当前位置:网站首页>This time, thoroughly understand the MySQL index
This time, thoroughly understand the MySQL index
2022-07-06 13:38:00 【Li bohuan】
Catalog
Two : The underlying principle of indexing ——B+ Tree analysis
3、 ... and : Clustered index and non clustered index
Four : Inability to utilize indexes
One : Basic overview of index
I don't say much nonsense , Look directly at the official definition of index : A kind of help mysql Data structure to improve query efficiency . So the advantage of indexing is : It greatly accelerates the speed of data query !! however , Index also has its disadvantages :
- Maintaining the index requires the resources of the database
- Indexing requires disk space
- When adding, deleting and modifying the data in the table , Because to maintain the index , It's affected by speed
Look at the classification of the index (innodb): primary key : After being set as the primary key, the database will automatically index it ,innodb Index for clustering . Single value index : That is, an index contains only a single column , A table can have multiple single-column indexes . unique index : The value of the index must be unique , But null values are allowed . Composite index : That is, an index contains multiple columns . Primary key index Index column value cannot be empty , The index column value of the unique index can be empty .
Finally, let's take a look at the basic operation of indexing , First, let's look at the primary key index , It is automatically created . We create a... In the database user surface , Let's look at its index . You can see the index name Key_name yes PRIMARY, The index type is BTREE, Here is B+ Trees , Not at all B Trees .
-- The primary key index is automatically created when creating a table --
create table user(id varchar(20) primary key, name varchar(20));
------
show index from user;
Let's look at the general index ( Single value index ), There are two ways to create , One is When creating a table , One is Create a table after it is created . above user Table has been created , Let's see how to give name Field plus index . You can use the following sql sentence , give the result as follows .
CREATE index name_index on user(name);
------
show index from user;
We can also create ordinary indexes when creating tables , When creating an index, you cannot actively specify the index name , The default is consistent with the field name , The creation method and results are as follows .
create table teacher(id varchar(20) primary key, name varchar(20),key(name));
------
show index from teacher;
Then let's look at the unique index , It can also be created when and after creating a table , Similar to normal index creation , It's just using unique keyword , As shown in the figure , When and after creating the table . Note the unique index Null when YES, That is, the index column value can be empty .
create table teacher2(id varchar(20) primary key, name varchar(20),unique(name));
------
show index from teacher2;
create table teacher3(id varchar(20) primary key, name varchar(20));
create unique index name_index on teacher3(name);
show index from teacher3;
Finally, let's look at the creation of composite index , It is based on multiple columns to create an index , It is similar to ordinary index creation , Creating a table is key(name,age,bir), After the table is created create index name_index on user(name,age,bir), No more demonstrations . Pay attention to one point , When creating an index name,age,bir There is order and quantity , When using the index, we first need to comply with the leftmost prefix principle . seeing the name of a thing one thinks of its function , That is to say The leftmost is the starting point of any continuous index They all match . in addition ,mysql In order to make better use of the index, the engine will Dynamically adjust the order of query fields , In order to take advantage of the index . For example, the above situation , If there is only the leftmost prefix principle , The query is only based on name and name,age as well as name,age,bir You can use the index . After introducing dynamic adjustment ,bir,age,name and name,bir,age You can also use indexes , As long as the leftmost prefix is included .
Two : The underlying principle of indexing ——B+ Tree analysis
First of all, let's think about a question , We query a certain data in the database , Is it faster to query in an ordered set or in an unordered set ? In a disordered set, we may be lucky , I found it once , But there may be bad luck , Traverse the whole set and finally find , If the amount of data in the database is large , This is very unstable and slow . And if it is an ordered set , The number and speed of our queries are relatively stable , And faster than unordered sets . therefore MySQL The data will be Sort , And use a pointer to Connect . You can see that the underlying inode is divided into three parts : Primary key value , Specific data , Pointer to the next node .

But here comes the problem , This forms a linked list structure , As shown in the figure below , We know that the time complexity of linked list query is O(n), This is very slow for massive data query . therefore MySQL It is optimized , Store data by page , Default storage 16KB, Then make a page directory , Query the data according to the page directory , As shown in the figure below . Page directories do not store specific data , It mainly stores every page First node Of Primary key value and pointer . thus , We first look in the page directory to find the data , According to the primary key value and pointer , And then locate specific data , In this way, query efficiency can be improved . When the amount of data is too high , We can add a page directory to the page directory , In this way, more data can be stored ! The above structure is B+ Trees .

So let's see , How much data can this design store . We see first 2 Layer of B+ Trees , That is, the root node and several leaf nodes , Each node is the page we mentioned above . Look at the root node first , Its internal structure is : Primary key + The pointer . Each page of the data 16KB, The general type of table is INT( Occupy 4 Bytes ) perhaps BIGINT(8 Bytes ), Pointer size again innodb The source code is set to 6 byte , We take the primary key as 8 byte . In this case , The root node can store 16KB/(8B+6B) = 1170 A pointer to the , And each pointer points to a page . Let's see how many pieces of data can be saved per page , Each piece of data consists of a primary key + The pointer + Data values , We calculate by the small , each page 16KB Storage 20 Data . In this case ,2 Layer of B+ Trees can store 1170 * 20 = 23400 Data . The third level is the two-level page directory plus leaf nodes , Be able to store 1170 * 1170 * 20 = 27,378,000 Data , Reach ten million level . Four layers can reach 10 billion level data .
Now let's take a closer look B+ Some introduction of trees , And why not choose B Tree as index data structure .B+ The tree is right B Tree optimization , Let's take a look first B Trees .
B Trees are a kind of Self balancing tree , One m Step B Trees , Will meet some characteristics , Include B The order of a tree is the number of child nodes at most , Each non leaf node will contain keyword information and pointer information , most important of all B The search of the tree may end at a non leaf node ,B The search of the tree starts from the root node and performs binary search according to keywords , If it hits a non leaf node, it ends , Otherwise, continue to look down through the pointer . and B+ Trees Search process and B Trees Basically the same , The difference lies in B+ The tree ends only when the leaf node is searched , All keywords will appear in the linked list composed of leaf nodes , And the keywords of the linked list are ordered from left to right . A non leaf node is the index of a leaf node , Not specific data .B+ The tree is shown in the figure below .
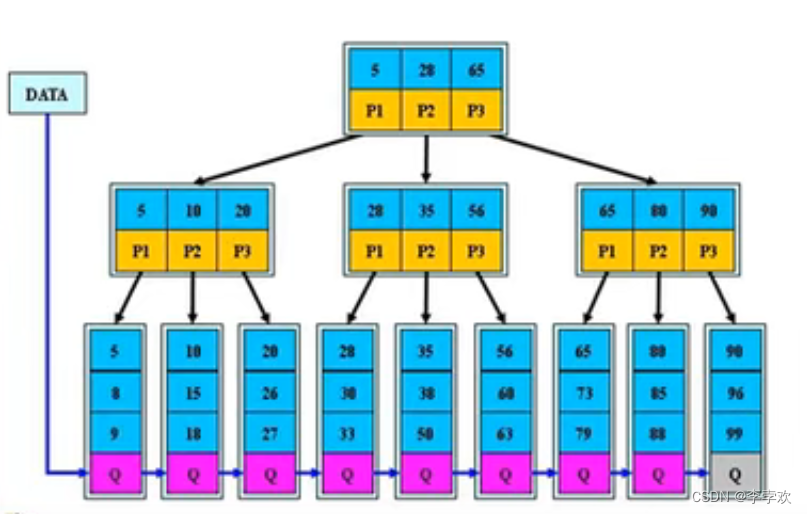
You can see ,B Treelike Non leaf nodes also store data data, In this case , According to our above calculation , Contents of each page (16KB) The number of pointers that can be stored will be reduced , Then store the same amount of data ,B The number of layers of trees may be higher than B+ Trees !! This will increase the number of disks IO The number of times ( Every query node ( page ) There will be a disk IO),I/O Reading and writing times are the main factors that affect the efficiency of index retrieval , Then it affects the efficiency of query . in addition ,B Trees in Query based on range There is no performance in the operation of B+ Good tree , because B+ The leaf node of the tree uses Pointer order links together , As long as you traverse the leaf node, you can traverse the whole tree , Comparison B+ For trees , because B The leaf nodes of the tree are independent of each other , So for range query , You need to query again from the root node , Added disk I/O Operating frequency . Last ,B+ Tree addition and deletion file ( node ) when , More efficient , because B+ The leaf node of the tree contains all the keywords , And Orderly linked list structure storage , This can improve the efficiency of addition and deletion .
MySQL Of innodb The storage engine is designed to keep the root node in memory , That is, to find the row record of a key value, only 1-3 Secondary disk IO operation (3 layer B+ Trees ). The primary key index can be used twice at most IO You can find it , The ordinary index will find the primary key index first and then search , So there will be one more disk IO.
AVL Trees compare with B Trees are less efficient , The first is that each node stores too little data , The second is that the height of the tree is higher , disk IO The number is even higher . So why not use hash table as the data structure of index ? There are mainly the following reasons
- Fuzzy Lookup does not support : Hash table is to map the index field into the corresponding hash code, and then store it in the corresponding location , In this case , If we're going to do a fuzzy search , Obviously, hash table structure is not supported , You can only traverse this table . and B+ The tree can quickly find the corresponding data through the leftmost prefix principle .
- Range lookup is not supported : If we want to do a range lookup , For example, find ID by 1 ~ 500 People who , Hash tables also do not support , Can only traverse the whole table
- Hash conflict problem : The index field is mapped into hash code through hash , If many fields just map to the hash code of the same value , Then the index structure will be a long linked list , In this case , The search time will be greatly increased
3、 ... and : Clustered index and non clustered index
First look at the definition , Cluster index : Put the data storage and index together , The leaf node of the index structure holds the row data . Nonclustered index : Store data and indexes separately , The leaf node of the index structure points to the corresponding position of the data . To put it bluntly, the index we drew above is cluster index , Put the data storage and index together !! A clustered index is not necessarily a primary key index , The primary key index must be a clustered index . Actual data page Only according to one tree B+ Trees sort , So each table can only have one clustered index , The rest are non clustered indexes , Non clustered index can be understood as built on non clustered index ( Secondary index ) Index above . The secondary index leaf node no longer stores the physical location of the row , It's the primary key value , Secondary index access data always requires secondary search . As shown in the figure below .
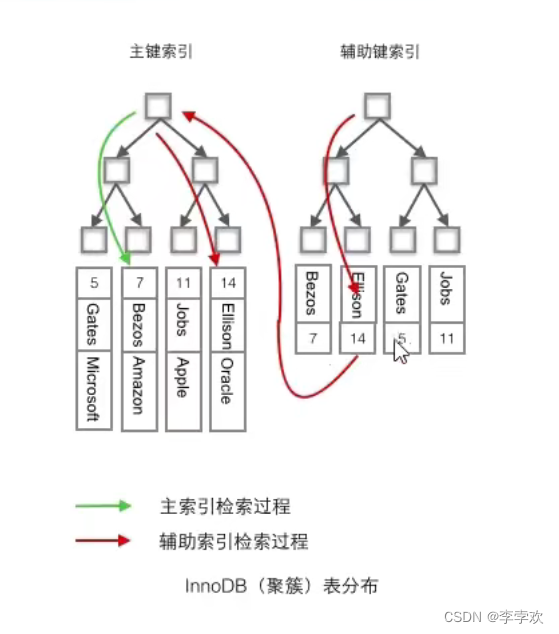
- InnoDB Using clustered index , Organize the primary key into a tree B+ In the tree , The row data is stored on the leaf node , If you use "where id=14" This condition looks up the primary key , According to B+ The search algorithm of tree can find the corresponding leaf node , Then get the line data .
- If yes Name Column to search , It takes two steps ∶ The first step is to assist in indexing B+ Search the tree for Name, Go to its leaf node to get the corresponding primary key . The second step is to use the primary key in the primary index B+ The tree species will be executed once more B+ Tree retrieval operations , Finally, you can get the whole row of data when you reach the leaf node .( The point is that you need to build secondary indexes through other keys ).
- Cluster index is the primary key by default , If the primary key is not defined in the table ,InnoDB A unique and non empty index will be selected instead of .
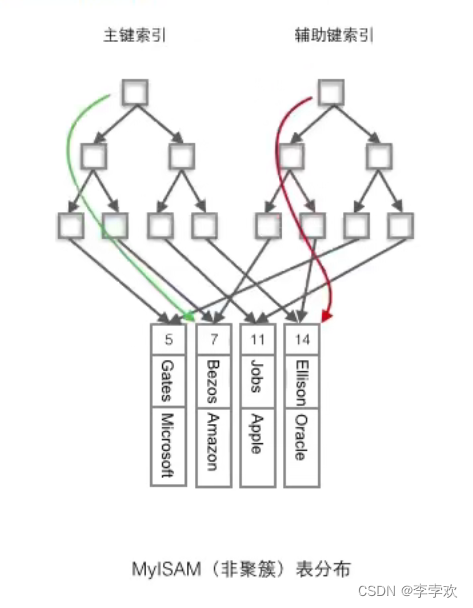
MyISAM Using a non clustered index , Two non clustered indexes B+ Trees don't look different , The structure of nodes is completely consistent, but The content stored is different nothing more , primary key B+ The node of the tree stores the primary key , Secondary key index B+ The tree stores auxiliary keys . Table data is stored in a separate place , These two B+ The leaf nodes of the tree all use an address to point to the real table data , For table data , There is no difference between the two keys . Because the index tree is independent , Retrieve the index tree without access to the primary key through the secondary key .
So here comes the question , Every time you use a secondary index, you have to go through two B+ Tree search , It seems that the efficiency of clustered index is obviously lower than that of non clustered index , Isn't that an unnecessary move ? What are the advantages of clustering index ?
- Because row data and clustered leaf nodes are stored together , There will be multiple rows of data on the same page , When accessing different row records of the same data page , The page has been loaded into Buffer in , On another visit , Access will be done in memory , You don't have to access the disk . In this way, the primary key and row data are loaded into memory together , Find the leaf node and immediately return the row data , If you follow the primary key ID To organize data , Getting data faster .
- The leaf node of the secondary index , Store primary key values , Instead of the address where the data is stored . The advantage is The maintenance cost of the index is lower , When the row data changes , The nodes of the index tree also need to be split and changed , Or the data we need to look up , Last time IO There is no... In the read-write cache , There needs to be a new IO In operation , It can avoid the maintenance of the secondary time index , Just maintain the clustered index tree . Another benefit is , Because the secondary index stores the primary key value , Reduce the storage space occupied by the secondary index .
Four : Inability to utilize indexes
- Use... In query statements LIKE keyword : Use... In a query statement LIKE Keyword query , If it matches the string The first character is "%", Index will not be used . If "%"" Not in the first position , The index will be used
- Use... In query statements Multi column index ( Composite index ): The multi column index is in the... Of the table Multiple fields Create an index on , Only the First field , Indexes are used .
- Use... In query statements OR keyword : The query statement has only OR When a keyword , If OR The columns of the two conditions are indexes , Then the index will be used in the query . If OR A column with one condition is not an index , Then the index will not be used in the query .
- If the column type is string , Be sure to use the index in the condition No , Otherwise, the index is not used
- If mysql It is estimated that full table scanning is faster than indexing , Index is not used
If it helps you , You can praise bloggers and pay attention ~~~
边栏推荐
- 3. Number guessing game
- 强化学习系列(一):基本原理和概念
- There is always one of the eight computer operations that you can't learn programming
- FileInputStream和BufferedInputStream的比较
- Service ability of Hongmeng harmonyos learning notes to realize cross end communication
- Voir ui plus version 1.3.1 pour améliorer l'expérience Typescript
- ROS machine voice
- Redis实现分布式锁原理详解
- 为什么要使用Redis
- IPv6 experiment
猜你喜欢
Database operation of tyut Taiyuan University of technology 2022 database

9. Pointer (upper)

C语言实现扫雷游戏(完整版)

2.初识C语言(2)

5. Download and use of MSDN
甲、乙机之间采用方式 1 双向串行通信,具体要求如下: (1)甲机的 k1 按键可通过串行口控制乙机的 LEDI 点亮、LED2 灭,甲机的 k2 按键控制 乙机的 LED1
Change vs theme and set background picture
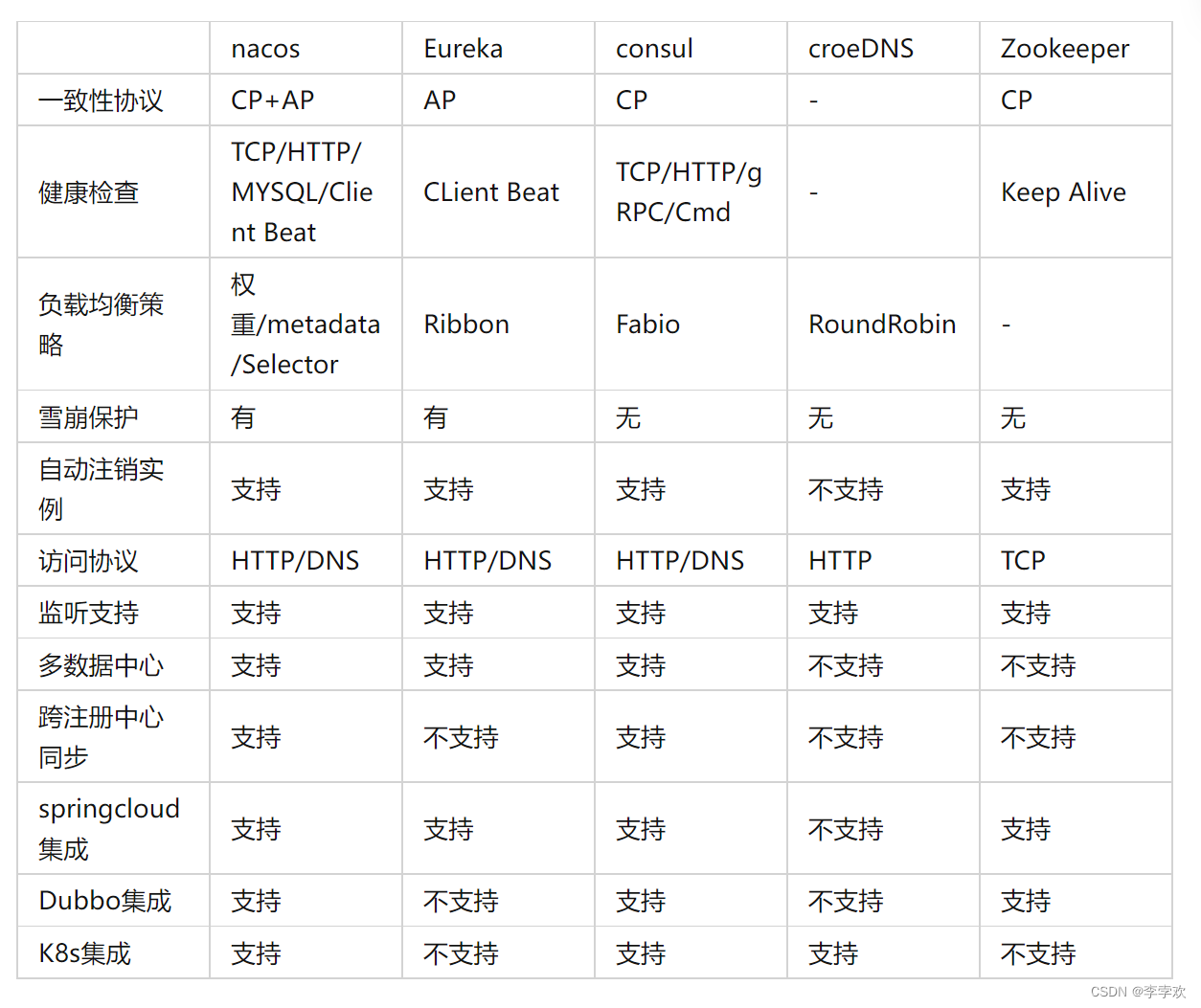
Custom RPC project - frequently asked questions and explanations (Registration Center)

8.C语言——位操作符与位移操作符
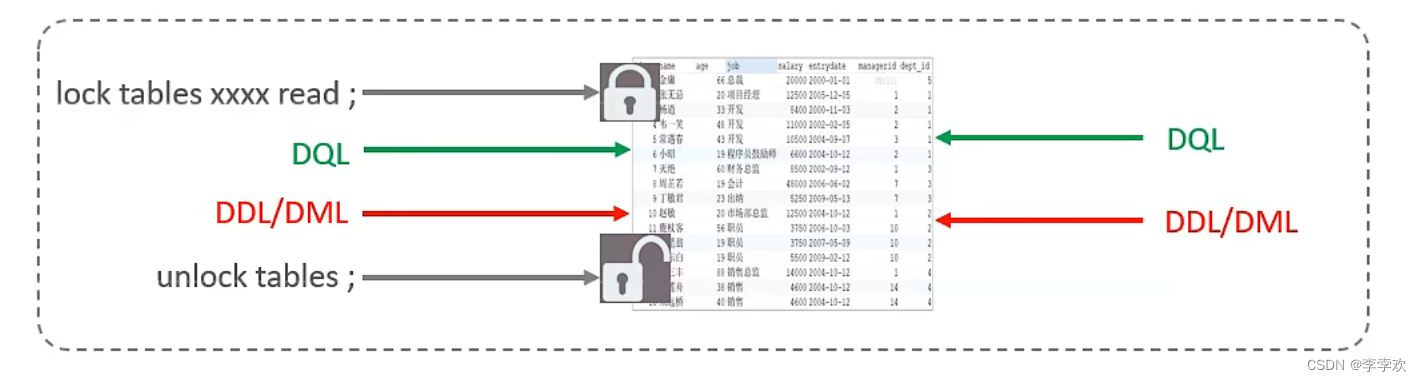
MySQL锁总结(全面简洁 + 图文详解)
随机推荐
Summary of multiple choice questions in the 2022 database of tyut Taiyuan University of Technology
Thoroughly understand LRU algorithm - explain 146 questions in detail and eliminate LRU cache in redis
View UI Plus 发布 1.2.0 版本,新增 Image、Skeleton、Typography组件
Atomic and nonatomic
[the Nine Yang Manual] 2018 Fudan University Applied Statistics real problem + analysis
6. Function recursion
Data manipulation language (DML)
ABA问题遇到过吗,详细说以下,如何避免ABA问题
A comprehensive summary of MySQL transactions and implementation principles, and no longer have to worry about interviews
MySQL Database Constraints
MPLS experiment
Leetcode.3 无重复字符的最长子串——超过100%的解法
View UI plus released version 1.2.0 and added image, skeleton and typography components
[面试时]——我如何讲清楚TCP实现可靠传输的机制
【九阳神功】2016复旦大学应用统计真题+解析
5月27日杂谈
5月14日杂谈
8. C language - bit operator and displacement operator
仿牛客技术博客项目常见问题及解答(二)
2.C语言矩阵乘法