当前位置:网站首页>How to ensure the uniqueness of ID in distributed environment
How to ensure the uniqueness of ID in distributed environment
2022-07-04 08:56:00 【Java geek Technology】
Preface
First, let's talk about why we need distributed ID, And distributed ID It's used to solve some problems . When our project was still in a single architecture , We use the autoincrement of the database ID You can solve a lot of data identification problems . But with the development of our business, our architecture will gradually evolve into a distributed architecture , So this is the time to use the self increasing data ID No way. , Because the data of a business may be put in several databases , At this point we need a distributed ID Used to identify a piece of data , So we need a distributed ID Build services for . So distributed ID What are the requirements and challenges of our service ?
requirement
- Globally unique : Since it is used to identify the unique data , So a distributed ID It must be the only one in the world , All services in the same business are consistent , It won't change , This is a basic requirement ;
- Global incremental : It's also easy to understand , We want to make sure that the generated ID It's increasing in turn , Because a lot of times ID It's for people to see , If it's not incremental , It lacks a lot of readability ;
- Information security : Distributed ID It's also important to be safe , Because we're talking about generated ID Is increasing , It's possible that our competitors will know our ID The generation frequency of , There will be a big problem in such scenarios as e-commerce , But this often conflicts with global increment ;
- High availability : Distributed ID The build service for must be highly available , After all, once it can't be generated ID, All subsequent services cannot continue to be used ;
Common distributed ID Realization
In today's Internet , According to different business scenarios and requirements , For distributed ID There are several ways to realize :
- UUID;
- Redis;
- The distorted database is self increasing ID;
- Twitter snowflake algorithm
- US mission Leaf—— A variation of the snowflake algorithm ;
UUID
Write Java My friend is right UUID It's not strange ,7dbb9f04-d15e-4c88-b74b-72a35e0d7580 It's a standard UUID, Although they all say UUID It's the only one in the world , Have the first of the requirements we mentioned earlier , But obviously there is no global incremental , This kind of distribution ID Poor readability , If it's just used to record logs or scenes that don't need people to understand, it can be used , But it's not suitable for the unique identification of business data we're talking about here . And this kind of disorder UUID If it is a primary key, it will seriously affect the performance .
Redis
Redis There is one incr The order of , This command can guarantee the increment of atoms , To some extent, it can also generate the global ID, But the use of Redis There are two questions :
- Not beautiful , Although what we need is an overall situation ID, however incr The order is from 1 The starting integer , So it will lead to the whole situation ID The length of is inconsistent , Although it can also be used to identify unique business data , But some scenes also lack readability , Because it doesn't carry date information ;
- rely on Redis High availability , because Redis It's memory based , In order to ensure ID It's not lost, so it's necessary to Redis persist , But what about Redis The two ways of persistence have their own advantages and disadvantages , Detailed reference to the official account before the article interviewer : Please tell me Redis How to ensure that data will not be lost after downtime ;
Database autoincrement ID
Previously, we mentioned that a single database can no longer use auto increment in a distributed environment ID 了 , Because of every MySQL The number of examples increases ID from 1 Start , And the steps are in accordance with 1 In turn, increasing , In this case, it's easy to think about whether we can consider setting different step sizes for each database . If we set different steps , This ensures that every database instance can generate ID, And it doesn't repeat . Although a simple system can work like this , But there are also a few problems :
- Relying on databases DB, In a distributed environment , It's risky to rely too much on databases , Can't support high concurrency , Especially for some e-commerce trading scenarios , Hundreds of thousands per second QPS, The database can't handle it ;
- The data of different database instances cannot be directly associated with each other , Need extra storage , To string data together , Increase business complexity ;
Twitter's snowflake algorithm —— snowflake
snowflake The algorithm is twitter open source distributed ID generating algorithm , This algorithm provides a standard idea , Many companies refer to this algorithm to do their own implementation , The more famous one is meituan Leaf. Here we focus on how to realize the snowflake algorithm .
If you are interested, please refer to the article https://tech.meituan.com/2017/04/21/mt-leaf.html Take a look at meituan's leaf Implementation principle of .
The idea of snowflake algorithm is to divide the whole into parts , Will be distributed ID The generation of distributed to each machine room and machine , Use a 64 position long Type to represent a ID,64 The structure of is as follows , The first sign bit 0, And then there was 41 Bit time stamp , Next 10 It's a computer room plus machines , final 12 Bits are serial numbers .
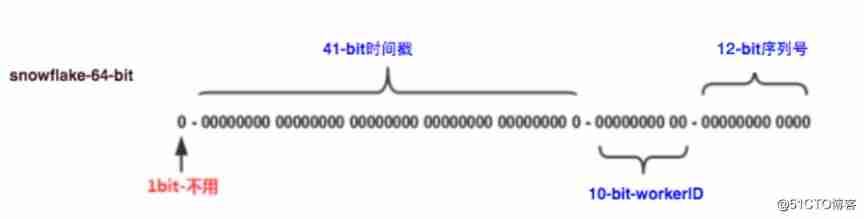
The above structure is the basic structure of snowflake algorithm , Different companies will adjust according to their own business , Some can adopt 32 Bits or other bits , And the number of time stamp can also be adjusted according to the actual situation ,10 Bit workerID Companies with computer rooms can be made up of computer rooms and machines , Companies without computer rooms can be directly made up of machines , The sequence bit can also be adjusted according to the situation .
We can do a simple calculation ,41 The time of bit is 2 ^ 41 / (365 * 24 * 3600 * 1000) = 69 year , Every machine can generate every millisecond 2 ^ 12 = 4096 individual ID.
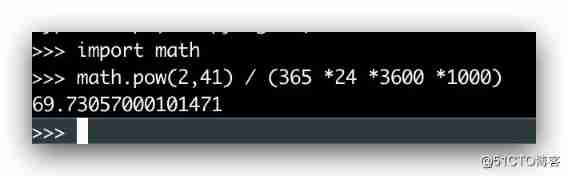
Does that mean that our code can only run 69 Years? ? It's not , Here, the service will set an initial value when it starts , The timestamp here is the difference between the machine time and the initial value . that SnowFlake What are the advantages and disadvantages of the algorithm ?
- Because of the time stamp , So meet the self increasing requirements , At the same time, it also has a certain readability ;
- Divide the whole into parts, and each service can directly generate unique ID, Just configure the computer room and machine number ;
- The length can be adjusted according to the business ;
- The disadvantage is that it depends on the clock of the machine , If there is something wrong with the clock of the machine , Will lead to the generation of ID May repeat , This needs to be controlled ;
Combined with the above principles , We can go through Java Code to implement , The code is as follows :
public class SnowFlakeUtil {
// Initial timestamp
private final static long START_TIMESTAMP = 1624796691000L;
// The number of bits occupied by the data center
private final static long DATA_CENTER_BIT = 5;
// Number of digits occupied by machine identification
private final static long MACHINE_BIT = 5;
// The number of digits occupied by the serial number
private final static long SEQUENCE_BIT = 12;
/**
* The maximum value of each part
*/
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
private final static long MAX_MACHINE_NUM = ~(-1L << MACHINE_BIT);
private final static long MAX_DATA_CENTER_NUM = ~(-1L << DATA_CENTER_BIT);
/**
* The displacement of each part to the left
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
private final long idc;
private final long serverId;
private long sequence = 0L;
private long lastTimeStamp = -1L;
private long getNextMill() {
long mill = System.currentTimeMillis();
while (mill <= lastTimeStamp) {
mill = System.currentTimeMillis();
}
return mill;
}
/**
* According to the specified data center ID And machine logo ID Generate the specified serial number
*
* @param idc Data Center ID
* @param serverId Machine logo ID
*/
public SnowFlakeUtil(long idc, long serverId) {
if (idc > MAX_DATA_CENTER_NUM || idc < 0) {
throw new IllegalArgumentException("IDC Illegal data center number !");
}
if (serverId > MAX_MACHINE_NUM || serverId < 0) {
throw new IllegalArgumentException("serverId Illegal machine number !");
}
this.idc = idc;
this.serverId = serverId;
}
/**
* Generate the next ID
*
* @return
*/
public synchronized long genNextId() {
long currTimeStamp = System.currentTimeMillis();
if (currTimeStamp < lastTimeStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currTimeStamp == lastTimeStamp) {
// In the same milliseconds , The serial number is increasing
sequence = (sequence + 1) & MAX_SEQUENCE;
// The number of sequences in the same millisecond has reached the maximum
if (sequence == 0L) {
currTimeStamp = getNextMill();
}
} else {
// In different milliseconds , The serial number is set to 0
sequence = 0L;
}
lastTimeStamp = currTimeStamp;
return (currTimeStamp - START_TIMESTAMP) << TIMESTAMP_LEFT | idc << DATA_CENTER_LEFT | serverId << MACHINE_LEFT | sequence;
}
public static void main(String[] args) {
SnowFlakeUtil snowFlake = new SnowFlakeUtil(4, 3);
for (int i = 0; i < 100; i++) {
System.out.println(snowFlake.genNextId());
}
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
Reference resources
- You know · Say in one breath 9 Species distributed ID generation , The interviewer is a little confused
- Leaf—— Meituan comments distributed ID generating system
< END > Here's good news ,Java Geek technology reader group ( Mainly fishing ), Time interval 2 Years later, it opened up again , Interested friends , You can reply on the public account :999
边栏推荐
- How to send pictures to the server in the form of file stream through the upload control of antd
- HMS core helps baby bus show high-quality children's digital content to global developers
- Guanghetong's high-performance 4g/5g wireless module solution comprehensively promotes an efficient and low-carbon smart grid
- Research Report on research and investment prospects of China's testing machine industry (2022 Edition)
- What if I forget the router password
- In depth research and investment strategy report on China's hydraulic parts industry (2022 Edition)
- Awk from entry to earth (12) awk can also write scripts to replace the shell
- How to choose solid state hard disk and mechanical hard disk in computer
- Dede plug-in (multi-function integration)
- CLion-控制台输出中文乱码
猜你喜欢

Nurse level JDEC addition, deletion, modification and inspection exercise
![[C Advanced] file operation (2)](/img/50/e3f09d7025c14ee6c633732aa73cbf.jpg)
[C Advanced] file operation (2)
微服務入門:Gateway網關

Guanghetong's high-performance 4g/5g wireless module solution comprehensively promotes an efficient and low-carbon smart grid
User login function: simple but difficult

What if I forget the router password
![Langage C - démarrer - base - syntaxe - [opérateur, conversion de type] (vi)](/img/3f/4d8f4c77d9fde5dd3f53ef890ecfa8.png)
Langage C - démarrer - base - syntaxe - [opérateur, conversion de type] (vi)
ArcGIS application (XXII) ArcMap loading lidar Las format data

How does Xiaobai buy a suitable notebook

The basic syntax of mermaid in typera
随机推荐
Implementation principle of redis string and sorted set
China battery grade manganese sulfate Market Forecast and strategic consulting report (2022 Edition)
awk从入土到入门(10)awk内置函数
C語言-入門-基礎-語法-[運算符,類型轉換](六)
Codeforces Round #803 (Div. 2)(A-D)
awk从入门到入土(12)awk也可以写脚本,替代shell
[Chongqing Guangdong education] National Open University spring 2019 455 logistics practice reference questions
Ehrlich sieve + Euler sieve + interval sieve
awk从入门到入土(14)awk输出重定向
Awk from entry to earth (8) array
What is inner connection and outer connection? What are the uses and benefits
Codeforces Global Round 21(A-E)
System disk expansion in virtual machine
In depth investigation and Strategic Research Report on China's motion controller Market (2022 Edition)
Awk from getting started to digging in (11) detailed explanation of awk getline function
How to choose solid state hard disk and mechanical hard disk in computer
The old-fashioned synchronized lock optimization will make it clear to you at once!
Internal learning
Cancel ctrl+alt+delete when starting up
awk从入门到入土(18)gawk线上手册