当前位置:网站首页>Redis configuration and optimization of NoSQL
Redis configuration and optimization of NoSQL
2022-07-07 03:55:00 【Game programming】
introduction
NoSQL, A general term for a non-relational database . With the interconnection web2.0 The rise of websites , Traditional relational databases are dealing with web2.0 Website , Especially for super large-scale and highly concurrent types SNS Of web2.0 Pure dynamic website has appeared to be powerless , There are a lot of insurmountable problems , The non-relational database has developed rapidly due to its own characteristics .NoSQL The emergence of database is to solve the challenge of large data sets and multiple data types , Especially big data application problems .
One 、 Cache concept
Cache is to adjust the speed of two or more different substances with inconsistent speed , In the middle, it accelerates the slower side , such as CPU The first level of 、 The L2 cache is saved CPU Recently frequently accessed data , Memory is saved CPU Frequently access hard disk data , And the hard disk also has different sizes of cache , Even physical servers raid The card has a cache , All to accelerate CPU Purpose of accessing hard disk data , because CPU It's too fast ,CPU The required data can not be met in a short time due to the hard disk CPU The needs of , therefore CPU cache 、 Memory 、Raid Card cache and hard disk cache meet the requirements to a certain extent CPU Data requirements for , namely CPU Reading data from the cache can greatly improve CPU Work efficiency .
1、 System cache
(1)buffer And cache
buffer : Buffer is also called write buffer , Generally used for write operations , You can write data to memory first and then to disk ,buffer Generally used for write buffer , Buffer used to solve the speed inconsistency of different media , First, temporarily write the data to the nearest place in the , To improve write speed ,CPU The data will be written to the disk buffer in memory first , Then it is considered that the data has been written. Look , Then the kernel writes to the disk at a subsequent time , So if the server suddenly loses power, some data in memory will be lost .
cache : Cache is also called read cache , Generally used for read operations ,CPU Read file read from memory , If there is no memory, first read the memory from the hard disk, and then read CPU, Put the data that needs to be read frequently in its nearest cache area , The next time you read, you can quickly read .
2、 Cache storage location and hierarchy
Internet applications , Mention cache as king
User level : browser DNS cache , Applications DNS cache , operating system DNS Caching clients
Broker layer : CDN, Reverse proxy cache
Web layer : Web Server cache
application layer : Page static
The data layer : Distributed cache , database
System level : operating system cache
The physical layer : disk cache, Raid Cache
(1) DNS cache
Browser's DNS Cache defaults to 60 second , namely 60 Access to the same domain name in seconds is not going on DNS analysis
(2) Application layer cache
Nginx、PHP etc. web The service can set the application cache to speed up the response to user requests , There are also some explanatory language , such as :PHP/Python/Java Can't run directly , It needs to be compiled into bytecode first , But bytecode can only be executed after the interpreter interprets it as machine code , So bytecode is also a kind of cache , Sometimes the bytecode is not updated after the program code is online . So usually before the new version goes online , You need to clean up the application cache first , Then launch the new version .
In addition, you can use dynamic page static technology , To speed up access , such as : A dynamic page that will access the data in the database , Generate static page file with program in advance html Product introduction of e-commerce website , Comment information and non real-time data can be realized by this technology .
(3) Data layer cache
Distributed cache service
Redis
Memcached
- database MySQL The query cache
innodb cache 、MYISAM cache
(4) Hardware cache
CPU cache (L1 Data caching and L1 Instruction cache for )、 Second level cache 、 Three level cache
Disk caching :Disk Cache
Disk array cache : Raid Cache, The battery can be used to prevent power failure and data loss
Two 、 Relational database and non relational database
1、 What is a relational database
(1) A structured database , Based on the relational model ( Two dimensional table model ) On the basis of
(2) Generally oriented to records
(3)SQL sentence ( Standard data query language )
(4) It's based on Relational database Language , Used to perform retrieval and operation of data in relational database . Include :Oracle、MySQL、SQL Server、Microsoft Access、DB2 etc.
2、 What is a non relational database
(1)NoSQL (NoSQL=NotOnlySQL), intend “ not only SQL", yes Non relational database The general term of .
(2) In addition to the mainstream relational databases , They all think it's non relational .
(3) Mainstream NoSQL The database has Redis、MongBD、Hbase、Memcached etc. .
3、 Background of non relational database
(1) High performance —— High concurrent read and write requirements for the database
(2) Huge Storage —— Requirements for efficient storage and access of massive data
(3) High Scalability && High Availability —— Requirements for high scalability and high availability of database
4、 The difference between relational database and non relational database
(1) Data storage is different
The main difference between relational and non relational databases is the way data is stored .
Relational data is naturally tabular , Therefore, it is stored in the rows and columns of the data table . Data tables can be associated with each other and stored cooperatively , It's also easy to extract data .
Non relational is the opposite , Data is not suitable to be stored in rows and columns of the data table , It's big pieces together . Non relational data is usually stored in a dataset , It's like a document 、 Key value pairs or graph structures . Your data and its characteristics are the primary factors in choosing how to store and extract data .
Relational type : Dependent on the relational model E-R chart , At the same time, data is stored in table format Non relational : In addition to storing in tabular form , It is usually combined in large blocks to store data
(2) Different expansion methods
SQL and NoSQL The biggest difference between databases may be in the way they are extended , To support growing demand, of course, expand .
To support more concurrency ,SQL The database is vertically extended , In other words, improve processing capacity , Use a faster computer , This makes it faster to process the same data set . Because the data is stored in relational tables , The performance bottleneck of the operation may involve many tables , This needs to be improved by improving computer performance . although SQL The database has a lot of expansion space , But it will eventually reach the upper limit of vertical expansion .
and NoSQL The database is scalable . Because non relational data storage is naturally distributed ,NoSQL The database can be expanded by adding more common database servers to the resource pool ( node ) To share the load .
Relationship : The longitudinal ( Natural table format ) Not off : The transverse ( Naturally distributed )
(3) Support for transactional is different
If the data operation needs high transaction or complex data query needs to control the execution plan , So traditional SQL The database is the best choice in terms of performance and stability .SQL The database supports fine-grained control over the atomicity of transactions , And it's easy to roll back transactions . although NoSQL Databases can also use transactional operations , But it can't compare with relational database in terms of stability , So their real value is in the scalability of operation and large amount of data processing .
Relational type : It is especially suitable for tasks with high transactional requirements and the need to control the implementation plan Non relationship : There will be a slight weakness here , Its value lies in high scalability and large amount of data processing
5、 summary
(1) Relational database : example -> database -> surface (table)-> Record line (row)、 Data field (column)
(2) Non relational database : example -> database -> aggregate (collection)–> Key value pair (key-value) Non relational databases do not need to build databases and collections manually ( surface ).
3、 ... and 、Redis Introduce
Official website :Redis
Redis It's an open source 、 Use C language-written NoSOL database ,Redis The server program is a single process model .
Redis Run based on memory and support persistence ( Support storage on disk ), use key-value( Key value pair ) Storage form of , It is an indispensable part of the current distributed architecture .
Redis The service can start more than one server at the same time Redis process ,Redis The actual processing speed depends entirely on the execution efficiency of the main process .
If you run only one on the server Redis process , When multiple clients access at the same time , The processing capacity of the server will decline to a certain extent ;
If on the same server Multiple Redis process , Redis While improving the concurrent processing ability, it will give the server CPU Cause a lot of pressure . That is, in the actual production environment , You need to decide how many... To open according to the actual needs Redis process . ( It is generally recommended to turn on 2 individual , Used as backup and anti high concurrency )
If the requirements for high concurrency are higher , You may consider starting multiple processes on the same server . if CPU Resources are tight , A single process can be used .
Four 、Redis advantage
1、 It has very high data reading and writing speed : The speed of data reading can be as high as 110000 Time /s, Data write speed can be as high as 81000 Time /s.、
2、 Support rich data types : Support key-value、 Strings、Lists、Hashes ( Hash value )、Sets And OrderedSets And so on . pS : string character string ( It can be used for plastic surgery 、 Floating point and character , Collectively referred to as element ) list list :( Implementation queue , The element is not unique , First in, first out ) set aggregate :( Different elements ) hash hash Hash value :( hash Of key Must be unique ) set /ordered sets aggregate / Ordered set
3、 Support data persistence : The data in memory can be saved on disk , When you restart, you can load it again for use .
4、 Atomicity : Redis all Operations are atomic .
5、 Support data backup : namely master-salve Mode data backup .
5、 ... and 、 Single thread
Redis 6.0 Before the version, the user's request was processed in a single thread mode
Why is single thread so fast ?
- Pure memory
Non blocking
Avoid thread switching and race consumption
6、 ... and 、redis contrast memcached
Support data persistence : Data in memory can be kept on disk , restart redis After the service or server, you can restore the data from the backup file to memory and continue to use
Support more data types : Support string( character string )、hash( Hash data )、list( list )、set( aggregate )、zset( Ordered set )
Support data backup : Can achieve data like master-slave Mode data backup , It also supports the use of snapshots +AOF
Support the greater value data :memcache Single key value It only supports 1MB, and redis The biggest support 512MB( Production is not recommended to exceed 2M, Performance is affected )
stay Redis6 Before version ,Redis A single thread , and memcached Is a multithreaded , So there is no single machine memcached High concurrency , Better performance , but redis Support distributed clusters for higher concurrency , single Redis The instance can realize tens of thousands of concurrent
Support cluster horizontal expansion : be based on redis cluster Horizontal expansion of , It can realize distributed cluster , Significantly improve performance and data security
It's all based on C Language development
| memcached | redis | |
|---|---|---|
| type | key-value | key-value |
| Expiration strategy | Support | Support |
| data type | Single data type | Five data types |
| Persistence | I won't support it | Support |
| Master slave copy | I won't support it | Support |
| Virtual memory | I won't support it | Support |
7、 ... and 、Redis Installation and deployment
1、 Deployment steps
1)# Close the firewall and SElinux systemctl stop firewalldsystemctl disable firewalldsetenforce 02)# install gcc gcc-c++ compiler yum install -y gcc gcc-c++ make3)# Switch to /opt Catalog , Upload the downloaded installation package and unzip it cd /opt/tar zxvf redis-5.0.7.tar.gz 4)# Enter the directory and compile and install cd /opt/redis-5.0.7/makemake PREFIX=/usr/local/redis install# because Redis The source package directly provides Makefile file , So after unpacking the package , You don't have to do it first ./configure To configure , It can be executed directly make And make install Command to install 5)# perform install_server.sh Script cd /opt/redis-5.0.7/utils ./install_server.sh # Enter all the way , The guide asks you to enter the path # The path needs to be entered manually Please select the redis executable path [] /usr/local/redis/bin/ redis-serverSelected config:Port : 6379 # The default listening port is 6379Config file : /etc/redis/6379.conf # Profile path Log file : /var/log/redis_6379.log # Log file path Data dir : /var/lib/ redis/6379 # Data file path Executable : /usr/local/redis/bin/redis-server # Executable file path Cli Executable : /usr/local/redis/bin/redis-cli # Client command tools 6)# Optimize the path and check whether the port is open # hold redis The executable program file of is put into the directory of path environment variable to facilitate system identification ln -s /usr/local/redis/bin/* /usr/local/bin/# When install_server.sh The script is finished ,Redis The service has started , The default listening port is 6379netstat -natp | grep redis7)# Modify the configuration file vim /etc/redis/6379.confbind 127.0.0.1 192.168.154.19 #70 That's ok , Add the listening host address port 6379 #93 That's ok ,Redis Default listening port daemonize yes #137 That's ok , Enable daemons pidfile /var/run/redis_6379.pid #159 That's ok , Appoint PID file loglevel notice #167 That's ok , The level of logging logfile /var/log/redis_6379.log #172 That's ok , Specify log text 8) # restart redis Check the listening address /etc/init.d/redis_6379 restart # restart ss -antp|grep redis9)##Redis Service control /etc/init.d/redis_6379 stop # stop it /etc/init.d/redis_6379 start # start-up /etc/init.d/redis_6379 restart # restart /etc/init.d/redis_6379 status # state (1) Close the firewall and SElinux

(2) install gcc gcc-c++ make compiler

(3) Switch to /opt Catalog , Upload the downloaded installation package and unzip it

(4) Enter the directory and compile and install


(5) perform install_server.sh Script

(6) Optimize the path and check whether the port is open

(7) Modify the configuration file

(8) restart redis Check the listening address

2、 Redis Command tool
rdb and aof yes redis There are two forms of persistence in services redis-cli Often used to log in to redis database | Redis Command tool | function |
|---|---|
| redis-server | Used to start Redis Tools for |
| redi s-benchmark | Used to detect Redis The operating efficiency of the machine |
| redis-check-aof | Repair AOF Persistent files |
| redis-check-rdb | Repair RDB Persistent files |
| redis-cli: | Redis Command line tools |
3 redis-cli Command line tools ( Remote login )
# grammar : redis-cli -h host -p port -a password# Options : -h : Specify the remote host -p : Appoint Redis The port number of the service -a : Specified password , The database password is not set and can be omitted -a Options -n : Specify the serial number of stock in and stock out. If no option is added, it means , Then use 127.0.0.1:6379 Connect... On this computer Redis database ,# Example redis-cli -h 192.168.59.118 -p 6379
4、redis-benchmark Testing tools
redis-benchmark It's official Redis Performance testing tools , Can effectively test Redis Service performance .
# grammar redis-benchmark [ Options ] [ Option value ]| Options | effect |
| -h | Specify the server host name |
| -p | Specify the server port |
| -s | Specify the server socket( Socket ) |
| -c | Specify the number of concurrent connections |
| -n | Specify the number of requests |
| -d | Specify... In bytes SET/GET Data size of value |
| -k | 1=keep alive O=reconnect |
| -r | SET/GET/INCR Use random key,SADD Use random values |
| -P | Pipeline requests |
| -q | Forced exit redis. Show only querylsec value |
| -csv | With csv Format output |
| -1 | Generate a cycle , Perform tests permanently |
| -t | Run only comma separated list of test commands |
| -l | ldle Pattern . Just open N individual idle Connect and wait |
(1) Example 1: towards IP The address is 192.168.59.118、 Port is 6379 Of Redis Server send 100 Multiple concurrent connections and 100000 Requests to test performance
redis-benchmark -h 192.168.154.19 -p 6379 -c 100 -n 100000

Example 2: The test access size is 100 Byte packet performance .
redis-benchmark -h 192.168.154.19 -p 6379 -q -d 100
Example 3: Test on this machine Redis The service is in progress set And lpush Performance during operation .

author : Guannan first handsome
Game programming , A game development favorite ~
If the picture is not displayed for a long time , Please use Chrome Kernel browser .
边栏推荐
- 预处理——插值
- [security attack and Defense] how much do you know about serialization and deserialization?
- 1200.Minimum Absolute Difference
- [dpdk] dpdk sample source code analysis III: dpdk-l3fwd_ 001
- CMB's written test - quantitative relationship
- Top 50 hit industry in the first half of 2022
- AVL树插入操作与验证操作的简单实现
- Hisilicon 3559 universal platform construction: RTSP real-time playback support
- Hongmi K40S root gameplay notes
- 小程序能运行在自有App中,且实现直播和连麦?
猜你喜欢
Enumeration general interface & enumeration usage specification

24. (ArcGIS API for JS) ArcGIS API for JS point modification point editing (sketchviewmodel)
Ubuntu 20 installation des enregistrements redisjson
Top 50 hit industry in the first half of 2022
Docker部署Mysql8的实现步骤
Ggplot facet detail adjustment summary
![[safe office and productivity application] Shanghai daoning provides you with onlyoffice download, trial and tutorial](/img/58/d869939157669891f369fb274d32af.jpg)
[safe office and productivity application] Shanghai daoning provides you with onlyoffice download, trial and tutorial
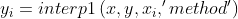
预处理——插值

What is the experience of maintaining Wanxing open source vector database

Summer 2022 daily question 1 (1)
随机推荐
22.(arcgis api for js篇)arcgis api for js圆采集(SketchViewModel)
1200.Minimum Absolute Difference
C# Task拓展方法
Implementation steps of docker deploying mysql8
Kotlin Android 环境搭建
MySQL storage engine
List interview common questions
[development software] tilipa Developer Software
Sorting operation partition, argpartition, sort, argsort in numpy
Code quality management
复杂因子计算优化案例:深度不平衡、买卖压力指标、波动率计算
Construction of Hisilicon universal platform: color space conversion YUV2RGB
Cryptography series: detailed explanation of online certificate status protocol OCSP
【DPDK】dpdk样例源码解析之三:dpdk-l3fwd_001
QT item table new column name setting requirement exercise (find the number and maximum value of the array disappear)
Allow public connections to local Ruby on Rails Development Server
CMB's written test - quantitative relationship
Optimization cases of complex factor calculation: deep imbalance, buying and selling pressure index, volatility calculation
About Tolerance Intervals
U.S. Air Force Research Laboratory, "exploring the vulnerability and robustness of deep learning systems", the latest 85 page technical report in 2022