables are read into memory and large tables are traversed , In this way, there will still be the action of traversing the large dimension table , The performance will be much worse than the external memory search algorithm just mentioned .
If the fact sheet is large , You can use Unilateral stacking The algorithm of . Because the dimension table has pressed the associated key ( The primary key ) Orderly , It is convenient to logically divide into several segments and take out the boundary value of each segment ( The maximum and minimum values of each primary key ), Then the fact table is stacked according to these boundary values , Each pile is associated with each segment of the dimension table . In the process, you only need to do physical heap caching on the side of the fact form , The dimension table does not need physical heap splitting cache , And don't use HASH function , Use segments directly , There can be no HASH Bad luck with the function leads to secondary heap splitting , Performance is controllable . And the database HASH The heap splitting algorithm will cache the two large tables in physical heap splitting , That is, bilateral stacking , It may also appear HASH Secondary heap splitting caused by bad luck of functions , The performance is much worse than that of single side heap splitting , Not yet controllable .
You can also use the power of clusters to solve the problem of large dimension tables .
The memory of a machine can't hold , We can get more machines to install , The dimension table is segmented and stored on multiple machines according to the primary key value Cluster dimension table , Then you can continue to use the above algorithm for memory dimension tables , You can also get the benefits of parsing multiple foreign keys at once and being easy to parallelize . similarly , Cluster dimension tables can also use serialization technology . In this algorithm , Fact tables do not need to be transferred , The resulting network traffic is not large , There is no need for the node to cache data locally . and SQL The dimension table cannot be distinguished under the system ,HASH The splitting method needs to make both tables Shuffle action , Internet traffic is much larger .
The details of these algorithms are still somewhat complicated , It is impossible to explain in detail due to space limitations , Interested readers can go to the information of Qian College .
8、 ... and 、 Orderly merge
Let's look at the same dimension table and the main sub table JOIN, The optimization and acceleration methods for these two cases are similar .
We discussed earlier ,HASH JOIN The computational complexity of the algorithm ( That is, the comparison times of the correlation key ) yes SUM(nimi), More complex than full traversal nm It's a lot smaller , But it depends on HASH The luck of a function .
If both tables are ordered for the associated key , So we can use the merge algorithm to deal with the correlation , The complexity here is n+m; stay n and m When it's all big ( It's usually much bigger than HASH The value range of the function ), This number will also be much smaller than HASH JOIN Algorithm complexity . The details of the merging algorithm are introduced in many materials , I won't go into that here .
however , Foreign keys JOIN You can't use this method , Because in fact, there may be multiple foreign key fields to participate in the association , It is impossible to make the same fact table orderly for multiple fields at the same time .
The same dimension table and primary sub table can !
Because the same dimension table and the primary sub table are always associated with the primary key or part of the primary key , We can sort the data of these associated tables according to their primary key in advance . The cost of sorting is high , But disposable . Once the sorting is complete , In the future, we can always use the merging algorithm to realize JOIN, Performance can be improved a lot .
This also makes use of the fact that the association key is the primary key ( And its parts ) Characteristics of .
Orderly merging is especially effective for big data . Primary sub tables such as orders and their details are growing fact tables , Over time, it often accumulates very large , It is easy to exceed the memory capacity .
External storage of big data HASH The heap splitting algorithm needs to generate a lot of cache , Data is read twice and written once in external memory ,IO Costly . And the merging algorithm , The data of both tables can be read only once , Didn't write . Not only is CPU The amount of calculation is reduced , External storage IO It's also down a lot . and , Little memory is needed to perform the merge algorithm , Just keep several cache records in memory for each table , It hardly affects the memory requirements of other concurrent tasks . and HASH Heap splitting requires a large amount of memory , Read more data each time , In order to reduce the number of heap splitting .
SQL Defined by Cartesian product JOIN Operations do not distinguish JOIN type , Don't assume that some JOIN Always for primary keys , There is no way to take advantage of this feature at the algorithmic level , It can only be optimized at the engineering level . Some databases check whether the data table is in order for the associated fields in the physical storage , If ordered, merge algorithm is adopted , However, the relational database based on the concept of unordered set will not deliberately ensure the physical order of data , Many operations will destroy the implementation conditions of the merging algorithm . Using index can realize logical order of data , However, the traversal efficiency will be greatly reduced in case of physical disorder .
The premise of orderly merging is to sort the data by primary key , And this kind of data is often appended , In principle, you should sort again after each addition , And we know that the sorting cost of big data is usually very high , Does this make it difficult to append data ? Actually , The process of adding additional data is also an orderly merging , Sort the new data separately and merge them with the ordered historical data , Complexity is linear , It is equivalent to rewriting all the data once , Unlike conventional big data sorting, which requires cache write and read . Doing some optimization actions in the project can also make it unnecessary to rewrite it all every time , Further improve maintenance efficiency . These are all introduced in Qian college .
The advantage of orderly merging is that it is easy to segment and parallel .
Modern computers have multicore CPU,SSD The hard disk also has strong concurrency , Using multithreaded parallel computing can significantly improve performance . But traditional HASH It is difficult to realize parallelism by using heap splitting technology , Multithreading does HASH When splitting the heap, you need to write data to a certain heap at the same time , Cause shared resource conflict ; In the second step, a large amount of memory will be consumed when a component heap association is implemented , It is impossible to implement a large number of parallels .
The use of ordered merging to achieve parallel computing requires the data to be divided into multiple segments , Single table segmentation is simple , But when two associated tables are segmented, they must be aligned synchronously , Otherwise, the data of the two tables are misaligned when merging , You can't get the correct result , And data ordering can ensure high-performance synchronous alignment segmentation .
First put the main table ( For the same dimension table, take the larger one , Other discussions do not affect ) Divided into several sections equally , Read the primary key value of the first record in each segment , Then use these key values to find the location in the sub table by dichotomy ( Because it is also orderly ), So as to obtain the segmentation point of the sub table . This ensures that the segments of the primary and child tables are aligned synchronously .
Because the key values are in order , Therefore, the record key value of each segment of the main table belongs to a continuous interval , Records whose key values are outside the range will not be in this segment , Records with key values in the interval must be in this segment , The record key value of the corresponding segment of the sub table also has this feature , So there will be no dislocation ; And also because the key values are in order , Then we can perform efficient binary search in the sub table and quickly locate the segmentation point . That is, the orderly data ensures the rationality and efficiency of segmentation , In this way, we can safely execute parallel algorithms .
The primary key relationship between primary tables and child tables has another feature , That is, a child table is only associated with a primary table on the primary key ( In fact, the same dimension table also has , But it is easy to explain with the master sub table ), It won't have multiple unrelated primary tables ( There may be a main table with a main table ). Now , You can also use the mechanism of integrated storage , Store the sub table records as the field values of the main table . such , On the one hand, the storage capacity is reduced ( The associated key is stored only once ), It is also equivalent to making a connection in advance , There's no need to compare . For big data , You can get better performance .
We have applied these performance optimization methods to the set solver SPL And has been applied in the actual scene , It has also achieved very good results .SPL Open source , Readers can go to the official website and forums of shusu company or Runqian company to download and get more information .
Conclusion
JOIN Operations are indeed the most complex operations in a database , This paper deals with JOIN The operation is deeply analyzed and sorted out , The space is not small , But it still hasn't completely exhausted all aspects .
Interested students can further study dry College (c.raqsoft.com.cn) Books and articles on .
There is also a video material in this article : Optimization and acceleration of connection operation
SPL Information
Welcome to SPL Interested assistant (VX Number :SPL-helper), Into the SPL Technology exchange group
边栏推荐
- RHCSA3
- Research: data security tools cannot resist blackmail software in 60% of cases
- Ecplise development environment configuration and simple web project construction
- SAP self-development records user login logs and other information
- 实战模拟│JWT 登录认证
- ActiveMQ installation and deployment simple configuration (personal test)
- 《信息系统项目管理师》备考笔记---信息化知识
- Taobao product details API | get baby SKU, main map, evaluation and other API interfaces
- 非技术部门,如何参与 DevOps?
- Reshape the power of multi cloud products with VMware innovation
猜你喜欢
JDBC -- use JDBC connection to operate MySQL database
Transactions from December 27 to 28, 2021
![[figure neural network] GNN from entry to mastery](/img/e2/bb045fb03bc255b8659f9ca7cdd26b.jpg)
[figure neural network] GNN from entry to mastery
Resnet+attention project complete code learning
2021.12.16-2021.12.20 empty four hand transaction records
I met Tencent in the morning and took out 38K, which showed me the basic smallpox
Ecplise development environment configuration and simple web project construction
Simply take stock reading notes (4/8)
国内市场上的BI软件,到底有啥区别
Taobao short videos are automatically released in batches without manual RPA open source
随机推荐
ZABBIX agent2 monitors mongodb nodes, clusters and templates (official blog)
DNS的原理介绍
Pytoch implements tf Functions of the gather() function
Volatile instruction rearrangement and why instruction rearrangement is prohibited
Oppo Xiaobu launched Obert, a large pre training model, and promoted to the top of kgclue
Distributed solution - completely solve website cross domain requests
Preliminary exploration of basic knowledge of MySQL
在家庭智能照明中应用的测距传感芯片4530A
Principle of universal gbase high availability synchronization tool in Nanjing University
UNIX socket advanced learning diary -ipv4-ipv6 interoperability
Research: data security tools cannot resist blackmail software in 60% of cases
HiEngine:可媲美本地的云原生内存数据库引擎
#yyds干货盘点#js截取文件后缀名
Add a new cloud disk to Huawei virtual machine
Annotation problem and hidden Markov model
Distance measuring sensor chip 4530a used in home intelligent lighting
GPON technical standard analysis I
How do e-commerce sellers refund in batches?
激动人心!2022开放原子全球开源峰会报名火热开启!
Taobao product details API | get baby SKU, main map, evaluation and other API interfaces