当前位置:网站首页>阅读心得:FGAGT: Flow-Guided Adaptive Graph Tracking
阅读心得:FGAGT: Flow-Guided Adaptive Graph Tracking
2020-11-08 08:04:00 【osc_mox9hom9】
论文地址: FGAGT: Flow-Guided Adaptive Graph Tracking
FGAGT阅读心得
一、 摘要
本文提出的FGAGT追踪器,不同于FairMoT,使用Lucas金字塔光流方法预测当前帧中的历史目标位置信息,同时利用ROI Pooling和全连通层提取历史对象在当前帧特征图上的外观特征向量。然后将他们和新目标的特征向量输入进自适应图神经网络来更新特征向量,自适应图神经网络可以通过组合全局历史位置和外貌信息来更新目标的特征向量。因为历史信息的保留,他可以重新识别被遮挡的目标。训练阶段,提出了平衡MSE损失来平衡采样分布。推理阶段,使用匈牙利算法进行数据关联。FGAGT坚信匹配目标的时候,位置信息和外貌特征必须全部使用才能获得一个好的追踪结果,这也是这算法的核心。
创新点:
- 使用光流预测历史目标的在当前帧的位置,并且提取特征。相较于其他的利用过去帧的特征图来提取特征向量,我们的方法避免了从不同特征图上提取特征,这样新检测的目标特征和提取的目标历史特征会保持一致。
- 使用自适应的图网络来整合时空外貌位置信息,并且来更新特征和识别遮挡目标(加权学习特征)。
- 提出了平衡MSE损失来平衡不同的采样分布。
二、 简要介绍
多目标追踪需要根据目标的历史轨迹匹配当前帧中检测到的多个目标,同样的目标需要分配同样的id,并且形成新的轨迹,新出现的目标需要分配一个新的id而消失的目标需要删除轨迹,且无法被匹配。
问题:尽管很多方法使用了光流方法预测位置信息,但是在特征匹配过程中,历史目标和新检测的目标的特征是从不同的特征图上获得的,这会导致同样的目标特征向量总会不同,甚至相差很远。这样一个目标因为遮挡而消失,当再次出现在视野时,如何匹配上历史轨迹成为一个问题。并且过去的目标能够唯一匹配当前帧的一个目标,长时间历史目标一多,历史目标很有可能会匹配上新出现目标(错误匹配),从而导致会出现很少的新目标。
解决:提出了FGAGT追踪器,使用Lucas金字塔算法计算当前帧历史目标的中心位置。

然后当前帧通过卷积神经网络进行下采样获得特征图,使用ROI Pooling和全连接层提取历史目标和新检测到的目标(当前帧中的目标)的初始外貌特征向量,将他们输入自适应图网络,历史目标和新检测目标被视为二分图,初始外貌特征的距离和IOU被认为是边的权重,组合全局时空位置和外貌信息,输入进图网络,来更新特征向量。
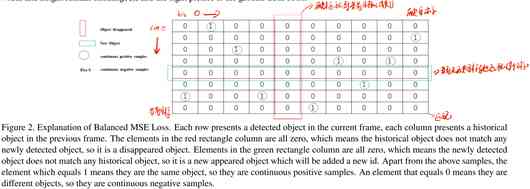
图网络中,每个维度的整合特征会被乘上一个自适应的权重,用以强化学习目标中最能解决遮挡和重识别问题的特征。图网络最终输出是一个相似性矩阵。训练阶段,提出了一个MSE Loss,具体来说就是分别在连续正,连续负,新和消失目标的损失函数前乘以一个和样本数负相关的一个系数,有利于解决不平衡样本数量分布的问题,从而让图网络学到我们想要的特征向量。
2.1 光流
光流:它指的是视频中一帧中表示同一对象到下一帧的像素移动量,由一个二维向量表示。根据是否选择图像像素稀疏的点用于光流评估,可以将光流评估分为稀疏光流评估和密集光流评估。稀疏光流选择明显的特征(梯度大的)用于光流评估和追踪。密集光流描述的是图像中的所有像素点到下一帧的运动,使用颜色作为光流的方向,亮度表示光流大小。
LK (Lucas-Kanade)算法有三个假设:1.亮度恒定,2.目标运动小,3.邻域光流一致。
所有假设成立都满足的条件下,可以构造所选像素从当前帧到下一帧的光流微分方程:
考虑第一帧的像素亮度强度 I ( x , y , t ) I\left(x,\ y,\ t\right) I(x, y, t)(t代表时间维度,(x,y)代表位置),到下一帧,这个像素运动了 ( d x , d y ) \left(dx,\ dy\right) (dx, dy)的距离,花费了 d t dt dt的时间。因为是同样的像素,且根据第一个假设像素运动前后亮度恒定,即:
I ( x , y , t ) = I ( x + d x , y + d y , t + d t ) (1) I(x, y, t)=\mathrm{I}(\mathrm{x}+\mathrm{d} \mathrm{x}, \mathrm{y}+\mathrm{d} \mathrm{y}, \mathrm{t}+\mathrm{dt}) \tag1 I(x,y,t)=I(x+dx,y+dy,t+dt)(1)
右边泰勒展开得:
I ( x , y , t ) = I ( x , y , t ) + ∂ I ∂ x d x + ∂ I ∂ y d y + ∂ I ∂ t d t + ε (2) I(x, y, t)=\mathrm{I}(\mathrm{x}, \mathrm{y}, \mathrm{t})+\frac{\partial I}{\partial x} d x+\frac{\partial I}{\partial y} d y+\frac{\partial I}{\partial t} d t+\varepsilon \tag2 I(x,y,t)=I(x,y,t)+∂x∂Idx+∂y∂Idy+∂t∂Idt+ε(2)
ε \varepsilon ε是二阶无穷小,可以忽略。然后将公式(2)带入公式(1),同时除以 d t dt dt获得:
∂ I ∂ x d x d t + ∂ I ∂ y d y d t + ∂ I ∂ t d t d t ≈ 0 (3) \frac{\partial I}{\partial x} \frac{d x}{d t}+\frac{\partial I}{\partial y} \frac{d y}{d t}+\frac{\partial I}{\partial t} \frac{d t}{d t} \approx 0 \tag3 ∂x∂Idtdx+∂y∂Idtdy+∂t∂Idtdt≈0(3)
假设u,v分别为x轴和y轴的速度矢量: u = d x d t , v = d y d t (4) \mathrm{u}=\frac{d x}{d t}, v=\frac{d y}{d t}\tag4 u=dtdx,v=dtdy(4)
I x = ∂ I ∂ x I_x=\frac{\partial I}{\partial x} Ix=∂x∂I, I y = ∂ I ∂ y I_y=\frac{\partial I}{\partial y} Iy=∂y∂I, I t = ∂ I ∂ t I_t=\frac{\partial I}{\partial t} It=∂t∂I代表图片沿着X轴,Y轴,t轴方向的像素灰度值的偏导数。则(3)可以描述为: I x u + I y v + I t ≈ 0 (5) I_{x} u+I_{y} v+I_{t} \approx 0\tag5 Ixu+Iyv+It≈0(5)
其中 I x , I y , I t I_x,\ I_y,I_t Ix, Iy,It都可以通过有限差分(一种求偏微分(或常微分)方程和方程组定解问题的数值解的方法)得到, ( u , v ) \left(u,\ v\right) (u, v)是所需的光流向量。由(5)估计一个目标函数:
min ∑ ( x , y ∈ Ω ) W 2 ( X ) ( I x u + I y v + I t ) 2 (6) \min \sum_{(x, y \in \Omega)} W^{2}(X)\left(I_{x} u+I_{y} v+I_{t}\right)^{2}\tag6 min(x,y∈Ω)∑W2(X)(Ixu+Iyv+It)2(6)
上式中 W 2 ( X ) W^2\left(X\right) W2(X)是一个权重函数,离邻域中心越远,权重越小。让
V = ( d x d t , d y d t ) = ( u , v ) T , ∇ I ( X ) = ( ∂ I ∂ x , ∂ I ∂ y ) = ( I x , I y ) T V=\left(\frac{dx}{dt},\frac{dy}{dt}\right)=(u,v)^T,\nabla I(X)=(\frac{\partial I}{\partial x},\frac{\partial I}{\partial y}){=\left(I_x,I_y\right)}^T V=(dtdx,dtdy)=(u,v)T,∇I(X)=(∂x∂I,∂y∂I)=(Ix,Iy)T
A = ( ∇ I ( X 1 ) , … , ∇ I ( X n ) ) T A=\left(\nabla I\left(X_1\right),\ldots,\nabla I\left(X_n\right)\right)^T A=(∇I(X1),…,∇I(Xn))T
W = d i a g ( W ( X 1 ) , … W ( X n ) ) W=diag{\left(W\left(X_1\right),\ldots W\left(X_n\right)\right)} W=diag(W(X1),…W(Xn))
b = − ( ∂ I ( X 1 ) ∂ t , … , ∂ I ( X n ) ∂ t ) T b=-\left(\frac{\partial I\left(X_1\right)}{\partial t},\ldots,\frac{\partial I\left(X_n\right)}{\partial t}\right)^T b=−(∂t∂I(X1),…,∂t∂I(Xn))T
n表示邻域像素的个数。然后用最小二乘法求出式(6)的解:
V = ( A T W 2 A ) − 1 A T W 2 b (7) \mathrm{V}=\left(A^{T} W^{2} A\right)^{-1} A^{T} W^{2} b\tag7 V=(ATW2A)−1ATW2b(7)
最后可以使用Newton-Raphson方法获得更加精确的值。
金字塔LK算法
由于LK算法要求位移必须足够的小,所以Pyramid-LK算法解决了这个缺点:
逐层向上减少图片大小,形成一个图片金字塔,其中图片的缩放大小为底层的宽高的一半。这会将大的位移转换为小的位移,然后使用LK算法从顶层开始计算光流,在每一层进行光流的矫正,知道最底层获得最终的光流。
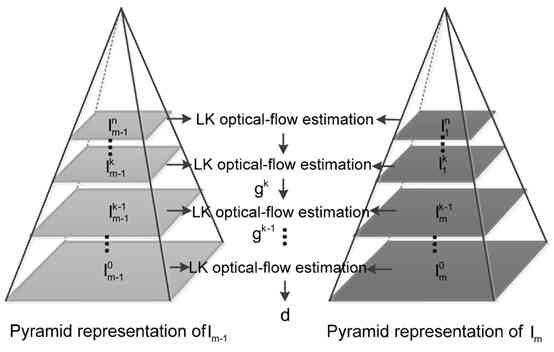
金 字 塔 L K 算 法 示 意 图 金字塔LK算法示意图 金字塔LK算法示意图
2.1 图神经网络(GNN)
早期的图网络多用于分子结构分类问题,事实上,欧式空间(例如图片)或者序列(例如text文本)等常见的场景也可以转变为图,然后利用图神经网络技术进行处理。
直到2013年,Bruna基于图信号处理提出了基于谱域和空域的图卷积神经网络,自此GNN开始不断展示其强大的能力。
对于一张图 G G G,每个节点v有自己的特征向量 X v X_v Xv。每条边连接两个节点,并且对于连接的结点 v , u v,u v,u,这条边也有自己的特征向量 X ( v , u ) X_{\left(v,u\right)} X(v,u)。GNN的目标是获得每个节点的图形感知 h v h_v hv的隐藏状态,对于每个节点,他的隐藏状态包含从邻节点获得的信息。图上通过迭代更新所有节点的隐藏状态来实现GNN。在 c + 1 c\ +\ 1 c + 1层,节点 v v v的更新状态为: h v c + 1 = f ( x v , x c o [ v ] , h n e c [ v ] , x n e [ v ] ) (8) \mathbf{h}_{v}^{c+1}=f\left(\mathbf{x}_{v}, \mathbf{x}_{c o}[v], \mathbf{h}_{n e}^{c}[v], \mathbf{x}_{n e}[v]\right)\tag8 hvc+1=f(xv,xco[v],hnec[v],xne[v])(8)
上式中的 f f f是隐藏状态的状态更新函数,我们使用神经网络代替。 x c o [ v ] \mathbf{x}_{co}\left[v\right] xco[v]代表为节点 v v v的相邻边对应的特征向量, x n e [ v ] \mathbf{x}_{ne}\left[v\right] xne[v]代表节点 v v v的相邻节点的特征向量, h n e c [ v ] \mathbf{h}_{ne}^c\left[v\right] hnec[v]代表在𝑐层的时候,节点 v v v的邻节点的隐藏状态。 f f f是所有节点共享的全局函数。
三、 FGAGT网络结构
结构图如下:
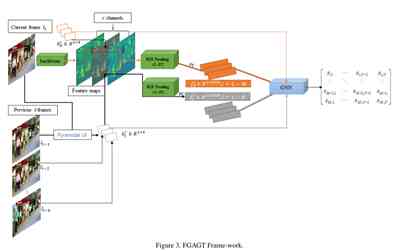
如图,当前帧 I t I_t It通过backbone变为了特征图,用当前帧检测后的获得的M个bbox提取区域特征,然后通过ROI Pooling和全连接层全变为特征向量。同时 I t − 1 I_{t-1} It−1帧的历史目标的在当前帧中的bbox通过LK金字塔算法进行预测出来,然后加上过去 T T T(除去 I t − 1 I_{t-1} It−1帧) 帧中的bbox,一共N个历史bbox通过ROI Pooling和全连接层转化为特征向量。
输入图神经网络主要有两部分:当前帧的M个目标的外貌特征向量和bbox和过去T帧的历史目标的外貌特征向量和bbox。
需要注意的是,外貌特征向量是从当前帧的特征图中提取,而不是从历史帧的特征图中提取的历史目标。最终输出相似矩阵 S ∈ R M × N S\ \in\ R^{M\times N} S ∈ RM×N。
3.1 自适应图神经网络模型
如下,将新检测的目标和历史目标作为一个二分图,如下图(和上面介绍的意义通过迭代的思想不断优化历史和当前检测的信息相同):
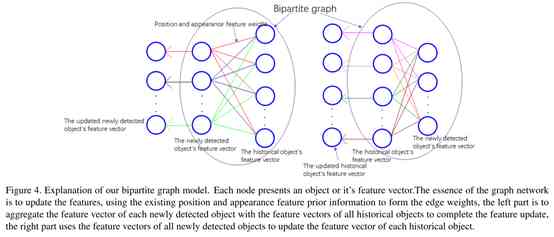
如上图中左边,任意一个新检测的目标会和所有的历史目标进行关联,但是任意两个新检测目标或者两个历史目标之间不会有关联。为了获取点之间的隐藏状态 h v h_v hv,根据公式(8),我们来进行迭代更新:
( c + 1 ) h d i = f ( ( c ) h d i , { ( c ) h t j , ( c ) e d i , j } j = 1 N ) , i = 1 , 2 , ⋯ , M ( c + 1 ) h t j = f ( ( c ) h t j , { ( c ) h d i , ( c ) e t j , i } i = 1 M ) j = 1 , 2 , ⋯ , N \begin{aligned} {}^{(c+1) }& h_{d}^{i}=f\left({ }^{(c)} h_{d}^{i},\left\{ { }^{(c)} h_{t}^{j},{ }^{(c)} e_{d}^{i, j}\right\}_{j=1}^{N}\right), i=1,2, \cdots, M \\ { }^{(c+1)} h_{t}^{j} &=f\left({ }^{(c)} h_{t}^{j},\left\{ { }^{(c)} h_{d}^{i},{ }^{(c)} e_{t}^{j, i}\right\}_{i=1}^{M}\right) j=1,2, \cdots, N \end{aligned} (c+1)(c+1)htjhdi=f((c)hdi,{ (c)htj,(c)edi,j}j=1N),i=1,2,⋯,M=f((c)htj,{ (c)hdi,(c)etj,i}i=1M)j=1,2,⋯,N
f f f是隐藏状态的更新函数,使用神经网络代替。在本文中,我们使用一个单层GNN,并添加了一个自适应部分。
AGNN(自适应图神经网络)利用已存在的位置和特征先验信息作为边 e i , j e_{i,j} ei,j的权重来整合目标特征向量并更新所有目标特征。
整合步骤如下:
- 首先计算初始特征相似性:
s i , j = 1 ∥ f d i − f t j ∥ 2 2 + 1 × 1 0 − 16 s i , j = s i , j s i , 1 2 + s i , 2 2 + ⋯ s i , j 2 + ⋯ + s i , N 2 S f t = [ s i , j ] M × N , i = 1 , 2 , ⋯ M , j = 1 , 2 , ⋯ N \begin{aligned} s_{i, j}=& \frac{1}{\left\|f_{d}^{i}-f_{t}^{j}\right\|_{2}^{2}+1 \times 10^{-16}} \\ s_{i, j}=& \frac{s_{i, j}}{\sqrt{s_{i, 1}^{2}+s_{i, 2}^{2}+\cdots s_{i, j}^{2}+\cdots+s_{i, N}^{2}}} \\ \mathbf{S}_{\mathrm{ft}}=&\left[s_{i, j}\right]_{M \times N}, \quad i=1,2, \cdots M, j=1,2, \cdots N \end{aligned} si,j=si,j=Sft=∥∥∥fdi−ftj∥∥∥22+1×10−161si,12+si,22+⋯si,j2+⋯+si,N2 si,j[si,j]M×N,i=1,2,⋯M,j=1,2,⋯N - 计算交并比,和1的结果形成一个先验相似性矩阵:
E = w × I O U + ( 1 − w ) × S f t \mathrm{E}=w \times \mathrm{IOU}+(1-w) \times \mathbf{S}_{\mathrm{ft}} E=w×IOU+(1−w)×Sft参数w测量的是位置信息和外貌特征信息之间的关联度,初始为0.5。 - 整合信息: F t a g = E F t = E [ f t 1 f t 2 ⋮ f t N ] \mathbf{F}_{\mathrm{t}}^{\mathrm{ag}}=\mathrm{EF}_{t}=\mathrm{E}\left[\begin{array}{c} f_{t}^{1} \\ f_{t}^{2} \\ \vdots \\ f_{t}^{N} \end{array}\right] Ftag=EFt=E⎣⎢⎢⎢⎡ft1ft2⋮ftN⎦⎥⎥⎥⎤
然后更新特征: H d = σ ( F d W 1 + Sigmoid ( F d W a ) ⊙ F t a g W 2 ) (9) \mathbf{H}_{\mathrm{d}}=\sigma\left(\mathbf{F}_{d} W_{1}+\operatorname{Sigmoid}\left(\mathbf{F}_{d} W_{a}\right) \odot \mathbf{F}_{\mathrm{t}}^{\mathrm{ag}} W_{2}\right)\tag9 Hd=σ(FdW1+Sigmoid(FdWa)⊙FtagW2)(9)同时更新: H t = σ ( F t W 1 + Sigmoid ( F t W a ) ⊙ F d a g W 2 ) (10) \mathbf{H}_{\mathrm{t}}=\sigma\left(\mathbf{F}_{t} W_{1}+\operatorname{Sigmoid}\left(\mathbf{F}_{t} W_{a}\right) \odot \mathbf{F}_{\mathrm{d}}^{\mathrm{ag}} W_{2}\right)\tag{10} Ht=σ(FtW1+Sigmoid(FtWa)⊙FdagW2)(10)
⊙ \odot ⊙是点积。对象特征向量在不同维度上的值代表了被捕获对象不同部位的特征,不同部位可能是区分对象的关键。因此聚合信息是需要给不同维度特征加权,设置一个自适应参数 W a W_a Wa, S i g m o i d ( F d W a ) Sigmoid{\left(\mathbf{F}_dW_a\right)} Sigmoid(FdWa)作为自适应权重。
更新完特征后,通过全连接层,来减少图网络更新后的特征的维度,并计算欧式距离来测量特征之间的相似性。我们只需要一个简单的单层图网络将输出的特征向量进行归一化,然后通过矩阵乘法即可得到相似度矩阵: h d i = h d i ∥ h d i ∥ 2 h t j = h t j ∥ h t j ∥ 2 S out = H d H t T (11) \begin{aligned} h_{d}^{i} &=\frac{h_{d}^{i}}{\left\|h_{d}^{i}\right\|_{2}} \\ h_{t}^{j} &=\frac{h_{t}^{j}}{\left\|h_{t}^{j}\right\|_{2}} \\ \mathbf{S}_{\text {out }} &=\mathbf{H}_{\mathrm{d}} \mathbf{H}_{\mathrm{t}}^{\mathrm{T}} \end{aligned}\tag{11} hdihtjSout =∥∥hdi∥∥2hdi=∥∥∥htj∥∥∥2htj=HdHtT(11)
相同目标输出1,不同目标输出0。其目的是使同一目标的特征向量近似重合,不同目标的特征向量近似垂直。当特征向量未归一化且元素均大于0时,相当于同一目标之间特征的欧几里得距离越近,不同目标之间的欧几里得距离越长越好。
3.2 平衡MSE Loss
在所有的目标中,新出现的目标和消失的目标占少数,所以他们在损失中的比重也相应的小。对于每个目标,至多存在一个正样本(label=1),相应的其余都是负样本(label=0),采样极度不平衡。因此想到了在每种损失前面乘以一个系数,来达到平衡的作用。
L = α E c 0 + β E c 1 + γ E n e + δ E d + ε E w = ∑ i = 1 M ∑ j = 1 N [ α ( S ^ i , j − S i , j ) 2 ⋅ I continue ⋅ I S i , j = 0 + β ( S ^ i , j − S i , j ) 2 ⋅ I continue ⋅ I S i , j = 1 + γ ( S ^ i , j − S i , j ) 2 ⋅ I n e w + δ ( S ^ i , j − S i , j ) 2 ⋅ I disap + ε ∥ W ∥ 2 2 ] (12) \begin{aligned} \mathcal{L} &=\alpha E_{c 0}+\beta E_{c 1}+\gamma E_{n e}+\delta E_{d}+\varepsilon E_{w} \\ &=\sum_{i=1}^{M} \sum_{j=1}^{N}\left[\begin{array}{c} \alpha\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {continue }} \cdot \mathbb{I}_{S_{i, j}=0}+\beta\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {continue }} \cdot \mathbb{I}_{S_{i, j}=1} \\ +\gamma\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{n e w}+\delta\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {disap }}+\varepsilon\|W\|_{2}^{2} \end{array}\right] \end{aligned}\tag{12} L=αEc0+βEc1+γEne+δEd+εEw=i=1∑Mj=1∑N⎣⎢⎡α(S^i,j−Si,j)2⋅Icontinue ⋅ISi,j=0+β(S^i,j−Si,j)2⋅Icontinue ⋅ISi,j=1+γ(S^i,j−Si,j)2⋅Inew+δ(S^i,j−Si,j)2⋅Idisap +ε∥W∥22⎦⎥⎤(12)
I c ( S i , j ) = { 1 , if S i , j is the c target 0 , if S i , j isn’t the c target \mathbb{I}_{c}\left(S_{i, j}\right)=\left\{\begin{array}{c} 1, \text { if } S_{i, j} \text { is the c target } \\ 0, \text { if } S_{i, j} \text { isn't the c target } \end{array}\right. Ic(Si,j)={ 1, if Si,j is the c target 0, if Si,j isn’t the c target 其中𝛼,𝛽,𝛾,𝛿,𝜀是超参。
3.3 推理
通过自适应矩阵获得的相似度矩阵S_{out},然后在其右边增加一个 M × M M\times M M×M的矩阵,其所有元素为 m a r g i n = π margin = π margin=π,形成一个增广矩阵 S o u t = [ S o u t , π × 1 M × M ] S_{out}=\ [S_{out},\ \pi\ \times\ 1_{M\times M}] Sout= [Sout, π × 1M×M],然后使用匈牙利算法匹配。
3.3.1. 匹配关联和新目标的出现
假设匈牙利输出为 ( i , j ) (i,j) (i,j), i i i代表行, j j j代表列。如果 j < N j<N j<N,则 i i i和 j j j的轨迹匹配, j j j的 i d id id就分配给 i i i;否则i就是个新目标,然后 i i i的 i d id id就为 m a x { i d } + 1 max\{id\}\ +\ 1 max{ id} + 1。

3.3.2. 目标消失
假设选取的过去帧数为10,如果一个目标在接下来的10帧中都没有匹配成功,则目标会被认为是消失。
四、 总结
MOTChalleng上达到了SOTA,提高很大。这项工作进一步研究了如何提取更好的对象特征,以获得更好的数据关联。第一次使用再当前帧中预测过去帧的位置信息,并且提取特征,将他们和当前帧检测到的特征共同输入到自适应图网络,通过整合时空全局位置和外貌信息来更新特征。同时提出了一个平衡MSE损失用于训练,能够更加平衡不同类型目标之间的损失的权重,以便让神经网络更好的数据关联。
版权声明
本文为[osc_mox9hom9]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4274636/blog/4707855
边栏推荐
- November 07, 2020: given an array of positive integers, the sum of two numbers equals N and must exist. How to find the two numbers with the smallest multiplication?
- ubuntu实时显示cpu、内存占用率
- 16. File transfer protocol, vsftpd service
- Visual Studio 2015 未响应/已停止工作的问题解决
- leetcode之判断路径是否相交
- Application of bidirectional LSTM in outlier detection of time series
- Go sending pin and email
- ulab 1.0.0发布
- FORTRAN77从文件中读入若干数据并用heron迭代公式开方
- Introduction to ucgui
猜你喜欢

归纳一些比较好用的函数
鼠标变小手

Problems of Android 9.0/p WebView multi process usage

China Telecom announces 5g SA commercial scale in 2020
NOIP 2012 提高组 复赛 第一天 第二题 国王游戏 game 数学推导 AC代码(高精度 低精度 乘 除 比较)+60代码(long long)+20分代码(全排列+深搜dfs)
WPF personal summary on drawing
Basic operation of database
Adobe Prelude / PL 2020 software installation package (with installation tutorial)
个人短网址生成平台 自定义域名、开启防红、统计访问量
Android Basics - RadioButton (radio button)
随机推荐
Summary of knowledge points of Jingtao project
C expression tree (1)
Python3.9的7个特性
IOS upload app store error: this action cannot be completed - 22421 solution
GoLand writes a program with template
Ladongo open source full platform penetration scanner framework
Go之发送钉钉和邮箱
Fortify漏洞之 Privacy Violation(隐私泄露)和 Null Dereference(空指针异常)
双向LSTM在时间序列异常值检测的应用
[solution] distributed timing task solution
nvm
UCGUI简介
面部识别:攻击类型和反欺骗技术
On the stock trading of leetcode
Basic knowledge of C + +
What details does C + + improve on the basis of C
Sum up some useful functions
FORTRAN 77 reads some data from the file and uses the heron iteration formula to solve the problem
Experience the latest version of erofs on Ubuntu
scala 中 Future 的简单使用