当前位置:网站首页>Bert knowledge distillation
Bert knowledge distillation
2022-06-11 05:27:00 【just do it now】
1 brief introduction
Pre training model BERT And related variants have basically occupied the list of major language evaluation tasks since their publication , Constantly refresh records , however ,BERT The space and time cost caused by the large number of parameters limits its wide application in downstream tasks . Based on this , People hope to pass Bert Get a smaller scale model , At the same time, they basically have Bert The ability of , So as to provide the possibility for large-scale application of downstream tasks . At present, many Bert Relevant distillation methods have been proposed , This chapter will analyze the details and differences between these distillation methods .
Knowledge distillation consists of two models ,teacher The model follows student Model , commonly teacher The scale of the model and the amount of parameters are relatively large , So the ability is stronger , and student The scale of the model is relatively small , If you train directly, the effect is limited , So it's training first teacher Model , Let it learn enough , And then use student Model to learn teacher Model behavior , So as to realize the transformation of knowledge from teacher The model moves to student Model , bring student The model has the ability to approach a large model with a small number of parameters . In distillation , The most common student Model part loss, For the same data , take teacher The prediction of the model soft Probability as ground truth, Give Way teacher Model to learn and predict the same results , This part teacher The model follows student The distance between the probabilities predicted by the model is the most common loss( It's usually cross entropy ). Distillation learning hope student Model learned teacher The power of the model , So the predicted results are consistent with teacher The model predicted soft The probability is close enough , That is, I hope this part loss As small as possible .
2 DualTrain+SharedProj
Although previous knowledge distillation can effectively compress the model size , But it is difficult to teacher The ability of the model to distill into a smaller vocabulary student In the model , and DualTrain+SharedProj Solved the problem . It's mainly aimed at Bert The size of the vocabulary and the embedded latitude are reduced , The rest of the , Including the model structure and the number of layers teacher Model (Bert Base) Agreement , So as to realize the transformation of knowledge from teacher Model migration to student In the model .

chart 1: DualTrain+SharedProj frame
Different from other distillation methods ,DualTrain+SharedProj There are two special places , One is Dual Training, The other is Shared Projection.Dual Training Mainly to solve teacher The model follows student The model does not share a vocabulary , In distillation , about teacher Model , They'll randomly choose teacher Models or student The vocabulary of the model is used for word segmentation , Understandably, it's a mixture teacher The model follows student Glossary of models , This way you can align two lists of different sizes . For example, the left part in the figure ,I and machine It's using teacher The word segmentation result of the model and the rest token It's using student Word segmentation results of the model . The second part is Shared Projection, This part is easy to understand , because student The latitude of the model embedded layer is reduced , Cause every transformer The latitude of the layers has shrunk , But we want to student The model follows teacher Model transformer The parameters of the layer are close enough , So here we need a trainable matrix to combine two different dimensions of transformer Layer parameters can only be compared when they are scaled to the same dimension . If yes teacher Scale the parameters of the model , It's called down projection, If yes student Scaling of model parameters , It's called up projection. meanwhile ,12 Layer of transformer Parameters share the same scaling matrix , So it's called shared projection. Such as below , Subscript t,s Represent the teacher The model follows student Model .

chart 2: up projection Loss

chart 3: DualTrain+SharedProj Loss function of
In distillation , Will teacher The model follows student Models are trained on supervisory data , Add the loss of the predicted results of the two models to the difference between the two models transformer The loss of distance between layer parameters is taken as the final loss , To update student Parameters of the model . The final experimental results also show that , With student The more the latitude of the hidden layer of the model is reduced , The effect of the model will gradually deteriorate .

chart 4: DualTrain+SharedProj The experimental effect of
DualTrain+SharedProj It's rare student The model follows teacher A distillation method of model not sharing vocabulary , By reducing the vocabulary and the latitude of the embedded layer , It can greatly reduce the size of the model . At the same time, pay attention to , The size has shrunk dramatically ,student The more the effect of the model decreases . Another point I don't quite understand , Only through one dual training Can the process align the two lists ? Is it necessary to check before distillation teacher Model , It is more reasonable to mix the segmentation results of the two word lists for pre training ?
3 DistillBERT
DistilBERT It is obtained by a more conventional distillation method , its teacher The model is still Bert Base, DistilBERT Continue to use Bert Structure , however transfromer The number of layers is only 6 layer (Bert Base Yes 12 layer ), It will also embed layers token-type embedding With the last pooling Layer removal . In order to make DistilBERT There is a more reasonable initialization ,DistilBERT Of transformer The parameter comes from Bert Base, Every two floors transformer Take the parameters of one layer as DistilBERT Parameter initialization of .
In distillation , Except for the conventional distillation part loss, A self-monitoring training is also added loss(MLM Mission loss), besides , The experiment also found that adding a word embedded loss Good for alignment teacher The model follows student Hidden layer representation of the model .
DistilBERT It is a common method obtained by distillation , Basically by reducing transformer To reduce the model size , At the same time, it accelerates the model reasoning .
4 LSTM
Distillation learning does not require teacher The model follows student The model should belong to the same model architecture , So there is a big hole in the brain , Want to use BiLSTM As student Model to carry Bert Base Huge capacity . there teacher The model is still Bert Base,student The model is divided into three parts , The first part is the word embedding layer , The second part is two-way LSTM+pooling, Here will be BiLSTM The status of the hidden layer is obtained by max pooling Generate a representation of a sentence , The third part is the full connection layer , Directly output the probability of each category .
Before distillation begins , It is necessary to first set the task specific monitoring data teacher Fine tune the model , Because it's a classification task , therefore Bert Base The following full connection layer will update the parameters together , So that teacher The model adapts to downstream tasks . In distillation ,student The loss of the model is divided into three parts , The first part is still the conventional basis teacher The model predicted soft Probability heel student The model predicts the probability of cross entropy loss between . The second part is under the supervision data student The cross entropy loss between the predicted results of the model and the real label results . The third part is teacher The model follows student The relationship between model generation and representation KL distance , That is to say BiLSTM+pooling Follow Bert base The distance between the state outputs of the last layer , But because the two may have different dimensions , Therefore, it is also necessary to introduce a full connection layer to scale .
![]()
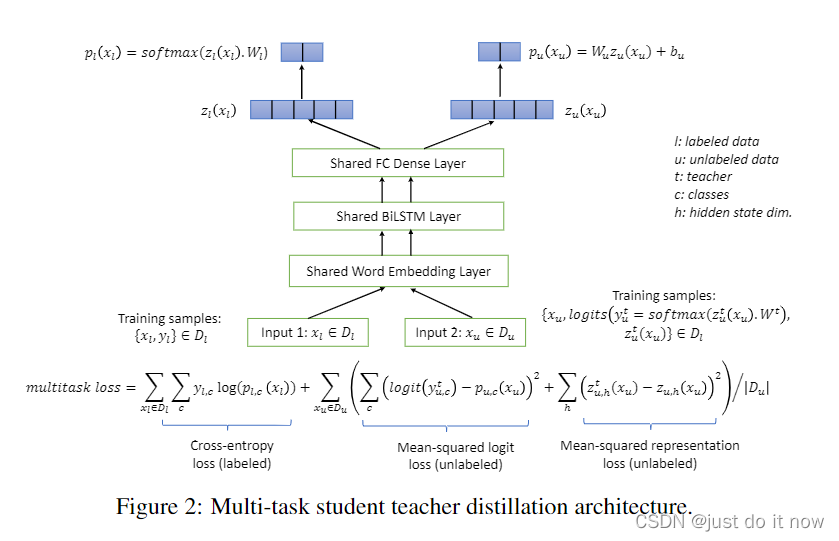
chart 5: BiLSTM The distillation process of

chart 6: BiLSTM Comparison of distillation effect
You can see what you get by distillation BiLSTM Obviously superior to direct finetune Of , This proves the effectiveness of distillation learning . besides ,BiLSTM Its accuracy is very high , Explain that the task is relatively simple ( Or after distillation BiLSTM More accurate than teacher Model Bert Base It's weird to be tall ?), So it doesn't mean that Bert Base Distillation to BiLSTM It's a good choice .LSTM The limitation of its own structure makes it difficult to learn transformer Knowledge and ability , The author has tried similar methods on some difficult data sets before , But ultimately as student Model LSTM The effect of teacher There is still a big gap between the models , And the generalization ability is poor .
5 PDK
PKD Want to learn through distillation Bert Base Of transformer The number of layers is compressed , But the normal way is to learn teacher The result of the last layer of the model , Although it can achieve comparable results in the training set teacher Effect of model , But the performance in the test set quickly converged . This phenomenon seems to be over fitting on the training set , So it's affecting student The generalization ability of the model . Based on this ,PKD New constraints are added to the original , Drive student Model to learn to imitate teacher The intermediate process of the model . Specifically, there are two possible ways , The first is to let student Model to learn teacher Model transformer Results every few layers , The second is to let student Model to learn teacher The last layers of the model transformer Result .
The loss function of distillation process includes three parts , The first part is conventional teacher The model predicted soft Probability and student The cross entropy loss between the predicted results of the model , The second part is student The model predicts the cross entropy loss between the probability and the real label , The third part is teacher The model follows student The distance between the intermediate states of the models , Used here [CLS] Representation of position .
6 TinyBert
TinyBert It is special in that its distillation process is divided into two stages . The first stage is general distillation ,teacher model It's pre trained Bert, Can help TinyBert Learn a wealth of knowledge , Have strong general ability , The second stage is task specific distillation ,teacher moder Is a finetune Of Bert, bring TinyBert Learn about specific tasks . Design of two distillation links , Can guarantee TinyBert Powerful general ability and improvement under specific tasks .
At each distillation stage ,student The distillation of the model is divided into three parts ,Embedding-layer Distillation,Transformer-layer Distillation, Prediction-layer Distillation.Embedding-layer Distillation It is the distillation of the word embedded layer , bring TinyBert Smaller dimensions embedding The output results should be as close as possible to Bert Of embedding Output results .Transformer-layer Distillation Is one of transformer Distillation of layers , The distillation here uses a separator k The way of layer distillation . That is to say , If teacher model Of Bert Of transformer Yes 12 layer , If TinyBert Of transformer The design has 4 layer , So, every time 3 Layer distillation ,TinyBert Of the 1,2,3,4 layer transformer What we learn separately is Bert Of the 3,6,9,12 layer transformer Layer output .Prediction-layer Distillation Mainly alignment TinyBert Follow Bert Output at the prediction layer , What we learn here is the prediction layer logit, That is, the probability value . The losses of the first two parts are MSE Calculation , because teacher The model follows student The dimensions of the model in the embedded layer are inconsistent with those in the hidden layer , So here we need the corresponding linear mapping to student The intermediate output of the model maps to the following teacher The same dimension as the model , The last part of the loss is calculated by cross entropy loss . Through these three parts of learning , Can guarantee TinyBert Both the middle layer and the final prediction layer have learned Bert Corresponding results , So as to ensure the accuracy .

chart 7: TinyBert frame
TinyBert The two-stage distillation process can drive student The model can learn teacher General knowledge and domain specific knowledge of the model , Guarantee student The performance of the model in downstream tasks , It is a training skill worth learning from .
7 MOBILEBERT
MOBILEBERT It may be the most cost-effective distillation method at present ( Maybe the author's vision is limited ), Whether from the goal of learning , Or the whole way of training , They are all very considerate .MOBILEBERT Of student The model follows teacher The network layers of the model are consistent , The relevant model structure has changed , First of all student The model follows teacher Models have been added bottleneck, Used to scale internal representation dimensions , rearwards loss This section will introduce , The second is student The model will FFN Change to stacked FFN, Finally, it removed layer normalization Follow the activation function by gelu Switch to relu.
In distillation ,student The loss of the model consists of two parts . The first part is student Models and teacher Between models feature map Distance of , there feature map It refers to each layer transformer Output result . ad locum , In order to make student The hidden layer dimension ratio of the model teacher The hidden layer dimension of the model is smaller to achieve model compression , there student The model follows teacher Model transformer The structure has been added bottleneck, That is, the green trapezoid in the figure , Through these bottleneck The text representation size can be scaled , So as to achieve teacher The model follows student The models are in each transformer Different internal dimensions , But the input and output dimensions are the same , So it is possible to use the interior to represent the small size student Model to learn the internal representation of large teacher The ability and knowledge of the model . The second part is about each layer of the two models transformer in attention Distance of , This part loss It's to take advantage of self attention from teacher Learn relevant contents in the model, so as to better learn the first part feature map.

chart 8: MOBILEBERT Related network structure
MOBILEBERT The distillation process is asymptotic , In distillation, learn L The parameters of the layer will be fixed L Parameters below layer , Study layer by layer teacher Model , Until you have learned all the levels .

chart 9: MOBILEBERT The asymptotic knowledge transfer process
After finishing the distillation study ,MOBILEBERT There will be further pre training , Pre training has three parts loss, Part one and part two are BERT In the process of the training MLM Follow NSP Mission loss, The third part is teacher The model follows student Model in [MASK] The cross entropy loss between the predicted probabilities of the positions .
8 summary
In order to intuitively compare the compression efficiency and model effect of the above mentioned distillation methods , We have summarized the specific information of several models as well as in MRPC Performance on dataset . On the whole , There are some related conclusions .
a) The higher the compression efficiency, the lower the model effect .
b) Student The upper limit of the model is teacher Model . For the same student Model , Not at all teacher The bigger the model student The better the model will be . Because the bigger it is teacher Model , Means greater compression efficiency , It also means more serious performance degradation .
c) Just learn teacher The final prediction of the model soft Probability is not enough , Need to be right teacher The representation or parameters in the middle of the model are also learned , To further ensure that student Effect of model .
d) cut transformer The number of layers or reducing the latitude of the hidden layer state can compress the model , For reducing the hidden layer state dimension , use MOBILEBERT That kind of bottleneck Is superior to the conventional method of aligning model dimensions through an additional mapping . The upper limit of model compression efficiency by reducing the hidden layer state dimension is higher .
e) Progressive learning is effective . That is, to fix the parameters of the lower layer , Only the parameters of the current layer are updated , Iterate until the update is completed student All layers of the model .
f) Staged distillation is effective . First learn the general teacher Model , Then learn about specific tasks finetune Of teacher Model .
g) Distillation across model structures is effective . use BiLSTM To learn Bert Base Ability than direct finetune BiLSTM The effect is better .
Model | type | Compress Factor | MRPC(f1) |
Bert Base | 1 | 88.9 | |
DualTrain+SharedProjUp | 192 96 48 | 5.74 19.41 61.94 | 84.9 84.9 79.3 |
DistilBERT | 1.67 | 87.5 | |
PKD | 6 3 | 1.64 2.40 | 85.0 80.7 |
TinyBert | 4 | 7.50 | 86.4 |
MOBILEBERT | 4.30 | 88.8 |
reference
1. (2020) EXTREME LANGUAGE MODEL COMPRESSION WITH OPTIMAL SUBWORDS AND SHARED PROJECTIONS
https://openreview.net/pdf?id=S1x6ueSKPr
2. (2020) DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
https://arxiv.org/abs/1910.01108
3. (2020) DISTILLING BERT INTO SIMPLE NEURAL NETWORKS WITH UNLABELED TRANSFER DATA
https://arxiv.org/pdf/1910.01769.pdf
4. (2019) Patient Knowledge Distillation for BERT Model Compression
https://arxiv.org/pdf/1908.09355.pdf
5. (2020) TINYBERT: DISTILLING BERT FOR NATURAL LAN- GUAGE UNDERSTANDING
https://openreview.net/attachment?id=rJx0Q6EFPB&name=original_pdf
6. (2020) MOBILEBERT: TASK-AGNOSTIC COMPRESSION OF BERT BY PROGRESSIVE KNOWLEDGE TRANSFER
边栏推荐
- Zed2 running vins-mono preliminary test
- Traversal of binary tree -- restoring binary tree by two different Traversals
- GAMES101作业7-Path Tracing实现过程&代码详细解读
- Yolov5 training personal data set summary
- jvm调优五:jvm调优工具和调优实战
- Dongmingzhu said that "Gree mobile phones are no worse than apple". Where is the confidence?
- (十五)红外通信
- Click the icon is not sensitive how to adjust?
- Wxparse parsing iframe playing video
- Section IV: composition and materials of asphalt mixture (2) -- main materials of asphalt
猜你喜欢

Wechat applet, automatic line feed for purchasing commodity attributes, fixed number of divs, automatic line feed for excess parts

Paper reproduction: pare

Huawei equipment is configured to access the virtual private network through GRE
Share | guide language image pre training to achieve unified visual language understanding and generation

Oh my Zsh correct installation posture

NVIDIA SMI has failed because it could't communicate with the NVIDIA driver

Maximum number of points on the line ----- hash table solution

Click the icon is not sensitive how to adjust?

Take stock of the AI black technologies in the Beijing Winter Olympic Games, and Shenzhen Yancheng Technology
Preliminary test of running vins-fusion with zed2 binocular camera
随机推荐
BP neural network derivation + Example
Share | guide language image pre training to achieve unified visual language understanding and generation
oh my zsh正确安装姿势
Section IV: composition and materials of asphalt mixture (2) -- main materials of asphalt
Huawei equipment is configured with bgp/mpls IP virtual private network
How to make lamps intelligent? How to choose single fire and zero fire intelligent switches!
Games101 job 7-path tracing implementation process & detailed interpretation of code
Titanic rescued - re exploration of data mining (ideas + source code + results)
Emnlp2021 𞓜 a small number of data relation extraction papers of deepblueai team were hired
Section I: classification and classification of urban roads
lower_ Personal understanding of bound function
Vins fusion GPS fusion part
创建酷炫的 CollectionViewCell 转换动画
2021-04-19
35. search insertion position
Stone game -- leetcode practice
Analysis while experiment - a little optimization of memory leakage in kotlin
How much current can PCB wiring carry
6 questions to ask when selecting a digital asset custodian
The solution "no hardware is configured for this address and cannot be modified" appears during botu simulation