当前位置:网站首页>Tflite model transformation and quantification
Tflite model transformation and quantification
2022-07-07 03:56:00 【Luchang-Li】
ref
https://www.tensorflow.org/lite/convert?hl=zh-cn
if you're using TF2 then the following will work for you to post quantized the .pb file.
import tensorflow as tf
graph_def_path = "resnet50_v1.pb"
tflite_model_path = "resnet50_v1.tflite"
input_arrays = ["input_tensor"]
input_shapes = {"input_tensor" :[1,224,224,3]}
output_arrays = ["softmax_tensor", "ArgMax"]
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(graph_def_path, input_arrays, output_arrays, input_shapes)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with open(tflite_model_path, "wb") as f:
f.write(tflite_model)
incase if you want full int8 quantization then
import tensorflow as tf
from google.protobuf import text_format
graph_def_path = "resnet50_v1.pb"
tflite_model_path = "resnet50_v1_quant.tflite"
input_arrays = ["input_tensor"]
input_shapes = {"input_tensor" :[1,224,224,3]}
output_arrays = ["softmax_tensor", "ArgMax"]
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(graph_def_path, input_arrays, output_arrays, input_shapes)
tflite_model = converter.convert()
converter.optimizations = [tf.lite.Optimize.DEFAULT]
image_shape = [1,224,224,3]
def representative_dataset_gen():
for i in range(10):
# creating fake images
image = tf.random.normal(image_shape)
yield [image]
# IMAGE_MEAN = 127.5;
# IMAGE_STD = 127.5;
# def norm_image(img):
# img_f = (np.array(img, dtype="float32")- IMAGE_MEAN) / IMAGE_STD;
# return img_f
# def read_image(img_name):
# img = cv2.imread(img_name)
# tgt_shape = [299,299]
# img = cv2.resize(img, tgt_shape).reshape([1,299,299,3])
# return img
# def representative_dataset_gen():
# img_folder="resnet_v2_101/test_imgs/"
# img_names = glob.glob(img_folder+"*.jpg")
# for img_name in img_names:
# img = read_image(img_name)
# img = norm_image(img)
# yield [img]
converter.representative_dataset = tf.lite.RepresentativeDataset(representative_dataset_gen)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
tflite_model = converter.convert()
with open(tflite_model_path, "wb") as f:
f.write(tflite_model)
FP16 quantitative :
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()float16 The advantages of quantification are as follows :
Reduce the size of the model by half ( Because all weights become half their original size ).
Achieve minimum accuracy loss .
Support can be directly to float16 Partial delegation of data to perform operations ( for example GPU entrust ), So that the execution speed is faster than float32 Faster calculation .
float16 The disadvantages of quantification are as follows :
It does not reduce the delay as much as quantifying fixed-point mathematics .
By default ,float16 The quantitative model is CPU When running on, the weight value will be “ Inverse quantization ” by float32.( Please note that ,GPU Delegates do not perform this dequantization , Because it can be good for float16 Data operation .)
have 8 Bit weighted 16 Bit activation
That is to say A18W8 quantitative
This is an experimental quantitative scheme . It is associated with “ Integer only ” Similar scheme , However, it will be quantified as 16 position , The weight will be quantified as 8 An integer , The deviation will be quantified as 64 An integer . This is further referred to as 16x8 quantitative .
The main advantage of this quantization is that it can significantly improve the accuracy , But it only slightly increases the size of the model .
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.representative_dataset = representative_dataset
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8]
tflite_quant_model = converter.convert()If some operators in the model do not support 16x8 quantitative , The model can still be quantified , However, unsupported operators are retained as floating-point operators . Allow this operation , The following options should be added to target_spec in .
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.representative_dataset = representative_dataset
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS]
tflite_quant_model = converter.convert()Examples of use cases that have improved accuracy through this quantization scheme include :* Super resolution 、* Audio signal processing ( Such as noise reduction and beamforming )、* Image denoising 、* Single image HDR The reconstruction .
The disadvantage of this quantification is :
- Due to the lack of optimized Kernel Implementation , The current inference speed is significantly faster than 8 Bit full integer slow .
- At present, it is not compatible with existing hardware acceleration TFLite entrust .
notes : This is an experimental function .
Can be in here Find the tutorial of the quantitative model .
Model accuracy
Because the weight is quantified after training , Therefore, it may cause a loss of accuracy , This is especially true for smaller networks .TensorFlow Lite Model repository It provides a fully quantitative model of pre training for a specific network . Be sure to check the accuracy of the quantitative model , To verify that any decline in accuracy is within an acceptable range . There are some tools to evaluate TensorFlow Lite Model accuracy .
in addition , If the accuracy drops too much , Please consider using Quantitative perception training . however , This requires modifications during model training to add pseudo quantization nodes , The post training quantization technology on this page uses the existing pre training model .
The representation of the quantized tensor
8 Bit quantization approximates the floating-point value obtained using the following formula .
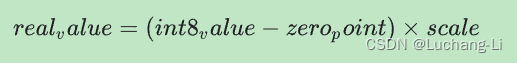
The representation consists of two main parts :
from int8 The complement value represents the axis by axis ( That is, channel by channel ) Or tensor by tensor weight , The scope is [-127, 127], Zero equals 0.
from int8 The complement value represents the tensor by tensor activation / Input , The scope is [-128, 127], The zero point range is [-128, 127].
Details about the quantification scheme , Please refer to our Quantitative specification . For want to insert TensorFlow Lite The hardware supplier who entrusts the interface , We encourage you to implement the quantitative scheme described in this specification .
边栏推荐
- PHP lightweight Movie Video Search Player source code
- Create commonly used shortcut icons at the top of the ad interface (menu bar)
- [leetcode] 700 and 701 (search and insert of binary search tree)
- 如何自定义Latex停止运行的快捷键
- 太方便了,钉钉上就可完成代码发布审批啦!
- termux设置电脑连接手机。(敲打命令贼快),手机termux端口8022
- Restcloud ETL Community Edition June featured Q & A
- 史上最全学习率调整策略lr_scheduler
- Open3D 网格滤波
- qt-线程等01概念
猜你喜欢
Mobile measurement and depth link platform - Branch
史上最全学习率调整策略lr_scheduler
About Confidence Intervals
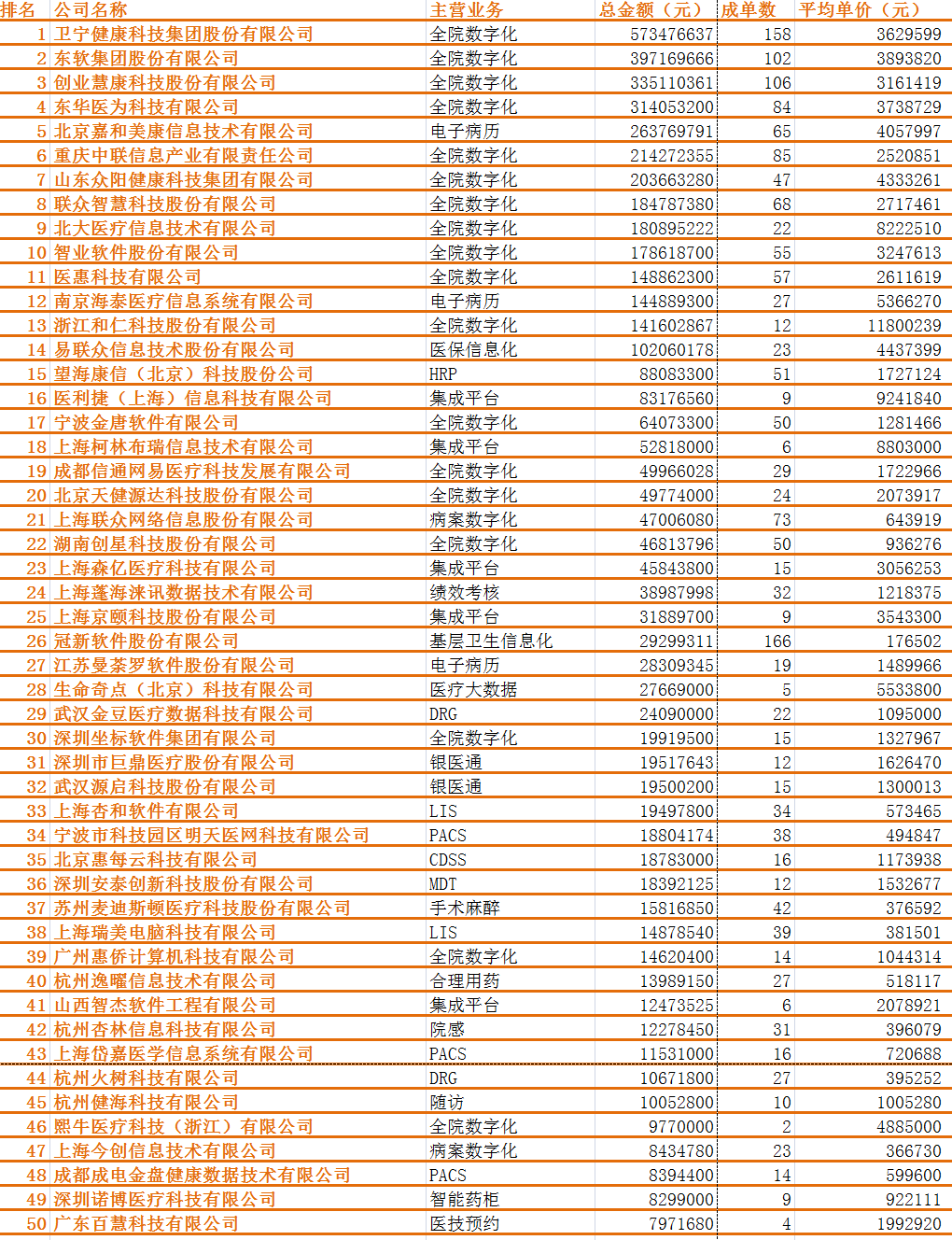
2022年上半年HIT行业TOP50

Can the applet run in its own app and realize live broadcast and connection?

Restcloud ETL Community Edition June featured Q & A
Open3D 网格滤波

25. (ArcGIS API for JS) ArcGIS API for JS line modification line editing (sketchviewmodel)

It's too convenient. You can complete the code release and approval by nailing it!

QT 使用QToolTip 鼠标放上去显示文字时会把按钮的图片也显示了、修改提示文字样式
随机推荐
[leetcode] 450 and 98 (deletion and verification of binary search tree)
浅谈网络安全之文件上传
我的勇敢对线之路--详细阐述,浏览器输入URL发生了什么
红米k40s root玩机笔记
web服务性能监控方案
Tencent cloud native database tdsql-c was selected into the cloud native product catalog of the Academy of communications and communications
2022夏每日一题(一)
My brave way to line -- elaborate on what happens when the browser enters the URL
ubuntu20安装redisjson记录
Free PHP online decryption tool source code v1.2
CMB's written test - quantitative relationship
VHDL implementation of single cycle CPU design
MySQL storage engine
A 股指数成分数据 API 数据接口
First understand the principle of network
Ubuntu 20 installation des enregistrements redisjson
About Estimation Statistics
Force buckle ----- path sum III
NoSQL之Redis配置与优化
Ggplot facet detail adjustment summary